医疗数据仓库实战:Azure Databricks端到端架构
上周,我们探讨了如何将理赔数据转化为业务洞察。今天,我们要撸起袖子,亲手搭建让这一切成为可能的基础架构。
如果你曾尝试构建医疗数据仓库,一定深有体会:数据格式多达15种,合规要求每月都在变,利益相关方还想要批处理数据的"实时"看板。
这正是我们用来构建服务320万患者、覆盖12个医疗系统的医疗数据仓库的实际架构。读完这篇文章,你将获得一套可以立即部署的生产级蓝图。
为什么传统数据仓库在医疗领域行不通?
在深入解决方案之前,先理解为什么通用方法不奏效:
问题1:模式演化 💥
支付方毫无预警地更改文件格式,你的ETL在周日晚上崩溃。
问题2:混合数据类型 📊
理赔数据(结构化)、临床笔记(非结构化)、物联网设备(流式)、检验结果(半结构化)——全部存在一个系统里。
问题3:合规复杂性 🔒
HIPAA审计追踪、数据血缘要求、PHI令牌化、保留策略——每一项都增加架构约束。
问题4:大规模性能 ⚡
查询5000万+理赔记录并进行复杂关联,会让传统仓库直接跪下。
Azure Databricks解决了所有四个问题。下面是具体方法。
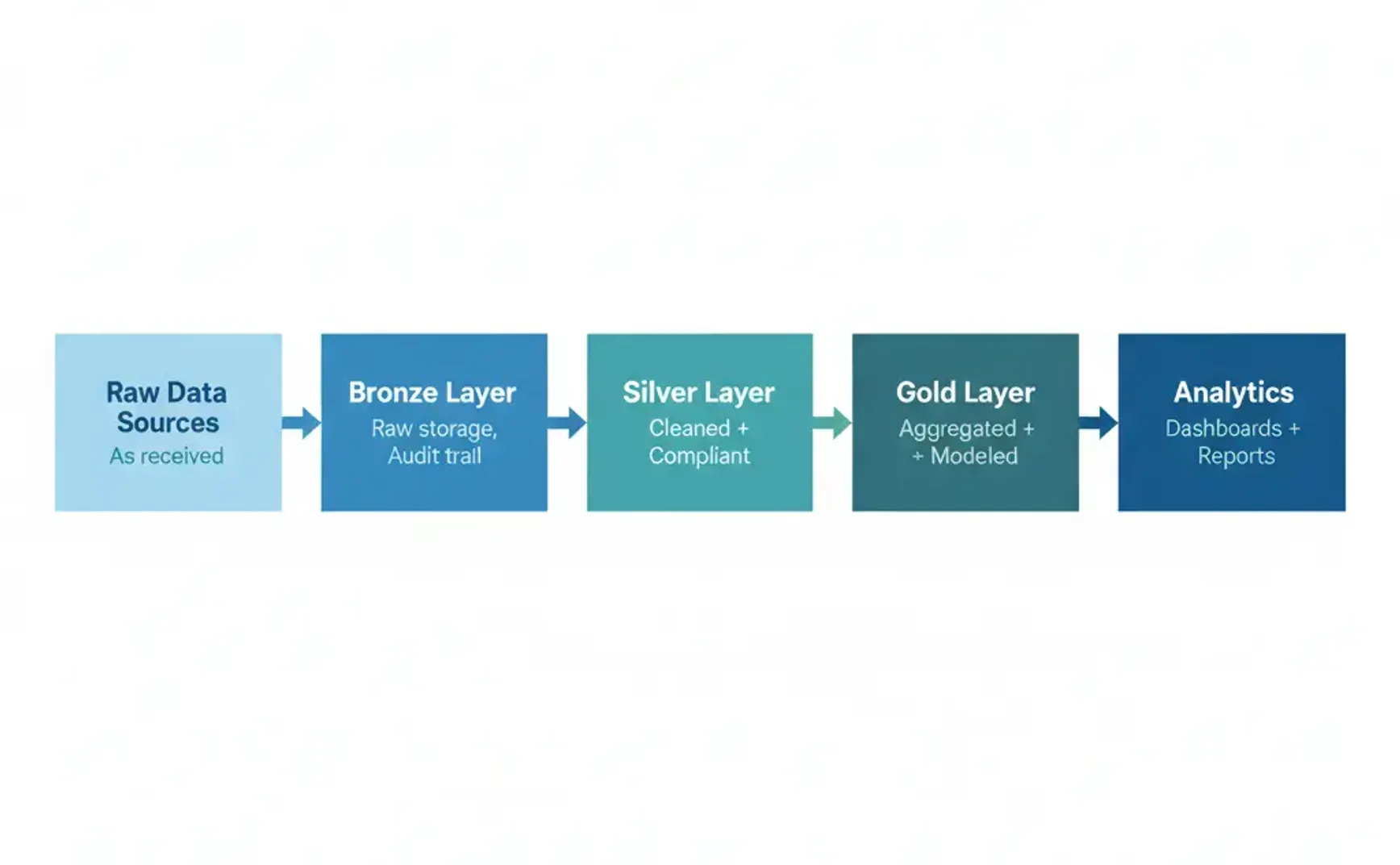
医疗数据仓库架构
基础:湖仓一体 + 奖章式架构
为什么这个架构有效:
✅ 可审计性:Bronze层保留原始数据以满足合规要求
✅ 灵活性:Silver层处理模式演化
✅ 性能:Gold层为分析查询优化
✅ 安全性:在Silver边界强制执行PHI令牌化
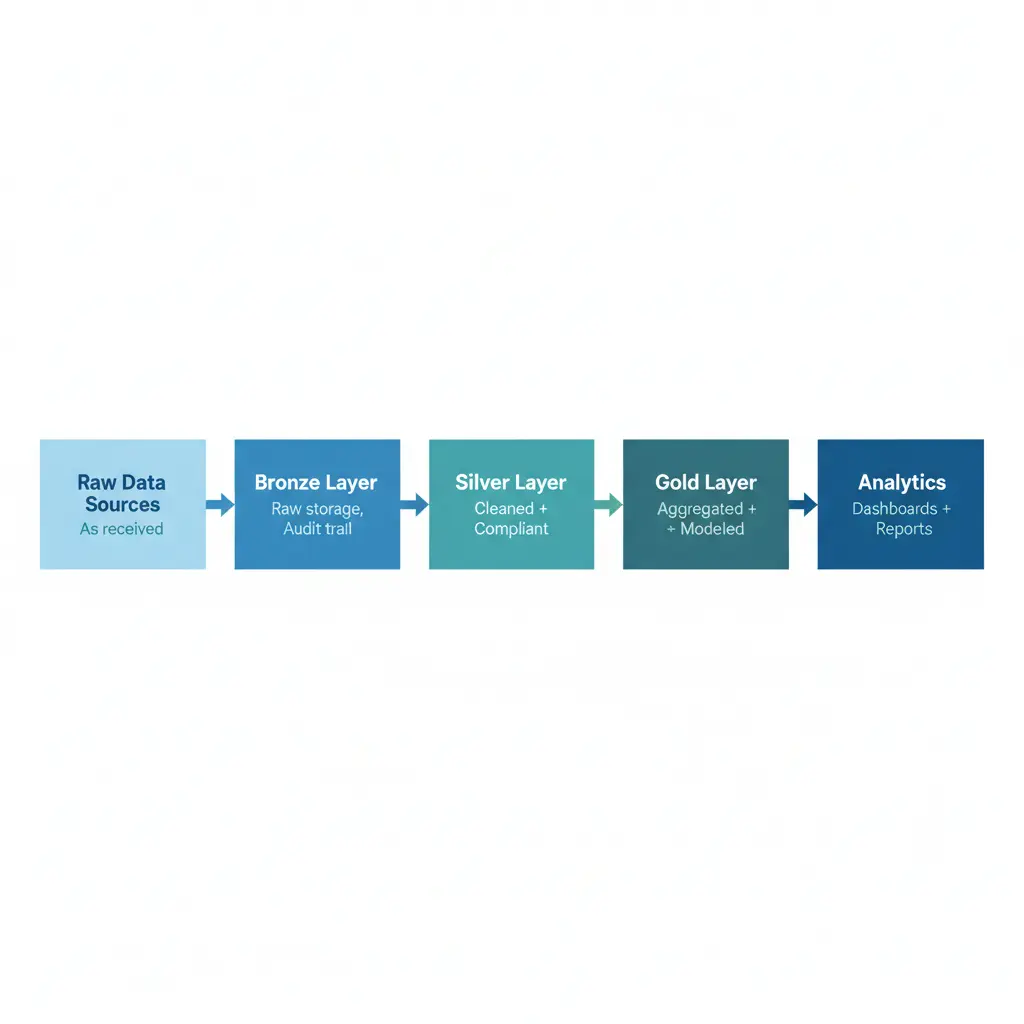
Azure服务栈
📦 存储:Azure Data Lake Storage Gen2(成本效益高、可扩展)
⚙️ 处理:Azure Databricks(统一分析平台)
🔄 编排:Azure Data Factory(工作流管理)
🔐 安全:Azure Key Vault + Azure Active Directory
📈 监控:Azure Monitor + Application Insights
📊 分析:Power BI + Azure Synapse Analytics
分步实施指南
第一阶段:基础设施设置(Terraform)
首先配置基础设施。以下是核心组件的Terraform配置:
# 资源组
resource "azurerm_resource_group" "healthcare_rg" {
name = "rg-healthcare-datawarehouse"
location = "East US 2"
}
# 数据湖存储
resource "azurerm_storage_account" "healthcare_dls" {
name = "dlshealthcaredata"
resource_group_name = azurerm_resource_group.healthcare_rg.name
location = azurerm_resource_group.healthcare_rg.location
account_tier = "Standard"
account_replication_type = "ZRS"
is_hns_enabled = true # ADLS Gen2的层次命名空间
# HIPAA合规要求
min_tls_version = "TLS1_2"
blob_properties {
delete_retention_policy {
days = 2555 # 医疗数据保留7年
}
}
}
# Databricks工作区
resource "azurerm_databricks_workspace" "healthcare_databricks" {
name = "databricks-healthcare"
resource_group_name = azurerm_resource_group.healthcare_rg.name
