如何把Medicare/Medicaid理赔数据变成真金白银
你有没有这样的困惑?
公司数据库里躺着几百万条理赔记录,领导问你:"这些数据能帮我们省钱吗?"
你打开Excel,看着密密麻麻的ICD-10代码、CPT编码、Provider ID... 一脸懵逼。
这就是99%医疗数据分析师的日常。
今天,我们聊聊如何把这些"睡在数据库里的黄金"挖出来,变成真正能用的产品。
💰 理赔数据:沉睡的金矿
先说个真实案例。
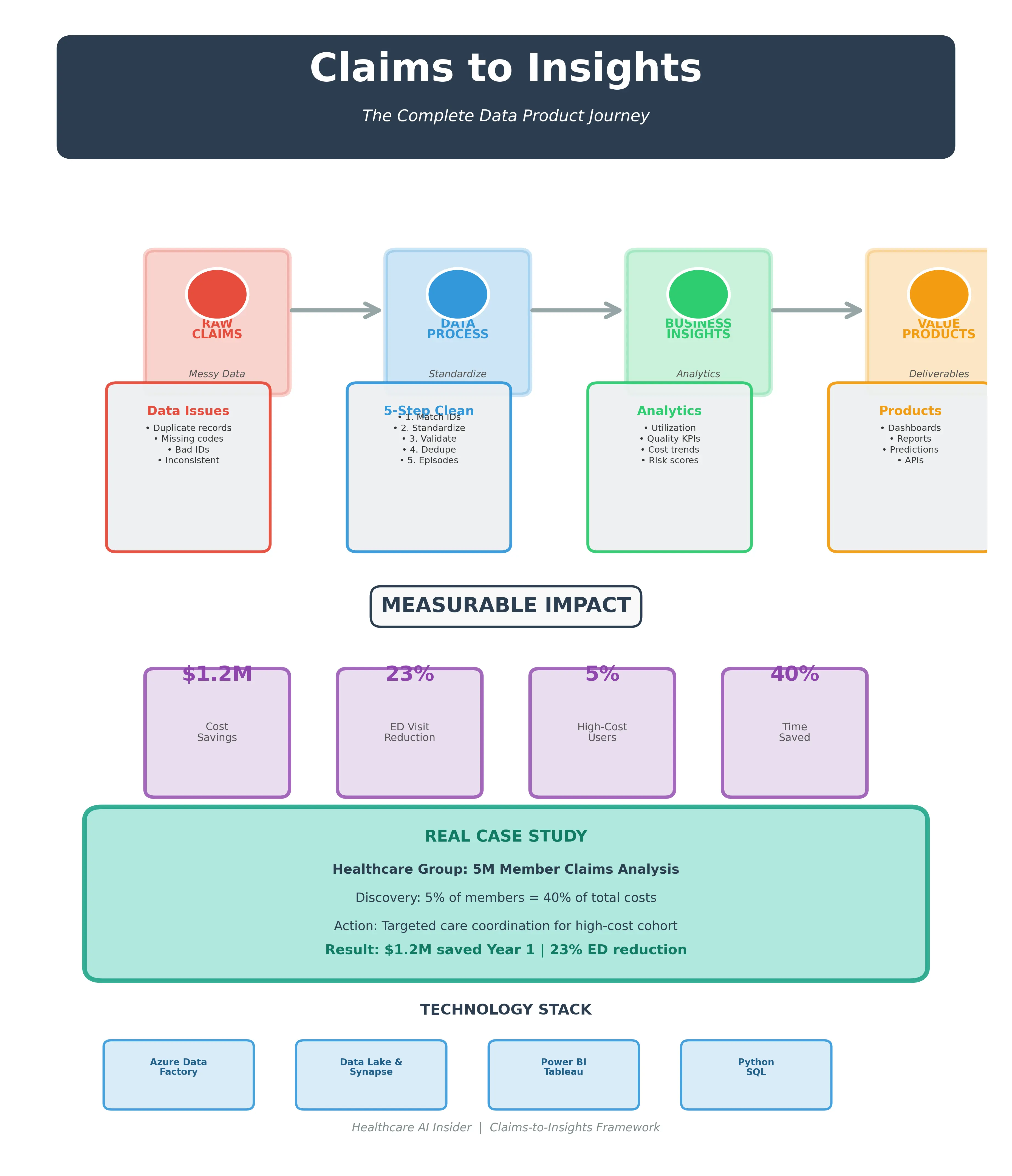
某医疗集团有500万会员的历史理赔数据,每天新增2万条记录。数据躺在服务器里三年,从来没人看过。
直到有一天,他们发现:5%的高频急诊用户贡献了40%的医疗成本。
针对这5%的人做干预,第一年就省下了120万美元。
这就是理赔数据的威力。
理赔数据里到底有啥?
