🆕 专题一 产品新功能/新版本
1. Kyverno 1.18 发布:CNCF 毕业后的首个版本,继续强化 Kubernetes 原生策略能力
Kyverno 1.18 发布:CNCF 毕业后的首个版本,继续强化 Kubernetes 原生策略能力
Kyverno 1.18 带来了以下更新:
- 面向基于 HTTP 的策略执行,提供更强的安全控制,并缓解多个 CVE 问题
- 大幅增强 CLI 能力,用于测试和应用现代策略类型
- 提升策略引擎在性能、可观测性和可扩展性方面的表现
- 增强 policies Helm chart,支持更灵活的自定义配置
- 本次发布没有破坏性变更,但 ClusterPolicy 的弃用计划仍在推进,用户应开始迁移到新的策略类型。
Kyverno 是一个 Kubernetes 原生策略引擎。可以帮助用户在 Kubernetes 环境中,通过策略(Policy)来实现配置管理、安全保障和自动化控制。
2. Traefik Proxy 3.7:使用 NGINX 作为入口网关的情况;不使用 NGINX 作为入口网关的情况
Traefik Proxy 3.7: Ingress NGINX, Without Ingress NGINX
产品/功能简介
Traefik Proxy 是一个开源云原生反向代理和 Kubernetes Ingress Controller。它负责把外部请求路由到集群内服务,并支持 TLS、负载均衡、中间件、Gateway API、服务发现和可观测性等能力。
Ingress NGINX 是 Kubernetes 生态中长期使用的 Ingress Controller。很多集群的 Ingress 资源依赖 NGINX annotations 来实现鉴权、重写、限流、header 注入、canary、custom error page 等行为。
核心变化
Traefik Proxy 3.7 的重点是:让 Traefik 能更像 Ingress NGINX 的直接替代品,减少迁移时重写 YAML 和转换 annotation 的成本。
Traefik Proxy 3.7 是一个偏迁移和生产可用性的版本,主要新增:
- 原生支持 85+ 个 Ingress NGINX annotations
- Ingress NGINX Provider 退出实验状态,成为正式能力
- Dashboard 新增 TLS certificates 视图
- 支持把 middleware 挂到 service 上
- 完整支持 Kubernetes Gateway API v1.5.1
- Retry 和 Failover 支持基于 HTTP 状态码触发
- 路由、TLS、可观测性、Web UI 等多个细节增强
适用场景
- 正在使用 Ingress NGINX,想迁移到 Traefik
- 需要保留已有 Ingress YAML 和 annotations
- 希望减少 annotation 转换和大规模 YAML 重写
- 需要更安全地处理 NGINX snippet 兼容
- 希望采用 Gateway API,但仍需要兼容现有 Ingress
- 需要更清晰的 TLS 证书可视化
- 需要基于 HTTP 状态码做重试、故障切换或蓝绿/主备路由
注意事项
- 虽然支持 85+ annotations,但仍需先审计现有 Ingress 使用了哪些 annotation
- Snippet 只支持 allowlist 中的安全指令,不是任意 NGINX 配置都能迁移
- 迁移前应使用官方 migration tool 做 inventory
- 建议先让 Traefik 与现有 Ingress NGINX 并行运行,再逐步切流
- Gateway API 和 Ingress Provider 的行为差异需要测试
- Retry 非幂等方法需要谨慎启用,避免重复提交、重复写入等副作用
- 生产升级前应查看 v3.7 release notes 和安全公告
3. etcd 3.7.0-beta.0 版本发布
etcd 是一个分布式、强一致的 key-value 数据库,是 Kubernetes 控制面的核心组件。Kubernetes API Server 会把集群状态保存到 etcd 中,例如 Pod、Node、ConfigMap、Secret、Deployment 等对象。因此,etcd 的性能、可靠性和升级兼容性会直接影响 Kubernetes 集群的稳定性。
SIG-etcd 发布了 etcd v3.7.0-beta.0,这是 etcd 3.7 的第一个 beta 版本。
这个版本的重点包括:
- 引入 RangeStream
- 移除 etcd v2store 残留组件
- 清理旧接口和实验性 flag
- 提升安全性和运维可靠性
- 改善大结果集查询体验
- 宣告 etcd 3.4 生命周期结束
该版本仍是 beta,目标是让用户测试并反馈问题,不建议直接用于关键生产环境。SIG-etcd 希望用户测试 v3.7.0-beta.0 并反馈问题。可通过以下渠道反馈:
- GitHub issues
- Kubernetes Slack 的
#SIG-etcd频道 - etcd-dev mailing list
后续可能还会发布更多 beta,特别是围绕 protobuf libraries 的重构。Release candidate 和最终版本预计会在 6 月到 7 月初之间推进。
注意事项
- 这是 beta 版本,不适合直接替换生产 etcd 集群。
- 使用前应先在测试环境验证数据备份、恢复、升级和回滚流程。
- 升级前检查是否依赖 v2 API、v2 client、旧 discovery/bootstrap 行为或 deprecated experimental flags。
- 仍在 etcd 3.4 的环境需要尽快规划升级路径。
- RangeStream 对大结果集有帮助,但客户端需要适配对应 gRPC 或 etcdctl 使用方式。
- Kubernetes 集群升级 etcd 时,应遵循发行版或托管平台的官方支持路径,避免手工替换导致控制面风险。
4. # Kubernetes v1.36 相关功能与素材总结
Kubernetes finally lands user namespace support, but shared kernel problem remains
Kubernetes v1.36: Pod-Level Resource Managers (Alpha)
Kubernetes v1.36: Admission Policies That Can't Be Deleted
Kubernetes v1.36: Declarative Validation Graduates to GA
Kubernetes v1.36: In-Place Vertical Scaling for Pod-Level Resources Graduates to Beta
Kubernetes v1.36: Server-Side Sharded List and Watch
Kubernetes v1.36: More Drivers, New Features, and the Next Era of DRA
Kubernetes v1.36: Moving Volume Group Snapshots to GA
Kubernetes v1.36: Advancing Workload-Aware Scheduling
Kubernetes v1.36: PSI Metrics for Kubernetes Graduates to GA
Kubernetes v1.36: Deprecation and removal of Service ExternalIPs
Kubernetes v1.36: New Metric for Route Sync in the Cloud Controller Manager
Kubernetes v1.36: Mixed Version Proxy Graduates to Beta
Simplify static hosting by using an OCI image as Volume in Kubernetes 1.36
Reconciling the Past: Correcting Records for Unfixed Kubernetes CVEs
Kubernetes CPU requests and limits, explained through cgroups
用户命名空间支持
Kubernetes v1.36 使 Pod 用户命名空间能力进入稳定阶段。它的目标是把容器内的 root 用户映射为宿主机上的非特权 UID/GID,从而降低容器进程突破隔离后直接以宿主机 root 身份行动的风险。The New Stack 文章把它称为 Kubernetes 安全基线的一个重要进步,但同时提醒不要把它误解为完整的隔离边界。
它的机制是:当 Pod 设置 hostUsers: false 时,容器内的 root 用户,也就是 UID 0,会被映射成宿主机上的非特权用户。这样即使容器里的进程认为自己是 root,从宿主机内核视角看也不是宿主机 root;CAP_NET_ADMIN 等能力也会被限制在容器命名空间内,而不是直接作用于宿主机。
这个能力可以缓解一类容器逃逸和权限提升问题,也让 Pod 之间的横向移动更困难,尤其是在每个 Pod 的 UID/GID 映射到宿主机上不重叠范围时。对多租户集群、运行不完全可信镜像的环境、以及仍有应用依赖容器内 root 语义的场景,它是实用的纵深防御层。
但 The New Stack 文章的主要批评是:用户命名空间只重映射身份,不隔离内核。无论是否启用 hostUsers: false,同一节点上的容器仍然共享同一个 Linux kernel。内核负责 syscall、内存、网络、设备和调度;如果攻击者利用的是内核漏洞,那么攻击发生在用户命名空间保护层之下,UID 重映射无法阻止这类路径。
文章还强调,用户命名空间有时会让原本需要特权的内核功能通过 namespace 抽象暴露给非特权 workload,因此它经常出现在现代内核漏洞利用链中。它不直接制造漏洞,但可能让已有漏洞更容易被触达。
因此,用户命名空间适合被理解为“降低部分容器逃逸后果”的能力,而不是“解决 Kubernetes 多租户隔离”的最终方案。对于云服务商、AI 平台、SaaS 多租户、不可信代码执行和强监管环境,文章认为真正改变威胁模型需要把隔离边界移动到内核之下,例如通过硬件虚拟化或每个 workload 独立内核的架构来避免共享内核成为共同失效点。
Pod 级资源管理器
Pod-Level Resource Managers 在 v1.36 进入 Alpha。它面向的问题是:Kubernetes 过去主要以容器为单位声明 CPU、内存等资源,但很多真实应用更接近一个 Pod 级工作负载,多个容器之间存在协作和资源共享关系。
该功能允许在 Pod 层面管理资源,使平台可以更自然地表达“整个 Pod 的资源预算”。这有助于 sidecar、辅助容器、主业务容器共享资源池,避免每个容器都必须提前精确拆分资源额度。
它背后的变化是资源管理边界从“每个容器独立算账”扩展到“Pod 内部整体协调”。在服务网格、日志采集、代理 sidecar、模型服务辅助进程等场景中,辅助容器的资源需求往往依赖主容器行为,提前为每个容器单独设置精确 request/limit 既困难,也容易造成资源碎片。
Pod 级资源管理器提供的是更贴近 workload 的抽象:平台可以先定义整个 Pod 可用资源,再由 Pod 内部组件共享和竞争。这对平台团队尤其有用,因为调度器、kubelet 和资源控制机制可以围绕 Pod 这个最小调度单位形成更一致的资源视图。
它与 Pod 级别原地垂直扩缩容、Memory QoS、CPU cgroup 语义等内容有明显关联:资源管理正在从单个容器的静态声明,逐渐转向 Pod 维度、更动态、也更贴近业务工作负载的控制方式。