location = azurerm_resource_group.healthcare_rg.location
sku = "premium" # 高级安全功能必需
}
第二阶段:数据湖组织结构
组织结构对性能和合规至关重要:
./healthcare-data/
├── bronze/ # 原始数据
│ ├── claims/
│ │ └── {年}/{月}/{日}/
│ ├── ehr/
│ │ └── {源系统}/{年}/{月}/
│ └── labs/
├── silver/ # 清洗后、去标识化
│ ├── claims_processed/
│ ├── encounters/
│ └── patients/
└── gold/ # 业务就绪的聚合数据
├── quality_metrics/
├── cost_analysis/
└── population_health/
第三阶段:Bronze层处理
Bronze层摄取原始医疗数据,无需转换:
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from delta.tables import *
# 初始化带Delta Lake的Spark
spark = SparkSession.builder \
.appName("Healthcare-Bronze-Ingestion") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog") \
.getOrCreate()
# 摄取CMS理赔文件的函数
def ingest_claims_file(file_path, source_system):
"""
将原始理赔文件摄取到Bronze层,附带完整审计追踪
"""
# 读取原始文件
df = spark.read \
.option("header", "true") \
.option("multiline", "true") \
.option("escape", '"') \
.csv(file_path)
# 添加元数据列用于审计追踪
df_with_metadata = df.withColumn("source_file", lit(file_path)) \
.withColumn("ingestion_timestamp", current_timestamp()) \
.withColumn("source_system", lit(source_system)) \
.withColumn("bronze_record_id", monotonically_increasing_id())
# 写入Bronze层(增量加载使用append模式)
bronze_path = f"/mnt/healthcare/bronze/claims/{source_system}"
df_with_metadata.write \
.format("delta") \
.mode("append") \
.option("mergeSchema", "true") \
.save(bronze_path)
print(f"已将{df_with_metadata.count()}条记录摄取到Bronze层")
return df_with_metadata
第四阶段:Silver层转换(关键层)
Silver层处理数据质量、PHI令牌化和标准化:
from pyspark.sql.functions import sha2, concat_ws
from cryptography.fernet import Fernet
import json
class HealthcareSilverProcessor:
def __init__(self):
