🆕 专题一 产品新功能/新版本
1. Kubernetes 1.36 ハル (Haru) 发布
拓展阅读:
New Features We Find Exciting in the Kubernetes 1.36 Release
Kubernetes 1.36: Deep dive into new alpha features
Kubernetes 1.36: What Actually Changed for Enterprise Platforms
发布主题与徽标

我们以 Kubernetes v1.36 开启 2026 年。 这个版本到来之时,季节更迭,山间光影流转。 ハル(Haru)在日语中富含多重意象; 其中我们最贴近的含义包括:春(spring)、晴れ(hare,晴空)和遥か(haruka,遥远)。 一个季节、一片天空和一条地平线。你将在接下来的内容中看到这三者。
该版本徽标由 avocadoneko / Natsuho Ide 创作, 灵感来自葛饰北斋的 《富嶽岳三十六景》 (富三十六景,Fugaku Sanjūrokkei)。 这一系列也诞生了了神奈川冲浪里这样的传世杰作。 我们的 v1.36 徽标重新诠释了这个系列中最著名的作品之一: 《凯风快晴》 (凱風快晴,Gaifū Kaisei),又名赤富士(Aka Fuji): 夏日黎明中被照亮成红色、经历漫长融雪后已不覆雪的山。 三十六景与 v1.36 相映成趣,也提醒我们即便是北斋也没有止步于此。1 Kubernetes 舵轮守望着这一幕,与山一同融入天空。
富士山脚下坐着 Stella(左)和 Nacho(右), 两只猫的项圈上带有 Kubernetes 舵轮, 象征着狛犬的角色: 守护日本神社的一对狮犬守护像。 它们成对出现,因为没有什么是独自守护的。 Stella 和 Nacho 代表着远比这两对爪子庞大得多的群体: SIG 和工作组、维护者和评审者、文档、博客与翻译背后的人们、发布团队、 迈出第一步的首次贡献者,以及年复一年回归的长期贡献者。 一如既往,Kubernetes v1.36 由众多双手托举。
徽标中横跨赤富士的书法是“晴れに翔け”(hare ni kake), 意为“翱翔于晴空”。 这是一个对句的前半句,完整对句太长,无法完全放在山上:
晴れに翔け、未来よ明け
hare ni kake, asu yo ake
“翱翔于晴空;迎向明日朝阳。”
稳定(GA)阶段
细粒度 API 鉴权
Kubernetes v1.36: Fine-Grained Kubelet API Authorization Graduates to GA
KubeletFineGrainedAuthz 功能在 Kubernetes v1.32 中作为可选的测试版功能被引入,随后在 v1.33 中升级为默认启用的功能。现在,该功能已经正式发布,且其开关始终处于启用状态。该功能能够更精确地实现基于最小权限原则的访问控制,从而取代了在常规监控和可观测性场景中必须授予过于宽泛的 nodes/proxy 权限的做法。
在该功能推出之前, kubelet 授权机制采用的是粗粒度的处理方式。当 Webhook 授权功能被启用后,几乎所有的 kubelet API 路径都被映射到了同一个 nodes/proxy 子资源上。这意味着,任何需要从 kubelet 中读取指标或健康状态的操作,都需要 nodes/proxy 权限。而这种权限,也意味着用户可以在该节点上运行的任何容器中执行任意命令。将 nodes/proxy 权限授予监控代理、日志收集工具或健康检查工具,违反了“最小权限原则”。如果这些组件中的任何一个遭到入侵,攻击者就能在该节点上的所有容器中执行命令。 nodes/proxy 权限实际上相当于节点级的超级用户权限,如果随意授予该权限,将会大大增加安全事件的破坏范围。
通过使用 KubeletFineGrainedAuthz , kubelet 现在会在回退到 nodes/proxy 子资源之前,进行额外且更具体的授权检查。几个常用的 kubelet API 路径都被映射到了各自的专用子资源。

