🆕 专题一 产品新功能/新版本
1. 在 Prometheus 3.8.0 中可视化目标重标记规则
Visualizing Target Relabeling Rules in Prometheus 3.8.0
背景
Prometheus 的目标重标记功能允许您调整已发现目标的标签,甚至完全删除该目标。重标记规则虽然功能强大,但可能难以理解和调试。您的规则必须与服务发现机制返回的预期标签相匹配,任何一步出错都可能导致目标标签错误或意外删除。
为了帮助您找出问题所在(或正确之处),Prometheus 3.8.0 新增了一个重新标记可视化工具。 通过 Prometheus 服务器的 Web 用户界面,您可以查看每条重新标记规则如何应用于已发现目标的标签。让我们来看看它是如何工作的!
使用方法
如果您访问任何 Prometheus 服务器的“服务发现”页面(例如:https://demo.promlabs.com/service-discovery),您会发现每个已发现目标旁边新增一个“显示重新标记”按钮:
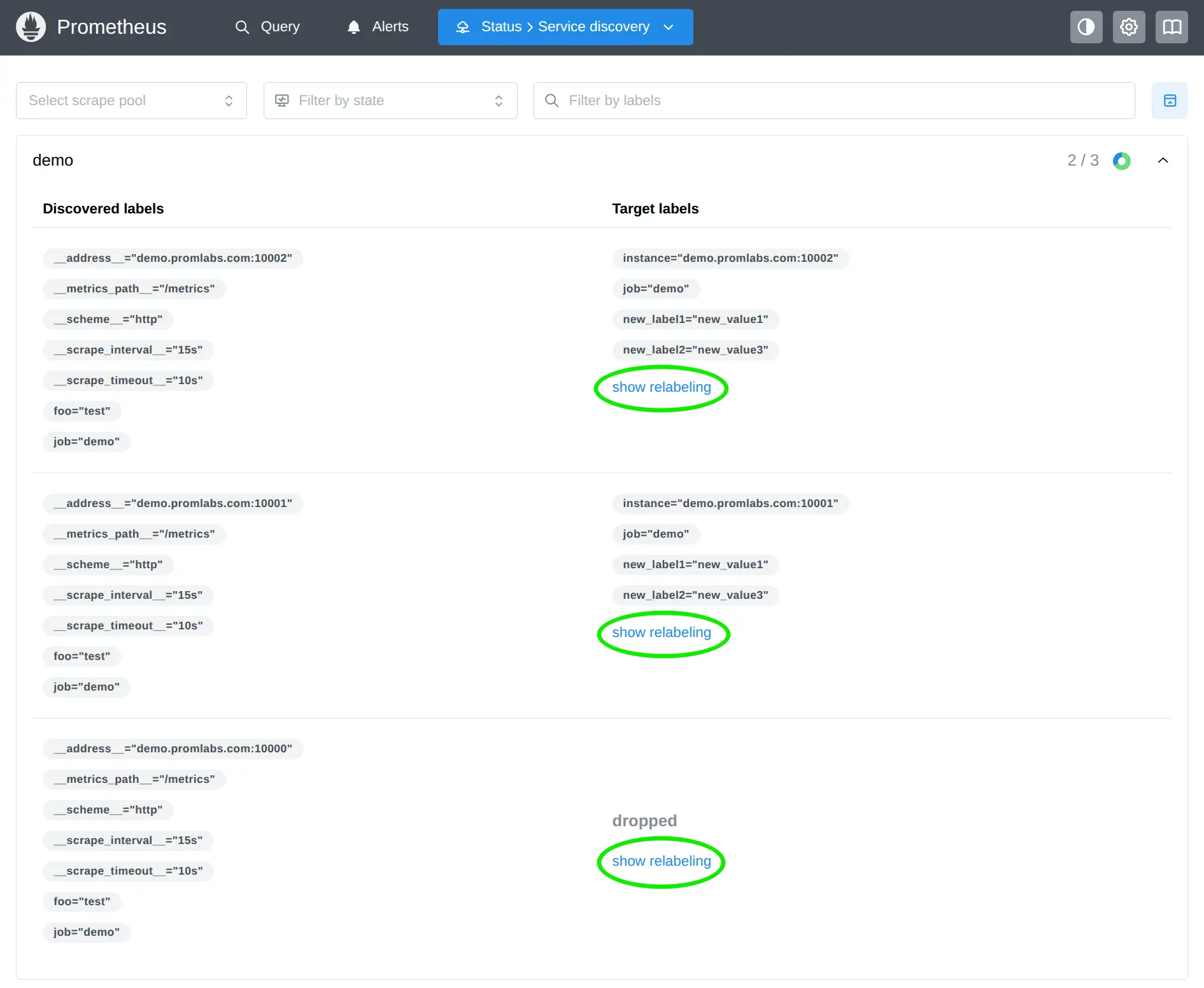
点击此按钮,即可查看每条重新标记规则如何按顺序应用于该特定目标。
可视化工具会向您展示:
- 服务发现机制发现的目标的初始标签。
- 每条重新标记规则的详细信息,包括其操作类型和其他参数。
- 应用每次重新标记规则后标签的变化情况,更改、添加和删除的内容以颜色突出显示。
- 在所有重新标记规则应用之后,最终是保留目标还是放弃目标。
- 如果保留目标,则输出最终标签。
拓展阅读
在 Prometheus 3.8.0 中可视化目标重标签规则
Introducing the Experimental info() Function
2. Karmada v1.16 版本发布!支持多模板工作负载调度
Karmada v1.16 版本发布!支持多模板工作负载调度
背景
Karmada 是开放的多云多集群容器编排引擎,旨在帮助用户在多云环境下部署和运维业务应用。凭借兼容 Kubernetes 原生 API 的能力,Karmada 可以平滑迁移单集群工作负载,并且仍可保持与 Kubernetes 周边生态工具链协同。
🎤 v1.15 在 9 月发布,发版节奏挺快的。
简介
- 支持多模板工作负载调度
- 使用 Webster 算法增强副本分配
- 驱逐队列速率限制
- 持续的性能优化
新增特性概览
1. 支持多模板工作负载调度
在 Karmada v1.16.0 中,我们引入了多模板调度,这是一项全新的能力,使得 Karmada 能够将由多个相互关联组件组成的多模版工作负载完整且统一地调度到具有充足资源的单个成员集群中。
此功能建立在 v1.15 版本引入的多模板工作负载资源精确感知[2]功能之上,该支持使 Karmada 能够准确理解复杂工作负载的资源拓扑。在 v1.16 中,调度器利用这些信息来:
- 基于 ResourceQuota 限制来估算成员集群可以容纳的完整的多模板工作负载数;
- 利用成员集群中实际节点的可用资源来预测工作负载的可调度性。
2. 使用 Webster 算法增强副本分配
Karmada 支持多种副本调度策略,如 DynamicWeight、Aggregated 和 StaticWeight,用于在成员集群之间分配工作负载的副本。这些策略的核心在于将集群权重转化为实际副本数量的算法。
在之前的版本中,副本分配算法存在一定的局限性:
- 非单调性:当总副本数增加时,某些集群可能意外地获得更少的副本;
- 缺乏强幂等性:相同的输入可能产生不同的输出;
- 不公平的余数分配:在具有相同权重的集群之间分配剩余副本时缺乏合理的优先级策略。
在当前版本中,我们引入了 Webster 方法(也称为 Sainte-Laguë 方法)来改进跨集群调度期间的副本分配。通过采用 Webster 算法,Karmada 现在实现了:
- 单调副本分配:增加总副本数绝不会导致任何集群丢失副本,确保行为一致且直观。
- 剩余副本的公平处理:在权重相等的集群间分配副本时,优先考虑当前副本数较少的集群。这种“小优先”方式有助于促进均衡部署,更好地满足高可用性(HA)需求。
3. 驱逐队列速率限制
在多集群环境中,当集群发生故障时,资源需要从故障集群中驱逐并重新调度到健康的集群。如果多个集群同时或在短时间内相继发生故障,大量的驱逐和重新调度操作可能会使健康集群和控制平面不堪重负,进而导致级联故障。
此版本引入了具有速率限制功能的驱逐队列,用于 Karmada 污点管理器。驱逐队列通过可配置的固定速率参数来控制资源驱逐速率,从而增强故障迁移机制。该实现还提供了用于监控驱逐过程的指标,提高了整体系统的可观测性。
这个特性在以下场景特别有用:
- 您需要在大规模故障期间防止级联故障,确保系统不会因为过多的驱逐操作而不堪重负。
- 您希望根据不同环境的特性配置驱逐行为。例如,在生产环境中使用较低的驱逐速率,在开发或测试环境中使用较高的速率。
- 您需要监控驱逐队列的性能,包括待处理驱逐的数量、处理延迟以及成功/失败率,以便调整配置和响应运维问题。
驱逐队列的核心特性包括:
- 可配置的固定速率限制:通过 --eviction-rate 命令行参数配置每秒驱逐速率。示例:设置每 2 秒最多驱逐 1 个资源:--eviction-rate=0.5。
- 完善的指标支持:提供队列深度、资源类型、处理延迟、成功/失败率等指标,便于监控和故障排查。
通过引入速率限制机制,管理员可以更好地控制集群故障迁移期间的资源调度速率,在保障服务稳定性的同时,提升资源调度的灵活性和效率。
4. 持续的性能优化
在 release-1.15 中,我们引入了 controller-runtime 优先级队列[4],它允许基于 controller-runtime 构建的控制器在重启或主从切换后优先处理最新的变更,从而显著减少服务重启和故障转移期间的停机时间。
在 release-1.16 中,我们扩展了这一能力。对于不是基于 controller-runtime 构建的控制器(如 detector controller),我们通过为所有使用异步 worker 的控制器启用优先级队列功能,使它们也能享受到这一优化。
3. Tanzu Platform 10.3 服务发布:内部源代码市场
Tanzu Platform 10.3 Service Publishing: The InnerSource Marketplace
背景
VMware Tanzu 团队认识到,平台扩展不仅仅是部署代码;更重要的是通过促进开发者之间的真正交流来建立信任和标准化。服务发布是内部开源市场的基础,它允许应用团队通过 API 将可重用的组件(无论是数据服务、微服务,还是代码助手的模型上下文协议 (MCP) 服务器)转换为 Tanzu Marketplace 中一流的、受监管的产品。
对于使用 API 的开发者而言,这意味着他们无需再为生成 API 密钥等手动配置而烦恼,而是可以通过简单的集成机制,使用诸如 cf create-service 和 cf bind-service 等可信命令来访问精心策划的服务。对于平台工程师而言,这标志着他们迈向标准化的又一步,并获得了管理内部服务依赖关系所需的必要控制,从而确保整个组织的安全性、性能和资源可预测性。
Tanzu Platform 服务发布是什么?