由于该能力仍为 Alpha,适合试验和评估,不适合在关键生产路径中默认依赖。落地时需要重点观察三个方面:调度结果是否符合预期、Pod 内多个容器之间是否出现非预期资源争抢、现有监控和成本分摊系统是否能正确理解 Pod 级资源口径。
Pod 级资源的原地垂直扩缩容
In-Place Vertical Scaling for Pod-Level Resources 在 v1.36 升级到 Beta。它允许在不重建 Pod 的情况下调整 Pod 级资源配置,降低传统垂直扩缩容中“修改资源后必须重启 Pod”的代价。
这类能力的价值在于减少应用中断。过去,如果工作负载资源估算不准,调整 CPU 或内存通常意味着重新调度或重启,可能带来连接中断、缓存丢失、启动时间和副本抖动。原地调整可以让平台更细粒度地响应负载变化。
对长生命周期服务来说,它可以把资源调优从一次性的部署决策变成运行期操作。例如服务在流量高峰需要更多 CPU,或 Java/数据库类 workload 需要在稳定运行后修正内存预算时,平台可以减少“删 Pod 再建 Pod”的破坏性动作。
它对自动化系统也有价值。VPA、平台控制器或内部容量管理系统可以更自然地把观测结果转化为资源调整,而不是每次调整都触发完整重建。这样可以降低扩缩容动作本身对 SLO 的影响。
结合 Pod-Level Resource Managers,这代表 Kubernetes 资源模型正在向“Pod 是资源管理基本单元”的方向增强。它尤其适合 sidecar-heavy 应用、批处理任务、AI/ML 辅助组件以及资源需求随时间变化的服务。
需要注意的是,原地调整并不等同于无限制实时变更。应用本身是否能感知并适应新的资源上限、运行时是否会重新计算线程池或堆大小、节点上是否仍有足够可分配资源,都会影响实际效果。生产使用时应先验证目标 workload 对 CPU 和内存变更的响应方式。
Memory QoS 与分层内存保护
Memory QoS 关注的是内存资源不只需要硬限制,还需要表达不同优先级的保护关系。v1.36 相关内容强调借助 cgroups v2 能力实现分层内存保护,例如 memory.min、memory.low、memory.high 和 memory.max 等语义。
这类机制可以把 Kubernetes 的 requests、limits、QoS class 与底层 cgroup 内存控制更紧密地连接起来。相比只在达到 limit 后 OOM kill,Memory QoS 更强调提前施加压力、保护关键工作负载、并让低优先级工作负载更早承担回收成本。
它解决的是 Kubernetes 内存管理中长期存在的“反应过晚”问题。传统 limit 更像最后一道硬墙,进程真正撞上时往往已经进入 OOM 路径;而 memory.high 这类机制可以更早触发回收和节流,让内存压力以更渐进的方式暴露出来。
分层保护也能把业务优先级表达得更清楚。关键服务、系统组件或 Guaranteed Pod 可以获得更强保护;临时任务、批处理或 BestEffort Pod 在节点压力升高时更早让出内存。这比单纯依赖 OOM killer 的结果更可预测。
实际意义是,集群在内存紧张时可以更稳定:关键 Pod 不容易被随机挤压,Burstable 或 BestEffort 工作负载更符合预期地让出资源。它也和 PSI 指标形成互补,一个负责控制和保护,一个负责观测压力。
落地时需要确认节点使用 cgroups v2,并重新审视 requests/limits 的含义。过去随意填写 request 的集群,在 Memory QoS 下可能会把错误的资源声明转化为错误的保护策略,因此资源画像和容量治理会变得更重要。
CPU requests、limits 与 cgroups
CPU requests 和 limits 最终都会落到底层 cgroups 机制。requests 通常用于调度和权重分配,limits 则用于设置 CPU quota。理解这一层有助于解释为什么 CPU limit 可能导致 throttling,而 request 更像是调度和相对权重信号。
在 cgroups v2 中,CPU 权重、配额和统计接口比 v1 更统一。Kubernetes 的资源声明不是抽象地停留在 API 层,而是被 kubelet 和运行时转化为内核可执行的控制文件。
这类材料的重点是提醒使用者:CPU limit 不是“性能保证”,而是“使用上限”;设置过低可能导致延迟增加。request 也不是硬隔离,而是在资源竞争和调度时表达需求。
实际调优时,一个常见误区是给所有服务都设置较低 CPU limit,以为这样能提高公平性。但对延迟敏感服务而言,CPU quota 触发 throttling 后,即使节点还有空闲 CPU,进程也可能被限制运行,表现为 p99 延迟升高或吞吐抖动。
更稳妥的做法通常是把 request 作为容量规划和调度的主要依据,对真正需要硬上限的 workload 再设置 limit。批处理、后台任务和多租户环境可能更需要 limit;核心在线服务则需要结合 throttling 指标、CPU 使用曲线和 SLO 结果谨慎设置。
PSI 指标 GA
PSI Metrics for Kubernetes 在 v1.36 进入 GA。PSI 即 Pressure Stall Information,用来观测任务因为 CPU、内存或 I/O 资源不足而停顿的时间比例。
传统指标通常告诉你资源“用了多少”,例如 CPU 使用率、内存占用、I/O 吞吐。PSI 更进一步,告诉你 workload 是否已经因为资源不足而“等住了”。这对定位尾延迟、内存回收压力、I/O 堵塞等问题更直接。
PSI 的关键价值在于补足“利用率不等于体验”的盲区。一个节点 CPU 使用率可能没有满,但某些 Pod 仍可能因为调度等待、内存回收或 I/O 拥塞出现明显停顿。PSI 直接衡量等待时间,更接近应用实际感受到的资源压力。
PSI 与 Memory QoS、Pod 级资源管理、调度改进可以组合使用:先通过 PSI 发现压力,再通过资源策略、调度或扩缩容调整工作负载。它让资源管理从“事后看 OOM 或 throttling”前移到“提前识别压力趋势”。
在运维实践中,PSI 适合进入告警和容量分析链路。比如 memory PSI 持续升高但 OOM 尚未发生,可能说明节点正在频繁回收;io PSI 升高可能说明存储层已经成为瓶颈;cpu PSI 升高则可能提示 CPU 竞争影响了任务推进。
DRA:更多驱动、新特性与下一代资源分配
DRA,即 Dynamic Resource Allocation,是 Kubernetes 面向 GPU、DPU、FPGA、AI 加速器和其他特殊硬件的资源分配框架。v1.36 的文章强调更多驱动程序、新特性和下一阶段演进。
传统 extended resources 更适合简单计数型资源,例如 “需要 1 块 GPU”。但现代加速器资源越来越复杂,可能涉及拓扑、分区、共享、设备初始化、驱动状态、NUMA 亲和性和工作负载特定约束。DRA 的目标是让设备供应商和平台能够用更结构化的方式声明、分配和准备这些资源。
随着 AI/ML workload 增多,资源不再只是 CPU 和内存。GPU 可能有 MIG 分区、共享模式、驱动版本、互联拓扑和内存容量差异;DPU 和其他设备还可能需要初始化、绑定、固件或网络配置。DRA 的意义是把这些复杂性纳入 Kubernetes 原生调度和资源生命周期中。
它和工作负载感知调度关系密切:调度器不仅要知道节点有没有某类资源,还要知道资源是否适合某个工作负载、是否满足拓扑和性能约束。对 AI/ML、HPC 和硬件加速平台来说,这是 Kubernetes 从“通用容器编排”走向“异构资源编排”的关键方向。
对平台团队而言,DRA 的采用通常依赖硬件厂商或基础设施团队提供驱动和资源类定义。评估时需要关注资源分配是否可观测、失败时是否能清晰回滚、以及与现有 device plugin、调度策略和配额体系的关系。
工作负载感知调度
Workload-Aware Scheduling 关注的是调度器如何理解更高层的工作负载需求,而不仅是单个 Pod 的静态资源请求。v1.36 的相关内容强调 Kubernetes 正在改进对批处理、AI/ML、队列化任务、Gang scheduling 相关场景的支持。
这类能力背后的问题是:有些工作负载不是一个 Pod 能独立完成,而是一组 Pod 必须同时获得足够资源才有意义。例如分布式训练任务,如果只启动了一部分 worker,资源可能被占住但任务无法推进。
传统 Kubernetes 调度以 Pod 为中心,这对无状态服务很有效,但对 Job、分布式训练、批处理队列和大规模数据任务并不总是最优。这些任务更关心“整个工作负载是否能按时启动和完成”,而不是某一个 Pod 是否能尽快落到某个节点上。
工作负载感知调度会与 DRA、Pod 级资源、资源队列和调度插件生态结合,帮助集群更好地处理“整体任务”而非孤立 Pod。它的价值不只是提高利用率,也包括避免无效调度、减少资源碎片、提升大型任务启动成功率。
在 AI 训练场景中,这类能力尤其关键。一个训练任务可能要求多个 GPU、节点间低延迟网络和一组 worker 同时就绪;如果调度器不能理解这些整体约束,就可能出现资源被部分占用但任务无法推进的情况。
Server-Side Sharded List and Watch
Server-Side Sharded List and Watch 面向的是大规模集群中 API Server 的列表与 watch 压力。Kubernetes 控制器、客户端和平台组件大量依赖 list/watch 机制;当对象数量很大时,单次 list 或 watch 可能对 API Server、etcd 和网络造成明显压力。
该功能通过服务端分片方式改进 list/watch 的扩展性,让大规模对象集合可以更高效地被读取和监听。它主要服务于集群规模扩大后的控制面稳定性。
在大型集群中,控制器重启、缓存重建、全量 list 和大量 watch 连接都可能造成控制面突发压力。对象规模越大,单次列表操作越容易成为 API Server 和 etcd 的热点,进而影响其他关键控制循环。
这类改进对普通应用开发者不一定直接可见,但对超大集群、多控制器平台、托管 Kubernetes 服务和高对象数量场景很重要。它减少了控制面热点和长尾延迟风险。
它的实际收益通常体现在稳定性和可扩展性上:控制器恢复更平滑,API Server 在高对象数量下更不容易被少数大请求拖慢,平台也能支持更多 namespace、Pod、CRD 对象和自定义控制器。
Manifest-Based Admission Control:不能被删除的准入策略
Admission Policies That Can't Be Deleted 介绍的是基于 manifest 的准入控制能力。它解决的问题是:如果某些安全策略本身以普通 Kubernetes 资源形式存在,那么拥有足够权限的用户可能删除或修改这些策略,从而绕过约束。
该机制让集群管理员可以把关键准入策略以更底层、更难被集群内用户删除的方式声明出来。适合用于强制基线安全要求,例如禁止特权容器、限制 hostPath、要求镜像来源、限制危险 capability 等。
这类策略的核心价值是“策略不能被同一套普通集群权限轻易移除”。在多团队共享集群里,RBAC 配置复杂,某些管理员或自动化系统可能拥有修改 admission policy 相关资源的权限。如果安全基线也只是普通对象,就存在被误删、被覆盖或被有意绕过的风险。
它的意义在于把准入控制从“可被集群内对象生命周期影响的策略”提升为更接近集群配置基线的一部分。对多租户和平台团队而言,这降低了策略被误删或恶意删除的风险。
适用场景包括平台强制合规策略、托管 Kubernetes 的默认安全约束、以及企业内部集群的不可变基线。它不替代审计和 RBAC,但能把关键策略从“运行时对象”提升为更接近“集群启动配置”的层级。
声明式验证 GA
Declarative Validation 在 v1.36 正式 GA。它的目标是让 Kubernetes API 的字段校验逻辑更声明式、更接近 API 类型定义本身,而不是大量依赖手写校验代码。