对于那些现在拥有细粒度子资源的端点( /pods 、 /runningPods/ 、 /healthz 、 /configz ), kubelet 会首先针对具体的子资源发送 SubjectAccessReview 请求。如果该请求通过验证,那么整个请求就会被授权。如果验证失败, kubelet 会为了保持向后兼容性,尝试使用粗粒度的 nodes/proxy 子资源来重新发送请求。
由于 kubelet 会进行双重授权验证(先进行细粒度的验证,再转而使用 nodes/proxy 的验证方式),因此对于大多数集群来说,升级到 v1.36 应该不会遇到任何问题。
用户命名空间
Kubernetes v1.36: User Namespaces in Kubernetes are finally GA
这是一个仅适用于 Linux 的特性。
这一特性还开启了一种关键模式:让工作负载在拥有特权的同时,依然被限制在用户命名空间内。 当设置 hostUsers: false 时,CAP_NET_ADMIN 这类权能(capabilities)会变成 被命名空间化(namespaced) 的权能, 这意味着它们只会授予容器本地资源的管理能力,而不会影响主机。 这实际上开启了此前只有运行完全特权容器(fully privileged container)才能实现的新用例。
在容器内以 root 身份运行的进程,从内核视角看,在主机上同样是 root。 如果攻击者成功逃逸出容器,无论是利用内核漏洞,还是借助配置错误的挂载(misconfigured mount), 他们都会在主机上获得 root 权限。
虽然运行容器时已经有许多安全防护措施,但这些措施并不会改变进程的底层身份, 它依然保留着 root 的某些“部分能力”。
在早期阶段,最大的阻碍之一是卷的所有权问题。 如果你把容器映射到较高的 UID 范围,Kubelet 就必须递归地对挂载卷中的每个文件执行 chown, 这样容器才能对这些文件进行读写。 对于大型卷来说,这一操作的成本高得惊人,足以摧毁启动性能。
实现这一目标的关键,是 ID-mapped mounts(在 Linux 5.12 中引入,并在后续版本中持续完善)。 借助这一机制,内核可以在挂载时重映射文件所有权,而不必改写磁盘上的实际所有权信息。
当一个卷被挂载到启用了用户命名空间的 Pod 中时,内核会透明地转换 UID(user ids)和 GID(group ids)。 对容器来说,这些文件看起来像是由 UID 0 拥有。 而在磁盘上,文件所有权完全不会变化,因此不需要执行 chown。 这是一个 O(1) 操作,既即时又高效。
使用用户命名空间非常直接:你只需要在 Pod spec 中设置 hostUsers: false。 无需修改容器镜像,也不需要复杂配置。 它仍然使用 Alpha 阶段引入的同一套接口。
SELinux 卷标签功能
SELinux Volume Label Changes goes GA (and likely implications in v1.37)
如果你在启用了 SELinux 强制模式的 Linux 系统上运行 Kubernetes,请提前做好规划:在未来的某个版本中(预计为 v1.37),该功能将默认处于启用状态。这对大多数工作负载来说能简化卷的配置流程,但对于那些仍依赖旧版递归重标记机制的应用程序来说,可能会带来问题(例如,在同一节点上,特权 Pod 与非特权 Pod 共享同一个卷时)。建议使用 Kubernetes v1.36 来检查你的集群,并根据需要修复相关问题或选择不应用此更改。
如果您的节点没有使用 SELinux,那么您无需做任何更改:当 Linux 内核中无法使用或禁用了 SELinux 时,kubelet 会直接跳过与 SELinux 相关的处理流程。您完全可以跳过这篇文章。
在堆栈结构允许的情况下,Kubelet 可以将卷挂载为 -o context=<label> 格式。这样一来,内核就能为该挂载点上的所有 inode 应用正确的标签,而无需进行递归的 inode 遍历。这一功能的启用取决于各种配置参数:首先,Pod 必须暴露足够的 SELinux 标签(例如 spec.securityContext.seLinuxOptions.level );其次,卷驱动程序也需要支持该功能(对于 CSI 来说,即需要设置 CSIDriver 字段为 spec.seLinuxMount: true )。
具体见原文。
Beta
已暂停 Job 的可变 Pod 资源