从本质上讲,服务发布规范化了服务提供者(构建和部署共享服务的团队)与服务使用者(使用该服务的团队)之间的关系。在 Tanzu Platform 10.3 中,这意味着任何已部署的应用程序现在都可以通过 Tanzu Platform 应用市场进行使用。这不仅仅是共享一个 URL;它将已部署的应用程序转化为一个一流的服务实例。Tanzu Platform 通过服务绑定自动处理身份验证、网络配置和环境变量注入等复杂问题。
这实现了内部开源的承诺。内部团队现在可以构建可重用的组件,并为其编写完整的文档和 API 规范,以便于使用,并能像使用公有云服务一样管理和使用这些组件。不同之处在于,这些组件是从您自己的私有应用程序平台交付的,您拥有完全的自主权和控制权。
价值
1. 提高开发者的速度和信任度
对于构建下一代 AI 增强型应用程序的开发人员来说,服务发布将依赖项集成体验从一项繁琐的工作转变为一个无缝的自助服务流程。
- 更便捷的服务使用 ——跨团队协作和已部署服务使用面临的最大障碍之一是文档和上下文信息。借助 Tanzu 平台,开发人员无需再费力查找如何通过 API 使用服务的文档,也无需手动配置端点和凭据。他们只需浏览 Tanzu Marketplace,找到所需的服务(例如产品目录 API、支付服务,甚至是共享 AI 上下文服务器),然后执行两个熟悉的 Cloud Foundry 命令:
cf create-service和cf bind-service。平台会处理必要的网络绑定和路由、管理环境变量以及扩展。这使得开发人员能够专注于核心业务逻辑。 - 信任与一致性 —— 当开发者从市场平台选择服务时,他们知道该服务已经过平台团队的审核和甄选。
- 内部市场竞争力 —— 服务发布商可以通过清晰的文档、操作指南、API 规范和个性化徽标来推广其服务产品,使其产品更具个性,并使其更容易在市场中被发现。
2. 治理与规模兼顾,无需妥协
对于平台工程团队而言,服务发布为整个内部生态系统提供了一个至关重要的治理层,将临时集成转变为可管理、可扩展的应用程序和服务组合。
- 集中审批和管理 —— 平台团队可以立即集中查看所有共享的内部应用程序。他们可以管理哪些服务通过服务市场公开,并确保团队始终使用受支持、安全且优化的组件。这意味着已发布服务的弃用或升级流程将得到显著简化,从而减少技术债务和运维负担。
- 高级运维安全与控制 —— 该平台将 API 网关功能直接集成到发布流程中,使平台工程师能够控制服务交互,从而实现安全性和运维风险管理。这包括配置身份验证策略、使用配额和速率限制、监控和日志记录等功能。
- 使用情况跟踪和容量分析 —— 平台团队需要了解服务消费者是谁,以及他们的使用量。
4. Amazon EKS 引入了增强的网络策略功能
Amazon EKS introduces enhanced network policy capabilities
简介
Amazon EKS 的原生网络策略支持已扩展至包括管理策略(Admin Policies)和应用网络策略(Application Network Policies)。借助这些新增策略,集群管理员(例如平台或安全团队)可以为集群设置集群范围的安全规则,从而增强 Kubernetes 工作负载的整体网络安全。
此外,命名空间管理员(例如应用团队)现在可以使用域名作为过滤器来控制 Pod 对外部资源的流量。这种方法取代了维护特定 IP 地址列表(这些地址经常更改)或宽泛的 CIDR 范围列表(这些范围通常与企业安全策略冲突)的需求,转而支持创建 Pod 可以访问的受信任外部网站和服务列表。您可以将其视为集群出站流量的“允许目标”列表。
背景
集群中的标准 Kubernetes NetworkPolicy 允许您实现虚拟防火墙,从而隔离集群内部的网络流量。这些策略允许您创建规则来管理入站(入口)和出站(出口)流量。您可以根据多个参数限制通信,包括 Pod 标签、命名空间、IP 地址范围(CIDR)和特定端口。
虽然 NetworkPolicy 确实改进了 Kubernetes 默认的“允许所有通信”设置,但它们也存在一些重要的局限性:
- 它们只能控制单个命名空间内的流量,而不能控制整个集群的流量。
- NetworkPolicy 中没有明确的“拒绝”规则。
- NetworkPolicy 的目的是让应用程序所有者通过限制网络流量来控制谁可以与他们的应用程序通信。
换句话说,当每个应用程序团队管理自己的安全规则时,标准网络策略运行良好,但它们并非为以下情况而设计:
- 集群范围安全规则
- 能够覆盖他人的安全设置
- 规则层级结构,其中某些策略优先于其他策略
这使得它们不太适合需要集中式安全控制或更复杂的安全安排的组织。
什么是管理网络策略
管理网络策略旨在让集群管理员集中管理集群中所有 EKS 工作负载的流量隔离,无论它们在哪个命名空间中运行,以符合其组织的安全要求。
Amazon EKS 与 Amazon VPC CNI 现在支持使用单个 CustomResourceDefinition (CRD) 对象实现两种类型的集群范围网络策略:管理层和基线层。
Kubernetes 管理网络策略的评估方式如下所示:
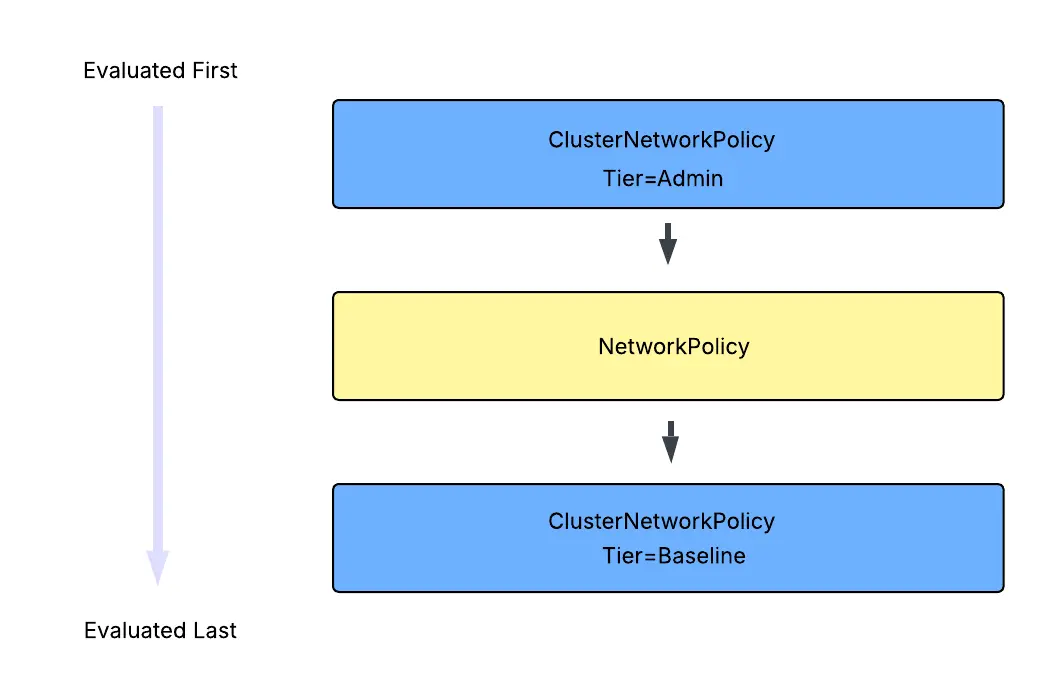
这意味着管理层策略会首先被评估,且无法被覆盖。管理层策略评估完成后,系统会使用标准 NetworkPolicies 来执行命名空间或应用程序所有者所需的网络隔离。最后,系统会强制执行描述集群工作负载默认连接的基线层规则,这些规则可以根据需要被开发人员的 NetworkPolicies 覆盖。
管理网络策略的常见用例:
- 在集群级别隔离命名空间。例如,如果您有敏感工作负载,则可能需要显式阻止来自其他命名空间的任何集群流量进入敏感工作负载命名空间。
- 强制集中式监控解决方案访问所有命名空间,以免本地网络策略无意中阻止您对工作负载的可见性。明确允许所有命名空间向在标准 EKS 集群的 kube-system 命名空间中运行的 kube-dns 发出出口流量。
什么是应用网络策略
应用网络策略通过将传统网络策略与 DNS 过滤整合到单一的、支持命名空间感知的自定义资源定义(CRD)中,帮助管理 Amazon EKS 自动模式集群内的网络流量。当您需要控制 Pod 如何连接到 EKS 集群外部资源时(例如,仅允许 Pod 访问特定的域名),该功能尤其有用。
标准网络策略在 OSI 模型的第 3 层和第 4 层运行,限制您只能使用 IP 地址块和端口号来控制流量目的地;而应用网络策略在 OSI 模型的第 7 层运行,允许您基于完全限定域名 (FQDN) 过滤流量。这意味着它们非常适合在以下场景中管理 Pod 的出站流量:
- 云端到本地通信
- SaaS 服务访问
拓展阅读
Enhance Amazon EKS network security posture with DNS and admin network policies
5. 通过 Amazon ECR Public 扩展容器安全性和选择范围
Expanding container security and choice with Amazon ECR Public
简介
Amazon Elastic Container Registry Public 作为值得信赖的容器镜像发现和分发平台,持续发展壮大。该平台为开发者和企业提供基于 AWS 基础设施构建的强大、安全且灵活的容器镜像仓库体验,并与 AWS 容器服务无缝集成。
Amazon ECR Public 现已提供免费的 Chainguard 可信容器镜像——这些安全强化、精简的容器镜像能够显著降低容器化应用程序中的漏洞。Chainguard 的安全优先理念与 ECR Public 的可靠性和 AWS 集成相结合,使开发人员能够访问通常几乎不包含任何常见漏洞和披露 (CVE) 的容器镜像,这相比通常包含数百个漏洞的传统基础镜像和应用程序镜像有了显著的改进。
为什么选择 Amazon ECR Public
- 可靠性和性能
- AWS 无缝集成
- 经济实惠
- 经验证的发布方
Chainguard 容器:可信容器镜像
Chainguard Containers 现已在 Amazon ECR Public 中提供,它们是经过安全强化的容器镜像。通过直接从 Amazon ECR Public 获取 Chainguard Containers,AWS 客户可以利用这些注重安全性的镜像,同时享受 ECR Public 的可靠性和集成优势。主要优势如下:
- 最小攻击面
- 显著减少的 CVE
- 专为容器而生
- 默认安全
- 每日从源码重建
6. Argo CD 3.3 发行候选版
重要新功能和改进:
- PreDelete Hooks
PreDelete hooks 允许你在 Argo CD 删除应用资源之前,先执行 Job 或其他资源。它就像应用生命周期中的缺失环节——之前有 PreSync、Sync、PostSync,现在有了 PreDelete。 - OIDC 背景令牌刷新
Argo CD 会在令牌过期前自动后台刷新 OIDC 令牌。新增的 refreshTokenThreshold 配置项允许你设置服务器在令牌剩余有效期多长时主动刷新。这样就不会再有 Keycloak 等 OIDC 提供商中途意外登出的情况。 - Source Hydrator 功能增强
- 内联参数支持:不必每次修改都提交参数文件,支持直接在 hydration 时传入参数。(@sangyeong01)
- 更好的 Monorepo 支持:显著提升了 monorepo 工作流的体验。(@pbhatnagar-oss)
- 性能提升:减少不必要的 repo-server 调用,使 hydration 更快更高效。(@pbhatnagar-oss)
- ClusterResourceWhitelist 支持资源名称
之前 clusterResourceWhitelist 在 AppProjects 中只能按 API 组和类型限制访问,如果允许访问 CustomResourceDefinitions,意味着能访问所有 CRD,无法限制到具体某几个。现在可以限制到指定资源名称。 - 支持浅克隆仓库
该功能允许 Argo CD 只拉取所需的提交,而不是完整仓库历史,大大缩短了大仓库的 git fetch 时间,从几分钟降到几秒。 - KEDA 第一类支持
- 暂停 ScaledObject 和 ScaledJob:可以直接在 Argo CD UI 中暂停和恢复 KEDA 资源,方便维护、调试和控制发布。
- ScaledJob 健康检查:Argo CD 现在能识别 KEDA ScaledJob 的健康状态,显示准确状态而非“未知”。
7. Podman Desktop 1.24 版本发布
主要更新
- 配置默认注册表:支持设置默认容器注册表及可选镜像。
- 环境栏显示连接名称:方便在管理多个连接时区分资源。
- Containerfile 中选择构建目标:通过 UI 选择所需构建阶段,简化多阶段构建。
8. Kubernetes 1.35:Timbernetes(世界树版本)发布
发布主题与徽标
2025 年在 Octarine:The Color of Magic(v1.33)的微光中启程, 又乘着 Of Wind & Will(v1.34)的疾风前行。我们在年末将双手搭在世界树上,灵感来自 Yggdrasil——那棵连接诸多世界的生命之树。如同所有伟大的树木,Kubernetes 也在全球社区的悉心呵护下,以年轮为记、以版本为序,不断成长。
在这棵树的中心,是环抱地球的 Kubernetes 方向盘标。它之所以稳固,源于那些始终如一的维护者、贡献者与用户。在本职工作与生活变迁之间,在持续的开源维护之中, 他们修剪旧 API、嫁接新特性,让这个全球最大开源项目之一保持健康。
三只松鼠守护着这棵树:为评阅者举起 LGTM 卷轴的法师;为发布团队挥斧开枝、并举起 Kubernetes 盾牌的战士;以及为分诊者照亮幽深 Issue 队列的提灯游侠。
它们共同象征着一支规模更大的冒险队伍。Kubernetes v1.35 为世界树再添一圈年轮——这一道新切面由无数双手、无数条路径与一个根系更深、枝叶更高的社区共同塑造。

重点更新速览
稳定(GA)阶段:Pod 资源原地更新
Kubernetes 1.35: In-Place Pod Resize Graduates to Stable
Kubernetes 已将 Pod 资源的原地更新特性升级为正式发布(GA)。
该特性允许用户在不重启 Pod 或容器的情况下,调整 CPU 与内存资源。此前,这类修改需要重建 Pod,可能会干扰工作负载,尤其是有状态或批处理应用。更早的 Kubernetes 版本仅允许你为现有 Pod 修改基础设施资源设置(requests 与 limits)。新的原地更新能力支持更平滑、不中断的纵向扩缩容,提高效率,也能简化开发流程。
关键概念:
- 所需资源: 容器的 spec.containers[*].resources 字段现在表示所需的资源。对于 CPU 和内存,这些字段现在是可变的。
- 实际资源: status.containerStatuses[*].resources 字段反映当前为正在运行的容器配置的资源。
- 触发调整大小: 您可以通过更新所需的 requests 来请求调整大小。 并利用新的 resize 大小子资源来限制 Pod 规范中的 limits 。
功能价值:
- 资源调整无需中断。对延迟或重启敏感的工作负载可以就地修改其资源,而不会造成停机或状态丢失。
- 更强大的自动扩缩容系统现在能够以更小的影响调整资源。例如,利用此功能的垂直 Pod 自动扩缩容 (VPA) 的 InPlaceOrRecreate 更新模式已进入 Beta 测试阶段。这使得资源能够根据使用情况自动无缝地调整,并将中断降至最低。
- 满足瞬时资源需求:可以快速调整临时需要更多资源的工作负载。这使得诸如 CPU 启动加速 ( AEP-7862 ) 之类的功能成为可能,应用程序可以在启动期间请求更多 CPU 资源,然后自动缩减。
使用场景:
- 需要根据玩家数量的变化调整自身规模的游戏服务器。
- 预热后的工作单元,不用时可以缩小,但第一次请求时可以膨胀。
- 根据负载动态扩展,实现高效的 bin-packing。
- 增加启动时 JIT 编译所需的资源。
下一步计划:
- 与自动扩缩容器和其他项目的集成
- 功能扩展
- 提升稳定性
Beta:用于工作负载身份与安全的 Pod 证书
此前,要向 Pod 下发证书,往往需要外部控制器(cert-manager、SPIFFE/SPIRE)、CRD 编排以及 Secret 管理,并由边车或 Init 容器负责证书轮换。Kubernetes v1.35 通过自动化证书轮换,实现原生工作负载身份,大幅简化服务网格与零信任架构。
现在,kubelet 会生成密钥,通过 PodCertificateRequest 请求证书,并将凭据包直接写入 Pod 的文件系统。kube-apiserver 会在准入阶段强制执行节点限制,消除第三方签名者最常见的陷阱:无意间突破节点隔离边界。这使得签发路径中无需持有者令牌即可实现纯双向 TLS 流程。
Alpha:调度前节点声明式特性
当控制平面启用新特性、但节点侧进度滞后时(Kubernetes 版本偏差策略允许这种情况),调度器可能会将需要这些特性的 Pod 调度到不兼容的旧节点上。
节点声明式特性框架允许节点声明其所支持的 Kubernetes 特性。启用这一 Alpha 特性后,Node 会通过新的 .status.declaredFeatures 字段上报其支持的特性,并将信息发布到控制平面。随后,kube-scheduler、准入控制器以及第三方组件都可以使用这些声明。例如,你可以强制执行调度与 API 校验约束,确保 Pod 只运行在兼容的节点上。
进入稳定(GA)阶段的特性
PreferSameNode 流量分配
Service 的 trafficDistribution 字段已更新,以便更明确地控制流量路由。新增选项 PreferSameNode:在可用时严格优先选择本节点上的端点,否则再回退到远端端点。
同时,现有的 PreferClose 选项已重命名为 PreferSameZone。这一变更让 API 更加直观、自解释:它明确表示优先在当前可用区内选择流量路径。虽然为了向后兼容仍保留 PreferClose,但 PreferSameZone 现在是可用区级别路由的标准选项,确保“节点级”与“可用区级”的偏好能够清晰区分。
Job API 的 managed-by 机制
Kubernetes v1.35: Job Managed By Goes GA
Job API 新增 managedBy 字段,允许外部控制器接管 Job 状态同步。该特性在 Kubernetes v1.35 中进入稳定(GA)阶段,主要由 MultiKueue 推动。MultiKueue 是一种多集群分发系统,在管理集群创建的 Job 会被镜像到工作集群执行,并将状态更新回传。为实现这一工作流,需要让内置 Job 控制器不要处理某个特定 Job 资源,从而由 Kueue 控制器接管状态更新。
其目标是让 Job 同步能够清晰地委派给另一个控制器。它并不意图向该控制器传递自定义参数,也不打算修改 CronJob 的并发策略。
工作原理:
.spec.managedBy 字段指示哪个控制器负责该作业,具体来说,有两种操作模式:
- 标准 :如果未设置或设置为保留值 kubernetes.io/job-controller ,则内置的 Job 控制器将照常协调 Job(标准行为)。