这有助于提升 API 一致性和可维护性。过去,字段校验分散在代码中,容易出现重复、遗漏或不同路径行为不一致。声明式验证把校验规则靠近 API schema,减少实现偏差。
对 Kubernetes 项目本身来说,这是一项工程质量改进。API 行为越复杂,手写校验越容易出现不同版本、不同字段、不同更新路径之间的不一致。声明式验证让规则更容易审查、测试和生成,也有助于减少维护成本。
对用户来说,它通常表现为更一致的错误提示和更可靠的 API 行为。对 Kubernetes 开发者和扩展 API 的生态来说,它降低了维护复杂度,也让后续 API 演进更稳。
它的影响不一定像新资源类型那样显眼,但属于长期收益很高的基础设施改进。API 校验越可靠,客户端、控制器和 GitOps 工具越容易依赖 Kubernetes 的行为稳定性。
细粒度 kubelet API 鉴权 GA
细粒度 kubelet API 鉴权在 v1.36 GA。kubelet 暴露多个与节点、Pod、日志、exec、metrics 等相关的 API,过去授权粒度较粗时,授予某类访问可能附带过多能力。
细粒度鉴权把不同 kubelet API 操作拆得更清楚,使集群管理员能按最小权限原则授权。例如允许读取某些状态信息,不一定允许执行命令或访问更敏感的节点接口。
这项改进的背景是 kubelet API 位于节点安全边界上,权限过大时风险很高。读取日志、获取 Pod 信息、执行命令、访问指标、查看节点状态,这些动作的敏感程度并不相同,粗粒度授权会让一些只需要观测能力的组件获得过多权限。
这项能力增强了节点层面的安全边界,尤其适合多租户集群、托管平台和安全合规要求较高的环境。它与用户命名空间、准入策略、Pod Security 等共同构成 Kubernetes v1.36 安全增强的一部分。
实际使用时,应重新盘点依赖 kubelet API 的监控、日志、诊断和运维工具,把它们的权限收敛到所需接口。这样即使某个工具或凭据泄露,也能减少对节点和 Pod 的影响范围。
Volume Group Snapshot GA
Volume Group Snapshot 在 v1.36 进入 GA。它允许对一组卷执行一致性快照,而不是只对单个 PVC 单独快照。
这对有状态应用很重要。数据库、中间件和分布式系统可能同时使用多个卷,如果这些卷的快照时间点不一致,恢复后可能出现数据不一致。卷组快照提供了更适合多卷应用的备份和恢复语义。
典型例子是一个数据库实例把数据文件、日志文件和配置或索引放在不同卷中。单独快照每个卷时,即使时间差很小,也可能造成恢复点不一致。卷组快照让这些卷以一个逻辑组被捕获,更接近应用一致性备份的需求。
该能力依赖底层 CSI 驱动支持。对平台团队而言,需要确认存储驱动是否实现相关能力,并把它纳入备份、灾备和恢复演练流程。
需要注意的是,卷组快照提供的是 Kubernetes 和存储层面的能力,应用层一致性仍然可能需要配合冻结写入、flush、事务日志或备份钩子。生产恢复流程不能只验证“快照能创建”,还要验证“从快照恢复后的应用能正确启动并保持数据一致”。
OCI Image Volume 与静态托管
社区素材提到在 Kubernetes 1.36 中使用 OCI image 作为 Volume 来简化静态托管。核心思路是把静态文件打包成 OCI 镜像,然后作为只读卷挂载到 Pod 中,而不是额外构建带 Web Server 和内容的完整镜像,或通过 ConfigMap/对象存储等方式分发内容。
这种方式适合静态站点、文档、前端构建产物、规则包、模型配置或其他只读内容分发。它复用了 OCI registry 的版本管理、签名、分发和缓存能力。
它的优势在于把内容分发纳入已有镜像供应链。静态内容可以像应用镜像一样被构建、扫描、签名、推送和回滚;部署时只需要声明镜像卷,运行容器可以保持更通用。例如一个 Nginx 或 Caddy 容器挂载不同 OCI image volume,就能服务不同版本的静态内容。
需要注意的是,它更适合只读内容,不适合频繁写入或运行时动态生成内容。实际采用时还需要评估镜像体积、拉取策略、节点缓存和供应链安全。
与 ConfigMap 相比,它更适合较大或版本化的静态产物;与对象存储相比,它更贴近 Kubernetes 部署和镜像治理流程。但如果内容需要跨区域 CDN、频繁增量更新或面向公网大规模分发,对象存储和 CDN 仍可能更合适。
Service ExternalIPs 弃用与移除
Kubernetes v1.36 宣布 Service ExternalIPs 的弃用和移除路径。ExternalIPs 允许用户在 Service 中声明外部 IP,但它长期存在安全和治理问题:普通用户可能声明并不属于自己的 IP,从而造成流量劫持或网络策略绕过风险。
这项变化说明 Kubernetes 正在收紧一些历史遗留、边界模糊的网络能力。平台应逐步迁移到更明确受控的入口方案,例如 LoadBalancer、Ingress、Gateway API 或云厂商/网络插件提供的专用机制。
对集群管理员而言,重点是审计现有 Service 是否使用 ExternalIPs,识别依赖路径,并制定替代方案。对多租户环境,这一变化尤其重要。
迁移时需要区分使用 ExternalIPs 的真实目的:如果是暴露 HTTP/HTTPS 服务,通常应迁移到 Ingress 或 Gateway API;如果是云负载均衡入口,应使用 type: LoadBalancer;如果是裸金属环境,需要评估 MetalLB 或网络插件提供的受控地址分配方案。
安全治理上,建议先通过审计和准入策略禁止新建高风险 ExternalIPs,再为存量服务制定迁移窗口。直接删除可能影响生产流量,因此更适合分阶段治理。
Cloud Controller Manager 路由同步指标
v1.36 为 Cloud Controller Manager 增加路由同步相关新指标,用于观测 route sync 行为。该指标帮助平台团队判断云路由同步是否成功、是否出现错误或延迟。
云环境中的 Kubernetes 依赖 CCM 与底层云网络交互。路由同步异常可能影响 Pod 跨节点通信、节点加入/删除后的网络收敛,以及集群可用性。
这个功能属于可观测性增强,主要面向平台运维和云厂商集成。它本身不改变调度或网络行为,但能更快暴露网络控制面问题。
它的价值在故障定位时更明显。过去当节点路由没有正确下发时,症状可能表现为 Pod 网络不通、跨节点流量失败或节点变更后网络迟迟不收敛,但根因分散在云 API、CCM 日志和网络状态中。新的同步指标可以让平台更早发现 route sync 是否异常。
对托管 Kubernetes 或自建云环境,建议把该指标纳入 CCM 监控面板,并与节点生命周期事件、云 API 错误率、网络插件指标一起分析。
Mixed Version Proxy Beta
Mixed Version Proxy 在 v1.36 升级到 Beta。它面向的是 Kubernetes 控制面滚动升级期间,不同 API Server 版本共存时的请求兼容和转发问题。
在大型集群中,升级控制面不是瞬间完成的。不同版本 API Server 同时存在时,客户端请求可能命中尚不支持某资源或某版本能力的 API Server。Mixed Version Proxy 通过代理转发改善这种混合版本阶段的可用性。
它的价值在于降低升级过程中的 API 不一致和客户端失败概率,使控制面升级更平滑。对托管服务、大规模生产集群和频繁升级的环境尤其有意义。
这项能力解决的是升级窗口中的现实问题:客户端通常只看到一个 Kubernetes API 入口,但背后可能有多个不同版本的 API Server。若某个请求需要由较新版本处理,而负载均衡把它送到旧版本实例,就可能出现短暂失败。Mixed Version Proxy 通过转发机制减少这类版本偏差带来的影响。
它不能替代正常的升级规划。API deprecation、CRD 兼容性、webhook 兼容性和客户端版本仍然需要提前验证;但它可以降低控制面滚动升级过程中的偶发请求失败。
Kubernetes CVE 记录纠偏
Reconciling the Past: Correcting Records for Unfixed Kubernetes CVEs 讨论的是 Kubernetes 项目如何纠正历史上“未修复 CVE”记录中的问题。它不是一个运行时功能,而是安全治理和漏洞记录维护方面的改进。
这类工作的重要性在于:安全扫描器、合规平台和用户风险评估都依赖 CVE 元数据。如果历史记录不准确,可能导致误报、漏报或错误的修复优先级。
文章体现的是 Kubernetes 安全响应流程的成熟化:不仅发布补丁,也维护漏洞状态、影响范围和历史记录的准确性。对企业用户来说,这能提升基于 CVE 的治理可信度。
对企业安全团队而言,这类纠偏会影响漏洞管理看板和合规报告。某些扫描结果可能因为历史 CVE 状态修正而发生变化,因此不能只看扫描器给出的“是否存在 CVE”,还要结合 Kubernetes 项目官方公告、受影响版本、修复版本和实际组件暴露面判断风险。
它也提醒平台团队:Kubernetes 安全治理不只是升级集群,还包括维护准确的软件物料清单、跟踪 CVE 数据源变化、理解漏洞是否真正影响当前部署方式,并把误报和已修复记录及时反馈到内部风险系统。
5. VCF 9.1 相关文章汇总
VMware Cloud Foundation 9.1 相关功能与素材总结
素材链接
Avi Innovations for VCF 9.1: Powering Kubernetes, Agentic AI and VPC Workloads
VCF 9.1: The Secure, Cost-Effective Private Cloud Platform for Production AI
Announcing VCF 9.1: Modern Private Cloud Built for Efficiency and Resilience
Announcing VMware Cloud Foundation Edge 9.1: A Scalable, Autonomous Edge Platform
Accelerate, Streamline, and Control Your Self-Service Private Cloud with VMware Cloud Foundation 9.1
Deploy Modern Apps Faster, Scale Smarter, and Lower Your TCO with VMware vSphere Kubernetes Service in VCF 9.1
Scale Smarter, Save More: Redefining Infrastructure Economics with VMware vSphere in VCF 9.1
AI with VCF 9.1 on AMD GPUs: Build with open frameworks and simplify management, at a lower TCO
Streamline, Simplify and Protect all your AI workloads with VCF 9.1
Simplify Workload Connectivity and Enhance Network Scale and Performance with VCF 9.1
VCF 9.1 Is Here. See It in Action.
The New Frontier: Leading the Cloud-Native Evolution
博通發布 VMware Cloud Foundation 9.1
Modernizing Your Infrastructure: Introducing VMware Cloud Foundation 9.1 to VCSPs
VCF 9.1 is Available: Explore the New Features in Hands-on Labs
What’s New with vSphere in VMware Cloud Foundation 9.1?