Kubernetes v1.36: Mutable Pod Resources for Suspended Jobs (beta)
Kubernetes v1.36 将允许在处于暂停状态的 Job 的 Pod 模板中修改容器资源请求和限制的功能提升到了测试版阶段。该功能最初在 v1.35 中作为测试版功能推出。借助这一功能,队列控制器和集群管理员可以在 Job 暂停时,即在它开始运行或恢复运行之前,调整其 CPU、内存、GPU 以及其它资源的配置。
批量处理和机器学习任务在创建时,其资源需求往往无法精确确定。最佳的资源配置需要考虑当前集群的容量、任务队列的优先级,以及 GPU 等专用硬件的可用性。在该功能推出之前,Job 的 Pod 模板中所指定的资源需求一旦确定,就无法再更改。如果像 Kueue 这样的队列控制器认为某个被暂停的 Job 应该使用不同的资源来运行,那么唯一的办法就是删除该 Job 后再重新创建它。这样一来,与该 Job 相关的所有元数据、状态和历史记录都会丢失。该功能还允许 CronJob 中的某个特定 Job 实例在资源受限的情况下仍能缓慢运行,从而避免在集群负载过重时导致该 Job 完全无法运行。
Kubernetes API 服务器针对处于暂停状态的作业,放宽了对 Pod 模板资源字段的“不可变”要求。并没有引入新的 API 类型;现有的 Job 和 Pod 模板结构通过放宽验证规则来适应这一变化。
在使用该功能处理那些可能包含已失败 Pod 的作业时,建议设置 podReplacementPolicy: Failed 参数。这样可以确保只有在之前的 Pod 完全终止后,才会创建新的 Pod,从而避免因多个 Pod 同时运行而导致的资源竞争问题。
资源健康状态
在 v1.34 发布之前,Kubernetes 缺少一种原生方式来报告已分配设备的健康状况, 这使得诊断由硬件故障导致的 Pod 崩溃变得困难。 在 v1.31 中聚焦于设备插件的初始 Alpha 版本基础上, Kubernetes v1.36 通过将每个 Pod 的 .status 中的 allocatedResourcesStatus 字段提升至 Beta,扩展了这一特性。 此字段为所有专用硬件提供统一的健康报告机制。
用户现在可以运行 kubectl describe pod 来判断容器的崩溃循环是否由 Unhealthy 或 Unknown 设备状态导致,无论相关硬件是通过传统插件还是较新的 DRA 框架制备。 这种增强的可见性使管理员和自动化控制器能够快速识别故障硬件, 并简化高性能工作负载的恢复流程。
Alpha
云控制器管理器中新增了用于路由同步的指标
Kubernetes v1.36: New Metric for Route Sync in the Cloud Controller Manager
Kubernetes v1.36 在 k8s.io/cloud-provider 处的云控制器管理器(CCM)路由控制功能中引入了一个新的 alpha 计数器指标 route_controller_route_sync_total 。每当路由与云服务提供商同步时,该指标的值就会增加。
添加这一指标的目的是为了帮助运维人员验证 Kubernetes v1.35 中引入的 CloudControllerManagerWatchBasedRoutesReconciliation 功能。该功能将路由控制器的运作方式从固定间隔的循环检测方式,改为基于节点状态变化的检测方式。这样一来,只有在节点确实发生变动时,才会进行相应的处理。这有助于减少对基础设施提供商的 API 调用次数,从而减轻 API 的限流压力,同时让运维人员能更高效地利用可用配额。
基于内存服务质量的控制层状内存保护机制
Kubernetes v1.36: Tiered Memory Protection with Memory QoS
内存 QoS 功能利用了 cgroup v2 内存控制器,从而让内核能够更准确地了解如何管理容器内存。该功能最初在 v1.22 中引入,后在 v1.27 中进行了改进。在 Kubernetes v1.36 中,我们新增了以下功能:用户可选择的内存预留机制、按 QoS 等级划分的保护机制、可观测性指标,以及针对特定内核版本的警告功能。