简单来说,每一条理赔记录都包含:
✅ 患者信息:谁看的病?年龄、性别、地址
✅ 医生信息:谁看的?哪家医院?
✅ 诊疗信息:做了什么检查?开了什么药?
✅ 费用信息:花了多少钱?保险报了多少?
✅ 时间信息:什么时候看的?多久复诊一次?
这些信息单独看没什么用,但组合起来,就能回答很多商业问题:
- 哪些疾病最花钱?
- 哪些患者最容易再次住院?
- 哪些医生看病效果好?
- 我们的医保网络有哪些漏洞?
问题不是数据不够,而是你不知道怎么用。
🔧 第一步:数据接入与清洗
Azure云平台:现代化的基础设施
现在大部分医疗机构都在用Azure云平台处理理赔数据,架构长这样:
Azure Data Factory(数据工厂)
↓
Azure Data Lake Storage(数据湖)
↓
Azure Synapse Analytics(数据仓库)
听起来很高大上?其实就是:把数据搬进来 → 存起来 → 分析处理。
⚠️ 三个常见的坑(和解决方案)
很多团队在这一步就翻车了。我总结了三个最常见的问题:
坑1:大文件导入失败 ❌
每次导入几百万条数据,Pipeline(数据管道)就崩溃。
解决方案 ✅
把大文件切成小块,并行处理,设置断点续传。
坑2:数据库内存爆了 ❌
多表Join(连接)的时候,Synapse SQL Pool直接卡死。
解决方案 ✅
用Member ID做分布键(Distribution Key),建立合理的索引策略。
坑3:HIPAA合规问题 ❌
数据在传输过程中没加密,违反了HIPAA法规。
解决方案 ✅
全程使用Azure Private Link和托管身份验证。
划重点:理赔数据不是普通数据,它涉及患者隐私,每一步都必须合规。
🧹 第二步:数据标准化
这是整个流程中最关键、最容易翻车的环节。
原始数据有多乱?
你以为理赔数据是这样的:
| 患者ID | 医生 | 诊断 | 费用 |
|---|---|---|---|
| 001 | 张医生 | 糖尿病 | $500 |
实际上是这样的:
- 同一个患者,在不同系统里有3个ID
- 同一个医生,名字拼写有5种版本
- 同一个诊断,ICD-10代码填错了
- 同一次就诊,有3条重复的理赔记录
- 关联关系对不上
不清洗数据,后面的分析全是垃圾。
5步标准化流程
我们团队用的方法是:
第1步:身份识别
把同一个患者在不同系统里的ID统一起来。
第2步:医生标准化
建立统一的医生档案库。
第3步:编码验证
校验和标准化所有的医疗编码(ICD-10, CPT等)。
第4步:去重
识别和处理重复的理赔记录。
第5步:Episode构建
把相关的理赔记录组合成"就诊事件"(这个很重要,后面详细说)。
🔥 秘密武器:Episode-Based分析
这是我们团队的核心方法论。
什么是Episode(就诊事件)?
简单说,就是把同一个疾病、同一段时间内的所有就诊记录打包在一起。
举个例子:
患者张三因为心脏病,在30天内产生了这些记录:
- 急诊就诊(1次)
- 住院(1次)
- 出院后复诊(2次)
- 心电图检查(1次)
- 处方药(3次)
单独看每一条记录,看不出什么。但打包成一个Episode,你就能看到:
✅ 这次心脏病治疗总共花了多少钱
✅ 治疗效果好不好(有没有再次急诊)
✅ 哪家医院、哪个医生治疗效果最好
这才是真正有价值的洞察。
SQL示例(简化版):
-- 构建就诊事件
WITH episode_groups AS (
SELECT
member_id, -- 患者ID
primary_diagnosis, -- 主要诊断
MIN(service_date) as episode_start, -- 事件开始
MAX(service_date) as episode_end, -- 事件结束
COUNT(*) as claim_count, -- 理赔次数
SUM(allowed_amount) as total_cost -- 总费用
FROM standardized_claims
WHERE service_date BETWEEN episode_start
AND episode_start + INTERVAL 30 DAY
GROUP BY member_id, primary_diagnosis
)
📊 第三步:生成洞察
数据清洗完了,现在要回答业务问题。
四大分析支柱
1️⃣ 使用率分析
- 识别高成本患者(Top 5%通常贡献50%的费用)
- 服务使用模式(哪些检查做得最多?)
- 网络外流失分析(患者为什么去竞争对手那里?)
2️⃣ 质量指标
- 再入院率(出院后30天内有多少人又住院?)
- 护理缺口识别(糖尿病患者该做HbA1c检测却没做)
- 医生绩效评分
3️⃣ 财务智能
- 成本趋势分析(哪些疾病成本在飙升?)