Resizing VMware vCenter in VMware Cloud Foundation 9
Non-Disruptive VMware vCenter Patching in VMware Cloud Foundation 9.1
VMware vCenter Virtual Hardware Gets an Upgrade in vSphere with VCF 9.1
Maximizing Profitability: VCF 9.1 Cost-Focused Approach for VMware Cloud Service Providers
VMware vSAN Protection and Recovery Enhancements for VCF 9.1
Deliver Production SQL Server DBaaS with VMware Data Services Manager 9.1
VCF Networking 9.1: Simpler VPC Connectivity Control
VCF Networking 9.1: Exploring Network Services for Virtual Private Clouds
VCF Networking 9.1: Seamless DDI Integration with Infoblox
Expand Shared VMDKs with Clustered Applications in VMware vSAN for VCF 9.1
Monetizing Zero-Trust Security with VCF 9.1 and VMware vDefend
VCF 9.1 Licensing: Programmatic, Centralized, and Built to Scale
More Memory, Less Effort: Configuring Memory Tiering in VCF 9.1
VCF Breakroom Chats Episode 85 - Cloning Success at Scale: Inside VCF 9.1’s App Stack Formation
Securing Your VCF 9.1 Infrastructure with the Symantec Identity Security Platform
Smarter Patching at Scale: Vulnerability Assessment and Remediation with VMware Tanzu Platform
Announcing the VMware Cloud Foundation 9.1 Upgrade Planning Tool
Modernizing the Private Cloud: Why VCF 9.1 Lifecycle Management is a Game Changer
Mastering Infrastructure Policies in VMware Cloud Foundation Automation 9.1
产品/功能简介
VMware Cloud Foundation, VCF,是 VMware 面向私有云和混合云的数据中心平台,整合计算、存储、网络、安全、自动化、运维和应用服务能力。VCF 9.1 的发布重点不是单个组件升级,而是把虚拟机、Kubernetes、AI、数据库、边缘站点、多租户 VPC 和服务商场景纳入一套更统一的私有云运营模型。
这一批文章可以理解为 VCF 9.1 的分主题发布说明。核心产品域包括:
vSphere:计算虚拟化、vCenter、ESX 生命周期、vMotion、内存分层、硬件加速和虚拟机运行能力。vSAN:存储、快照、复制、灾备、勒索恢复和有状态应用支持。VCF Networking / NSX:VPC、自服务网络、VPC 间连接策略、NAT、VPN、负载均衡、DDI/IPAM 集成。VKS:VMware vSphere Kubernetes Service,用于在 VCF 上提供 Kubernetes 集群服务。Avi Load Balancer:应用交付、L4/L7 负载均衡、TLS、WAF、Kubernetes 和 VPC workload 入口。VCF Automation:自服务资源申请、基础设施策略、应用栈模板和平台工程能力。VCF Operations:可观测性、容量、成本、合规和运行状态分析。VCF Edge:面向边缘站点的自治运行、零接触部署和离线环境管理。DSM:VMware Data Services Manager,用于数据库即服务,VCF 9.1 中强化 SQL Server 生产支持。
VCF 9.1 的主线是:在企业继续保留私有云控制权、数据位置和安全边界的同时,提供更接近公有云的自服务、自动化、弹性和多租户体验。
VCF 9.1 总体发布定位
VCF 9.1 面向的主要矛盾是:企业基础设施复杂度持续上升,但预算、人力和变更窗口没有同步增长。与此同时,企业还需要承载 AI、Kubernetes、数据库、边缘应用和传统 VM,并满足合规、数据主权和安全韧性要求。
VCF 9.1 围绕三类目标展开:
- 效率:提高已有硬件利用率,减少新增服务器、DRAM 和存储采购压力。
- 应用交付:让 VM、Kubernetes、容器、对象存储、数据库和 AI workload 通过统一平台交付。
- 安全韧性:把合规、补丁、灾备、勒索恢复、身份和 zero-trust 能力嵌入平台生命周期。
总体发布文章中提到的关键能力包括 Enhanced NVMe Memory Tiering、vSAN 全局去重和增强压缩、vSphere Elastic Provisioning、VKS 扩展到每个 Supervisor 最多 500 个 workload clusters、vSAN for Recovery、Advanced Cyber Compliance、live patching、encrypted vMotion offload、AMD Instinct GPU 支持,以及 CrowdStrike、Arista、Cisco、SONiC 等生态集成。
这些能力共同指向一个变化:VCF 9.1 不只是虚拟化基础设施,而是一个面向多 workload 的私有云平台。平台团队可以用一套控制面管理传统 VM、Kubernetes、AI 服务、数据服务、网络服务和边缘站点,而不是为每类 workload 单独建设孤立平台。
生产 AI 与 GPU 平台
VCF 9.1 多篇文章把生产 AI 作为重点场景。它试图解决企业 AI 落地中的几个现实问题:数据不能轻易离开私有环境、GPU 投入成本高、AI 平台和传统基础设施割裂、模型运行缺少运维可见性、MLOps 团队需要更快获取资源。
在 AI 方向,VCF 9.1 强调:
- 支持生产级推理、RAG、Agentic AI 和模型服务。
- 支持 AMD Instinct GPU,并通过 Enhanced DirectPath I/O 提供接近原生硬件性能的虚拟化运行方式。
- 通过 GPU 和模型级指标帮助团队观察 GPU 利用率、内存、模型吞吐和运行状态。
- 将 AI workload 放到已有私有云运维、安全、备份、合规和网络体系中,而不是另建一套孤立 AI 集群。
- 支持开放框架和多厂商硬件,降低单一硬件或云平台绑定风险。
AI with VCF 9.1 on AMD GPUs 相关内容的重点是成本和开放性。VCF 9.1 通过 AMD GPU、Enhanced DirectPath I/O 和既有 vSphere 运维能力,让 AI workload 可以在私有云中获得更接近裸金属的性能,同时保留虚拟化带来的高可用、维护、快照、调度和生命周期管理能力。
Streamline, Simplify and Protect all your AI workloads with VCF 9.1 更强调运营闭环。AI 工作负载不只是跑模型,还需要数据访问、网络隔离、监控、证书、负载均衡、漏洞管理、灾备和访问控制。VCF 9.1 将这些能力放到统一平台中,目标是减少 AI 团队和基础设施团队之间的交付摩擦。
Kubernetes 与 VKS
VKS, VMware vSphere Kubernetes Service,是 VCF 中面向 Kubernetes 的核心能力。VCF 9.1 中,VKS 的重点是规模、性能、隔离和运维效率。
相关功能包括:
- 每个 control plane 支持最多 500 个 workload clusters。
- 集群 provisioning 最多加快 70%。
- 集群升级最多加快 75%。
- 支持 multi-network / 多 vNIC,让 Kubernetes 节点可以接入多个网络,用于隔离管理流量、应用流量、存储流量或高性能流量。
- 支持 Intelligent Node Pool Placement,减少平台工程师手动选择集群、zone、资源池或放置位置的负担。
- 支持多个 clusters per zone,便于隔离租户、应用环境、合规边界或生命周期阶段。
- 自动 secret injection 和更细粒度访问控制,降低凭据管理和权限配置错误风险。
VKS 的定位不是单纯“在 vSphere 上跑 Kubernetes”,而是让企业在已有 VCF 环境中建立可治理的 Kubernetes 服务。平台团队可以通过 VCF Automation 统一管理多个 VKS 集群,开发团队获得更快的集群交付和升级体验。
这对多租户平台很重要。很多组织不希望一个超大 Kubernetes 集群承载所有团队,而是希望按团队、环境、合规域或 workload 类型拆分多个小集群。VCF 9.1 通过提高每个 control plane 可管理的集群数量,降低多集群模型的管理成本。
自服务私有云与 VCF Automation
VCF Automation 9.1 的核心是把私有云能力产品化给内部团队或租户使用。它不只是资源申请门户,还承担策略、配额、模板、审批、租户隔离和生命周期控制。
相关能力包括:
- 自服务申请 VM、Kubernetes、容器、网络、VPC、数据库和应用栈。
- Infrastructure Policies 管理资源放置、成本边界、环境约束、命名规范、租户资源上限和合规要求。
- Live Application Stack Blueprints 将运行中的应用栈转换为可复用模板,减少重复搭建开发、测试和生产环境的工作。
- 与 Tanzu Marketplace 集成,让平台团队发布经过验证的服务、组件和工具。
Mastering Infrastructure Policies in VCF Automation 9.1 的重点是治理。自服务如果没有策略约束,很容易造成资源浪费、配置漂移和安全例外。基础设施策略的作用是把平台团队的规则前置到资源创建阶段,而不是等资源创建后再靠人工审计纠正。
App Stack Formation 相关内容则关注“把一次成功交付变成可复制模式”。当一个应用栈已经在某个环境中跑通,平台可以捕获它的计算、网络、存储和配置关系,形成模板,用于快速克隆到其他环境。它适合标准化开发测试环境、PoC 环境、客户交付环境和多团队重复应用栈。
Avi 应用交付
Avi Load Balancer 在 VCF 9.1 中承担的是应用交付层能力。它不只是传统负载均衡器,还连接 Kubernetes、VPC、自服务、AI 和安全策略。
VCF 9.1 中 Avi 相关能力主要覆盖:
- 为 VKS/Kubernetes workload 提供 L4/L7 入口。
- 为 VPC workload 提供自服务负载均衡。
- 为 Agentic AI 和模型服务提供弹性流量入口。
- 支持 TLS、证书生命周期、WAF、安全策略和可观测。
- 与 VCF Automation、NSX 和 VKS 协作,让应用团队用更少网络工单完成服务暴露。
在 Kubernetes 和 AI 场景下,Avi 的价值在于让应用入口和安全控制更自动化。AI 推理服务、agent API、Kubernetes service 和传统 VM 应用都可能需要统一入口、证书、策略和运行指标。如果这些能力分散在不同负载均衡平台中,运维和安全治理会变复杂。
VPC、自服务网络与连接策略
VCF Networking 9.1 相关多篇文章围绕 VPC 展开。这里的 VPC 指 VCF 私有云中的 Virtual Private Cloud,是面向租户或项目的自服务网络边界,提供类似公有云 VPC 的消费体验。
VCF 9.1 的 VPC 网络服务包括:
- switching 和 routing。
- DHCP 或第三方 IPAM 集成。
- NAT,包括 1:1 External-IP、N:1 Outbound-NAT、自定义 SNAT/DNAT。
- load balancing,可使用 NSX native LB 或 Avi plugin。
- VPN,但 VPN 仅适用于 centralized design。
VCF 9.1 提供两类 VPC 连接架构:
- Distributed mode:架构更轻,不需要 edge nodes、Tier-0 Gateways 或 BGP 配置。它适合所有 ESX hosts 连接到同一 Layer 2 网络的环境。
- Centralized mode:功能更完整,支持 VPN,适用于更复杂的 Layer 2 / Layer 3 物理网络拓扑。
VPC Connectivity Policy 是 VCF 9.1 的重要新增能力。它用于控制 VPC 间通信边界,减少为了简单隔离就必须写防火墙规则的需求。策略类型包括:
- Community:同一 community 内的 VPC 可以互通,不同 community 之间隔离。
- Promiscuous:开放型 VPC,可以和项目内其他 VPC 通信,适合 shared services。
- Isolated:隔离型 VPC,只能与 Promiscuous VPC 通信,适合应用团队或租户独立环境。
典型场景是共享服务网络。DNS、AD、日志、监控等放在 Promiscuous VPC 中,所有应用 VPC 设置为 Isolated。这样应用 VPC 能访问共享服务,但彼此不能直接互通。
Infoblox DDI 集成