v1.36 将流量限制功能与内存预留功能分开处理。启用该功能后,系统的流量限制机制会被激活(Kubelet 会根据 memoryThrottlingFactor 的值来设置 memory.high ,默认值为 0.9)。不过,内存预留功能现在由 Kubelet 的另一个配置字段来控制。
- None (默认值):未输入 memory.min 或 memory.low 。此时仍可通过 memory.high 来控制流量。
- TieredReservation :Kubelet 会根据 Pod 的 QoS 等级来实施分层内存保护机制
控制器的过时问题缓解与可观测性提升
Kubernetes v1.36: Staleness Mitigation and Observability for Controllers
在 Kubernetes 控制器中,“僵化”现象是一个普遍存在的问题。它会以各种隐蔽的方式影响控制器的行为。通常,直到为时已晚——即生产环境中的控制器已经采取了错误的操作之后,人们才会意识到“僵化”现象所带来的问题。这些问题的根源往往在于控制器设计者所做出的某些假设。由“僵化”现象导致的问题包括:控制器采取错误的操作、在应该采取行动时却毫无反应,或者行动速度过慢。我很高兴地宣布,Kubernetes v1.36 新增了多项功能,有助于缓解控制器的“僵化”问题,并提升对控制器行为的可观测性。
控制器中的“过时数据”问题,源于控制器缓存中过时的数据信息。为了提供流畅的用户体验,控制器通常会维护一个关于集群状态的本地缓存。该缓存是通过持续监控 Kubernetes API 服务器上控制器所关注的各个对象的变更来更新的。当控制器需要采取行动时,它会先检查缓存中是否包含最新信息。如果缓存中的信息已经过时,控制器会继续监控 API 服务器的变更,从而更新缓存。这一过程被称为“同步/协调”。
不过,也有一些情况下,控制器的缓存可能会过时。例如,当控制器重新启动时,它需要通过监控 API 服务器上与自身相关的对象变化来重新构建缓存。在此期间,控制器的缓存将处于过时状态,因此无法正常执行任何操作。另外,如果 API 服务器发生故障,控制器的缓存也不会得到更新,同样无法正常工作。这些只是控制器缓存可能过时的部分情况而已。
Kubernetes v1.36 在 client-go 方面进行了改进,同时也在 kube-controller-manager 中改进了那些竞争激烈的控制器的实现方式,这些改进都得益于 client-go 方面的优化。
具体见原文。
2. Gateway API v1.5:功能已转入稳定版
Gateway API v1.5: Moving features to Stable
Kubernetes SIG Network 社区宣布 Gateway API(v1.5)版本现已发布!该版本于 2026 年 2 月 27 日发布,是我们迄今为止规模最大的一次发布。此次更新的主要目的是将那些原本处于“实验性”状态的功能转化为“稳定”状态。
Gateway API v1.5 为 Standard 频道带来了六项用户们长期期待的新增功能:这些功能都是通过 Gateway API 的正式发布渠道推出的。
- ListenerSet
- TLSRoute
- HTTPRoute CORS 过滤器
- 客户端证书验证
- 网关 TLS 发起连接的证书选择
- ReferenceGrant
更多信息见原文。
2. KubeVirt v1.8:机密计算、多 Hypervisor 与性能优化全面升级
KubeVirt v1.8:机密计算、多 Hypervisor 与性能优化全面升级
KubeVirt 是一个开源的 CNCF 项目,旨在通过 Kubernetes 的自定义资源定义(CRD)将虚拟机(VM)管理功能扩展到 Kubernetes 集群中。它实现了“容器原生虚拟化”,允许用户在同一个平台上以管理容器的方式来部署、运行和管理虚拟机。
KubeVirt v1.8 与 Kubernetes v1.35 保持对齐。
主要更新:
- 计算
- 机密计算增强:机密计算工作组引入了对 Intel TDX Attestation 的支持,机密虚拟机现在可以证明其运行在受信任的机密硬件上(当前为 Intel TDX)。
