
最近几个月,AI 圈出现了一个新概念——Large Action Models(LAMs),直译过来就是"大型行动模型"。这个名字听起来可能有点拗口,但它代表的变化却很有意思:AI 终于不再只是个话唠,开始学会真正动手做事了。
过去几年里,大家对 ChatGPT、Claude 这些语言模型已经很熟悉了。它们确实很厉害,能写文章、做翻译、回答问题,但说到底还是个"理论派"——只能告诉你该怎么做,却没法替你真正动手。你问它怎么订机票,它会给你一个完美的攻略,但你还是得自己打开网站、填表单、付款。
LAMs 的出现就是为了解决这个问题。简单说,它们不仅能理解你的需求,还能直接帮你完成任务。
什么是 Large Action Models?
要理解 LAMs,先得明白它们和传统 AI 助手的区别。
传统的 AI 助手更像是个知识渊博的顾问。你问它:"帮我订个明天下午2点的会议室",它会告诉你:"您可以打开公司的预订系统,然后点击预订按钮,选择时间..."然后你还得自己去操作。
而 LAMs 驱动的系统则不同。它接到同样的指令后,会直接去访问预订系统,查看可用时间,选择合适的会议室,完成预订,甚至给相关人员发送邀请。最后告诉你:"已经订好了A会议室,确认号是#12345。"
这就是 LAMs 的核心价值:从"说"到"做"的跨越。
LAMs 和 LLMs 有什么不同?
虽然 LAMs 通常建立在大型语言模型(LLMs)的基础上,但两者的设计目标完全不同。
LLMs 就像是一个博学的学者,它们在海量的文本数据上训练,学会了语言的各种模式和知识。它们的强项是理解和生成文本,但局限也很明显——只能在文字世界里打转。