- 风险调整准确性
- 欺诈检测模式
4️⃣ 人群健康洞察
- 疾病流行率地图
- 社会决定因素影响(穷人区vs富人区的就医模式)
- 护理协调机会
💡 真实案例:急诊室滥用问题
这是我们做过的最成功的项目之一。
问题:某医疗集团发现急诊室费用暴涨,但不知道原因。
数据分析:
- 识别出每年去急诊5次以上的会员
- 发现这些人大多有慢性病(糖尿病、高血压)
- 根本原因:没有家庭医生,小病也去急诊
干预方案:
- 为这些高频用户配备专属护理协调员
- 安排定期家庭医生随访
- 提供24小时护士热线咨询
结果:
✅ 急诊使用率下降23%
✅ 节省医疗费用120万美元
✅ 患者满意度提升15%
这就是数据的力量。
🚀 第四步:产品化
分析报告做出来了,然后呢?
很多团队到这一步就停了。他们把Excel表格或者PPT发给领导,然后就没有然后了。
真正有价值的,是把洞察变成产品。
四种产品形态
1. 高管仪表盘 📊
- 核心KPI(关键指标)一目了然
- 支持下钻查看详情
- 每周自动更新
2. 运营报告 📋
- 每日/每周自动发送
- 为护理管理员提供可执行的患者名单
- 例如:"今天有12个高风险患者需要随访"
3. 预测模型 🤖
- 风险评分(哪些患者最可能再次住院?)
- 干预目标识别(应该优先管理谁?)
4. API和集成 🔌
- 实时洞察嵌入临床工作流
- 医生打开电子病历时,就能看到患者的风险评分
技术栈推荐
如果你要从零搭建,这是我推荐的工具组合:
📈 可视化:Power BI 或 Tableau(交互式仪表盘)
⚙️ API开发:Azure Functions(实时数据接口)
🤖 机器学习:Azure ML(预测建模)
🔗 系统集成:FHIR API(对接临床系统)
📈 第五步:衡量效果与迭代
最好的数据产品是活的,会不断进化。
关键成功指标
数据质量
完整性、准确性、及时性评分
用户采纳率
仪表盘使用率、报告打开率
业务影响
成本节省、质量改进、会员满意度
运营效率
从数据到洞察的时间、自动化工作流完成率
持续改进框架
📅 每月:数据质量审查,识别并修复问题
📅 每季度:用户反馈会议,增强产品功能
📅 每半年:刷新预测模型
📅 每年:战略审查,对齐业务目标
⚠️ 四个常见陷阱
很多项目死在这些地方,你一定要注意:
陷阱1:技术优先,业务靠边
❌ 错误做法:"我们用最新的AI技术,然后看能解决什么问题。"
✅ 正确做法:先明确业务问题,再选择技术方案。
陷阱2:完美数据瘫痪症
❌ 错误做法:"数据质量只有90%,我们不能上线。"
✅ 正确做法:80%的数据质量就可以先上线,然后迭代改进。
陷阱3:仪表盘过载
❌ 错误做法:一个仪表盘上有30个图表,看得眼花缭乱。
✅ 正确做法:聚焦3-5个驱动决策的核心指标。
陷阱4:忽视变革管理
❌ 错误做法:产品开发完就完了,用户爱用不用。
✅ 正确做法:大量投资于用户培训和推广计划。
记住:最好的数据产品,是让用户离不开的产品。
🔮 未来展望
医疗理赔分析的未来很exciting:
🚀 实时处理:秒级分析,立即干预
🤖 AI洞察:发现人类看不到的模式
🔗 数据整合:理赔+临床+社会数据融合
🎯 预测干预:在问题发生前就解决掉
✅ 你的行动计划
如果你也想把理赔数据变成洞察,这是你的5步行动计划:
第1步:审计现状
你现在能拿到哪些理赔数据?
第2步:明确问题
哪些业务决策需要数据支持?
第3步:搭建基础设施
建立Azure/云平台架构
第4步:小步快跑
选一个用例,先做好一个
第5步:衡量和迭代
从第一天就建立反馈循环
💬 写在最后
记住一句话:
目标不是完美的数据或炫酷的仪表盘,而是能改善患者结果和业务绩效的洞察。
数据只是手段,不是目的。
下一期,我们将深入探讨"如何搭建医疗数据仓库(Azure实战篇)",手把手教你技术实现细节。
你在处理理赔数据时遇到的最大挑战是什么?
欢迎在评论区告诉我,我们一起解决!
👇👇👇
如果这篇文章对你有帮助,欢迎点赞、转发、收藏三连!
这是"美国医疗AI实战"系列的第2篇,每周更新医疗数据和AI的实战干货,记得关注!