- Hypervisor 抽象层(HAL):引入 Hypervisor Abstraction Layer,使 KubeVirt 能够支持除 KVM 之外的多种 Hypervisor 后端,同时默认仍保持 KVM 优先策略。
- AI / HPC 性能优化:通过引入 PCIe NUMA 拓扑感知以及其他资源优化,使虚拟机内运行 AI 和 HPC 工作负载时可接近原生性能。
- 网络
- passt 绑定升级:passt 从插件升级为核心绑定,相比早期实现有显著改进。
- 网络热更新能力:支持在无需重启虚拟机的情况下更新 NAD(NetworkAttachmentDefinition)引用,实现运行时切换底层网络。
- 架构解耦优化:将 KubeVirt 与 NAD 定义解耦,减少 virt-controller 的 API 调用,消除大规模虚拟机启动时的性能瓶颈,同时通过减少权限提升安全性。(该变更处于弃用过渡阶段,需要提前做好适配准备)
- 存储
- ContainerPath Volume:支持将容器路径映射为虚拟机存储,提升可移植性与配置灵活性,并可用于云厂商凭证注入等场景。
- 基于 CBT 的增量备份:引入 Changed Block Tracking(CBT)实现增量备份,结合 QEMU 与 libvirt 的能力,实现与存储无关的虚拟机备份方案。
- 规模与性能
- 本版本在性能与规模测试方面也有提升:
- KWOK 性能测试规模提升至 8000 VMI
- 控制平面在大规模场景下仍表现稳定
- 关键数据:
- virt-api:140MB → 170MB(+30MB)
- virt-controller:65MB → 1400MB(+1335MB)
- 本版本在性能与规模测试方面也有提升:
📰 专题二 新闻与访谈
1. Prometheus 成立用户体验研究工作组
Introducing the UX Research Working Group
背景
在 2025 年的 PromCon 大会上,有一项用户研究结果被公布,其中指出了其中的几个问题。虽然这项研究的重点在于 Prometheus 和 OpenTelemetry 相关的工作流程,但总体结论很明确:Prometheus 若能得到持续的努力来了解用户需求并提升整体用户体验,将会受益匪浅。
如何帮助 Prometheus 的维护者们
也许正在考虑两种相互竞争的解决方案,希望了解除了技术方面的因素之外,用户在做出选择时还需要权衡哪些因素。
UX 工作组将与您合作开展用户调研,或对您的用户拓展计划提出反馈意见。具体内容包括:
- 用户研究报告与总结
- 用户旅程、角色模型、线框图、原型以及其他用户体验相关文档/成果
- 关于提升可用性、用户引导流程、互操作性以及文档质量的建议
- 用户痛点的优先级列表
- 关于社区讨论或决策主题的建议
如何加入
- Slack:#prometheus-ux-wg
- 会议安排:我们每两周召开一次会议,目前是在 UTC 时间每周三的 14:00 召开(具体时间可能会根据参与人员的安排而有所变动)。
- GitHub: prometheus-community/ux-research
2. Nutanix 在.next 2026 大会上重点展示了基于智能代理技术的 AI 解决方案以及直接运行在裸机上的 Kubernetes 系统
Nutanix pushes agentic AI, bare-metal Kubernetes at .NEXT 2026
Nutanix Agentic AI 与 Neoclouds 支持
Nutanix Agentic AI 与 Nvidia AI Enterprise 深度集成,帮助客户构建、运行和保护 AI 代理应用。推出多租户框架和管理平台,旨在帮助“新云”服务提供商(Neoclouds)向企业提供高性能的 AI 推理服务(如 GPU-aaS、模型即服务等)。
Nutanix Agentic AI 目前处于早期测试阶段,预计将于 2026 年下半年正式上市。
裸机 Kubernetes (NKP Metal)
出 NKP Metal,支持在物理裸机上直接运行 Kubernetes 容器。这消除了虚拟化损耗,特别适合需要高密度 GPU 支持的 AI 训练和边缘计算任务。