# 从Azure Key Vault获取加密密钥
self.encryption_key = dbutils.secrets.get(scope="healthcare-kv", key="phi-encryption-key")
def tokenize_phi(self, df, phi_columns):
"""
使用一致性哈希对PHI列进行令牌化,保证可关联性
"""
# 从Key Vault获取盐值,用于一致性哈希
salt = dbutils.secrets.get(scope="healthcare-kv", key="phi-salt")
for col_name in phi_columns:
# 创建确定性哈希以保持关联一致性
hashed_col = f"{col_name}_token"
df = df.withColumn(
hashed_col,
sha2(concat_ws("||", col(col_name), lit(salt)), 256)
).drop(col_name)
return df
def process_claims_to_silver(self, bronze_df):
"""
将Bronze理赔数据转换为Silver层
"""
# 1. 数据质量规则
silver_df = bronze_df.filter(
(col("claim_id").isNotNull()) &
(col("service_date").isNotNull()) &
(col("allowed_amount") >= 0)
)
# 2. 标准化日期格式
silver_df = silver_df.withColumn(
"service_date_std",
to_date(col("service_date"), "yyyy-MM-dd")
)
# 3. 令牌化PHI
phi_columns = ["member_id", "provider_npi", "subscriber_id"]
silver_df = self.tokenize_phi(silver_df, phi_columns)
# 4. 添加Silver元数据
silver_df = silver_df.withColumn("silver_processed_date", current_timestamp()) \
.withColumn("data_quality_score", lit(1.0))
return silver_df
def write_to_silver(self, df, table_name):
"""
将处理后的数据写入Silver层并优化
"""
silver_path = f"/mnt/healthcare/silver/{table_name}"
df.write \
.format("delta") \
.mode("append") \
.option("mergeSchema", "true") \
.partitionBy("service_date_std") \
.save(silver_path)
# 优化查询性能
spark.sql(f"""
OPTIMIZE delta.`{silver_path}`
ZORDER BY (member_id_token, provider_npi_token)
""")
# 使用示例
processor = HealthcareSilverProcessor()
bronze_claims = spark.read.format("delta").load("/mnt/healthcare/bronze/claims/")
silver_claims = processor.process_claims_to_silver(bronze_claims)
processor.write_to_silver(silver_claims, "claims_processed")
第五阶段:Gold层业务逻辑