- 委托 :如果设置为任何其他值,则内置的作业控制器将完全跳过该作业的协调。
使用 .metadata.generation 可靠跟踪 Pod 更新
在历史上,Pod API 缺少 metadata.generation 字段(其他对象例如 Deployment 具备该字段)。因此,控制器与用户无法可靠地确认 kubelet 是否已经处理了 Pod 规约的最新变更。这种不确定性在诸如Pod 资源原地纵向扩缩容 等特性中尤为突出,因为很难精确判断资源调整请求何时真正生效。
Kubernetes v1.33 以 Alpha 形式为 Pod 增加了 .metadata.generation 字段。在 v1.35 的 Pod API 中,该字段已进入稳定(GA)阶段。每当更新 Pod 的 spec 时,.metadata.generation 的值都会递增。作为这一改进的一部分,Pod API 还新增了 .status.observedGeneration 字段,用于报告 kubelet 已经成功看到并处理的 generation。Pod 的各类状况(conditions)也各自包含独立的 observedGeneration 字段,客户端可以上报和/或观测这些字段。
由于该特性在 v1.35 进入稳定(GA)阶段,它对所有工作负载可用。
为拓扑管理器提供可配置 NUMA 节点上限
拓扑管理器过去使用硬编码上限 8,作为其可支持的 NUMA 节点最大数量,以避免在亲和性计算期间出现状态爆炸。这里有个重要细节:NUMA 节点(NUMA node)与 Kubernetes API 中的 Node 并不是同一概念。这一 NUMA 节点数量上限,限制了 Kubernetes 对现代高端服务器的充分利用,因为这类服务器越来越常见地采用拥有超过 8 个 NUMA 节点的 CPU 架构。
Kubernetes v1.31 为拓扑管理器策略配置引入了新的 Beta 选项max-allowable-numa-nodes。在 Kubernetes v1.35 中,该选项已进入稳定(GA)阶段。启用该选项的集群管理员可以使用拥有超过 8 个 NUMA 节点的服务器。
尽管这一配置选项已进入稳定(GA)阶段,Kubernetes 社区仍注意到在大型 NUMA 主机上性能欠佳,并提出了旨在改进该问题的增强提案(KEP-5726)。要了解更多信息,请阅读在节点上控制拓扑管理策略。
Kubelet 配置插件目录
Kubernetes v1.35: Kubelet Configuration Drop-in Directory Graduates to GA
随着 Kubernetes 最新发布的 v1.35 版本,kubelet 配置的 drop-in 目录功能已正式上线。这项新推出的稳定功能简化了跨大型异构集群的 kubelet 配置管理。
从 v1.35 版本开始,kubelet 命令行参数 --config-dir 已正式上线并得到全面支持,允许您指定一个包含 kubelet 配置插入文件的目录。该目录中的所有文件都将自动合并到您的主 kubelet 配置中。这使得集群管理员能够在维护统一的 kubelet 基础配置的同时,针对不同的节点组或用例进行定制,而无需复杂的工具或手动配置管理。
问题:
随着 Kubernetes 集群规模的扩大和复杂性的增加,它们通常包含具有不同硬件配置、工作负载需求和运维限制的异构节点池。这种多样性导致不同节点组需要不同的 kubelet 配置——然而,大规模管理这些多样化的配置变得越来越具有挑战性。由此产生了几个痛点:
- 配置漂移 :不同节点的配置可能略有不同,从而导致行为不一致。
- 节点组自定义 :GPU 节点、边缘节点和标准计算节点通常需要不同的 kubelet 设置。
- 运维开销 :为每种节点类型维护单独的、完整的配置文件容易出错且难以审计。
- 变更管理 :在异构节点池中部署配置变更需要精心协调。
具体的使用方式见链接原文。
精细的补充组控制
Kubernetes v1.35: Fine-grained Supplemental Groups Control Graduates to GA
新的 Pod 字段 supplementalGroupsPolicy 最初作为 Kubernetes v1.31 的可选 alpha 功能推出,随后在 v1.33 升级为 beta 版。现在,该功能已正式发布。此功能允许您对 Linux 容器中的补充组进行更精确的控制,从而增强安全性,尤其是在访问卷时。此外,它还提高了容器中 UID/GID 详细信息的透明度,从而提供更完善的安全监管。
背景:
默认情况下,Kubernetes 会将 Pod 中的组信息与容器镜像中 /etc/group 文件中定义的信息合并。容器镜像中隐式合并的 /etc/group 中的组信息存在安全风险。由于 Pod 清单中没有这些隐式 GID 的记录,策略引擎无法检测或验证它们。这可能导致意外的访问控制问题,尤其是在访问卷时(详情请参见 kubernetes/kubernetes#112879 ),因为在 Linux 系统中,文件权限是由 UID/GID 控制的。
Beta 中的新特性
通过 Downward API 暴露节点拓扑标签
过去,要在 Pod 内访问节点拓扑信息(例如区域与可用区),通常需要查询 Kubernetes API 服务器。 这种做法虽然可行,但为了获取基础设施元数据,往往需要授予较宽泛的 RBAC 权限,或引入边车容器,从而带来复杂度与安全风险。 Kubernetes v1.35 将“通过 Downward API 直接暴露节点拓扑标签”的能力提升为 Beta。
现在,kubelet 可以将标准拓扑标签(例如 topology.kubernetes.io/zone 与 topology.kubernetes.io/region)注入到 Pod 中,以环境变量或投射卷文件(projected volume files)的形式呈现。其主要收益是让工作负载以更安全、更高效的方式具备拓扑感知能力。应用可以在不依赖 API 服务器的情况下原生适配其所在可用区或区域,通过坚持最小特权原则来增强安全性,并简化集群配置。
说明:Kubernetes 现在会为每个 Pod 注入可用的拓扑标签, 使其可以作为 Downward API 的输入。升级到 v1.35 后,大多数集群管理员会看到每个 Pod 新增了若干标签;这是设计的一部分,属于预期行为。
存储版本迁移的原生支持
在 Kubernetes v1.35 中,存储版本迁移的原生支持升级为 Beta 并默认启用。这一改动将迁移逻辑直接集成到 Kubernetes 核心控制平面(in-tree)中,从而消除对外部工具的依赖。
在过去,管理员依赖手工的“读/写循环”(read/write loops),常见做法是把 kubectl get 的输出通过管道传给 kubectl replace,用来更新资源的模式(Schema)或重新加密静态数据。这种方式效率低且容易产生冲突,尤其是对 Secret 这类较大的资源更是如此。在本次发布中,内置控制器会自动处理更新冲突与一致性令牌,以更安全、简化且可靠的方式确保存储数据保持最新,并将运维开销降到最低。
可变更的卷挂接上限
CSI(Container Storage Interface)驱动是 Kubernetes 插件,为存储系统向容器化工作负载暴露能力提供一致的方式。 CSINode 对象会记录节点上安装的所有 CSI 驱动的详细信息。不过,节点上报告的挂接容量与实际挂接容量可能出现不一致:当 CSI 驱动启动后卷槽位被消耗时,kube-scheduler 可能把有状态 Pod 调度到挂接容量不足的节点上,最终卡在 ContainerCreating 状态。
Kubernetes v1.35 使 CSINode.spec.drivers[*].allocatable.count 可变更,以便动态更新节点可用的卷挂接容量。它还通过 CSIDriver 对象引入可配置的刷新间隔,允许 CSI 驱动控制在所有节点上更新 allocatable.count 值的频率。
此外,当检测到因容量不足导致的卷挂接失败时,它会自动更新 CSINode.spec.drivers[*].allocatable.count。尽管该特性在 v1.34 中已升级为 Beta,但当时特性门控 MutableCSINodeAllocatableCount 默认关闭;在 v1.35 中它仍处于 Beta,以便留出反馈时间,同时该特性门控默认启用。
机会式批处理
在过去,Kubernetes 调度器按顺序处理 Pod,其时间复杂度为 O(Pod 个数 × 节点个数),这会导致对“可兼容 Pod”执行重复计算。此 KEP 引入一种机会式批处理机制,旨在通过 Pod scheduling signature 识别这类可兼容 Pod 并将它们批量处理,从而在这些 Pod 之间共享过滤与打分结果以提升性能。
Pod 调度签名(Pod Scheduling Signature)机制确保从调度视角看,具有相同签名的两个 Pod 是“相同的”。 它不仅会考虑 Pod 与节点属性,还会纳入系统中的其他 Pod 以及有关放置的全局数据。这意味着:具有给定签名的任意 Pod,在任意一组节点上都会得到相同的打分/可行性判断结果。
该批处理机制包含两个可按需调用的操作:create 与 nominate。create 会基于具有有效签名的 Pod 的调度结果,创建一组新的批处理信息。nominate 会使用 create 生成的批处理信息,为一个新 Pod(其签名与规范 Pod 的签名一致)设置提名的节点名称。
StatefulSet 的 maxUnavailable
StatefulSet 运行一组 Pod,并为其中每个 Pod 维护粘性身份(Sticky Identity)。这对需要稳定网络标识符或持久存储的有状态工作负载至关重要。当 StatefulSet 的 .spec.updateStrategy.<type> 设置为 RollingUpdate 时,StatefulSet 控制器会删除并重建 StatefulSet 中的每个 Pod。它会按 Pod 终止的顺序(从最大序号到最小序号)推进,一次只更新一个 Pod。
Kubernetes v1.24 在 StatefulSet 的 rollingUpdate 配置中新增了一个 Alpha 字段 maxUnavailable,除非你的集群管理员显式选择启用,否则该字段不会出现在 Kubernetes API 中。在 Kubernetes v1.35 中,该字段升级为 Beta 且默认可用。你可以用它定义更新期间最多允许不可用的 Pod 数量。该设置与将 .spec.podManagementPolicy 设为 Parallel 组合使用时最有效。你可以把 maxUnavailable 设置为一个正整数(例如:2),或设置为期望 Pod 数量的百分比(例如:10%)。如果未指定该字段,它默认为 1,以保持此前“一次只更新一个 Pod”的行为。这一改进使有状态应用(可容忍多个 Pod 同时不可用)能够更快完成更新。
kuberc 中可配置的凭据插件策略
可选的 kuberc 文件用于将服务器配置与集群凭据和用户偏好相分离,而不会因意外输出而打断已经在运行的 CI 流水线。
作为 v1.35 发布的一部分,kuberc 增加了允许用户配置凭据插件策略的能力。此变更引入两个字段:credentialPluginPolicy(允许或拒绝所有插件), 以及 credentialPluginAllowlist(允许指定允许插件的列表)。
KYAML
YAML 是一种便于人类阅读的数据序列化格式。 在 Kubernetes 中,YAML 文件用于定义与配置资源,例如 Pod、Service 与 Deployment。 不过,复杂 YAML 很难阅读:YAML 对缩进与嵌套要求严格; 同时,其可选的字符串引用也可能导致意外的类型强制转换(参见:The Norway Bug)。 虽然 JSON 可以作为一种替代方案,但它不支持注释,并对尾随逗号与键的引号有严格要求。
KYAML 是专为 Kubernetes 设计的、更安全且更少歧义的 YAML 子集。 它在 v1.34 作为可选的 Alpha 特性引入, 并在 Kubernetes v1.35 升级为 Beta 且默认启用。 你可以通过设置环境变量 KUBECTL_KYAML=false 来禁用它。
KYAML 旨在解决 YAML 与 JSON 的一些共性挑战。 所有 KYAML 文件也都是合法的 YAML 文件, 这意味着你可以编写 KYAML 并将其作为输入提供给任意版本的 kubectl。 这也意味着,即使输入并非严格 KYAML,也仍然可以被解析。
可配置的 HorizontalPodAutoscalers 容忍度
水平 Pod 自动扩缩容器(Horizontal Pod Autoscaler,HPA)长期依赖固定的全局 10% 容忍度来执行扩缩容。 这一硬编码值的缺点是:对需要高灵敏度的工作负载(例如希望在负载增加 5% 时就扩容)不够友好, 这些工作负载常常无法触发扩缩容;而另一些工作负载则可能产生不必要的振荡。
在 Kubernetes v1.35 中,“可配置容忍度”特性升级为 Beta 并默认启用。 该增强允许用户在 HPA 的 behavior 字段中,按资源粒度定义自定义容忍窗口。 通过设置特定容忍度(例如将其降低到 0.05 来表示 5%),运维人员可以更精确地控制自动扩缩容灵敏度, 确保关键工作负载能对小幅指标变化快速响应,而无需进行集群范围的配置调整。
Pod 中的用户命名空间支持
Kubernetes 增加了对用户命名空间(user namespaces)的支持, 使 Pod 可以使用相互隔离的用户/组 ID 映射运行,而不是共享主机上的 ID。 这意味着容器在内部可以以 root 身份运行, 但在主机上实际映射为一个非特权用户,从而在发生入侵时降低提权风险。 该特性提升了 Pod 级别的安全性,使需要在容器内使用 root 的工作负载更安全。 随着时间推移,该能力也通过 ID 映射挂载(id-mapped mounts)扩展到无状态与有状态 Pod。
VolumeSource:OCI 工件和/或镜像
在创建 Pod 时,你常常需要为容器提供数据、二进制文件或配置文件。 这通常意味着要么把内容打进主容器镜像,要么使用自定义 Init 容器下载并解包到 emptyDir 中。 这两种方式仍然有效。Kubernetes v1.31 增加了对 image 卷类型的支持, 允许 Pod 以声明的方式拉取并将 OCI 容器镜像工件解包到卷中。 这使你可以使用标准 OCI 镜像库工具来打包与分发纯数据工件,例如配置、二进制文件或机器学习模型。
借助该特性,你可以将数据与容器镜像彻底分离,并去除额外 Init 容器或启动脚本的需求。 image 卷类型自 v1.33 起处于 Beta,并在 v1.35 中默认启用。 请注意,使用该特性需要兼容的容器运行时,例如 containerd v2.1 或更高版本。
对缓存镜像强制执行 kubelet 凭据校验
当前,imagePullPolicy: IfNotPresent 允许 Pod 使用节点上已经缓存的容器镜像, 即使 Pod 本身并不具备拉取该镜像所需的凭据。这种行为在多租户集群中会带来安全漏洞: 如果某个具备有效凭据的 Pod 把敏感的私有镜像拉取到某节点上, 同一节点上后续的未授权 Pod 只需依赖本地缓存就能访问该镜像。
此 KEP 引入一种机制:由 kubelet 对缓存镜像强制执行凭据校验。 在允许 Pod 使用本地缓存镜像之前,kubelet 会检查 Pod 是否具备拉取该镜像的有效凭据。 这确保只有经授权的工作负载才能使用私有镜像, 无论该镜像是否已经存在于节点上,从而显著增强共享集群的安全性。
在 Kubernetes v1.35 中,该特性升级为 Beta 并默认启用。 用户仍可将 KubeletEnsureSecretPulledImages 特性门控设为 false 来禁用它。 此外,imagePullCredentialsVerificationPolicy 参数允许运维人员配置期望的安全级别, 从优先保证向后兼容的模式到提供最高安全性的严格强制模式不等。
细粒度的容器重启规则
在过去,restartPolicy 字段只能在 Pod 级别定义,从而强制 Pod 内所有容器采用相同行为。 这一全局设置对复杂工作负载(例如 AI/ML 训练作业)缺乏足够的粒度。 这类作业往往需要 Pod 使用 restartPolicy: Never 以管理作业完成, 但某些容器仍希望能针对可重试的特定错误(如网络抖动或 GPU 初始化失败)执行原地重启。
Kubernetes v1.35 通过在容器 API 本身中启用 restartPolicy 与 restartPolicyRules 来解决这一问题。这允许用户为单个普通容器与 Init 容器定义重启策略, 并使其与 Pod 的整体策略相互独立。例如,你可以将容器配置为仅在以特定错误码退出时才自动重启, 从而避免因短暂故障而重调度整个 Pod 的昂贵开销。
在本次发布中,该特性升级为 Beta 并默认启用。用户可以立即在容器规约中使用 restartPolicyRules, 为长时间运行的工作负载优化恢复时间与资源利用率,而无需改变 Pod 更宏观的生命周期逻辑。
CSI 驱动可选择通过 secrets 字段获取 ServiceAccount 令牌