客户可以选择通过 CSI(容器存储接口)来使用 Nutanix 存储解决方案;或者选择使用 Cloud Native AOS 作为专为 Kubernetes 裸机部署而设计的存储方案。同时,客户还可以利用 Nutanix Data Services 来获取 Kubernetes 原生的数据服务。这样一来,就能实现端到端的 Nutanix 体验,同时让存储更贴近 Kubernetes 工作负载的需求。
NKP Metal 功能现已向 NKP Pro 和 NKP Ult 许可证的用户提供抢先体验版,预计将在 2026 年下半年全面上市。
3. 庆祝 Cilium 十周年:有哪些新进展,下一步又将走向何方
庆祝 Cilium 十周年:有哪些新进展,下一步又将走向何方
Cilium 正式迎来了它的 10 周年,并已稳固确立了自己作为生产级云原生部署默认 CNI 的地位。它已被所有主流云厂商采用,并且在客户需求推动下,许多其他云平台和 Kubernetes 发行版也正在大力投入,将 Cilium 作为其首选 CNI。根据最新的《Kubernetes Networking 状态报告》,Cilium 在 CNI 部署中的占比已超过 60%,是第二名替代方案的两倍以上。
这种稳定性同样反映了其背后的社区力量。如今,Cilium 已拥有一个不断壮大的开发者社区,成员超过 1,010 人,项目在 GitHub 上也已获得超过 24,000 个 Star。自项目第一年起,其年度开发活跃度已增长了 55 倍,仅 2025 年一年就有近 10,000 个 PR 被提交。
展望下一个十年,Cilium 已经确立了其作为 AI 网络数据平面的地位。Microsoft 和 Google 正使用 Cilium 运行全球一些规模最大的 AI 训练集群。像 ESnet 和 TikTok 这样的组织,则正在超大规模的纯 IPv6 数据中心中运行 Cilium。与此同时,Tetragon 有望重新定义运行时安全格局,而 Cluster Mesh 和 KubeVirt 等工具的结合,将使组织能够在统一的网络平面上同时运行虚拟机和容器。
2 月发布的 Cilium 1.19 延续了项目的发展势头,在网络、策略和可观测性方面都带来了改进。
- 面向 mTLS 的 ztunnel 集成:可以将命名空间纳入 ztunnel,实现透明的四层双向 TLS(mTLS)Pod 间流量保护,而无需对应用进行修改。关于这一新特性的意义以及其背后的工作,可进一步阅读相关内容。
- 增强的 IPv6 支持:IPv6 支持现已扩展到 Cilium 的二层服务通告和隧道网络,消除了运行 IPv6 优先或双栈环境团队所面临的限制。
- Multi-Pool IPAM 达到稳定版:Multi-Pool IPAM 已从 Beta 晋升为 Stable,并获得了实质性增强。团队现在可以基于工作负载身份分配 Pod IP,强制执行严格的地址池匹配,并为路由流量保留真实源 IP,在不做权衡取舍的前提下,同时获得灵活性与安全性。
- 更智能的 DNS 网络策略:新增的通配前缀机制,使编写基于 DNS 的出口策略变得更加容易,可通过单条规则覆盖完整的子域层级,从而降低复杂性,并减少授予过宽访问权限的风险。
- Hubble 流日志聚合:Hubble 现在可以在导出前先对流日志进行聚合,按命名空间、服务或判定结果,在设定时间间隔内对流量进行分组。对于高负载集群,这可以显著减少日志量,同时保留监控和分析所需的上下文信息。
💬 专题三 讨论与分享
1. 由 HPA 管理的工作负载:为何这种明显的浪费依然存在?
HPA-managed workloads: Why the obvious waste stays
运行 Kubernetes 的团队通常能够发现自己在哪些方面存在资源过度配置的问题。实际的需求量低于应有的水平,系统中始终有闲置的容量,但这些资源却未被充分利用。这种情况在由 HPA 管理的服务中尤为常见。其低效率显而易见:随着 HPA 规模的扩大,浪费现象也会随之加剧。但不太明显的是,当对这种机制进行更改时,会发生什么情况。
对于由 HPA 管理的工作负载而言,请求量不仅仅是用于确定规模大小的参数。它们还会影响系统的扩展行为。HPA 的决策会依据利用率来进行调整,因此当请求量发生变化时,利用率也会随之改变。这又会影响到系统扩展时的行为,以及副本数量的增加速度。