VCF Networking 9.1 增加 Infoblox 集成,用于解决私有云自服务网络与企业现有 DDI 系统脱节的问题。
DDI 指 DNS、DHCP、IPAM。很多企业已经把 IP 地址、DNS 记录和地址段治理集中在 Infoblox 中。如果 VCF 自服务网络单独维护一套 IPAM,就会带来重复数据库、手工工单、IP 冲突和 DNS 不一致。
VCF 9.1 与 Infoblox 集成后:
- Infoblox 可以继续作为数据中心 IP 和 DNS 的 single source of truth。
- vCenter 管理员和 VCF Automation 租户可以自助创建网络。
- VCF 在后台与 Infoblox 通信,自动分配和预留 IP block。
- workload 部署时可以自动注册 FQDN 到 Infoblox DNS。
这项能力的重点不是“增加一个 IPAM 插件”,而是让网络团队保留集中治理,同时让应用团队获得私有云自服务体验。
vSphere 计算与基础设施经济性
vSphere 在 VCF 9.1 中的主题是更高密度、更少维护窗口和更好的现代硬件适配。
关键能力包括:
- vCenter quick patch:对有代码变化的 RPM 或二进制做快速补丁,减少 vCenter 维护窗口,部分场景可将停机压到 1 分钟以内甚至零停机。
- Reduced Downtime Upgrade 改进:支持在线 depot,降低 vCenter 升级和更新操作复杂度。
- vCenter maintenance API:其他组件可以知道 vCenter 是否计划或正在维护,Envoy reverse proxy 可返回带维护信息的 503 header。
- vCenter resize API:通过
deployment/sizeAPI 和一次重启完成 vCenter sizing up。 - vCenter virtual hardware version:升级到 VM hardware version 17。
- ESX live patch:默认启用,支持更多 vmkernel、用户态 daemon、vSAN daemon、核心存储 daemon 和 TPM 服务器。
- Zero Touch Provisioning:基于 UEFI HTTP/S Boot、Secure Boot 和 TPM,减少传统 Auto Deploy 对 TFTP 的依赖。
- vSphere Configuration Profiles:扩展 desired state 配置,可用于 memory tiering、vSAN 相关配置、vDS bootstrap 和新主机自动 remediation。
- Topology Aware Scheduler:针对高核心数 CPU、NUMA、cache 和内存带宽竞争做更合理的 VM 放置。
- Encrypted vMotion offload:通过 Intel QAT 等硬件加速降低加密迁移的 CPU 消耗。
这些能力集中服务于两个目标:提高硬件利用率,以及减少维护动作对业务和平台团队的影响。
NVMe Memory Tiering
Memory Tiering 是 VCF 9.1 的基础设施经济性重点。它的核心思想是:DRAM 成本高,但很多 workload 的内存页并不总是热数据。VCF 9.1 通过 NVMe 设备扩展有效内存容量,让热页留在 DRAM,冷页下沉到 NVMe。
VCF 9.1 对 Memory Tiering 的改进包括:
- 通过 vSphere Configuration Profiles 进行图形化和集群级配置,减少逐主机 CLI 操作。
- 支持 NVMe mirror device,用软件 mirroring 提升 tier 设备可靠性。
- 提供更统一的内存模型,降低应用感知差异。
- 帮助提高 VM consolidation ratio,延迟昂贵 DRAM 扩容。
它适合内存容量压力大、但并非所有内存访问都高度延迟敏感的环境。对数据库、低延迟交易、高性能缓存等 workload,仍需要单独测试访问模式和性能影响。
vCenter 运维:补丁、扩容与虚拟硬件
VCF 9.1 中 vCenter 运维改进集中在三个方向:缩短补丁窗口、简化扩容、更新虚拟硬件。
Quick Patch 只更新补丁 payload 中真正发生变化的组件,而不是像传统 in-place patch 那样更新所有 RPM。这能显著缩短维护窗口,适合快速落地重要安全修复。
vCenter resizing 通过 deployment/size API 简化扩容动作。管理员可以用 Developer Center API Explorer 调用 PATCH 方法完成 vCenter size up,并通过重启生效。这个能力适合 vCenter 管理对象规模增加、会话数上升、备份并发增加或服务请求压力变大的环境。
vCenter virtual hardware upgrade 则把 vCenter VM 的硬件版本提升到 version 17。Reduced Downtime Upgrade 创建新 vCenter VM 时会自动完成;如果是 in-place update,则可能需要手动升级并关机执行。
注意点是:vCenter resize 是放大操作,不应当被当作随意来回调整的弹性伸缩;执行前需要备份并确认磁盘、CPU、内存和管理窗口。
vSAN 保护、恢复与共享磁盘
vSAN 在 VCF 9.1 中围绕数据保护、勒索恢复、灾备和有状态应用增强。
vSAN Protection and Recovery 相关能力包括:
- 多源复制到 vSAN ESA recovery site,支持 vSAN、VMFS、NFS 等源。
- fan-in 架构,多个源集群可复制到一个集中恢复站点。
- 本地 clean room / Isolated Recovery Environment,用于在私有环境中验证恢复 workload,不必依赖公有云。
- 与 EDR 集成,用于恢复前扫描和验证,降低勒索软件 reinfection 风险。
- 支持 GFS/分层 snapshot retention。
- 支持通过 vSphere tags 动态纳入保护范围。
- 支持 manual replica seeding,降低首次大规模复制的网络和时间压力。
Expand Shared VMDKs 关注 clustered applications。很多传统集群应用需要共享 VMDK,例如部分数据库或高可用软件。VCF 9.1 对 shared VMDK 扩容能力的增强,可以降低这类应用在 vSAN 上运行时的存储维护复杂度。
SQL Server DBaaS 与 Data Services Manager
Data Services Manager, DSM,在 VCF 9.1 中强化了 SQL Server DBaaS。SQL Server 从技术预览走向生产级支持后,VCF 可以用统一平台交付 Postgres、MySQL 和 SQL Server 等数据库服务。
SQL Server DBaaS 方向的关键能力包括:
- 支持生产 SQL Server 服务。
- 支持三节点 Always On availability group。
- 支持 Active Directory、DNS 注册和 SQL Server Agent。
- 支持基于 policy 的资源、存储、备份和认证治理。
- 可将指标转发到 VCF Operations,纳入统一监控和容量分析。
这类能力的价值在于把数据库交付从“DBA 与基础设施团队手工协作”转成自服务和策略化流程。平台团队可以定义模板、备份策略、资源边界和认证方式,应用团队按需申请数据库实例。
VCF Edge 9.1
VCF Edge 9.1 面向分布式边缘站点。边缘环境通常有几个特点:站点多、IT 人员少、网络可能不稳定、硬件空间有限、部分场景需要离线或半离线运行。
VCF Edge 9.1 的重点包括:
- 从单节点到多集群边缘拓扑。
- Zero-Touch Provisioning,设备开机后自动获取期望配置。
- Day 0 Activation Script,完成站点初始化、注册和 GitOps 集成。
- 支持 VM、Kubernetes、vSphere Pods 和 AI workload。
- 支持断连或 air-gapped 环境中的生命周期和策略管理。
- 通过 NVMe Memory Tiering 提升边缘硬件密度,减少新增服务器需求。
它的定位是让边缘站点不再依赖大量人工驻场。中心团队定义期望状态,边缘节点在现场完成自动激活、配置、更新和运行。
VCSP 与服务商场景
VCF 9.1 对 VMware Cloud Service Providers, VCSPs 的价值主要体现在成本结构、多租户能力、自服务和增值服务变现。
服务商关心的不只是技术能力,还包括每台服务器能承载多少租户 workload、每个服务能否标准化交付、许可是否可自动化管理、是否能把安全和合规包装成高价值服务。
相关能力包括:
- 更高 workload density 和更低单位资源成本。
- 多租户 VPC、自服务网络、NAT、LB、VPN 和 IPAM/DNS 集成。
- Tenant License Manager 和程序化许可管理,适合服务商多租户运营。
- VCF Automation 提供租户自服务和策略化治理。
- vDefend 和 zero-trust 能力可包装为微分段、安全合规、威胁防护等增值服务。
- Advanced Cyber Compliance、灾备和勒索恢复可作为托管安全/托管恢复服务。
Monetizing Zero-Trust Security with VCF 9.1 and VMware vDefend 的重点是服务商如何把安全能力产品化,而不是只把 vDefend 当作内部防火墙工具。服务商可以围绕微分段、east-west 防护、合规报告和托管策略运营构建新的收入项。
许可管理
VCF 9.1 Licensing 强调许可管理的集中化、程序化和规模化。
关键能力包括:
- connected mode 下每 24 小时自动下载和应用 license file。
- 引入本地 license server。
- 单个 vCenter 支持多个 primary license types 和多个 Site ID。
- 增加 License Refresh、Tenant License Manager、Read-only 等角色。
- Licensing API 面向所有客户开放,便于自动化和集成。
- 支持断网或受控环境中的许可运营。
这对大型企业和服务商都很重要。多站点、多租户、多产品组合下,人工维护 license file 和 entitlement 容易出错;程序化和集中化可以降低续期、审计和租户计量的操作成本。
生命周期、升级与补丁治理
VCF 9.1 的生命周期管理目标是把升级和补丁从“人工阅读矩阵、手工排 runbook”变成更可计划、更自动化、更可观察的流程。
相关能力包括:
- VCF 9.1 Upgrade Planning Tool,用于升级前规划、兼容性和依赖检查。
- VCF Lifecycle Management 改进大规模环境中的组件升级、补丁和漂移控制。
- vCenter Quick Patch 和 ESX Live Patch 减少维护窗口。
- Reduced Downtime Upgrade 改进 vCenter 更新体验。
- vSphere Lifecycle Manager 增强 image checksum、驱动/固件可见性和 HCL 验证。
- Tanzu Platform 提供应用和容器层面的漏洞评估与修复。
Smarter Patching at Scale with VMware Tanzu Platform 关注的是应用侧漏洞治理。基础设施补丁只能解决底层平台风险,容器镜像、依赖包和应用组件也需要持续扫描、评估和修复。Tanzu Platform 的角色是把漏洞发现、影响范围判断、修复建议和大规模 rollout 纳入平台流程。
安全、身份与合规
VCF 9.1 的安全内容分布在多个产品域中,主要包括身份、安全合规、zero-trust、勒索恢复、补丁和证书。
关键方向:
- Symantec Identity Security Platform 集成,用于保护 VCF 9.1 基础设施身份、权限和访问路径。
- Advanced Cyber Compliance 提供持续合规、漂移检测和自动修复。
- vDefend 提供 zero-trust、微分段和 east-west 流量安全。
- vSAN Protection and Recovery 与 EDR / clean room 结合,支持勒索恢复验证。
- vCenter Quick Patch、ESX Live Patch、Tanzu vulnerability remediation 降低补丁窗口和暴露时间。
- Avi 提供 TLS、WAF、负载均衡和证书自动化,保护应用入口。
这批文章体现出的安全思路是:不要把安全放在单个工具中,而是嵌入资源申请、网络连接、运行监控、补丁、备份、恢复和身份治理的完整生命周期。
Hands-on Labs、演示与可用性
VCF 9.1 Is Here. See It in Action 和 Hands-on Labs 相关文章面向评估和试用。它们的作用是把发布功能变成可操作体验,帮助用户验证新能力是否适合自己的环境。
适合通过实验室优先验证的内容包括:
- VKS 集群交付和升级。
- VCF Automation 自服务和策略。
- VPC 网络服务、连接策略和 Infoblox 集成。
- Memory Tiering 配置。
- vCenter patching、resize 和生命周期操作。
- vSAN Protection and Recovery。
- AI/GPU 相关运行和可观测能力。
对于 VCF 这类平台级产品,直接在生产环境验证新功能风险较高。Hands-on Labs 和演示环境更适合先理解对象模型、控制面流程、权限边界和操作路径。
落地注意事项
VCF 9.1 涉及的产品域很广,落地时不应把它看成一次普通版本升级。更合理的方式是按能力域分阶段评估:
- 先评估基础组件兼容性:vCenter、ESX、vSAN、NSX、Avi、VCF Automation、VCF Operations、VKS、DSM。