LAMs 则更像是一个实干家。它们的训练数据不是文本,而是各种操作演示、用户界面交互记录、API 调用日志等。这让它们学会了如何与真实世界的软件系统打交道。
简单对比一下:
| 特征 | 大型语言模型 (LLMs) | 大型动作模型 (LAMs) |
|---|---|---|
| 主要功能 | 文本/内容生成 | 任务/动作执行 |
| 核心输出 | 预测下一个词/标记 | 预测下一个动作/操作 |
| 训练数据 | 海量文本和代码语料库 | 人类操作演示、UI交互、动作轨迹、API调用 |
| 输入模态 | 主要为文本 | 多模态(文本、图像、UI状态、音频) |
| 交互范围 | 自包含的、对话式的 | 与外部系统、API、GUI交互 |
| 核心能力 | 语言理解与流畅性 | 推理、规划与执行 |
| 典型任务 | 写邮件、回答问题、翻译 | 预订服务、处理订单、控制设备 |
LAMs 在 AI Agent 中的位置
说到 LAMs,就不能不提 AI Agent(AI 智能体)。这个概念最近也很火,但很多人容易把它们搞混。
简单来说,AI Agent 是一个完整的系统,能够感知环境、制定计划、执行任务。而 LAMs 更像是这个系统的"大脑",负责将计划转化为具体的行动。
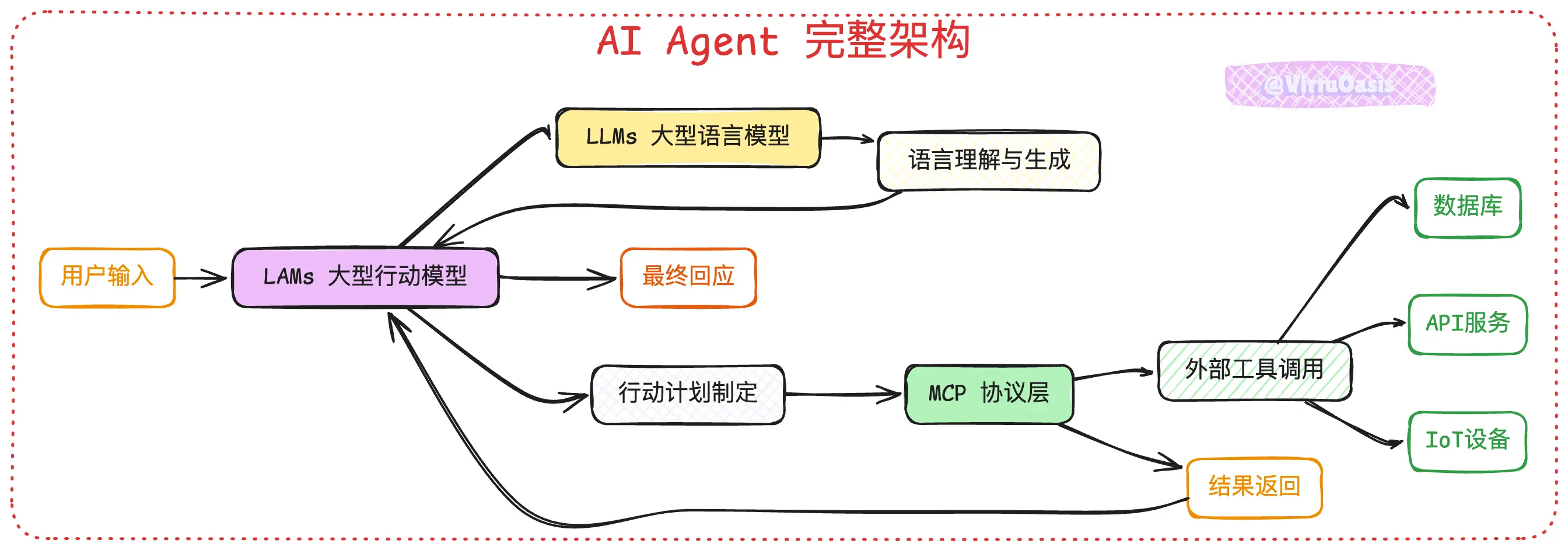
一个完整的 AI Agent 通常包含几个层次:
语言理解层:这部分还是传统的 LLMs 在工作,负责理解用户的自然语言指令。