这就是为什么资源更改与代码部署有着本质上的不同。代码部署出错时,总有明确的回滚方案。而资源更改则更为隐蔽:它改变了工作负载与调度器之间的“隐性契约”。问题可能要等到周五下午,当流量激增到旧有参数下根本不会出现的水平时才会显现出来。到那时,还有另外三件事也发生了变化,要确定因果关系几乎是不可能的。
在大多数情况下,这并非出于惯性或无知,而是一种刻意的选择。各团队都在维持那些已经行之有效的行为方式。
一旦某件事物看起来“运转正常”,那么任何可能改变其运行机制的改动都会被视为有风险。大多数团队宁愿忍受现有的浪费状况,也不愿在自己已经依赖的服务中引入新的变量。
诚实地说明原因是很重要的:那些决定资源价值的人,正是那些在凌晨 2 点因为设备故障而被叫醒的人。这种风险并非抽象的概念。虽然削减成本的提议在技术上可能是正确的,但如果涉及到某个六个月前就发生过故障的团队所负责的服务,那么该团队根本不会做出任何改变。节省成本的好处远远抵不上个人需要承担的责任。
大多数用于调整工作流程的方法都遵循一个简单的循环:调整请求参数,观察结果,然后进行迭代调整。这种方法适用于那些服务较为稳定的情况,因为在这些情况下,请求参数的变更不会影响服务的扩展行为。
这与由 HPA 管理的工作负载方式截然不同:在 HPA 管理的方式中,请求处理和扩展操作是紧密关联的。而在模型服务类工作负载中,这种情况更为复杂:流量变化可能非常迅速,而且为应对潜在的流量峰值而预留的额外资源所带来的成本也非常明显。
这种故障模式尤其危险,因为它不会立即显现出来。某个服务在整个星期内的平均使用率可能都很低,但随后会突然出现流量激增的情况。此时,那些看似被浪费了的资源,其实正是维持服务稳定运行的关键因素。如果自动化系统仅根据近期的平均数据来调整参数,那么它就无法考虑到各种业务因素:比如产品发布、季节性需求波动、营销活动,以及季度末的流量激增现象——而这些因素并不体现在过去两周的数据中。
有效的处理方式是将请求与 HPA 目标视为一个整体来处理。只要对两者进行原子性调整,那么即使在资源占用量减少的情况下,工作负载的性能也能保持稳定。
但即便采用了正确的技术方法,单凭这一点也是不够的。团队需要了解每一项变更背后的理由,而不仅仅是相关的建议而已。他们还需要有相应的约束机制,以确保各项操作都符合既定的服务水平协议。此外,还需要一个循序渐进的流程:先确保对各项操作的透明度,再批准那些经过评估的建议,只有在赢得了信任之后,才能最终实现自动化。如果直接跳到完全自动化的阶段,是无法建立信任的。因为这样会跳过建立信任的必要过程。
这种信任度差异在更广泛的 Kubernetes 市场中同样存在。在 CloudBolt 最近关于 Kubernetes 自动化领域信任度问题的研究中,各团队一致表示:与自动执行相比,能够清晰了解现状并获取相应的建议要容易得多。
为了便于操作,团队还需要能够实现自动回滚功能。不必“提交工单再等待处理”。这一过程应该是自动的、快速的,并且由团队已经信任的健康监测指标来触发。如果没有了那些因素,最简单的处理方式就是:别去管它。
最昂贵的低效率问题,恰恰存在于那些没人敢擅自更改的工作流程中。
2. VMware vSphere Kubernetes Service 的可观测性
Observability on VMware vSphere Kubernetes Service
指标/数据
在指标收集方面,该架构采用了 Prometheus 社区技术栈(kube-prometheus-stack)。该技术栈包括用于动态目标发现的 Prometheus Operator、用于制作仪表盘的 Grafana,以及用于收集节点级统计数据的 Node Exporter。此外,Istio 服务的遥测数据也被整合进来,这些数据与 VCF Operations 系统相连,从而提供了关于底层基础设施的详细信息。
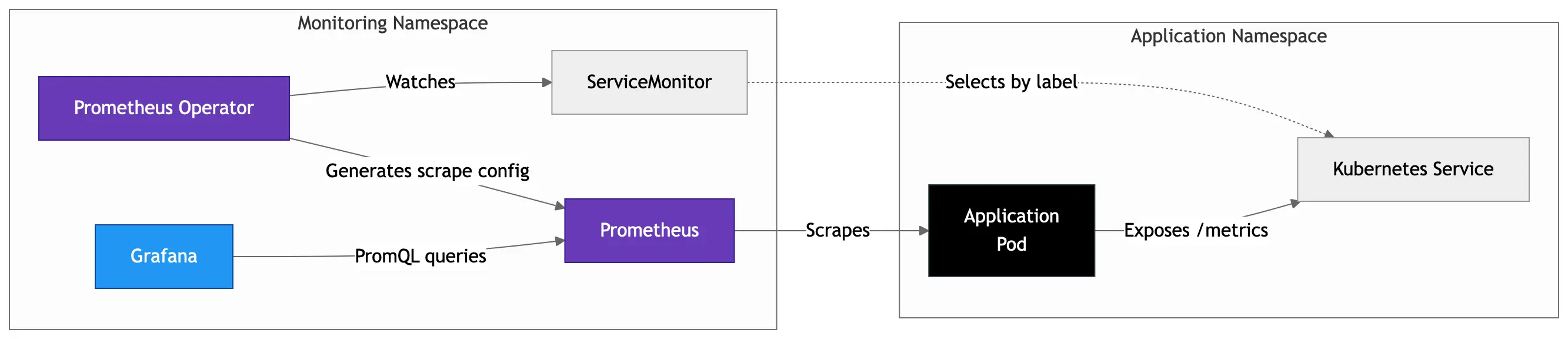
日志
在日志处理方面,Fluent Bit 负责收集和整理 Kubernetes 系统的日志数据。Grafana 和 Loki 则共同承担了日志的存储与索引功能,从而使得用户能够在 Grafana 中方便地查看和分析 Kubernetes 系统的日志。同一条日志流还会被发送到 VCF Operations for Logs 系统中,以便与整个基础设施环境中的其他数据相互关联起来。