在向 CSI(Container Storage Interface)驱动提供 ServiceAccount 令牌时, 传统上依赖把令牌注入到 volume_context 字段中。 这种方式存在显著安全风险:volume_context 主要用于非敏感配置数据, 并且常被驱动与调试工具以明文形式记录到日志中,从而可能泄露凭据。
Kubernetes v1.35 引入一套可选择启用的机制, 让 CSI 驱动通过 NodePublishVolume 请求中的专用 secrets 字段获取 ServiceAccount 令牌。 驱动现在可以在其 CSIDriver 对象中将 serviceAccountTokenInSecrets 设为 true 来启用此行为, 从而指示 kubelet 以更安全的方式填充该令牌。
其主要收益是防止凭据在日志与错误信息中被意外暴露。 这一变更确保敏感的工作负载身份通过合适的安全通道处理, 在保持对既有驱动向后兼容的同时,也更符合密文管理最佳实践。
Deployment 状态:正在终止的副本计数
在过去,Deployment 状态会提供可用副本与已更新副本的详细信息, 但缺少对“正在关闭过程中的 Pod”的明确可见性。 这一缺失使用户与控制器难以区分“稳定的 Deployment”与“仍有 Pod 正在执行清理任务或处于较长优雅终止期”的 Deployment。
Kubernetes v1.35 将 Deployment 状态中的 terminatingReplicas 字段提升为 Beta。 该字段提供已设置删除时间戳但尚未从系统移除的 Pod 数量。该特性是一个更大计划中的基础一步, 旨在改进 Deployment 如何处理 Pod 替换,并为未来制定“在滚动发布期间何时创建新 Pod”的策略奠定基础。
其主要收益是提升生命周期管理工具与运维人员的可观测性。 通过公开正在终止的 Pod 数量,可以让外部系统做出更明智的决策, 例如在继续后续任务之前等待完全关闭,而无需手工查询并筛选各个 Pod 的列表。
Alpha 阶段的新特性
Kubernetes 中的 Gang 调度支持
Kubernetes v1.35: Introducing Workload Aware Scheduling
对相互依赖的工作负载(例如 AI/ML 训练作业或 HPC 仿真)进行调度, 传统上一直很有挑战性,因为默认的 Kubernetes 调度器会逐个调度 Pod。 这常导致“部分调度”:部分 Pod 已启动,而其他 Pod 由于资源不足无限期等待, 从而引发死锁并浪费集群容量。
Kubernetes v1.35 通过新的 Workload API 与 PodGroup 概念, 引入对所谓成组调度(Gang Scheduling)的原生支持。 该特性实现“全有或全无”的调度策略:只有当集群有足够资源同时容纳整个 Pod 组时,才会对该组进行调度。
其主要收益是提升批处理与并行工作负载的可靠性与效率。通过避免部分部署,它消除了资源死锁, 并确保昂贵的集群容量只在能够运行完整作业时才会被使用,从而显著优化大规模数据处理任务的编排。
新的 Workload API 资源是 scheduling.k8s.io/v1alpha1 API 组的一部分。该资源以结构化、机器可读的方式定义了多 Pod 应用的调度需求。用户工作负载(例如 Jobs)定义了要运行的内容,而 Workload 资源则决定了如何调度一组 Pod,以及如何在整个生命周期内管理其部署位置。
gang 策略强制执行要么全部执行要么全部不执行的调度方式。如果没有组调度,作业可能只被部分调度,消耗资源却无法运行,导致资源浪费和潜在的死锁。
当您创建属于 GangScheduled Pod 组的 Pod 时,调度器的 GangScheduling 。 插件独立管理每个 pod 组(或副本键)的生命周期:
- 当你创建 Pod(或者控制器为你创建 Pod)时,调度器会阻止它们进行调度,直到:
- 已创建引用的工作负载对象。
- 引用的 pod 组存在于工作负载中。
- 该组中待处理的 Pod 数量满足您的 minCount 。
- 当足够多的 Pod 到达时,调度器会尝试将它们部署到节点上。然而,Pod 并不会立即绑定到节点,而是在 Permit 门前等待。
- 调度程序检查是否已找到整个组的有效分配(至少 minCount )。
- 如果组内有足够的空间,则闸门打开,所有 Pod 都绑定到节点。
- 如果在超时时间(设置为 5 分钟)内只有一部分 Pod 被成功调度,调度器将拒绝该组中的所有 Pod。它们将返回队列,从而释放预留资源供其他工作负载使用。
受限的身份扮演(Impersonation)
在过去,Kubernetes RBAC 中的 impersonate 动词按“全有或全无”运作: 一旦用户被授权可以扮演某个目标身份,就会获得该身份所关联的全部权限。 这种宽泛授权的缺点是违背最小特权原则,使管理员难以将模拟者的权限限制到特定动作或特定资源上。
Kubernetes v1.35 引入一个新的 Alpha 特性:受限的身份扮演(Constrained Impersonation), 它在身份扮演流程中增加一次二次鉴权检查。当 ConstrainedImpersonation 特性门控被启用后, API 服务器不仅会校验基础的 impersonate 权限,还会使用新的动词前缀(例如 impersonate-on:<mode>:<verb>) 检查身份扮演者是否被授权执行特定动作。 这使管理员可以定义细粒度策略——例如允许支持工程师模拟集群管理员仅用于查看日志, 而不授予完整的管理员访问权限。
Kubernetes 组件的 Flagz
在过去,要验证 Kubernetes 组件(例如 API 服务器或 kubelet)的运行时配置, 通常需要对宿主机节点或进程参数具有特权访问权限。 为解决这一问题,引入了 /flagz 端点,通过 HTTP 公开其命令行选项。 但其最初输出仅为纯文本,使自动化工具难以可靠地解析并校验配置。
在 Kubernetes v1.35 中,/flagz 端点增强为支持结构化、机器可读的 JSON 输出。 经授权的用户现在可以通过标准 HTTP 内容协商请求版本化的 JSON 响应, 同时原先的纯文本格式仍保留,便于人工查看。 此更新显著改进可观测性与合规工作流,让外部系统无需脆弱的文本解析或直接基础设施访问, 即可通过编程方式审计组件配置。
Kubernetes 组件的 Statusz
传统上,排查 kube-apiserver 或 kubelet 等 Kubernetes 组件问题, 往往需要解析非结构化日志或文本输出,这种方式脆弱且难以自动化。 此前虽然存在基础的 /statusz 端点, 但缺乏标准化、机器可读的格式,从而限制了外部监控系统的可用性。
在 Kubernetes v1.35 中,/statusz 端点增强为支持结构化、机器可读的 JSON 输出。 经授权的用户现在可以通过标准 HTTP 内容协商请求这一格式, 以获取精确的状态数据——例如版本信息与健康指标——而无需依赖脆弱的文本解析。 该改进为所有核心组件的自动化调试与可观测性工具提供了可靠且一致的接口。
CCM:基于 Informer 的 Watch 式路由控制器调谐
Kubernetes v1.35: Watch Based Route Reconciliation in the Cloud Controller Manager
在云环境中管理网络路由,传统上依赖云控制器管理器(CCM)定期轮询云提供商 API 来校验并更新路由表。 这种固定间隔的调谐方式可能效率不高, 常会产生大量不必要的 API 调用,并在节点状态变化与路由更新之间引入延迟。
在 Kubernetes v1.35 中,cloud-controller-manager 库为路由控制器引入基于 watch 的调谐策略。 控制器不再依赖定时器,而是利用 Informer 监听特定的 Node 事件,例如新增、删除或相关字段更新, 仅在确有变更发生时触发路由同步。
其主要收益是显著减少对云提供商 API 的使用,从而降低触发速率限制的风险并减少运维开销。 此外,这种事件驱动模型通过确保路由表在集群拓扑变化后立即更新,提升了集群网络层的响应速度。
用于基于阈值放置的扩展容忍度运算符
Kubernetes v1.35 通过允许工作负载表达可靠性要求,引入 SLA 感知调度(SLA-aware scheduling)。 该特性为容忍度增加数值比较运算符, 让 Pod 可以依据与 SLA 相关的污点(例如服务保障或故障域质量)来匹配或避开节点。
其主要收益是让调度器具备更精确的放置能力。关键工作负载可要求更高 SLA 的节点, 而低优先级工作负载则可选择使用较低 SLA 的节点。这在不牺牲可靠性的前提下提升了利用率并降低成本。
Job 挂起时可变更的容器资源
运行批处理工作负载时,经常需要对资源限制进行反复试错。 目前 Job 规约是不可变的,这意味着当 Job 因内存不足(OOM)或 CPU 不足而失败时, 用户无法直接调整资源;他们必须删除 Job 并重新创建,从而丢失执行历史与状态信息。
Kubernetes v1.35 引入一种能力:对处于挂起状态的 Job 更新资源请求与限制。 通过 MutableJobPodResourcesForSuspendedJobs 特性门控启用后, 用户可以暂停一个失败的 Job,修改其 Pod 模板中的资源值,然后在修正配置后恢复执行。
其主要收益是让配置错误的 Job 具备更平滑的恢复流程。 通过允许在挂起期间进行原地修正,用户可以消除资源瓶颈, 而不会破坏 Job 的生命周期标识,也不会丢失完成状态追踪, 从而显著改善批处理场景下的开发体验。
其他值得关注的变更
动态资源分配(DRA)的持续创新
核心能力在 v1.34 中进阶至稳定(GA)阶段,并允许关闭。 在 v1.35 中,此特性将始终被启用。此外,若干 Alpha 特性也得到了显著改进,已准备好进行测试。 我们鼓励用户就这些能力提供反馈,以帮助它们在后续版本中更顺利地走向 Beta。
通过 DRA 扩展资源请求
相较于通过设备插件(Device Plugins)实现的扩展资源请求, 当前版本补齐了若干特性差距,例如对 Init 容器中设备的打分与复用能力。
设备污点与容忍度
新的 “None” 效果可用于报告问题,而不会立刻影响调度或正在运行的 Pod。 DeviceTaintRule 现在还会提供正在进行驱逐的状态信息。 在真正开始驱逐 Pod 之前,可以先用 “None” 效果进行一次“演练”(dry run):
- 使用 effect: None 创建 DeviceTaintRule。
- 检查状态,了解将会驱逐多少个 Pod。
- 将 effect: None 替换为 effect: NoExecute。
可切分设备
属于同一类可切分设备(Partitionable Devices)的设备, 现在可以定义在不同的 ResourceSlice 中。
可消耗容量与设备绑定条件
该版本修复了若干缺陷并添加了更多测试。
可比较的资源版本语义
Kubernetes v1.35 改变了客户端被允许解释资源版本(resource versions)的方式。
在 v1.35 之前,客户端唯一受支持的比较方式是字符串相等性检查: 如果两个资源版本相等,它们就是同一个版本。 客户端也可以向 API 服务器提供资源版本,并请求控制平面执行内部比较, 例如流式获取自某个资源版本以来的所有事件。
在 v1.35 中,所有 in-tree 的资源版本都满足更严格的新定义: 它们的取值是一种特殊形式的十进制数。由于这些值可比较, 客户端也可以自行比较两个不同的资源版本。
例如,这意味着客户端在崩溃后重新连接时,可以检测自己是否丢失了更新, 而不仅仅是判断“期间是否有更新但没有丢失变更”的情况。
这一语义变更还支撑了其他重要用例,例如存储版本迁移、对 informers(一种客户端辅助概念)的性能改进,以及控制器可靠性提升。这些用例都需要能够判断一个资源版本是否比另一个更新。
弃用、移除与社区更新
Ingress NGINX 退役
这虽然并非严格意义上的 v1.35 发布内容, 但它影响重大,我们希望在这里特别强调。
Kubernetes 项目宣布 Ingress NGINX 将仅提供尽力而为的维护, 直至 2026 年 3 月。 此日期之后,该项目将归档并不再更新。 推荐的后续路径是迁移到 Gateway API, 它提供了更现代、更安全且更可扩展的流量管理标准。
移除对 cgroup v1 的支持
在 Linux 节点的资源管理方面,Kubernetes 历史上依赖 cgroups(control groups)。 尽管最初的 cgroup v1 可以工作,但它常常不一致且存在局限。 因此,Kubernetes 在 v1.25 引入对 cgroup v2 的支持, 提供了更干净的统一层级结构与更好的资源隔离能力。
由于 cgroup v2 现已成为现代标准, Kubernetes 准备在 v1.35 中退役遗留的 cgroup v1 支持。 这对集群管理员而言是一项重要提醒: 如果你仍在运行不支持 cgroup v2 的旧 Linux 发行版节点, 你的 kubelet 将无法启动。 为避免停机,你需要将这些节点迁移到启用了 cgroup v2 的系统上。
kube-proxy 中 ipvs 模式的弃用
多年前,Kubernetes 在 kube-proxy 中采用ipvs 模式, 以提供比标准iptables 更快的负载均衡。 虽然它带来了性能提升,但为了跟上不断演进的网络需求, 维护其一致性所带来的技术债与复杂度已过高。
由于这一维护负担,Kubernetes v1.35 弃用 ipvs 模式。尽管该模式在本次发布中仍可用, 但当 kube-proxy 被配置为使用该模式时,将在启动时发出警告。 该弃用的目标是精简代码库并聚焦于现代标准。 对于 Linux 节点,你应开始迁移到nftables, 它现在是推荐的替代方案。
containerd v1.X 的最后通告
尽管 Kubernetes v1.35 仍支持 containerd 1.7 与其他 LTS 版本, 但这是最后一个提供此类支持的版本。 SIG Node 社区已将 v1.35 指定为最后一个支持 containerd v1.X 系列的版本。
这是一条重要提醒: 在升级到下一个 Kubernetes 版本之前,你必须切换到 containerd 2.0 或更高版本。 为帮助识别哪些节点需要关注,你可以在集群中监控 kubelet_cri_losing_support 指标。
kubelet 重启期间的 Pod 稳定性改进
此前,重启 kubelet 服务往往会造成 Pod 状态的短暂波动。在重启期间,kubelet 会重置容器状态, 导致健康的 Pod 被标记为 NotReady 并从负载均衡器中移除,即便应用本身仍在正常运行。
为解决这一可靠性问题,该行为已被修正,以确保节点维护更平滑。 kubelet 现在会在启动时从运行时中正确恢复现有容器状态, 确保你的工作负载保持 Ready,并使流量在 kubelet 重启或升级期间持续不中断。
拓展阅读
Kubernetes 1.35: Deep dive into new alpha features
Kubernetes 1.35 - New security features
Kubernetes 1.35 “Timbernetes” Introduces Vertical Scaling
Kubernetes v1.35 重磅发布 :迈向更现代、更稳定的生产级基础设施能力
Kubernetes: Get the Most from Dynamic Resource Allocation
Kubernetes GPU Management Just Got a Major Upgrade
🎤 随着 1.35 被逐步使用,后续会有更多分析的文章发布。
9. Lima v2.0:为安全AI工作流带来新特性
Lima 是什么
Lima 启动 Linux 虚拟机,并具有自动文件共享和端口转发功能(类似于 WSL2)。
Lima 的最初目标是推广 containerd,包括 nerdctl(containNERD ctl)。Lima 适用于 Mac 用户,但也可以用于非容器应用程序。
Lima 还支持其他容器引擎(Docker、Podman、Kubernetes 等)和非 macOS 主机(Linux、NetBSD 等)。
v2.0 更新内容
-
插件支持
- VM 驱动插件:支持更多虚拟机管理程序。
- CLI 插件:为limactl命令增加子命令。
- URL 方案插件:支持limactl create SCHEME:SPEC中传入更多 URL 方案。
-
GPU 加速
- Lima 新增 krunkit VM 驱动,支持 macOS 主机上的 Linux 虚拟机 GPU 加速。
-
模型上下文协议(MCP)
Lima 提供了 MCP 工具,通过 VM 沙箱安全地执行本地文件的读写和命令执行
📰 专题二 新闻与访谈
1. Cedar 作为沙盒项目加入 CNCF
Cedar Joins CNCF as a Sandbox Project
All About Cedar, an Open Source Solution for Fine-Tuning Kubernetes Authorization
背景
Kubernetes 的 RBAC 功能过于简单,仅支持“允许”,无法实现“拒绝”操作、条件判断或基于属性的访问控制。
Cedar 最初并非为 Kubernetes 开发,Cedar 的初衷是“真正解决亚马逊团队以及客户遇到的问题。这些问题包括:如何授权请求?如何确保授权过程快速、安全且高效?”