行动规划层:这就是 LAMs 的核心价值所在。它不仅要理解指令,还要制定具体的执行计划,决定调用哪些工具、按什么顺序操作。
接口协议层:这里就要提到 MCP(Model Context Protocol)了。这是一个新兴的标准化协议,专门用来连接 AI 模型和各种外部工具。
举个例子,如果你让 AI 帮你处理一个退款申请:
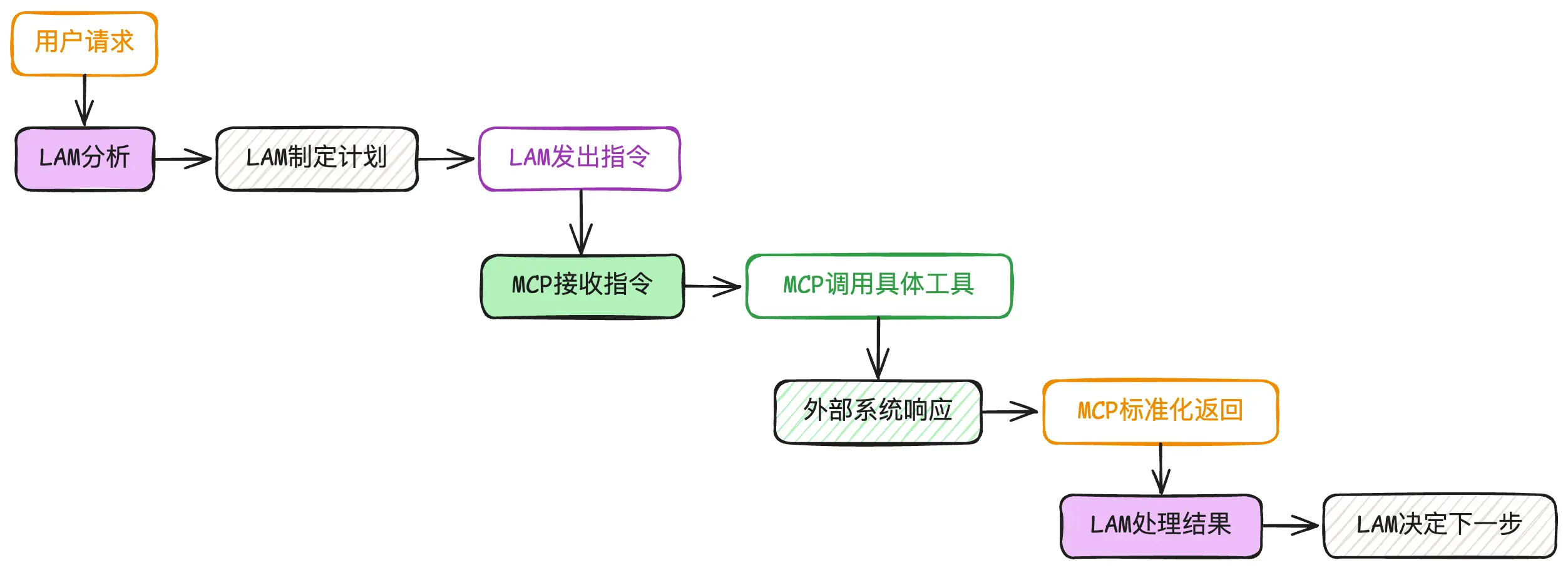
- LLMs 先理解你的意图:用户要申请退款
- LAMs 制定行动计划:查订单→检查政策→验证条件→处理申请→发送通知
- 通过 MCP 协议调用各种工具:订单系统、支付接口、邮件服务等
- 最终完成退款并通知用户
三者关系图解
| 技术层 | 核心功能 | 智能程度 | 实际影响 | 发展阶段 |
|---|---|---|---|---|
| LLMs | 语言理解与生成 | 高(语言智能) | 信息输出 | 成熟技术 |
| LAMs | 智能行动执行 | 最高(行动智能) | 改变现实 | 新兴技术 |
| MCP | 标准化连接协议 | 无(纯协议) | 信息传递 | 新兴标准 |
LAMs 的技术实现原理
要理解 LAMs 的工作机制,需要从架构、训练和执行三个维度来分析。
神经-符号(Neuro-symbolic)混合架构:给AI装上两套"大脑"
如果把传统的AI比作只有一个大脑的机器人,那么LAMs就像是有两套不同思维系统的智能体。这种设计被称为神经-符号混合架构,听起来很复杂,但理解起来其实不难。
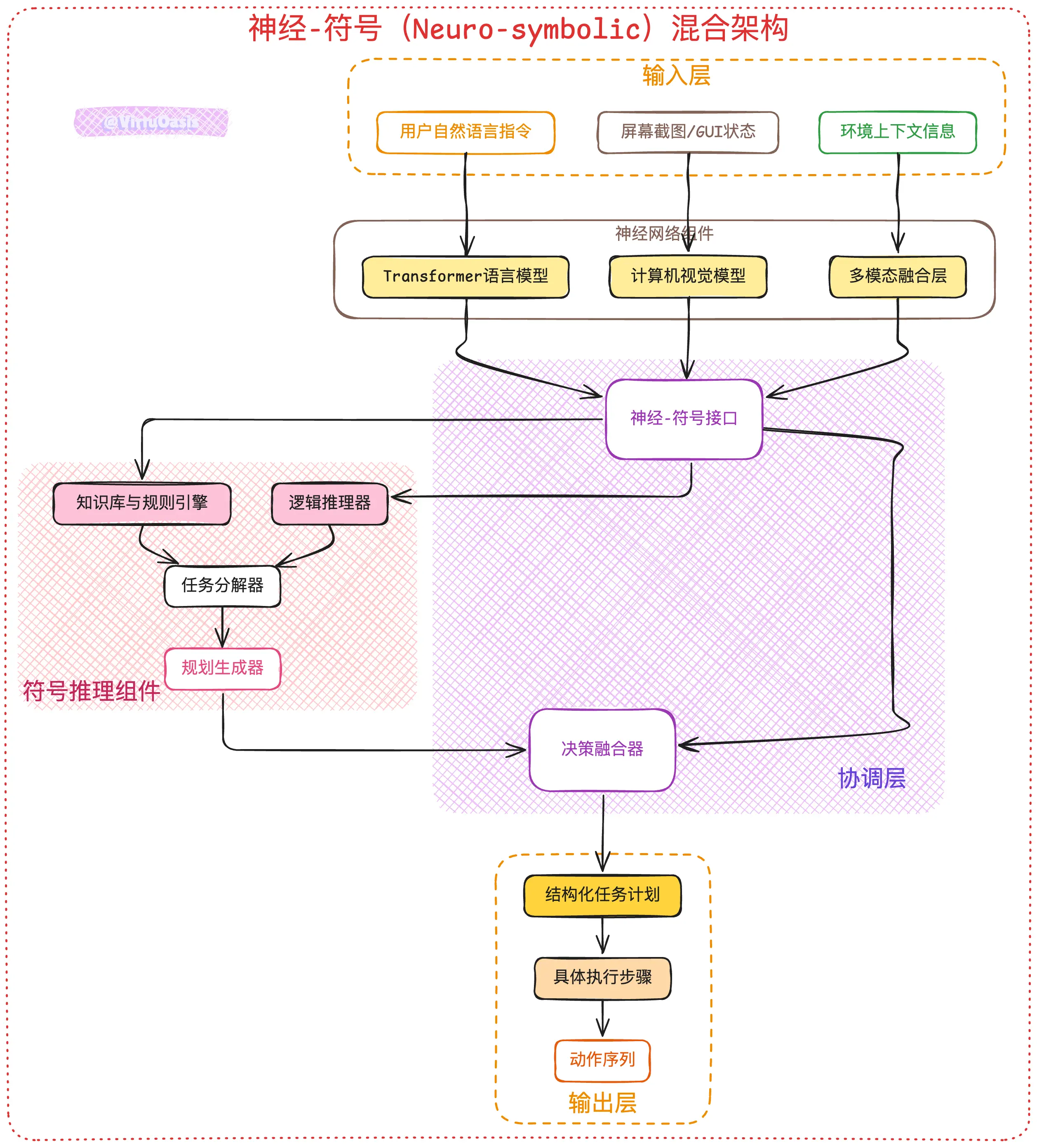