- 对生产 AI 场景,单独验证 GPU 型号、驱动、Enhanced DirectPath I/O、模型指标、网络延迟和存储路径。
- 对 Kubernetes 场景,先验证 VKS 集群规模、升级速度、多网络、secret injection、RBAC 和租户隔离。
- 对网络场景,明确使用 distributed mode 还是 centralized mode,并确认是否需要 VPN、Tier-0、BGP、edge nodes 或 Infoblox。
- 对 Memory Tiering,要按 workload 类型压测,不应假设所有应用都适合把冷页下沉到 NVMe。
- 对 vSAN recovery 和 clean room,要演练恢复流程,而不是只配置复制策略。
- 对 vCenter quick patch、ESX live patch、RDU 和 upgrade planning,要在非生产环境验证完整维护流程和回滚路径。
- 对服务商环境,要提前设计租户模型、许可模型、VPC 边界、计费口径和安全服务目录。
- 对安全集成,要明确身份系统、EDR、vDefend、ACC、Tanzu vulnerability remediation 和 Avi WAF/TLS 的责任边界。
📰 专题二 新闻与访谈
1. SUSE 正在把自己定位为 AI 时代的开放基础设施平台
How SUSE positions itself as the infrastructure layer for the AI era
受访者:SUSE 公司负责云原生业务的资深副总裁兼总经理 Pete Smails。
SUSE 的新定位
SUSE 希望成为现代工作负载的开放基础设施平台,底层仍是操作系统,但上层扩展到 Kubernetes、容器、虚拟机和 AI 服务。
三个重点方向
文章把 SUSE 当前战略概括为统一三类能力:
- AI 服务;
- 容器与 Kubernetes;
- 虚拟机管理。
SUSE 的逻辑是,企业未来会运行在多数据中心、多云环境中,因此需要统一管理 VM、容器和 AI 工作负载,而不是让这些系统彼此割裂。
Rancher Prime 的角色
SUSE Rancher Prime 是 SUSE 的 Kubernetes 管理和编排层,用于帮助企业在不同环境中构建、部署和管理云原生应用。文章强调它是 SUSE 云原生战略的核心组件。
SUSE Virtualization
SUSE Virtualization 被描述为现代化传统基础设施的基础,也被定位为一种“现代 VMware 替代方案”。它和 Rancher 一起承担统一 VM 与容器管理的角色。
AI Agent “Liz”
文章重点介绍了 SUSE 的 AI agent:Liz。它集成在 SUSE Rancher Prime 中,面向平台工程团队。
Liz 的作用包括:
理解集群、namespace 和 workload 的实时状态; 用自然语言帮助工程师排查 Kubernetes 问题; 发现 CVE 等风险,并建议是否查找干净版本; 通过 Model Context Protocol 连接运行时数据和可执行建议。
它不是通用聊天机器人,而是面向 Kubernetes 运维上下文的 AI 助手。
开发者体验
SUSE 还强调 Rancher Developer Access,目标是让开发者能在本地环境中运行 Kubernetes 和可信内容,降低使用云原生技术的认知负担。
2. Microcks 成为 CNCF 孵化项目
产品介绍
Microcks 是一个开源、云原生的 API Mock 与测试平台,用于帮助团队在隔离环境中开发和测试依赖外部 API 或微服务的应用。它可以把 OpenAPI、AsyncAPI、gRPC/Protobuf、GraphQL Schema、Postman Collection、SOAP/WSDL 等契约文档转换为可运行的 Mock 服务,并用同一组契约对真实实现执行自动化一致性测试。
Microcks 的特点是多协议覆盖,既支持 REST/RPC 等同步 API,也支持事件驱动的异步架构,因此适合微服务、云原生和 API DevOps 场景。
晋级背景
CNCF 技术监督委员会已投票接纳 Microcks 成为 CNCF 孵化项目。Microcks 最初由 Laurent Broudoux 于 2015 年创建,并在 2023 年 6 月进入 CNCF Sandbox。随着企业应用逐渐拆分为大量相互依赖的 API 和微服务,团队需要在不依赖完整上下游环境的情况下完成开发、测试和契约验证,这正是 Microcks 要解决的问题。
生态与采用
Microcks 在进入 Sandbox 后采用规模明显扩大。2025 年容器镜像下载量超过 250 万次,是 2024 年总量的三倍;已有 34 家组织公开采用,仅 2025 年新增 13 家,采用者包括 BNP Paribas、Société Générale、Lombard Odier、Deloitte、Amway 和 J.B. Hunt 等。
社区贡献也在增长。项目累计有 645 名 GitHub 贡献者,最近一个季度有 51 名活跃贡献者,季度留存率为 57%。2025 年,167 名活跃贡献者来自 35 个组织。过去一年中项目有 342 天保持活跃,平均每月新增 288 个 Pull Request,Issue 平均解决时间为 11 天,PR 平均合并周期为 6 天。
技术能力
Microcks 由多个模块化组件组成。Core Server 提供 API Mock 引擎、Web UI 和 REST API,负责导入契约文档并生成动态 Mock 响应。Async Minion 扩展异步协议支持,覆盖 Kafka、MQTT、AMQP、WebSocket、Google Pub/Sub 等事件驱动场景。
Operator 和 Helm Chart 用于 Kubernetes 环境中的部署和生命周期管理,也支持通过 GitOps 部署 Mock 和执行测试。Testcontainers 模块覆盖 Java、Node.js、Go、Python 和 .NET,便于开发者把 Microcks 嵌入本地和自动化测试流程。CLI 则可从 Jenkins、GitHub Actions、Tekton 等 CI/CD 流水线触发 API 一致性测试。
CNCF 评价
CNCF TOC 认为,Microcks 解决了 Kubernetes 分布式系统中的关键问题:当服务之间存在大量依赖时,如何在隔离环境中开发和测试单个服务。它以开源方式在 Kubernetes 上大规模提供 API Mock,支持 REST、GraphQL、AsyncAPI、gRPC 等多种规范,并保持厂商中立。
进入孵化阶段意味着 Microcks 已在采用度、社区活跃度、治理和生态集成方面达到更高成熟度,也将获得 CNCF 和 Linux Foundation 在治理、市场推广和社区拓展方面的支持。
后续路线
Microcks 后续重点包括支持 AI 驱动 API 和 Agent 测试,集成模型上下文协议 MCP,继续扩展 AsyncAPI 生态,尤其是 Kafka 契约测试。同时,团队还将推进更多语言和框架下的 Testcontainers 支持,增强 OpenTelemetry 可观测性能力,支持更多事件驱动协议,并通过 JavaScript Dispatcher 提供更动态、复杂的 Mock 场景。
3. Cloud Custodian 十周年:AI 时代,云治理需要自动化护栏
Cloud Custodian 十周年:AI 时代,云治理需要自动化护栏
Cloud Custodian 是一个开源、无状态的策略引擎,可通过统一的 DSL 管理公有云环境、Kubernetes 以及基础设施即代码。作为 CNCF 的孵化项目,Cloud Custodian 让组织能够跨多个云服务提供商,定义并执行面向 FinOps、安全与合规的策略。
Q:Cloud Custodian 如何帮助企业管理成本?
A:Cloud Custodian 通过策略减少资源浪费,例如清理闲置或配置不足的资源,包括闲置的训练任务与 GPU 集群。同时,它也可以防止昂贵的错误配置,例如过大的存储层级选择,从而帮助云环境保持高效并处于良好治理状态。
Q:Cloud Custodian 是否兼容多云环境?
A:是的。Cloud Custodian 提供统一的 DSL,可跨 AWS、Azure、GCP 与 OCI 管理资源,帮助组织建立统一的策略事实来源。
Q:为什么 Cloud Custodian 与 AI 生成代码有关?
A:AI Agent 生成与交付代码的速度,可能远快于人类审查代码的速度。Cloud Custodian 在这里扮演自动化安全网的角色,确保所有由机器部署的基础设施都符合安全与合规规则,同时在错误配置演变成安全缺口或预算超支之前,及时发现并处理问题。
🔐 专题三 安全
1. CVE-2026-31431
漏洞简介
CVE-2026-31431 是 Linux kernel algif_aead 加密算法接口中的漏洞。Red Hat 描述为:错误的 in-place 操作会导致加密处理时源数据和目标数据映射不一致;低权限本地攻击者可利用该问题破坏敏感系统文件内容,并提升到 root 权限。
严重等级
- Red Hat 评级:Important。
- CVSS v3 基础分:7.8。
- CVSS 向量:CVSS:3.1/AV:L/AC:L/PR:L/UI:N/S:U/C:H/I:H/A:H。
2. CVE-2026-46333
漏洞简介
CVE-2026-46333 是 Linux kernel 中与 ptrace 和 get_dumpable() 逻辑相关的漏洞。
问题点在于:dumpable 概念本来主要针对有内存映像的进程,也就是带有 mm 的任务;但 ptrace_may_access() 会在一些与内存映像无关的场景中使用 dumpable 判断访问权限,包括已经没有 VM 的线程,甚至某些内核线程。
Ubuntu 页面描述的修复方向是:如果目标任务没有 mm 指针,则使用缓存的“last dumpability”状态;对于从未有过 mm 的内核线程,该值为 0;如果要绕过限制,则需要真正具备 CAP_SYS_PTRACE。
严重等级
- Ubuntu priority:High
- CVSS v3:5.5 Medium
发布时间:2026-05-15
最后更新:2026-05-26
这里需要注意,Ubuntu priority 和 CVSS 严重度不是同一个字段:
- Ubuntu priority 反映 Ubuntu 安全团队对修复优先级的判断
- CVSS 分数反映漏洞通用评分体系下的基础严重度
影响范围
受影响的是多个 Ubuntu Linux kernel 包。页面中状态较多,核心状态如下:
处理建议
- 优先确认系统的 Ubuntu release 和正在运行的 kernel package。
- 对照 Ubuntu CVE 页面中的 Status 表判断是否受影响。
- 如果状态为
Vulnerable或Vulnerable, work in progress,关注 Ubuntu 后续安全更新。 - 在无法立即修复且业务不依赖跨进程 ptrace 的场景中,可临时设置
kernel.yama.ptrace_scope=2。 - 修复包发布后,通过常规系统更新升级 kernel,并重启进入新内核。
3. Argo CD 的高危漏洞:Kubernetes Secret Extraction via ArgoCD ServerSideDiff
Kubernetes Secret Extraction via ArgoCD ServerSideDiff
漏洞简介
Argo CD 的 ServerSideDiff 接口存在授权和敏感数据脱敏缺陷。攻击者只要拥有 Argo CD 应用的只读访问权限,就可能通过该接口从 Kubernetes API Server 的 Server-Side Apply dry-run 响应中提取真实的 Kubernetes Secret 数据。
问题点在于:Argo CD 其他返回 Kubernetes 资源状态的接口会调用 hideSecretData() 对 Secret 内容脱敏,但 ServerSideDiff 接口返回的 PredictedLive 和 NormalizedLive 状态没有正确脱敏。
当 Application 设置了:
argocd.argoproj.io/compare-options: IncludeMutationWebhook=true
时,原本用于移除非 Argo CD 管理字段的保护逻辑会被跳过,导致来自 etcd 的真实 Secret 值直接进入 API 响应。
严重等级
- 严重等级:Critical
- CVSS v3:9.6
- 向量:CVSS:3.1/AV:N/AC:L/PR:L/UI:N/S:C/C:H/I:H/A:N
可通过网络利用、攻击复杂度低、需要低权限、无需用户交互,主要影响机密性和完整性。
影响范围
受影响包:github.com/argoproj/argo-cd/v3
受影响版本:3.2.0 - 3.3.8
已修复版本:3.3.9 3.2.11
影响后果
任何拥有 Argo CD application get 权限的用户,都可能提取真实 Kubernetes Secret 值,包括:service account token; TLS 证书; 数据库凭据; API key。
如果某个 Application 已经设置了 IncludeMutationWebhook=true,攻击者只需要只读 Argo CD 权限即可利用。
处理方式
升级到修复版本:Argo CD 3.3.9 或更高; Argo CD 3.2.11 或更高。
同时建议排查是否有 Application 使用了:argocd.argoproj.io/compare-options: IncludeMutationWebhook=true
并重新评估只读用户的 Argo CD application 权限,因为该漏洞的利用门槛就是 application get 权限。
💬 专题四 讨论与分享
1. Kubernetes 默认限制汇总
Kubernetes default limits I keep forgetting
Pods per node: 110
Nodes per cluster: 5,000
Total pods per cluster: 150,000