Cedar 是什么
Cedar 是一种用于在应用程序中编写和实施授权策略的语言。使用 Cedar,您可以编写策略来指定应用程序的细粒度权限。然后,您的应用程序通过调用 Cedar 的授权引擎来授权访问请求。由于 Cedar 策略与应用程序代码分离,因此可以独立地编写、更新、分析和审计它们。您可以使用 Cedar 的验证器来检查 Cedar 策略是否与定义应用程序授权模型的已声明模式保持一致。
Cedar 的特点
- 表达能力:支持常见的授权模型,包括基于角色的访问控制 (RBAC)、基于属性的访问控制 (ABAC) 和基于关系的访问控制 (ReBAC)。
- 性能:快速、可扩展的实时评估,延迟可控
- 可分析性:专为自动化推理而构建,支持策略优化和验证。
- 安全性:使用定理证明器(Lean)进行形式化验证,并对已验证的规范和 Rust 代码实现进行严格的差异测试。
Cedar 与 CNCF
Cedar 现已加入云原生计算基金会 (CNCF) 成为沙箱项目。CNCF 为处于早期阶段和正在开发的开源项目提供了一个中立的平台。Cedar 满足了云原生环境中对快速、安全且易于分析的授权策略语言的需求,它允许开发人员将访问控制逻辑与应用程序代码分离,并进行定义、外部化和管理。
AWS 从 Cedar 的架构设计之初就秉持着基金会管理的理念。加入 CNCF 满足了云原生领域的一项需求,它提供了一种中立的、由基金会支持的授权方式,是对现有 CNCF 项目的补充。基金会成员资格也为 Cedar 带来了更广泛的社区参与机会。
CNCF 还为 Cedar 提供了一个厂商中立的治理模型、更广泛的贡献者群体、增强的集成机会以及社区驱动的开发投入。
下一步是将 Cedar 从 CNCF 沙箱阶段升级到孵化阶段,最终毕业,这体现了 Cedar 已展现出的成熟度和生产就绪性。
2. KubeSphere 关于 Ingress NGINX 停止维护的说明
背景
Ingress NGINX 项目终止维护。这并不代表 Kubernetes Ingress API 被弃用。
- Ingress NGINX 是 Ingress Controller 的一种社区实现,由社区维护。
- 根据公告,该项目将从 2026 年 3 月起停止维护,不再提供补丁和版本更新。
- Kubernetes 官方的 Ingress API(networking.k8s.io/v1)仍然处于稳定状态,可以继续正常使用。
KubeSphere 的后续支持计划
1. 从 2026 年 3 月起,提供 Gateway API 支持
KubeSphere 将在 2026 年 3 月起提供:
- Gateway API 的可视化管理能力
- 一个可开箱即用的内置 Gateway API 实现
2. 默认替换 Ingress NGINX,选用社区活跃的替代方案
在 Ingress NGINX 停止维护后,KubeSphere 将:
- 选择一个社区活跃度高、维护稳定、具备长期支持能力的 Ingress Controller 作为默认方案
- 新版本与新集群将默认启用该替代实现
3. 过渡期间,您可以自由选择适合的方案
在新的默认方案正式发布前,为了不影响现有业务,您依然可以自由扩展自己的流量管理方式:
- 手动部署任意 Ingress Controller(https://kubernetes.io/docs/concepts/services-networking/ingress-controllers/)
- 手动部署任意 Gateway API 实现(https://gateway-api.sigs.k8s.io/implementations/)
- 继续通过 Web Terminal 或其他 CLI 工具进行管理
3. MinIO 处于维护模式
简介
MinIO 是一款高性能、与 S3 兼容的对象存储解决方案,采用 GNU AGPL v3.0 许可证发布。它专为速度和可扩展性而设计,以业界领先的性能为 AI/ML、分析和数据密集型工作负载提供支持。
- 兼容 S3 API –— 与现有 S3 工具无缝集成
- 专为人工智能和分析而打造 —— 针对大规模数据管道进行了优化
- 高性能 —— 是高要求存储工作负载的理想之选
处于维护模式
该项目目前正在维护中,不接受新的更改。
- 代码库目前处于仅维护状态。
- 不接受任何新功能、改进或拉取请求。
- 关键安全修复可能需要根据具体情况进行评估。
- 现有问题和拉取请求将不会得到积极审查。
- 社区支持将继续通过 Slack 以尽力而为的方式进行。
拓展阅读
MinIO is now "Maintenance Mode"
4. SUSE Rancher for AWS 隆重发布 —— Rancher 正式登陆 AWS Marketplace
SUSE Rancher for AWS 隆重发布 —— Rancher 正式登陆 AWS Marketplace
背景
SUSE Rancher for AWS 正式发布!用户可以直接在 AWS Marketplace(应用市场)订阅 Rancher,用来管理 EKS 容器集群,订阅方式更加灵活,部署效率更高。
这是 Rancher 首次以全托管式 SaaS 产品的形式出现在云厂商应用市场,目前仅在 AWS Marketplace 上提供。您只要登录 AWS 账户,在应用市场订阅 Rancher,导入集群,仅需几分钟时间就可以享受 Rancher 带来的全新容器管理体验。
SUSE Rancher for AWS 现提供 30 天免费试用。
SUSE Rancher for AWS 能为用户带来哪些价值?
全面提升 EKS 管理体验
SUSE Rancher for AWS 可以帮助用户将所有集群整合到一个全托管的智能控制平面中,大大降低管理难度。它为每个 Amazon EKS 集群提供了集中可视化、一致性治理、AI 辅助运维与集成可观测性等功能。
IT 团队可以在一个界面轻松管理所有 EKS 资源,包括管理用户权限、策略、应用和性能等。有了 Rancher,IT 团队就不需要四处拼接工具,这将大幅降低运维难度,减少系统安全风险。
此外,这个新平台还包含了简单易用的应用目录,用户即可一键部署 Helm Chart 应用。同时,它还支持用户添加自定义应用,便于开发人员一键安装。
实现一致的身份与访问控制
SUSE Rancher for AWS 支持 LDAP 和 Active Directory,你可以无缝集成现有身份提供商(IdP),直接在所有 Amazon EKS 集群中应用统一的身份验证与授权策略,不再需要管理单独的用户存储系统或访问控制模型,让团队获得一致且可预测的访问体验。
通过将 AWS IAM 角色映射到 Kubernetes 权限,并严格执行最小权限原则,SUSE Rancher for AWS 大幅简化多集群运维。
SUSE Rancher for AWS 可直接连接你的 EKS 环境,无需托管或维护任何基础设施。你可以立即导入现有集群,无需停机,并即时获得治理、可视化与成本优化能力。
随时在线的技术助理
SUSE Rancher 拥有 AI 助手功能,它改变了过去管理员需要在不同工具间切换、排查,阅读分散的日志与事件的历史。这就如同为管理员配备了一个 24 小时在线的技术助理,只需使用自然语言就可以完成大量重复性工作。
这个 AI 助手由 Amazon Q 与 Amazon Bedrock (AWS 的 AI/生成式 AI 服务)提供支持,它可以为团队提供升级、配置决策、YAML 校验与 GitOps 工作流中的指导建议。你可以用自然语言向集成的 AI 代理提问,它会给出清晰解释和推荐的下一步操作。所有操作均遵循严格的 SSO 与 RBAC 限制,确保每个用户只能访问被授权的内容。
为每个 EKS 集群提供统一可观测性
SUSE Rancher for AWS 内置了 SUSE Observability(可观测性平台),团队可以基于轻量的 eBPF 数据洞察整体 EKS 健康、性能和成本。
SUSE Observability 把指标、日志、事件与链路追踪全部汇集到一个视图中,为用户提供了超过 40 个开箱即用的仪表盘。此外,它还独有“时间回溯”差异比较功能,能让团队能跨任意时间点对比集群或工作负载状态(精确到毫秒),加速故障排查速度。
SUSE Observability 会突出显示闲置和低效的工作负载,并提供合理化建议。
5. vSphere Kubernetes Service (VKS) 现已成为 CNCF 认证的 Kubernetes AI 合规平台
Kubernetes Gets an AI Conformance Program — and VMware Is Already On Board
11 月的简报中简单介绍了 AI 合规平台,并且 GKE 已经获得认证,现在 VKS 也获得了认证。
6. Canonical 将 Kubernetes 长期支持期限延长至 15 年
Canonical Extends Kubernetes Long-Term Support to 15 Years
如题,而今年 2 月还是 12 年:Canonical 将 Kubernetes 发行版支持时间延长至十倍。
7. Docker 发布了强化容器镜像
Docker Sets Free the Hardened Container Images
DHI 简介
Docker 宣布旗下 Docker Hardened Images(DHI)现在成为开源项目,并向所有开发者免费开放使用,采用 Apache 2.0 许可证。该计划涵盖了 1000 多个安全强化的容器基础镜像,适合用于生产环境构建和部署。
DHI 镜像都是经过精简和安全强化的基础镜像,默认不以 root 运行、尽可能去除不必要组件、减少潜在攻击面,有助提升容器安全性。镜像支持 VEX 安全标准,可以更高效地管理漏洞可利用性信息。
Docker 企业扩展
Docker 的付费订阅服务主要面向企业用户。DHI Premium 是一项付费服务,并提供服务级别协议 (SLA),以确保及时完成 CVE 修复。镜像文件符合 FIPS 和 STIG 标准,可用于美国国防部项目。Docker 还将支持自定义工具、证书和运行时配置。
这项服务保证:
- 在七天内,根据服务级别协议 (SLA) 提供针对关键漏洞的 CVE 修复方案,并制定了当天修复的路线图。
- 支持 FIPS 和 STIG 标准的图像。
- 完全自定义,包括添加或更改运行时配置、工具、证书和镜像内容,同时保持信任和来源。
- 完整目录访问权限。
延长生命周期支持
扩展生命周期支持 (ELS) 是 DHI Enterprise 的一项付费附加功能,旨在为需要为生命周期结束的软件提供强化更新和合规性连续性的组织提供服务。如果某个软件包仅由项目维护者提供五年支持,但用户由于内部升级周期或其他原因需要其运行数年,Docker 将确保软件本身得到维护。
该服务提供:
- 在上游产品生命周期结束后,额外提供五年的安全保障。
- 持续进行 CVE 补丁、SBOM 更新和来源证明。
- 持续签署和审计合规框架。
拓展阅读
Let’s Make Hardened Images the Seatbelts of Software
💬 专题三 讨论与分享
1. 从 NetworkPolicy 到 ClusterNetworkPolicy
从 NetworkPolicy 到 ClusterNetworkPolicy
NetworkPolicy 作为 Kubernetes 早期的 API 看似美好,实际使用过程中就会发现它功能有限,不易扩展,不易理解且不易使用。因此 Kubernetes 成立了 Network Policy API Working Group 来制订下一代的 API 规范,而 ClusterNetworkPolicy 就是目前探讨出来的最新成果,未来可能会成为新的规范。
NetworkPolicy 的局限性