第一套"大脑"是神经网络,它的工作方式很像人的直觉系统。你看到一个网页,瞬间就能识别出哪里是搜索框、哪里是按钮,这种快速的模式识别就是神经网络的强项。它能理解屏幕截图、解析用户的自然语言,甚至读懂网页的结构,但这个过程是"黑盒"的——你很难解释它是怎么做到的。
第二套"大脑"是符号推理系统,它更像人的理性思维。当你计划一次旅行时,会条理清晰地想:先查航班、比较价格、订票、找酒店、安排交通。符号系统就是这样工作的,它能把复杂的目标拆解成逻辑清晰的步骤序列。
这两套系统配合得很巧妙:神经网络负责"看懂"世界,符号系统负责"想清楚"怎么做。Rabbit的r1设备就是这样设计的,它不只是记住在哪个位置点击,而是真正理解用户想要达成什么目标。
训练方式:跟着人类"做中学"
要让AI学会操作电脑,最直接的办法就是让它观察人类是怎么做的。这听起来很简单,但实际操作起来比想象的复杂得多。
传统的语言模型吃的是文字,而LAMs吃的是"行为"。研究人员需要记录下人类操作计算机的每一个细节:鼠标在哪里点击、键盘输入了什么内容、点击后屏幕发生了什么变化。这些完整的操作记录被称为"行为轨迹"。
每一条轨迹就像是一个完整的故事,包含了四个关键要素:首先是AI"看到"了什么(屏幕截图、网页结构、应用状态),然后是AI"想到"了什么(内部推理过程),接着是AI"做了"什么(点击、输入、调用接口),最后是"结果"如何(成功还是失败、界面有什么变化)。
收集这些数据是个巨大的工程。Salesforce专门为此开发了ActionStudio框架,就像是给LAMs训练建了一个标准化的工厂流水线。它不仅能处理各种复杂的多媒体数据,还支持不同的训练方式——有些直接调整整个模型,有些只优化关键部分,还有些会根据人类的反馈来改进AI的行为。