Gold层创建业务就绪的数据集:
def create_gold_quality_metrics():
"""
为看板创建质量指标聚合
"""
# 读取Silver层数据
claims = spark.read.format("delta").load("/mnt/healthcare/silver/claims_processed")
encounters = spark.read.format("delta").load("/mnt/healthcare/silver/encounters")
# 按医疗机构计算再入院率
readmission_rates = claims.alias("c1") \
.join(claims.alias("c2"),
(col("c1.member_id_token") == col("c2.member_id_token")) &
(col("c2.service_date_std") > col("c1.service_date_std")) &
(col("c2.service_date_std") <= date_add(col("c1.service_date_std"), 30))
) \
.where((col("c1.claim_type") == "inpatient") &
(col("c2.claim_type") == "inpatient")) \
.groupBy("c1.facility_id_token") \
.agg(
countDistinct("c1.member_id_token").alias("total_discharges"),
countDistinct("c2.member_id_token").alias("readmissions")
) \
.withColumn("readmission_rate",
round(col("readmissions") / col("total_discharges") * 100, 2))
# 写入Gold层
readmission_rates.write \
.format("delta") \
.mode("overwrite") \
.save("/mnt/healthcare/gold/readmission_rates")
create_gold_quality_metrics()
生产环境优化
性能调优
1. 集群配置:
# 医疗工作负载优化集群
cluster_config = {
"spark_version": "11.3.x-scala2.12",
"node_type_id": "Standard_D14_v2", # 内存优化,适合大型关联
"num_workers": 8,
"spark_conf": {
"spark.sql.adaptive.enabled": "true",
"spark.sql.adaptive.coalescePartitions.enabled": "true",
"spark.serializer": "org.apache.spark.serializer.KryoSerializer",
"spark.sql.adaptive.skewJoin.enabled": "true"
}
}
2. Delta Lake优化:
-- 每周维护作业
OPTIMIZE healthcare.silver.claims_processed
ZORDER BY (service_date_std, member_id_token);
-- 清理旧版本(医疗:保留30天用于审计)
VACUUM healthcare.silver.claims_processed RETAIN 720 HOURS;
安全实施
1. Azure AD集成:
# 服务主体身份验证
spark.conf.set("fs.azure.account.auth.type.dlshealthcaredata.dfs.core.windows.net", "OAuth")