Total containers per cluster: 300,000
etcd request size: 1.5 MiB
etcd default DB size: 2 GB (8 GB suggested max)
Secret size: 1 MiB
ConfigMap data: 1 MiB
Annotations total per object: 256 KiB (262,144 bytes)
Label/annotation key name: 63 chars max
Label value: 63 chars max
Annotation/label key prefix: 253 chars (DNS subdomain)
Object name (DNS subdomain rule): 253 chars max
Object name (DNS label rule): 63 chars max
NodePort range: 30000 to 32767
Default Service CIDR (kubeadm): 10.96.0.0/12
terminationGracePeriodSeconds: 30s
Eviction hard memory.available: 100Mi
Eviction hard nodefs.available: 10%
Eviction hard nodefs.inodesFree: 5%
Eviction hard imagefs.available: 15%
PodPidsLimit: -1 (unlimited per pod by default)
Kubelet API port: 10250
etcd client port: 2379-2380
kube-apiserver port: 6443
2. 利用 AWS Backup 实现 Amazon EKS 的跨区域灾难恢复
Cross-Region disaster recovery for Amazon EKS using AWS Backup
灾备背景
对于在 Amazon EKS 上运行有状态容器化工作负载的组织,多可用区部署可以满足大部分高可用需求,但如果需要应对区域级中断,并满足更严格的 RTO 和 RPO 要求,就需要跨 Region 灾难恢复方案。
核心方案
AWS Backup 对 Amazon EKS 提供原生支持,可以集中、策略化地保护 Kubernetes 资源和持久卷数据。通过结合 AWS Backup 的跨 Region 复制能力,应用的完整状态可以从源 Region 复制到灾备 Region。
备份内容包括 EKS 集群配置、Kubernetes 资源,例如 Deployments、StatefulSets、Services、ConfigMaps、Secrets,以及通过 EBS 快照保存的持久卷数据。这些内容会整合到一个 EKS 复合恢复点中,并存储在 AWS Backup Vault 中。
实施流程
方案分为五个阶段:先在源 Region 部署 VPC、EKS 集群、节点组、EBS CSI Driver、AWS Load Balancer Controller 等基础设施;再部署带状态数据的零售商店应用,其中 MySQL 和 Redis 使用 EBS 持久卷;随后配置 AWS Backup 进行按需备份,并将恢复点跨 Region 复制到灾备 Region。
灾备 Region 中提前预置 VPC、EKS 集群、节点组和相关组件。发生故障时,从灾备 Region 的恢复点中将 Kubernetes 资源和持久卷数据恢复到已有的 DR 集群,并验证 Pod、PVC/PV、负载均衡访问,以及数据库和缓存数据是否正常。
关键优势
将应用恢复到预先配置好的 DR 集群,而不是在恢复时新建集群,可以缩短 RTO,因为控制平面、节点和基础设施在灾难发生前已经准备就绪。
AWS Backup Vault 提供角色访问控制、静态加密和 Vault Lock 等能力,增强备份数据的隔离与安全性。跨 Region 复制则提供地理冗余,同时减少手动维护多套备份流程的操作负担。
生产建议
生产环境中应配置自动化备份计划、EventBridge 告警和定期 DR 演练,持续验证备份与恢复流程。同时可使用 AWS Backup Audit Manager 检查备份策略和合规性。
3. 使用 Velero 来备份和恢复 Amazon EKS 集群中的资源
链接
Back up and restore your Amazon EKS cluster resources using Velero
Velero 简介
Velero 是 Kubernetes 原生的备份、恢复和迁移工具。它可以备份集群中的 Kubernetes 资源对象,也可以结合云厂商快照能力备份持久卷数据。
在 Amazon EKS 中,Velero 通常配合以下组件使用:
- Amazon S3:保存备份数据和 Kubernetes 资源定义
- Amazon EBS snapshot:备份 EBS 持久卷数据
- EBS CSI Driver:提供 EBS 卷和快照能力
- snapshot-controller:支持 Kubernetes CSI 卷快照
- EKS Pod Identity:让 Velero Pod 使用 IAM Role 获取 AWS 权限
- IAM Role / IAM Policy:控制 Velero 对 S3 和 EBS snapshot 的访问权限
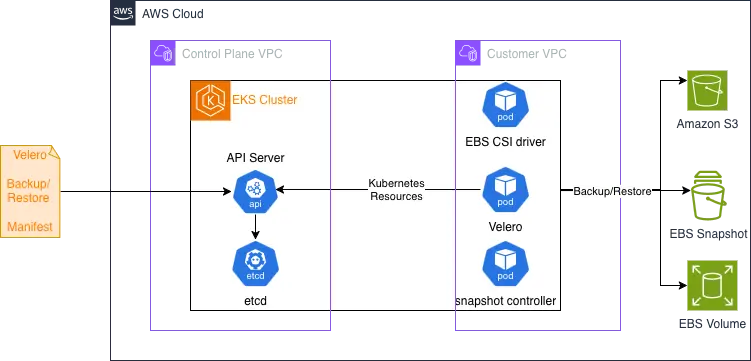
方案目标
该方案用于在 EKS 中备份和恢复应用资源,覆盖两类内容:
- Kubernetes 资源对象:Namespace、Deployment、Service、ConfigMap、Secret、PVC、PV 等
- 持久化数据:通过 EBS snapshot 备份 PVC 背后的 EBS 卷
适合应对 namespace 误删、应用迁移、集群升级失败、灾难恢复等场景。
核心流程
- 准备 EKS 集群,并安装 AWS CLI、kubectl、Helm
- 创建 S3 bucket,用于存放 Velero 备份
- 创建 IAM policy 和 IAM role,授权 Velero 访问 S3 与 EBS snapshot
- 使用 EKS Pod Identity 将 IAM role 绑定到 Velero ServiceAccount
- 安装 snapshot-controller
- 使用 Helm 安装 Velero,并配置 AWS provider、S3 存储位置、EBS snapshot 位置和 CSI 支持
- 创建
VolumeSnapshotClass,指定 EBS CSI driver,并添加 Velero 所需 label - 部署带 PVC 的示例有状态应用
- 创建 Velero Backup,备份指定 namespace,并启用卷快照
- 创建 Velero Restore,将备份恢复到目标 namespace
- 验证恢复后的 Pod、PVC 和持久化数据
安全建议
- IAM 权限只授予指定 S3 bucket 和必要 EBS snapshot API
- 不在 Pod、镜像或配置文件中保存长期 AWS 凭据
- 使用 EKS Pod Identity 提供临时凭据
- Kubernetes RBAC 不建议直接使用默认
cluster-admin - 使用受限
ClusterRole,只允许 Velero 操作备份恢复所需资源
适用场景
- EKS 应用级备份
- namespace 误删恢复
- 集群升级前备份
- 有状态应用灾备
- 同集群不同 namespace 恢复
- 跨 EKS 集群或跨 Region 恢复
- Kubernetes 发行版之间迁移
注意事项
- S3、EBS snapshot 和 EKS 资源会产生费用
- EBS 卷恢复依赖 EBS CSI Driver、snapshot-controller 和正确的
VolumeSnapshotClass - 备份成功不代表恢复一定可用,应定期演练恢复
- 可使用 Velero Schedule 实现周期性自动备份
- 如需集中式托管备份管理,可评估 AWS Backup for Amazon EKS
4. 为多个账户下的 Amazon EKS 实现集中式可观测性监控
Implement centralized observability for multi-account Amazon EKS
背景
多账号、多 Region 的 Amazon EKS 环境中,监控数据通常分散在不同 AWS 账号和 Region 里。发生故障时,运维人员需要频繁切换账号、查找不同 log group、手动关联指标和日志,容易拉长 MTTR。
这篇内容介绍一种集中式可观测方案:在保留账号隔离边界的前提下,把多个账号中的 EKS 监控数据统一汇聚到一个中心监控账号中。
方案目标
目标是构建一个 hub-and-spoke 监控架构:
- Hub:中心监控账号
- Spoke:运行 EKS 集群的业务账号或源账号
该架构用于统一查看多账号 EKS 集群的健康状态、指标、日志、trace、告警和升级需求,减少故障排查时的账号切换和上下文切换。
核心组件
-
Amazon EKS Dashboard
提供组织级 EKS 集群视图,用于查看集群健康、版本升级需求、控制面成本预测、托管节点组 AMI 版本等。 -
Amazon CloudWatch cross-account observability
将源账号中的 metrics、logs、traces 等遥测数据共享到中心监控账号。适合同 Region 内的集中查询和分析。 -
CloudWatch Observability Access Manager, OAM
用于创建 sink 和 link。中心账号创建 sink,源账号创建 link,从而建立跨账号遥测数据共享关系。 -
Cross-account cross-Region dashboards
通过 IAM role assumption 跨账号、跨 Region 查询 CloudWatch 数据,用于构建统一运维看板。 -
Container Insights
提供 EKS 集群、节点、Pod 等维度的容器指标和日志,是集中式观测的数据基础。
两种跨账号监控方式
CloudWatch cross-account observability
这种方式会把源账号中的遥测数据共享到中心监控账号。配置完成后,中心账号可以像访问本地数据一样查询多个源账号的 metrics、logs 和 traces。
适合:
- 同 Region 内集中监控
- 跨账号 Logs Insights 查询
- 聚合多个账号的 EKS Container Insights 数据
- 快速查看多个账号的指标和日志
Cross-account cross-Region dashboards
这种方式不复制数据,而是在查看 dashboard 时通过 IAM role assumption 实时查询源账号和其他 Region 的 CloudWatch 数据。
适合:
- 跨 Region 运维看板
- 全球集群健康视图
- 多 Region EKS 指标对比
- 管理层或平台团队的统一 dashboard
两者可以组合使用:前者提供 Region 内深度观测能力,后者提供跨 Region 的统一视图。
实施流程
-
启用 Amazon EKS Dashboard
在中心监控账号中开启组织级 EKS Dashboard,查看所有 EKS 集群的健康状态、版本、升级需求、支持类型和成本预测。 -
创建 CloudWatch OAM sink
在中心监控账号、目标 Region 中创建 sink,选择允许接收的 telemetry 类型,例如 metrics、logs、traces、Application Insights。 -
在源账号创建 OAM link
每个运行 EKS 的源账号都需要创建 link,连接到中心账号的 sink。可以手动创建,也可以使用 CloudFormation 模板。 -
扩展到多个账号
对大量账号,可以使用 CloudFormation StackSets 批量部署 OAM link 到多个账号或组织单元。 -
验证跨账号访问
在中心监控账号中查看 CloudWatch Metrics 和 Log groups,确认可以看到源账号中的 Container Insights 指标和日志,例如/aws/containerinsights/<cluster-name>/performance。 -
配置跨账号跨 Region dashboard
在源账号中创建CloudWatch-CrossAccountSharingRole,允许中心账号读取 CloudWatch 数据。 -
启用中心账号的跨账号跨 Region 查看能力
在 CloudWatch 控制台启用 account selector 和 Region selector。 -
创建统一 dashboard
在中心账号中创建 CloudWatch dashboard,添加来自不同账号和 Region 的 EKS 指标,例如 Pod CPU、Pod memory、集群错误率、告警等。
适用场景
- 多 AWS 账号下的 EKS 集群统一监控
- 多 Region EKS 运维看板
- 平台团队集中查看集群健康状态
- 故障期间快速定位异常账号、Region 和集群
- 跨账号查询 Container Insights 日志和指标
- 统一追踪集群版本升级和容量状态
- 组织级 EKS 成本和扩展支持成本分析
运维价值
- 减少故障排查时的账号切换
- 缩短 MTTR
- 更容易关联多个账号和 Region 的日志、指标和告警
- 提前发现节点容量、Pod CPU、Pod memory 等资源压力
- 统一识别需要升级的 EKS 集群
- 保留源账号与中心账号之间的安全隔离边界
- 支持从少量账号扩展到大量账号
成本说明
CloudWatch cross-account observability 共享 metrics 和 logs 不额外收费,第一份 trace copy 免费,额外 trace copy 按 AWS X-Ray 标准计费。
EKS Dashboard 本身不额外收费。CloudWatch dashboard 按标准价格计费,示例价格为每个 dashboard 每月 3 美元,按小时折算。