NetworkPolicy 是 Namespace 级资源,本质上是“应用视角”的策略。它通过 podSelector、namespaceSelector 来选中一批 Pod,然后对这些 Pod 的 Ingress、Egress 做限制。这带来了几个实际的问题:
1)缺少 Cluster 级别的控制
由于策略的作用域是 Namespace,集群管理员无法定义集群级别的默认网络策略,只能在每个 Namespace 里都创建相同的网络策略。这样一方面每次更新策略需要对所有 Namespace 下的资源进行更新,另一方面,很容易和开发者创建的网络策略产生冲突。管理员设置的策略,应用侧很容易就可以通过新的策略绕过去。
本质上在于 NetworkPolicy 这种应用视角的策略和管理员集群视角的策略存在冲突,当用户的安全模型并不是应用视角的时候 NetworkPolicy 就会变得难以应用。而集群管理员管控集群整体的安全策略是个现实中很常见的场景。
2)语义不清晰
NetworkPolicy 的语义有几个“坑”,新手和运维人员都容易踩:
-
隐式隔离。
一旦有任何 NetworkPolicy 选中了某个 Pod,那么“未被允许”的流量就会被默认拒绝。这种隐式的行为需要靠心算来推导,很难一眼看懂。 -
只有允许,没有显式拒绝。
标准 NetworkPolicy 只能写 allow 类型的规则,想要“拒绝某个来源”,通常要通过补充其他 allow 规则间接实现,或者依赖某些 CNI 厂商特有的扩展。 -
没有优先级。
多个 NetworkPolicy 选择同一批 Pod 时,规则是加法而不是覆盖关系。最终行为往往需要把所有策略合在一起看,排查问题时非常困难。
这些特点叠加在一起,就会导致 NetworkPolicy 理解起来困难,调试起来更困难。
ClusterNetworkPolicy 的解决方案
为了解决 NetworkPolicy 固有的问题,Network Policy API 工作组提出了一个新的 API —— ClusterNetworkPolicy (CNP),它的目标是在不破坏现有 NetworkPolicy 用法的前提下,给集群管理员提供一个更清晰、更强大的网络控制能力。
其最核心的思路是引入策略分层,在现有的 NetworkPolicy 之前和之后分别引入独立的策略层,将集群管理员的策略和应用的策略分开,提供了更丰富的视角和更灵活的使用。
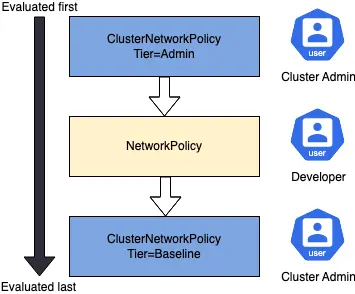
1)集群管理员视角
- tier: Admin 的策略用来定义绝对不能做的事情。
- tier: Baseline 的策略用来定义默认不建议做的事情,用户可以通过 NetworkPolicy 来放行。
2)明确的优先级
ClusterNetworkPolicy 中新增了 priority 字段,这样在同一个 Tier 中多个规则的范围出现重叠时,可以通过优先级清晰的界定哪个规则该生效,不会再出现 NetworkPolicy 里那种隐式覆盖,需要互相猜测的情况。
3)清晰的动作语义:Accept / Deny / Pass
和 NetworkPolicy 只有“允许”语义不同,ClusterNetworkPolicy 的每条规则都有一个显式的 action 字段,可以取值:
- Accept:允许这条规则选中的流量,并停止后续策略评估
- Deny:拒绝这条规则选中的流量,并停止后续策略评估
- Pass:在当前 tier 里跳过后续 ClusterNetworkPolicy,交给下一层继续评估
同时,文档中特别强调:
- ClusterNetworkPolicy 不再有 NetworkPolicy 那种“隐式隔离”的效果
- 所有行为都来自你写的规则本身,读策略时看到什么就是什么
2. VMware Cloud Foundation Automation – 使用和部署虚拟机和 Kubernetes 集群
VMware Cloud Foundation Automation – Consume and Deploy Virtual Machines and Kubernetes Clusters
这篇博文将深入探讨在配置使用 K8S 风格 API 的租户组织时,两项默认开启且开箱即用的基础架构服务:虚拟机服务 (Virtual Machine Service) 与 vSphere Kubernetes 服务 (vSphere Kubernetes Service)。
Kubernetes 的声明式 API 模型已经彻底改变了企业构建和运维现代应用程序的方式。但近年来,同样的 Kubernetes 模型已经从容器化工作负载扩展到了基础设施本身。
最初,Kubernetes 仅支持使用 kubectl apply 来管理 Pod 和 Deployment,如今已发展成为利用 Kubernetes API 来配置和管理虚拟机、K8S 集群、网络、存储、负载均衡器,甚至数据库 。Kubernetes 不再仅仅是“云原生应用的平台”,它正逐步成为应用和基础设施的通用控制平台 。
Virtual Machine Service
VMware Cloud Foundation 9.0 中的虚拟机 (VM) 服务提供了一个统一的 Kubernetes 原生接口,用于直接通过命名空间(Namespaces)对虚拟机进行置备和管理。通过将虚拟机规格(VM classes)、镜像、存储策略和网络配置公开为声明式的 Kubernetes 资源,VM 服务使平台和应用团队能够使用熟悉的 Kubernetes 工具来消费基于 vSphere 的计算资源。该服务通过强制执行 VCF Automation 在组织、区域和项目层级定义的策略,确保了一致的治理和生命周期管理,同时在底层充分利用了 vSphere 成熟的虚拟化能力。
vSphere Kubernetes Service
VMware Cloud Foundation 9.0 中的 vSphere Kubernetes 服务 (VKS) 提供了一个完全集成、与上游兼容的 Kubernetes 控制平面,该控制平面原生运行于 vSphere 之上。通过 VKS,组织可以将 Kubernetes 集群创建并运行为“一等”云资源,并由底层 VCF 平台强制执行一致的网络、存储、身份验证和安全策略。该服务提供了跨集群的生命周期自动化、一致性校验和治理能力,使团队能够利用标准 Kubernetes API 可靠地部署应用,同时继承 VMware Cloud Foundation 内置的企业级韧性、可扩展性和基础架构自动化能力。
3. 专家分享管理 Kubernetes 的五大深刻教训
背景
Kubernetes 改变了现代组织部署和运营可扩展基础设施的方式。过去十多年,自动化云原生编排的热潮让 Kubernetes 几乎普及开来。但实际上,多数团队在 Kubernetes 之路上很快就面对运营复杂性、配置难题和高昂维护成本,这些问题鲜少被厂商提及。
五大深刻教训
1. 运营负担让团队措手不及
Kubernetes 社区知道创建集群很简单,尤其使用 AKS、EKS、GKE 这类托管服务时。但实际生产环境要管理的隐藏附加组件非常多:DNS 控制器、网络、存储、监控、日志、密钥、安全等。支持内部用户(开发、运维、数据科学团队)也带来巨大负担。
内部 Slack 频道经常被请求淹没,推动了平台工程和开发者自助服务的兴起,减少运营压力。但后台必须有人搭建好这些能力,让开发者轻松部署应用。每层抽象都会影响支持和排查。隐藏复杂度越多,开发者越难独立解决问题。成功团队在易用性和透明度间找到平衡。
2. 安全隐患隐藏角落,威胁集群安全
托管平台和云厂商承诺快速创建集群,确实快且简单,但这些集群往往不适合生产使用。它们缺少加固的安全措施、合理的资源请求和限制、关键集成及监控。
生产就绪意味着在部署业务应用前,规划服务器访问、RBAC、网络策略、附加组件、CI/CD 集成和灾难恢复。安全、生产级 Kubernetes 环境需要细致配置和资源规范。这些细节保护系统和客户数据安全。
-
默认设置风险
默认配置几乎从不安全。你需要考虑给谁什么样的集群权限。要设置 RBAC 权限、角色和集群角色。虽然规格看似简单,但集群对象多且命名复杂,理解它们是安全的前提。注意:Kubernetes 本身没有内置身份和访问管理(IAM),必须谨慎管理访问权限和端点暴露。
复杂性常导致内置集群角色权限过大,用户权限超标。云厂商正在通过集成 IAM 和 RBAC 工具(如 AWS IRSA)简化权限管理。
-
网络策略与命名空间隔离
命名空间提供逻辑隔离,但默认无网络隔离。真正隔离需定义网络策略并使用兼容 CNI,需规划、测试和持续调优。
-
容器及镜像安全
尽管软件供应链问题频发,许多组织仍未扫描容器镜像。直接从公共镜像仓库拉取方便,但存在风险。镜像通常由多层镜像构成,可能含漏洞。
务必扫描、验证并追踪镜像来源,了解镜像构建和维护者。建立漏洞缓解计划。有些厂商提供订阅式安全补丁镜像,减轻团队在 CVE 和漏洞管理上的负担。
3. 扩展挑战阻碍增长和敏捷
Kubernetes 擅长扩展,无需手动配置服务器或管理峰值连接,自动完成复杂任务。
起步很简单:部署 Cluster Autoscaler 和 Horizontal Pod Autoscaler(HPA),启动即可。但这背后隐藏两大问题:失控成本和性能不稳定。
-
节点扩展成本
节点自动扩展必不可少,但若无限制会带来巨额费用。务必设置上限,避免云账单暴涨和节点过大过贵。缺乏实例族指导时,工具如 Karpenter 可能选用昂贵大节点,团队往往只关注高可用,忽视成本。
-
Pod 扩展指标
HPA 部署简单,选指标难。基于 CPU 和内存的通用指标虽易用,但大多数应用不会真正受限于此。有效扩展需用自定义指标,如请求数或队列长度,虽复杂,但更准确反映负载,避免过度扩展和浪费,确保性能稳定。
4. 人才获取:技能缺口与高成本
管理 Kubernetes 的核心教训是:人才是最关键资源。Kubernetes 作为复杂基础设施,广泛应用时间较短,且技术深度大,导致:
- 人才稀缺:真正有生产环境深度经验的技术人员少。
- 成本高昂:经验丰富人才薪资高,预算压力大。
了解懂 Kubernetes 和能大规模运营 Kubernetes 是两回事。个人机或业余项目的 Kubernetes 跟生产环境需求差距大。真实经验包括升级管理、稳定性保障、成本控制和复杂集成。
5. 技术债务积累快于团队消化
迁移到云和 Kubernetes 不用升级物理服务器或操作系统,但引入了新的技术债,主要体现在:
-
持续升级,必须不断管理更新,保持安全稳定:
- Kubernetes 核心:虽然版本发布频率降至每年三次,但保持主组件最新(N+1)是必须。大版本升级可能带来破坏性变更,如从 Ingress 迁移到 Gateway API。
- 关键附加组件:CoreDNS、CNI 等基础组件独立发布,需持续监控更新和兼容性。
这需要大量时间做调研、测试和部署。忙于支持和排错时,升级常被拖延,技术债堆积,直到某个 CVE 迫使一次性跨多版本大升级,风险极高。
-
工具生态变迁:
Kubernetes 生态不断发展,新模式让旧工具过时或被弃用。依赖五年前的工具可能用上低效甚至不受支持的组件。忽视新项目和标准,有落后风险。
关键功能最佳实践在变,如:
- 从 Git 中加密 Secrets(如用 SOPS)转向使用 External Secrets Operator 从 Vault 拉取。
- 从传统 Ingress 资源迁移到更强大的 Gateway API。
- 不跟踪 CNCF 新项目和工具评估,可能被废弃工具锁住,失去安全补丁,迫发紧急迁移。安全可靠需持续关注生态。
额外经验
不是所有工作负载都适合 Kubernetes
团队常在未评估业务需求前就用 Kubernetes。但有些工作负载用简单托管或独立 VM 效果更好。没必要因为流行就在 Kubernetes 上运行个人博客、简单数据管道或一次性批处理。