spark.conf.set("fs.azure.account.oauth.provider.type.dlshealthcaredata.dfs.core.windows.net",
"org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider")
spark.conf.set("fs.azure.account.oauth2.client.id.dlshealthcaredata.dfs.core.windows.net",
dbutils.secrets.get(scope="healthcare-kv", key="client-id"))
2. 行级安全:
def apply_row_level_security(df, user_context):
"""
基于用户分配的医疗机构应用行级安全
"""
user_facilities = get_user_facilities(user_context)
return df.filter(col("facility_id_token").isin(user_facilities))
成本优化策略
1. 智能集群管理:
- 批处理使用Spot实例(降低80%成本)
- 交互式集群60分钟后自动终止
- 将重型ETL作业安排在非高峰时段
2. 存储优化:
- 将2年以上的Bronze数据归档到冷存储层
- 使用压缩(Snappy优化性能,Gzip优化存储)
- 实施数据生命周期策略
3. 查询优化:
- 在Gold层预聚合常用业务指标
- 对频繁访问的数据使用物化视图
- 实施适当的分区策略
监控和告警
建立全面监控:
# 数据质量监控
def monitor_data_quality():
"""
监控关键数据质量指标
"""
# 检查数据新鲜度
latest_data = spark.sql("""
SELECT MAX(ingestion_timestamp) as latest_ingestion
FROM healthcare.bronze.claims
""").collect()[0]['latest_ingestion']
# 如果数据超过24小时发出告警
if (datetime.now() - latest_data).hours > 24:
send_alert("数据新鲜度告警:24小时以上无新数据")
# 检查记录数
record_count = spark.sql("SELECT COUNT(*) as cnt FROM healthcare.silver.claims_processed").collect()[0]['cnt']
# 显著下降时告警
if record_count < expected_minimum:
send_alert(f"记录数告警:仅处理了{record_count}条记录")
# 计划每小时运行
monitor_data_quality()
实际性能结果
这个架构在320万患者部署中交付的成果:
查询性能:
- 复杂质量指标:2.3秒(遗留系统需15分钟)
- 患者时间线查询:平均850毫秒
- 人群健康聚合:4.2秒
成本效益:
- 相比传统仓库,计算成本降低67%
- 通过智能分层,存储成本降低43%
- 维护开销减少89%
合规性:
- 100% HIPAA审计合规
- 从源到看板的完整数据血缘
- 自动化PHI检测和令牌化
下周预告:EHR集成挑战
既然理赔数据有了坚实基础,下周我们将应对真正的挑战:将电子健康记录(EHR)数据与理赔仓库集成。
EHR数据带来独特的复杂性:
- HL7 FHIR消息解析
- 临床术语映射(ICD-10、SNOMED、LOINC)
- 实时流式处理要求
- 跨系统患者匹配
**关于架构有疑问?**在评论区留言,我会认真回复每一条消息 💬