如果 dashboard 中包含 Logs Insights 查询,每次打开或刷新 dashboard 都会触发查询并产生相应费用。
限制与注意事项
- EKS Dashboard 每 12 小时更新一次,不适合实时故障响应
- CloudWatch cross-account observability 是 Region 级能力,需要在每个目标 Region 分别配置 sink 和 link
- Cross-account observability 每个中心监控账号最多支持 100,000 个源账号
- 每个源账号最多可以向 5 个监控账号共享 telemetry
- 基于跨账号数据创建 CloudWatch Alarm 时,资源必须创建在 telemetry 所在 Region
- IAM 权限应遵循最小权限原则,限制 OAM sink、link 和 CloudWatch 读取权限
- 大规模账号接入建议使用 CloudFormation StackSets 自动化部署
5. 确保开源项目的 CI/CD 流程安全:从 Cilium 项目中获得的经验教训
Securing CI/CD for an open source project: lessons from Cilium
背景与风险
过去一年开源供应链攻击频发,npm、PyPI、Go 模块、CI/CD 系统和软件发布链路都可能成为攻击入口。Cilium 运行在大量 Kubernetes Pod 的内核级网络路径中,如果构建或发布流程被攻破,影响范围会很大,因此 CI/CD 被视为需要重点加固的高价值攻击面。
核心思路
Cilium 的 CI/CD 安全并不依赖单一防线,而是围绕几个关键问题逐层收敛风险:谁能触发构建、CI 实际执行什么代码、依赖从哪里来、凭据能访问什么资源,以及用户如何验证最终发布物。
这些控制措施的共同目标是降低攻击者从 PR、依赖、GitHub Actions 或凭据入手后的爆炸半径,即使某一层出问题,也尽量避免影响正式发布产物。
构建触发与代码执行
Cilium 使用 Ariane 控制谁可以通过 PR 评论触发 CI,只有经过验证的组织成员才能触发允许列表中的工作流,避免外部用户随意启动高成本或高权限的测试任务。
对于必须使用 pull_request_target 的场景,Cilium 采用两阶段 checkout:可信脚本、复合 Action 和签名逻辑来自 base branch,PR 分支只作为 Docker 构建上下文使用,不执行其中的脚本。这样既能构建贡献者提交的代码,又能避免不受信任代码直接接触 GitHub Actions 环境变量、仓库密钥或生产凭据。
依赖与配置防护
所有 GitHub Actions 都固定到完整 commit SHA,容器镜像也固定到 sha256 digest,避免可变 tag 被篡改后影响 CI。Renovate 负责自动更新这些固定版本,并设置 5 天冷却期,降低刚发布的恶意或被劫持版本立即进入项目的风险。
Go 依赖全部 vendoring 到仓库中,CI 会检查 go.mod、go.sum 和 vendor/ 是否一致。这样依赖变更会在代码审查中以 diff 形式出现,而不是在构建时静默从外部代理拉取。
审查、静态分析与凭据隔离
.github/ 下的 CI 配置变更必须经过 CODEOWNERS 指定的安全相关团队审查,auto-approve.yaml 等敏感流程还需要维护者把关。CodeQL 和 actionlint 用于检查工作流中的不安全模式,例如缺少显式 permissions:,以及在 run: 块中直接使用 GitHub Actions 表达式导致命令注入。
凭据按用途隔离:CI 凭据只能推送到 *-ci 开发镜像标签,生产 registry 凭据放在受保护的 release 环境后面,需要维护者批准后才能访问。即使 CI 被攻破,攻击者最多影响开发镜像,不能直接发布正式 Cilium 镜像。
发布验证与待改进项
Cilium 使用 Sigstore Cosign 的 keyless OIDC 方式对 release 镜像和 Helm chart 签名,并附带 SBOM attestations,使用户能够验证发布物来源。
仍在改进的部分包括:尚未生成 SLSA provenance,PR 阶段缺少依赖审查,CI 中还没有集成 govulncheck,部分内部复合 Action 仍引用 @main,后续计划迁移到专门的 composite actions 仓库。GitHub 2026 Actions 安全路线图中的依赖锁定、策略化执行和更细粒度 secret scope,也能进一步补齐这些缺口。
6. 从 AWS VPC CNI 和 Kube-Proxy 迁移至 EKS 上的 Cilium
Migrating from AWS VPC CNI & Kube-Proxy to Cilium on EKS
产品/功能简介
AWS VPC CNI 是 EKS 默认的容器网络插件。它让 Pod 直接使用 VPC 网段中的 IP,和 AWS VPC 网络模型集成紧密,适合大多数 EKS 默认场景。
kube-proxy 是 Kubernetes 默认的 Service 转发组件,通常基于 iptables 或 IPVS 实现 Service 到 Pod 的流量转发。
Cilium 是基于 eBPF 的 Kubernetes 网络、网络安全和可观测性方案。它可以替代传统 CNI 和 kube-proxy,用 eBPF 处理路由、Service 负载均衡、网络策略和流量可观测。
Hubble 是 Cilium 的可观测性组件,用于查看 Pod 之间、Service 之间的流量关系、DNS 请求、丢包、TCP/HTTP 流量等。
WireGuard 是现代 VPN/加密隧道协议。Cilium 可以用 WireGuard 加密跨节点 Pod-to-Pod 流量。
背景
这篇文章记录了一次在 Amazon EKS 上的网络迁移:从默认的 AWS VPC CNI + kube-proxy 迁移到 Cilium。
集群环境:
- Amazon EKS 1.35
- Bottlerocket OS
- 原网络方案为 AWS VPC CNI 和 kube-proxy
- 目标方案为 Cilium ENI IPAM、eBPF kube-proxy replacement、WireGuard 加密和 Hubble 可观测
迁移动机主要有三点:
- 合规:需要可验证的 Pod-to-Pod 传输加密,用于 SOC 2 合规
- 可观测性:希望通过 Hubble 观察 Pod 间流量关系和网络行为
- 无 Sidecar:希望不用 Istio 这类 sidecar 模式,也能获得网络安全、路由和观测能力,减少资源开销和延迟
核心方案
迁移采用 blue/green node pool 策略,而不是在现有节点上直接替换 CNI。
整体思路是:
- 老节点继续运行 AWS VPC CNI 和 kube-proxy
- 新节点打上
cni=cilium标签 - Cilium 只调度到新节点
- 工作负载逐步从旧节点迁移到新节点
- 旧节点 drain 后退出
这种方式避免了在 live cluster 上一次性切换 CNI,降低中断风险。
方案价值
- 用 Cilium eBPF 替代 kube-proxy,减少传统转发表维护成本
- 使用 ENI IPAM 保持与 AWS VPC 网络模型兼容
- 通过 WireGuard 提供可验证的跨节点 Pod-to-Pod 加密
- 使用 Hubble 获得更细粒度的网络可观测性
- 不需要 sidecar 即可获得网络安全和观测能力
- blue/green 节点池降低 live cluster CNI 迁移风险
注意事项
- 不建议直接在现有节点上原地替换 CNI,风险较高
- Cilium、aws-node、kube-proxy 的 DaemonSet 调度范围必须严格隔离
- Cilium agent 启动前 ClusterIP 可能不可用,因此需要配置真实 EKS API endpoint
- Bottlerocket 环境下需要正确配置设备匹配,例如
eth+ - Cilium operator 默认行为可能影响 CoreDNS,需要按迁移策略调整
- WireGuard 加密的是跨节点 Pod-to-Pod 流量,不等于所有节点级流量都加密
- 抓包排查时要区分
eth0外层加密流量和cilium_wg0内层解密流量 - 启用 WireGuard 可能引入额外封装和延迟,需要结合业务性能要求测试
📄 专题五 报告查看与分析
💁♀️ 专题六 产品/方案介绍
1. Azure Kubernetes Fleet Manager:规模化管理多个集群
How Microsoft is governing thousands of Kubernetes clusters without manual intervention
背景与问题
Kubernetes 使用规模扩大后,企业面对的不再只是单个集群的部署和运维问题,而是如何治理成百上千个分布在云端、本地和边缘环境中的集群。AI 推理工作负载向边缘扩散进一步放大了这个问题,因为集群可能部署在工厂、门店或靠近数据源的位置,需要统一更新、调度和合规管理。
传统 GitOps 适合声明式管理,但在 fleet scale 下,一对一的仓库到集群同步模式会遇到协调延迟、配置一致性、跨集群路由、Secret 分发和可观测性等问题。GPU 等昂贵资源也要求平台具备跨集群调度能力,否则容易出现资源闲置或无法灵活迁移工作负载。
产品能力
Azure Kubernetes Fleet Manager 正是针对这些规模化管理问题提供统一控制层。它把多个 Kubernetes 集群作为一个 fleet 来管理,让平台团队可以定义集群分组、更新顺序和发布阶段,而不是逐个集群手动操作。
这种能力对应解决的是大规模集群更新的风险控制问题:团队可以先在低风险集群中验证,再逐步推进到生产环境,并结合指标判断是否继续发布,从而降低一次性变更影响大量集群的风险。
跨集群连接
Fleet 管理还需要解决集群之间“彼此隔离”的问题。Cilium Cluster Mesh 提供跨集群网络连接,使服务能够在多个集群之间通信,也让工作负载迁移、故障切换和资源重新分配更可行。
这与 AI 和边缘场景直接相关:当某些位置的资源紧张、GPU 成本较高或某个集群需要维护时,工作负载可以更灵活地移动到其他集群,而不是被固定在单一环境中。
管理价值
这套方案的价值在于把 Kubernetes 管理从单集群操作提升到 fleet 级治理。它通过统一策略、分阶段发布、跨集群网络和自动化生命周期管理,解决企业在大规模 Kubernetes 环境中遇到的更新、调度、安全和一致性问题,减少人工介入带来的复杂度和风险。
2. agent-substrate/substrate:Agent 运行时基础设施
产品/功能简介
Agent Substrate 是一个构建在 Kubernetes 之上的系统,用来运行大规模、长生命周期、状态化的 agent-like workload。
它不是一个 Agent SDK,也不是用来编写 Agent 逻辑的框架,而是一个 Agent 运行时基础设施:负责把大量“Actor”映射到较少数量的 Kubernetes Pod worker 上,并管理它们的生命周期、状态保存、恢复和流量路由。
这里有两个核心概念:
- Actor:逻辑上的应用实例,可以是 AI Agent、代码执行环境、MCP Server、长会话工具等。
- Worker:真实运行在 Kubernetes 中的 Pod,用来承载 Actor。
Agent Substrate 利用一个事实:很多 Agent 大部分时间是空闲的。因此它可以把大量 Actor 复用到少量 ready worker 上,实现高密度运行和资源复用。
核心目标
Kubernetes 本身擅长管理 Pod、节点和基础设施,但对高密度、低延迟、状态化 Agent 场景并不天然合适。
Agent Substrate 的目标是:
- 让大量状态化 Actor 复用少量 Kubernetes Pod
- 避免每次 Actor 激活都走 Kubernetes 控制面创建 Pod
- 降低启动和恢复延迟
- 在 Actor 空闲时挂起,释放计算资源
- 在需要时快速恢复到任意可用 worker
- 保留 Actor 的内存状态和文件系统状态
- 为 Agent workload 提供专用调度和生命周期控制
工作方式
Agent Substrate 在 Kubernetes 之上增加一层 Agent 专用控制面。
Kubernetes 仍然负责:
- 集群基础设施管理
- Pod 生命周期
- 节点调度
- 普通 workload 运行
Agent Substrate 负责:
- Actor 创建和销毁
- Actor suspend / resume
- Actor 到 worker 的实时分配
- Actor 状态快照
- 流量路由到当前承载 Actor 的 worker
- worker 池管理
- 高密度多路复用
这种设计把 Kubernetes 控制面从请求关键路径中移出。Actor 激活时不需要新建 Pod,而是把状态恢复到已有 worker 上,从而降低延迟。
关键能力
- 高密度多路复用
- 状态挂起与恢复
- 低延迟激活
- 框架无关
适用场景
- 大规模 AI Agent 执行平台
- 多用户代码执行环境
- 长生命周期 Agent 会话
- 状态化 MCP Server 托管
- 需要高密度复用的 sandbox
- 空闲时间长、激活延迟要求低的交互式 workload
- 希望继续使用 Kubernetes 管基础设施,但不想让 Kubernetes Pod 创建进入请求关键路径的系统
状态与风险
该项目目前处于非常早期阶段:
- 不适合生产使用
- API 基本确定会变化
- 不承诺向后兼容
- 目前目标支持最新稳定版 Kubernetes 和前一个 minor 版本
- 不是 Google 官方支持产品
- 不符合 Google Open Source Software Vulnerability Rewards Program 资格
🤔 专题七 有意思的事与 Meme
1. Bye bye Nginx (officially) 👋

2. Kubernetes In Anger
一份面向生产 EKS 运维和事故排查的实战手册。