两种技术路径:GUI vs API
LAMs 执行任务的方式主要分为两大类,这也代表了行业内的技术分化。
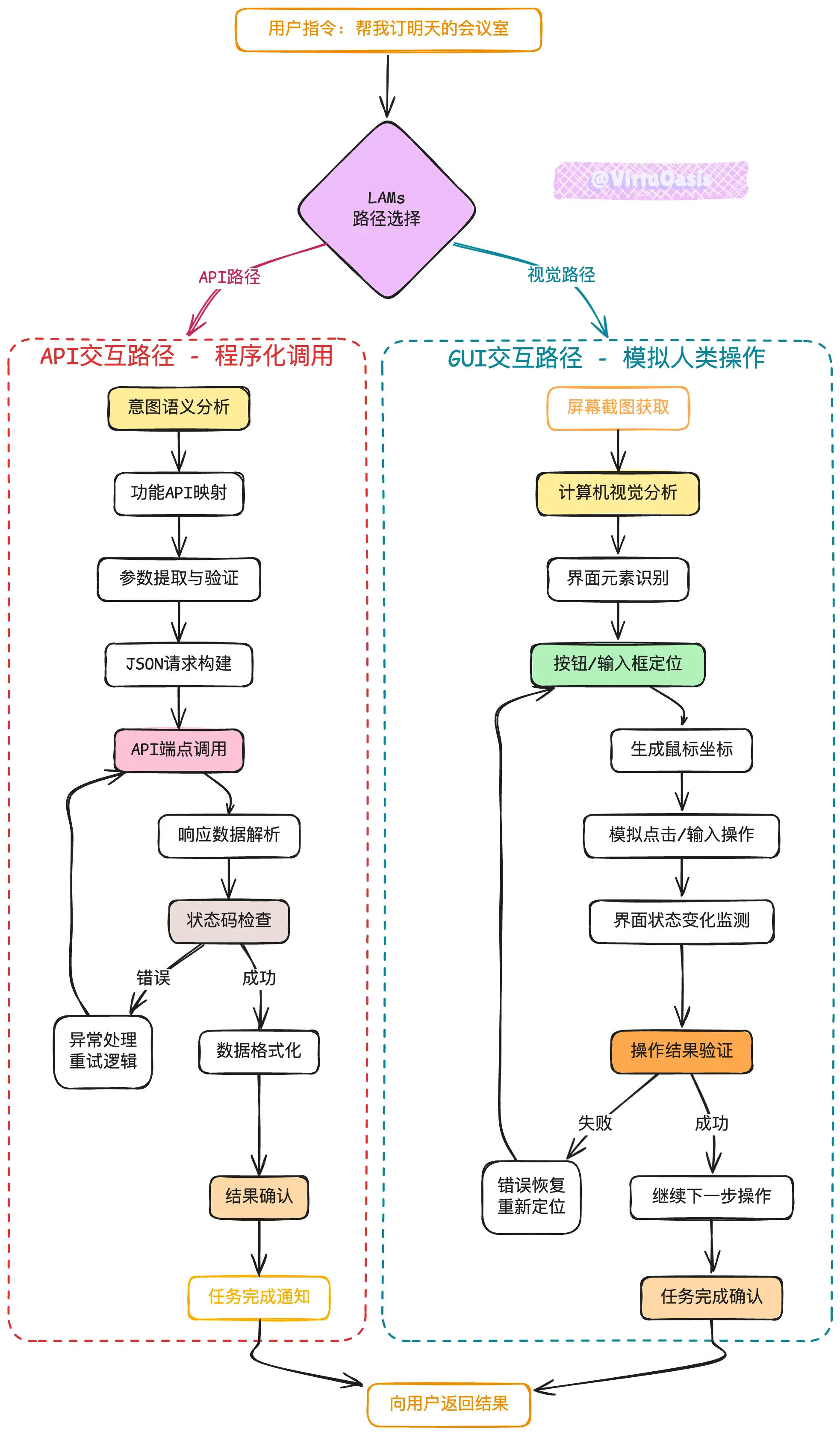
路径一:基于图形界面的自动化
这种方法让 AI 像人类一样"看"屏幕、"操作"界面。
视觉感知技术:AI 通过计算机视觉来理解屏幕内容。先进的模型如微软的 GUI-Actor 采用了"无坐标"方法——不是预测具体的(x,y)像素位置,而是使用注意力机制直接高亮目标元素。这种方法更加鲁棒,不容易因为界面布局变化而失效。
操作执行机制:AI 通过模拟鼠标和键盘事件来执行操作。Adept 的 ACT-1 就是这种模式的代表,它能够在 Chrome 浏览器中自主完成复杂的网页操作。
优势与挑战:这种方法的最大优势是通用性——理论上可以操作任何有图形界面的软件,无需额外集成。但脆弱性也很明显:UI的微小变化就可能导致整个流程失败。
路径二:基于API的程序化交互
这种方法更加结构化,AI 直接通过后端接口与系统交互。
函数调用机制:当收到用户请求时,LAMs 会分析意图,确定需要调用的API,然后生成相应的JSON格式参数。这个过程需要精确的语义理解和参数映射能力。
专门化优化:Salesforce 的 xLAM 系列就是为这种模式特别优化的。他们开发了从1B到8x22B参数的不同规模模型,在函数调用准确性上表现优异,在 Berkeley Function Calling Leaderboard 上取得了很好的成绩。