从业务需求出发,在能解决实际问题时用 Kubernetes。避免“全网服务网格”或“默认 Kubernetes”陷阱。关注结果、简洁和效率。
策略执行
Kubernetes 的声明式 API 使得通过结构化策略强制安全和最佳实践成为可能。
常用开源策略引擎包括:
- Open Policy Agent (OPA)(通过 Gatekeeper):通用策略引擎,使用强大 Rego 语言。
- Kyverno:Kubernetes 原生,直接用 YAML 写策略,无需新语言。
- Polaris:专注审计与自动执行安全、效率、可靠性最佳实践。
关键是从一开始就启用策略引擎。先创建裸集群再加策略,会突然阻止不安全部署,导致开发者抵触。
4. Ingress-nginx 退役:cert-manager 现状支持及未来展望
Ingress-nginx 退役:cert-manager 现状支持及未来展望
背景
自从宣布 ingress-nginx 和 InGate 将于 2026 年 3 月退役以来,关于从 Ingress 迁移到 Gateway API 的问题越来越多。由于两者设计差异,cert-manager 目前无法提供同样的 TLS 自助服务体验。
Ingress 是单一资源,而 Gateway API 将资源拆分为集群运营方管理的 Gateway 资源和团队管理的 HTTPRoute 资源,证书配置则放在集群运营方管理的 Gateway 上。
缺失的关键是 Gateway API 的实验性资源 XListenerSet,目标是恢复共享 Gateway 上的按团队 TLS 配置。cert-manager 计划在 1.20 版本(预计 2026 年 2 月 10 日)加入对 XListenerSet 的实验性支持,1 月份会有 alpha 版本发布。
多租户 Ingress 迁移难点
大多数 Ingress 用户采用多租户方式运行 Ingress 控制器,包括 ingress-nginx 和 InGate。所谓多租户 Ingress 控制器指的是:
- 每个集群只有一个由平台团队管理的共享控制器或代理。
- 各团队管理自己的 Ingress 和 TLS 注解。
- cert-manager 自动按主机名签发证书。
而 Gateway API 中,TLS 配置迁移到了 Gateway 资源:开发者可以创建 HTTPRoute,但无法安全修改平台团队拥有的共享 Gateway。因此失去了 TLS 自助能力,每次 TLS 变更都需要提交工单,如下图所示:
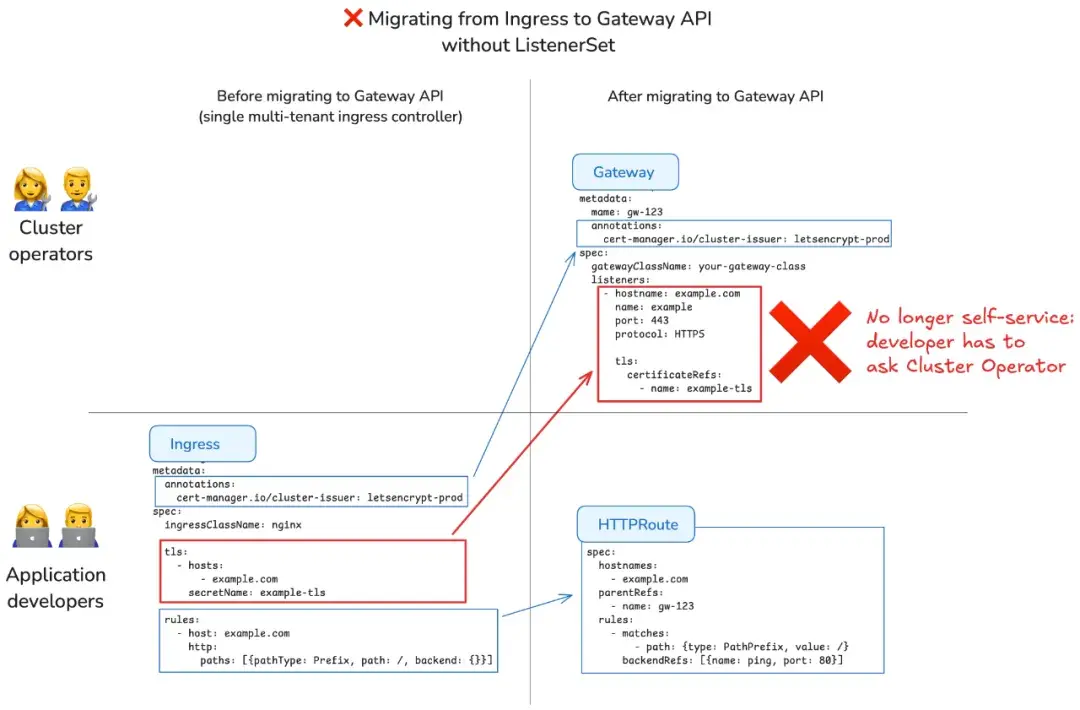
- 以前 Ingress,应用开发者自行配置 TLS。
- 现在 Gateway,应用开发者需请求集群运营方配置 Gateway 上的 TLS。
这意味着自助体验相较现有 Ingress 工作流有所下降。虽然这看似降低开发效率,但 Gateway API 的设计初衷是解决 Ingress API 中的安全隐患:不同团队可能会通过创建相同主机名但不同 TLS 配置的 Ingress,恶意或无意劫持其他团队流量。大型集群中多个团队的冲突 Ingress 对象常造成流量截取。将 TLS 配置集中在 Gateway 层,则强化了安全边界,代价是简单多租户场景下自助服务受限。
为什么 cert-manager 目前无法独立解决
cert-manager 当前对 Gateway API 的支持仅能管理 Gateway 资源上的 TLS 配置:cert-manager 监听 Gateway 资源中带有 cert-manager.io/issuer 或 cert-manager.io/cluster-issuer 注解、包含 HTTPS 监听器且 tls.certificateRefs 已设置的对象,自动创建对应的 Certificate 和 Secret。
注意 cert-manager 不关注 HTTPRoute 上的主机名,因为这些主机名主要供 Gateway API 控制器识别对应 Gateway 的监听器,不用于 TLS。
该模式仅在以下情况适用:
- 每个团队拥有独立 Gateway(增加成本与基础设施复杂度),或
- Gateway 被实现为“轻量”逻辑对象。
但对常见的“一个共享 Gateway + 多团队”模式不适用。当前没有安全且简便的方式允许多个团队在共享 Gateway 上自主管理 TLS,除非使用风险较大的通配符证书或危险的 RBAC 配置。
ListenerSet:缺失的关键组件
根据 GEP-1713,Gateway API 计划引入 ListenerSet 资源(目前是实验性的 XListenerSet),主要用于解决由自动化工具(例如 Knative)管理大量监听器的 Gateway 资源问题。
我们认为 ListenerSet 也能解决多租户共享 Gateway 上的 TLS 自助配置问题,同时保持基础设施运营方对 Gateway 资源的控制权。
通过 ListenerSet,能够实现:
- 平台团队拥有唯一共享 Gateway 及其基础设施。
- 各应用团队在 ListenerSet 对象中创建自己的监听器及 TLS 配置。
Gateway API 控制器通过 RBAC 和命名空间隔离,确保团队只能管理自己的监听器,避免配置冲突:
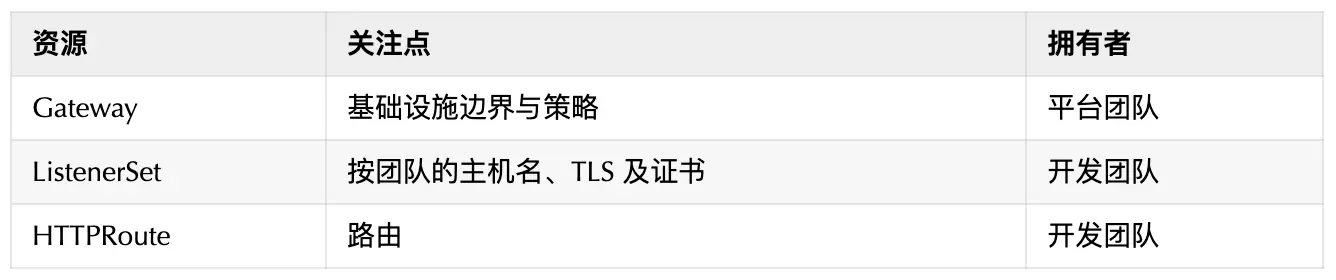
对 Ingress 用户来说,ListenerSet + HTTPRoute 是最接近原生 Gateway API 的 Ingress 体验,如下图所示:
- 过去 Ingress,应用开发者可自行配置 TLS。
- 现在 Gateway + ListenerSet,应用开发者依然能保持自助配置 TLS,无需每次都找集群运营方。
cert-manager 路线图:2026 年 2 月支持 XListenerSet
cert-manager 1.20 将支持对 XListenerSet 资源的 cert-manager.io/issuer 和 cert-manager.io/cluster-issuer 注解,作为实验性功能(需开启特性开关)。XListenerSet 的注解优先于 Gateway 注解,后者作为默认。
- 2026 年 1 月:发布支持 XListenerSet 的 alpha 版本,欢迎测试反馈。
- 2026 年 2 月 10 日:cert-manager 1.20 正式发布,包含实验性 XListenerSet 支持。
随着 Gateway API 将 ListenerSet 资源升级为稳定版,cert-manager 将添加对稳定版本的支持,并提供从 XListenerSet 到 ListenerSet 的迁移方案。
5. Nelm 与 Helm 4 的比较:现有差异与未来规划
Helm 与 Nelm
Helm 是一个用于管理 Chart 的工具。Chart 是预配置的 Kubernetes 资源包。
Nelm 是 Helm 4 的替代方案。它是一个 Kubernetes 部署工具,用于管理 Helm Chart 并将其部署到 Kubernetes。它也是 werf 的部署引擎。Nelm 不仅具备 Helm 的所有功能,而且功能更强大,甚至还在此基础上进行了诸多改进。
Nelm 与 Helm 4 的主要差异
1. CRD 部署
Helm 建议将 CRD 放在 chart 的 crds 目录,但该目录内资源只在首次安装时部署,无法更新,且 helm upgrade 会忽略它。有些用户将 CRD 放在 templates 目录以当作普通资源部署,但这样难以维护部署顺序,且 CRD 文件大,可能超出 Secret 大小限制。有些开源 chart 甚至单独用子 chart 来部署 CRD。
Nelm 只需将 CRD 放入 crds 目录,Nelm 提供完整的部署机制,CRD 会在每次升级时更新和部署。
2. 部署顺序定义
Helm 通常用 hooks 定义部署顺序,适合简单的 Job 在 rollout 前后运行。但如果 Job 依赖 Deployment,或需要在发布中途运行,Helm 没有标准解决方案。
Nelm 在每次发布前构建操作图,定义资源的部署顺序。并提供 werf.io/deploy-dependency 注释,设置操作间的依赖关系,确定顺序。
3. 资源生命周期
Helm 通过 helm.sh/resource-policy: keep 防止资源删除,helm.sh/hook-delete-policy 控制 hook 删除时机。但如果需要在发布中间部署不可变 Job,或部署后清理资源,或跨多个发布管理同一资源,Helm 很难满足。
Nelm 新增了一套资源生命周期管理注释:
- werf.io/delete-policy
- werf.io/ownership
- werf.io/deploy-on
这些注释能模拟 Helm hook 的行为,无需正式声明 hook。
4. 高级资源跟踪
Helm 3 支持简单的资源就绪等待。Helm 4 用 kstatus 改进了准确度,但无根本改变。
Nelm 具有自己的高级资源跟踪系统,相比 Helm 4:
- 检测资源就绪更准确
- 不仅跟踪就绪,还能判断资源是否存在,检测探针失败等错误
- 支持热门自定义资源的就绪规则
- 对其他自定义资源用启发式方法判断就绪,误判少
- 部署时在终端实时显示状态、错误、日志和事件
5. 加密 values.yaml 及其他文件
Helm 本身不支持 chart 内的加密文件,这由 helm-secrets 插件提供。
Nelm 原生支持加密 values 文件和 chart secrets 目录内的任意文件。操作更简单。
6. 发布计划
Nelm 内置类似 helm diff 的功能。nelm release plan install 命令精确显示下一次发布将对集群资源做的变更。
Nelm 缺少的功能
- 不支持 Helm 3 CLI 插件。它们依赖 Helm CLI 命令结构、选项和日志渲染,兼容性差。我们计划在 Nelm 内置实现最受欢迎的插件功能,如 helm diff 和 helm secrets。
- 不支持 post-renderers。计划推出 Go 模板替代方案,并内置资源 patch 功能,无需外部插件。详见 issues #54 和 #115。
- 目前无法与 Argo CD 和 Flux 结合,后续通过 Nelm operator 实现,相关 CR 会通过 Argo CD、Flux 或其它 GitOps 工具部署。
- Helmfile 和 Helmwave 不兼容 Nelm,计划实现 Nelmfile,方便 CLI 原生支持。Helmwave 项目考虑切换到 Nelm。
6. 开源:展望 2025 年的四大趋势
Open Source: Inside 2025’s 4 Biggest Trends
1)开源人工智能蓬勃发展
虽然大部分资金都流向了专有模型,但开源人工智能数据集、编排框架、评估工具和防护措施堆栈都取得了增长。
尽管开源人工智能的定义仍存在争议,而且极少有人工智能项目能够完全符合开源促进会(OSI)人工智能定义的严格要求,但人工智能仍然是建立在开源软件基础之上的。关于开放权重、数据和训练代码的争论还将继续,但即使是最专有的大型语言模型(LLM) 也离不开开源程序。
在目前这个阶段,最重要的似乎是模型上下文协议(MCP)。这是一个开放标准和开源实现,用于将代理统一连接到工具、文件、数据库和其他系统。MCP 越来越多地成为许多代理和 IDE 助手的“底层架构”,并且有许多开源的 MCP 服务器和工具包 ,允许任何兼容的代理框架插入到相同的工具中。
MCP 并不是唯一一款正在加速发展的智能体 AI 中间件:
今年 6 月,谷歌将其 Agent2Agent 协议(该协议规范了智能体之间的通信方式)捐赠给了 Linux 基金会。微软 Agent Framework (一个用于构建、部署和管理多智能体、支持 MCP 的应用程序的开源 SDK 和运行时)也越来越受欢迎。
2)关于“开放”许可与“源代码可用”许可的争论仍在继续
Linux 基金会 8 月份发布的一份报告显示,在过去 25 年里,风险投资支持的商业开源公司表现优于类似的闭源供应商。
哈佛商学院 2024 年的一项研究表明,96%的商业程序都依赖于开源软件,而开源代码的总价值高达 8.8 万亿美元。但这仍然无法阻止一些公司将开源软件开发模式与商业模式混淆。
在 2025 年,我们看到更多公司从开源转向伪开源。例如,ScyllaDB 团队在 2024 年 12 月宣布,它将转向单一的“ScyllaDB Enterprise” 版本,并采用源代码公开许可。在库层面,已经出现了一些备受瞩目的例子,一些以前较为宽松的项目悄悄地转向了源代码可用、商业用途付费的条款,例如 Fluent Assertions .NET 测试库在今年 1 月从 Apache-2.0 转向了专有源代码可用许可证,并按开发者收费。
3)开源项目资金匮乏
尽管我们都依赖开源软件,但太多项目仍然资金不足。另一些项目,例如 .NET 6,仍然很受欢迎,但它们的维护者已经停止了支持。
早在 2021 年,安全公司 Tidelift (该公司也为开源项目维护者提供资金支持)就发现,46%的开源项目维护者根本没有任何报酬。更糟糕的是,即使是那些获得报酬的维护者,也只有区区 26% 的人年收入超过 1000 美元。
情况并没有好转,实际上反而更糟了。Tidelift 最新发布的报告显示,2024 年,60% 的开源软件维护者都是无偿工作的。
正如 10 个开源基金会在 9 月份发表的一封公开信中所指出的那样,“这些(开源)系统大多运行在一个极其脆弱的前提下:它们的维护、运营和资金来源往往依赖于善意,而不是将责任与使用情况挂钩的机制。” “少数组织承担了大部分基础设施成本,而绝大多数大型用户(包括创造需求和获取经济价值的商业实体)在消费这些服务的同时,却没有为这些服务的可持续性做出贡献。”
拓展阅读:FFmpeg to Google: Fund Us or Stop Sending Bugs
4)开源供应链比以往任何时候都更加脆弱
2024 年,xz 数据压缩库代码被蓄意植入恶意软件,险些在红帽公司的社区版 Linux 发行版 Fedora 中植入后门。如果成功,它最终可能会出现在红帽企业版 Linux(RHEL)及其衍生发行版中。
2025 年的几项影响巨大的活动都以破坏开源软件包生态系统为中心,尤其是 npm。
每年我都会提醒大家,必须更加重视安全问题。最近,随着开源供应链违规事件日益增多,我一直在强调,必须确保供应链中的代码既安全,又是由值得信赖的人编写的。
展望未来,我只能再次发出这些警告。过去几年我们已经遭遇了严重的安全漏洞。你肯定还记得:Solarwinds、JetBrains TeamCity 和 Apache Log4j 的事件应该很快就会浮现在你的脑海中。尽管这些事件已经够糟糕了,但如果我们不更加重视开源供应链的安全,更严重的安全灾难还在后头。
7. 升级到 etcd v3.6 时如何避免出现僵尸集群成员
Avoiding Zombie Cluster Members When Upgrading to etcd v3.6
背景
最近,etcd 社区解决了一个用户从 v3.5 升级到 v3.6 时可能出现的问题。该漏洞会导致集群报告“僵尸成员”,这些成员是之前已从数据库集群中移除的 etcd 节点,它们会重新出现并加入数据库共识。在这些僵尸成员被移除之前,etcd 集群将无法正常运行。
在 etcd v3.5 及更早版本中,即使 v3store 也存在,v2store 仍然是成员数据的唯一来源。作为 v2store 弃用计划的一部分,在 v3.6 版本中,v3store 成为集群成员数据的唯一来源。我们通过一份错误报告发现,在某些较旧的集群中,v2store 和 v3store 的数据可能不一致。这种不一致表现为升级后,一些旧的、已被移除的“僵尸”集群成员会重新出现在集群中。
修复与升级路径
- 请将集群版本升级到 v3.5.26 或更高版本。
- 更新后请等待并确认所有成员身体状况良好。
- 升级到 v3.6。
📄 专题四 报告查看与分析
💁♀️ 专题五 产品/方案介绍
1. Agent Sandbox:管理隔离的、有状态的、单例工作负载
Agent Sandbox 深度解析:预热池让安全容器冷启动快如闪电
简介
agent-sandbox 能够轻松管理隔离的、有状态的、单例工作负载,非常适合 AI 代理运行时等用例。
本项目隶属于 SIG Apps ,旨在为 Kubernetes 开发 Sandbox 自定义资源定义 (CRD) 和控制器。目标是提供一个声明式、标准化的 API,用于管理需要长时间运行、有状态、单例容器且具有稳定身份的工作负载,类似于基于 Kubernetes 原语构建的轻量级单容器虚拟机体验。
核心特性
- Kubernetes 原生 Sandbox CRD 和控制器
用于管理沙箱化工作负载的原生 Kubernetes 抽象 - 高可扩展性
支持数千个并发沙箱,同时实现亚秒级延迟 - 开发者友好的 SDK
轻松集成到代理框架和工具中
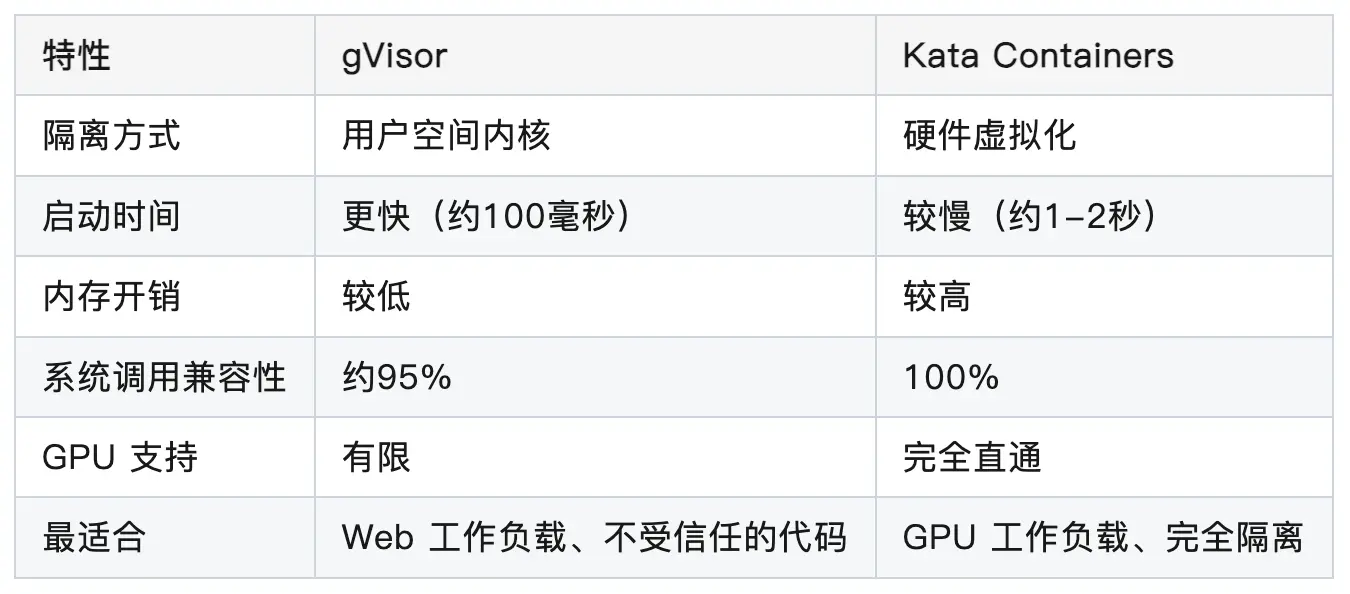
运行时集成:gVisor 和 Kata Containers
gVisor 是一个应用程序内核,在容器应用程序和宿主机内核之间提供额外的隔离层。 它拦截应用程序的系统调用并在用户空间中实现。
Kata Containers 提供轻量级虚拟机,行为像容器但提供虚拟机的安全隔离。 每个容器在自己的轻量级虚拟机中运行,具有专用内核。
2. Coroot:基于 eBPF 技术的新一代开源可观测性平台
简介
Coroot 不仅仅是一个展示图表的工具,其核心目标是解决“数据多但线索少”的问题。
特点
零仪器可观测性
- eBPF 会自动收集指标、日志、跟踪和配置文件。
- Coroot 为您提供覆盖系统 100% 的服务地图,没有任何盲区。
- 预定义的检查无需任何配置即可审核每个应用程序。
应用程序健康状况摘要
- 即使管理数百个服务,也能轻松了解其状态。
- 无需手动检查每个日志,即可深入了解应用程序日志。
- 服务级别目标 (SLO) 跟踪。
使用分布式追踪来探索任何异常请求
- 只需单击一下即可调查任何异常情况。
- 使用 OpenTelemetry 的厂商中立方案。
- 您是否无法对旧版服务或第三方服务进行检测?Coroot 基于 eBPF 的检测方案无需任何代码更改即可捕获请求。
只需快速浏览一下日志,即可获取关键信息。
- 日志模式:开箱即用的事件聚类。
- 日志与追踪结果的无缝关联。
- 基于 ClickHouse 的闪电般快速搜索。
一键创建任何应用程序的配置文件
- 分析 CPU 或内存使用率的任何意外飙升,精确到代码行。
- 不要妄下结论,要确切了解资源都花在了哪里。
- 通过将异常情况与系统基线行为进行比较,可以轻松调查任何异常情况。
内置专业知识
- Coroot 可以自动识别超过 80% 的问题。
- 如果某个应用未能达到其服务级别目标 (SLO),Coroot 将发送一条包含所有相关检查结果的警报。
- 您可以轻松地针对特定应用或整个项目调整任何检查。
部署跟踪
- Coroot 会发现并监控 Kubernetes 集群中的每个应用程序部署。
- 无需与您的 CI/CD 管道集成。
- 每次发布都会自动与前一个版本进行比较,因此您绝不会错过任何细微的性能下降。
- 借助集成的成本监控功能,开发人员可以跟踪每次更改对其云账单的影响。
成本监控
- 深入了解您的云成本,细化到具体应用程序层面。
- 无需访问您的云帐户或任何其他配置。
- 支持 AWS、GCP、Azure。
3. KubeVirtBMC:为 KubeVirt 虚拟机提供带外管理服务的项目
简介
KubeVirtBMC 以传统方式(即 IPMI 和 Redfish)为 Kubernetes 上的虚拟机提供带外管理功能。这允许用户对虚拟机进行开机/关机/重启以及设置启动设备等操作。它最初是为 Tinkerbell / Seeder 等工具配置 KubeVirt 虚拟机而设计的,但只要您的配置工具与 IPMI/Redfish 兼容,您就可以使用 KubeVirtBMC 来管理 Kubernetes 集群上的虚拟机。
主要功能
- 提供传统的 IPMI 和 Redfish 接口。
- 支持对 KubeVirt 虚拟机执行电源控制和启动设备设置。
- 为 KubeVirt 虚拟机提供精选的 BMC 功能,并确保在集群内部的网络可访问性。
🤔 专题六 有意思的事与 Meme
1. 协助将 Ingress NGINX 迁移到 HAProxy Kubernetes Ingress Controller
Migration assistance from Ingress NGINX to HAProxy Kubernetes Ingress Controller
此工具包用于将已停用的 Ingress NGINX 的配置和注解转换为 HAProxy Kubernetes Ingress Controller。
拓展阅读
Ingress NGINX Retirement: We Built an Open Source Migration Tool
2. SSO 耻辱墙
简介
一份将单点登录视为锦上添花的功能,而不是核心安全要求的供应商名单。
背景
单点登录 (SSO) 是一种将您的网站(或其他产品)的身份验证外包给第三方身份提供商(例如 Google、Okta、Entra ID (Azure AD)、PingFederate 等)的机制。
在此背景下,SSO 指的是 SaaS 或类似供应商允许企业客户通过客户自己的身份提供商管理用户帐户,而无需依赖供应商提供带有审计日志的强身份验证,并且能够集中创建和删除该客户使用的所有软件中所有用户的用户帐户。
对于拥有众多员工的组织而言,这项功能至关重要,它能帮助 IT 和安全团队有效管理跨数十甚至数百家供应商的用户帐户,而其中许多供应商并不支持 TOTP 双因素身份验证或 U2F 等功能。此外,如果员工离职,IT 团队可以立即禁用其对所有应用程序的访问权限,而无需登录 100 个不同的用户管理门户。
SSO 通常仅作为“企业版”定价的一部分提供,而这种定价要么假定用户数量庞大(达到最低席位要求),要么强制与其他“企业版”功能捆绑在一起,而这些功能对使用该软件的公司可能毫无价值。
许多供应商对 SSO 的访问权限收取基本产品价格的 2 倍、3 倍或 4 倍费用,这降低了用户使用 SSO 的积极性,并助长了不良的安全做法。
🎤 具体见原文,数据还是挺参差的。
3. Kubernetes 知识小测验
Kubernetes general knowledge, part 1
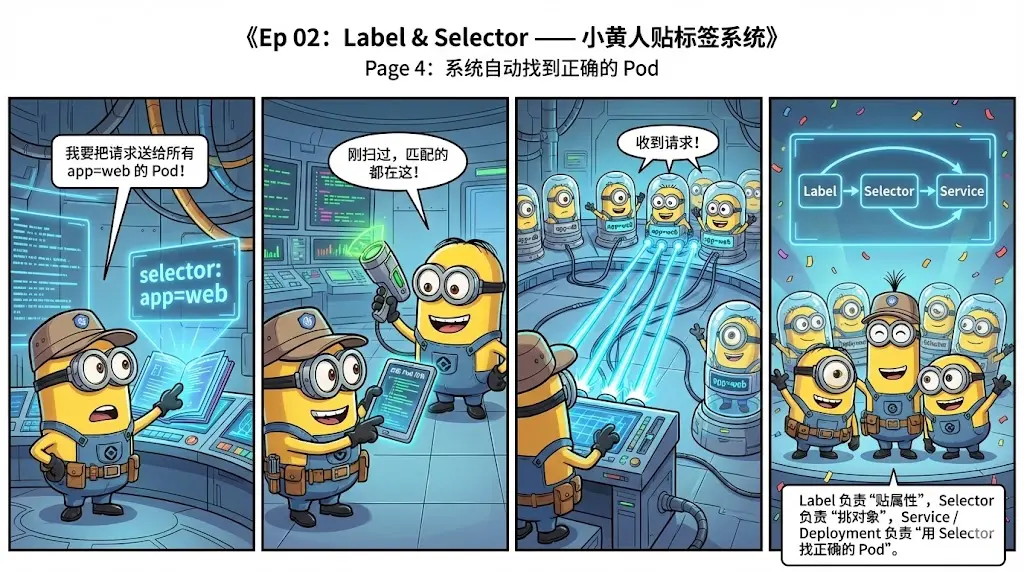
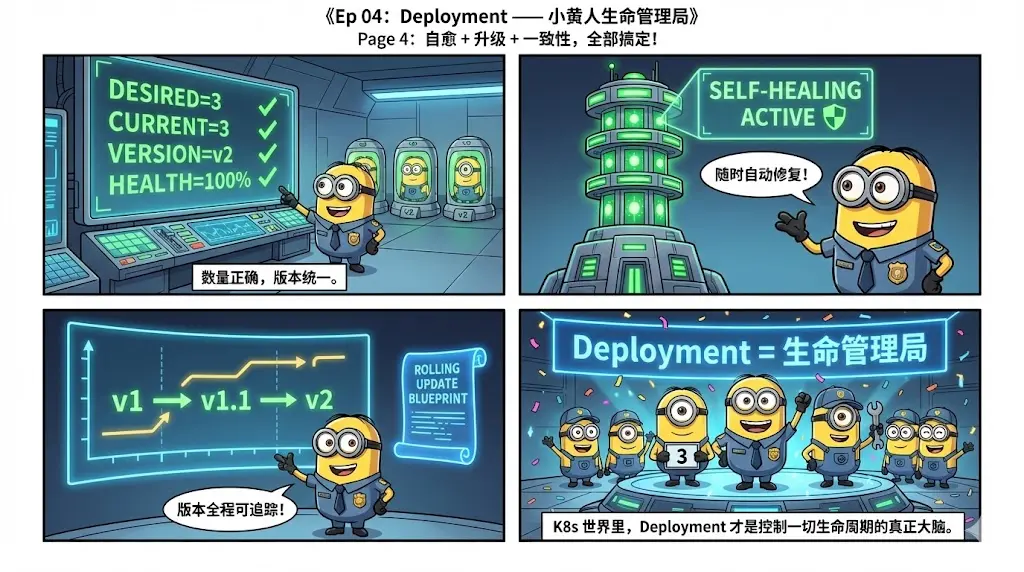
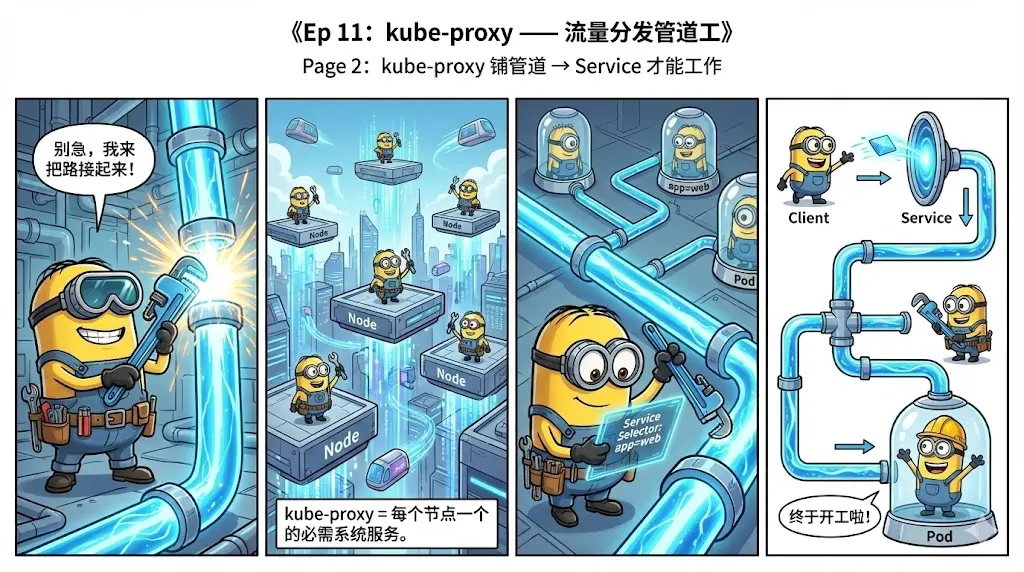
4. 《Kubernetes 小黄人工程师》用漫画讲 Kubernetes
从 Pod / Deployment 等核心对象, 到多租户、网络、存储、调度、GitOps、AI 自治等进阶主题,每集都是一段云原生小黄人的成长故事。
蛮有意思,生动形象。




















5. K8sQuest:一款学习 Kubernetes 的 CLI 工具
I made a CLI game to learn Kubernetes by breaking stuff (50 levels, runs locally on kind)