这种方法特别适合企业环境,因为API调用是可审计、可控制的,安全性更有保障。
推理循环:观察-思考-行动
LAMs 的运行不是一次性的预测,而是一个持续的循环过程。
规划阶段(Think):接收到用户指令后,LAMs 首先进行任务分解。这可能使用链式思维(Chain-of-Thought)推理,也可能采用更复杂的规划算法。ReAct(Reason+Act)框架就是将这个过程标准化的尝试。
执行阶段(Act):根据规划执行具体操作,可能是GUI点击,也可能是API调用。
观察阶段(Observe):执行后观察结果,获取反馈信息。这个环节至关重要——如果操作失败或产生意外结果,LAMs 需要能够调整策略,尝试其他方法。
这种闭环反馈机制是 LAMs 区别于传统自动化脚本的关键特征。它让 AI 具备了类似人类的错误恢复能力。
技术挑战与解决方案
多模态理解难题:LAMs 需要同时处理文本、图像、界面状态等多种数据类型。目前的解决方案是使用多模态Encoder,将不同类型的输入映射到统一的表示空间。
长序列处理:复杂任务可能需要几十上百步的操作序列。为了解决上下文长度限制,研究者们在探索层次化规划、记忆机制等方案。
安全性保障:让AI直接操作系统存在安全风险。目前的做法是通过权限控制、操作审核、沙盒环境等多重保护机制来降低风险。
在下篇文章中,我们将深入探讨当前市场上的主要玩家、他们的不同策略,以及 LAMs 面临的现实挑战和未来发展前景。这个从"能说会道"到"亲力亲为"的变化,正在如何改变我们与数字世界的交互方式?