追踪
在追踪功能方面,OpenTelemetry 被用于实现分布式追踪;Jaeger v2 则负责接收和可视化 OTLP 格式的追踪数据;OpenSearch 则作为永久性的追踪数据存储后端。这样一来,就可以追踪请求在各个服务之间的流动情况,并结合相关的应用程序和平台监控数据来进行分析。

拓展阅读:Observability on vSphere Kubernetes Service - Reference Architecture
3. Kubernetes 控制平面是如何运作的
How the Kubernetes control plane works
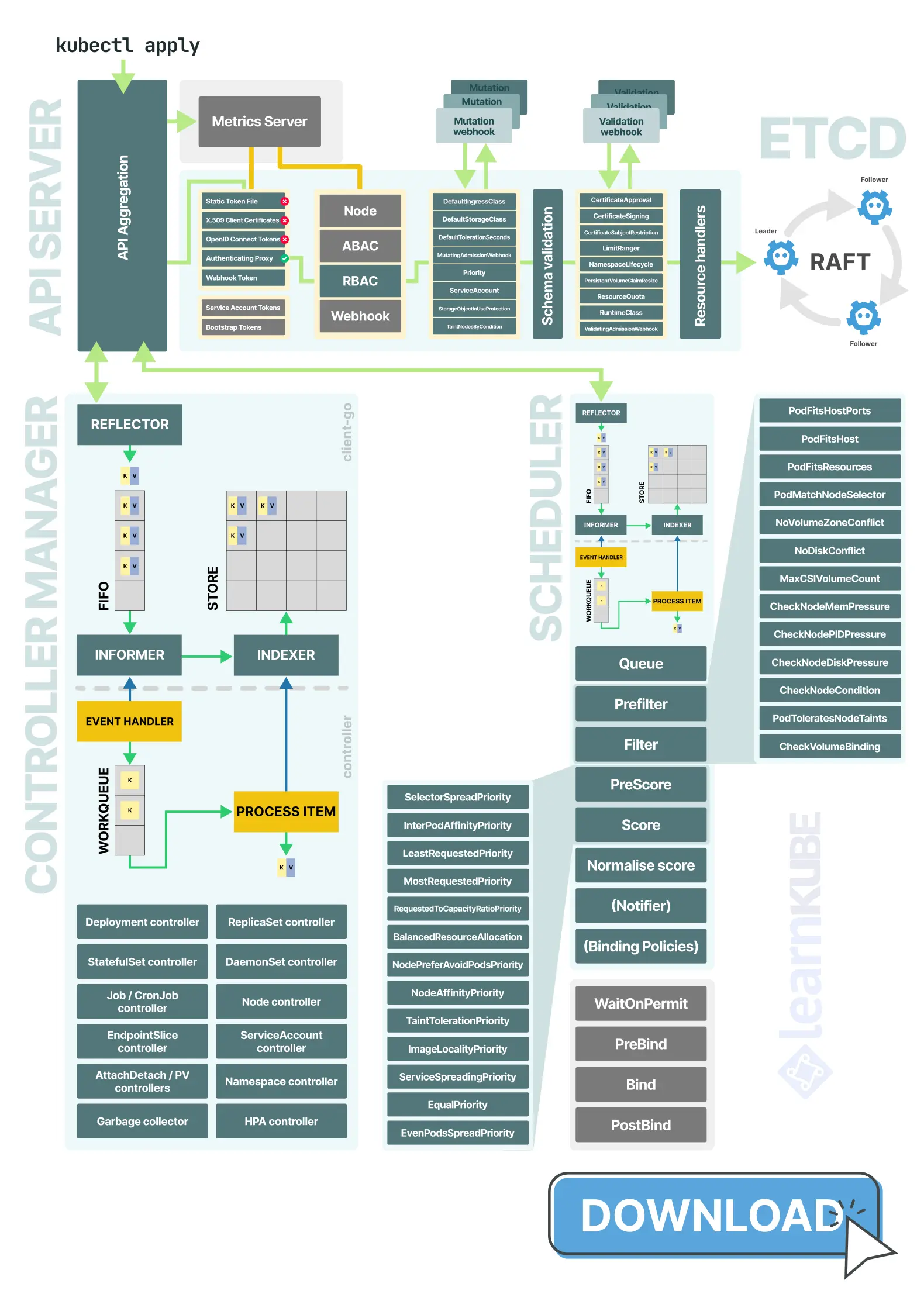
控制平面包含哪些组件?
Kubernetes 控制平面由四个主要部分组成:
- API Server,它是进入该集群的“前门”。负责处理与请求路径相关的各项操作:身份验证、授权、请求处理以及数据存储。
- etcd,用于久地、一致地存储集群状态。
- scheduler,负责为每个 Pod 选择相应的节点。只需做出一个决策:每个未安排好运行位置的 Pod 应部署在何处。
- controller manager,通过循环处理,确保实际状态与期望状态保持一致。负责在 Deployments、ReplicaSets、StatefulSets 等组件背后运行各种协调处理流程。
API Server
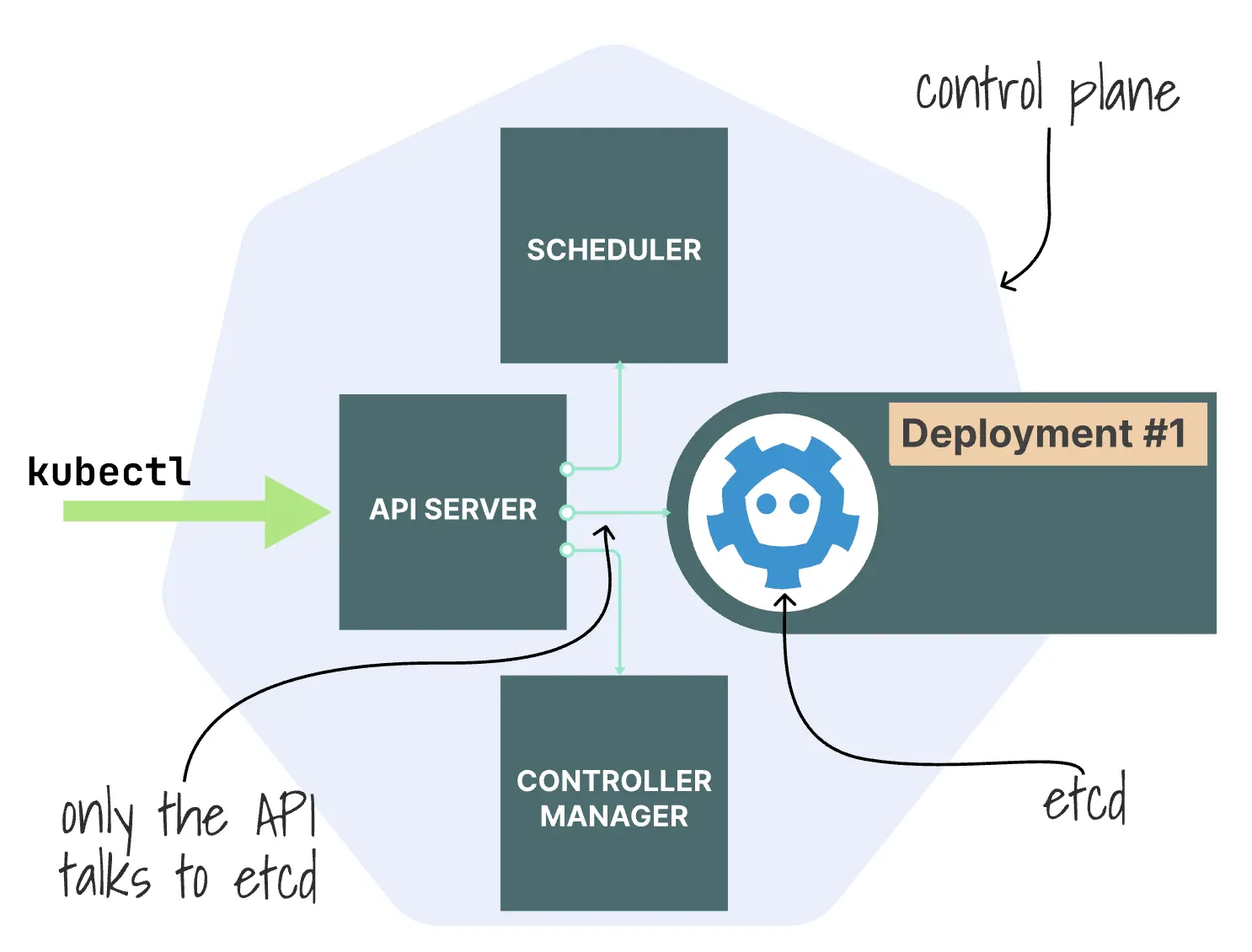
Kubernetes 不会将该 Deployment 直接保存到存储设备中。在存储请求之前,API 服务器会对其进行身份验证、授权检查、数据结构验证等处理。只有这样,它才会将请求交给相应的资源处理程序,并将其持久化存储在 etcd 中。
API 服务器还负责管理 API 的聚合功能。这样一来,即使某些 API 是由其他组件来提供的,像 Metrics Server 这样的 API 看起来也依然像是直接由该服务器提供的。从身份验证到数据存储的整个请求路径,正是 API 服务器核心功能的体现。
etcd
一旦 API Server 接受了某项更改,就会将其写入 etcd 中。只有API Server 会直接与 etcd 进行通信:scheduler 和 controller manager 则通过监听 API 服务器来获取所需信息,而无需直接连接数据库。
Etcd 是一种基于 Raft 算法构建的小型、一致性良好的键值存储系统。领导者接收写入请求,将其复制给其他成员。一旦达到法定人数的一致同意,就会提交新的版本。
这种组合方式使得 Kubernetes 能够实现有序的更新和高效的变更通知机制,因为控制平面是建立在 etcd 的版本控制与监控机制之上的。在大型集群中,这些优点也会带来一些弊端:达成共识的代价较高;数据库使用单个 bbolt 文件来存储数据;每次更改都会生成一个新的版本;此外,API 服务器由于其缓存和监控机制,会增加系统的负载。这也是 etcd 可能成为扩展瓶颈的地方。
scheduler
scheduler 也以循环方式运行,但其功能更为专注。它会查找那些没有对应节点的 Pod,移除那些无法运行这些 Pod 的节点,对剩余的节点进行排序,然后将相应的 Pod 分配到选定的节点上。在实际操作中,调度过程通常首先是淘汰那些不合适的节点,然后再对剩余的节点进行排序。
controller manager
Deployment 保存后,controller manager 会自动检测到这一变更。此时,Kubernetes 已不再仅仅是用于存储对象的工具,而演变成了一个具备自动化功能的系统。controller manager 负责运行许多较小的控制循环。每个循环负责处理系统的不同部分:有的负责创建 Pod,有的负责响应节点或端点的变化,有的负责管理存储,还有些则负责清理未使用的对象。所有这些循环都遵循相同的模式:首先观察当前状态,将其与期望状态进行比较,然后采取相应措施来缩小差距,最后重复这一过程。
4. 从 ingress-nginx 迁移到 Envoy Gateway:CNCF 内部服务集群的实践
从 ingress-nginx 迁移到 Envoy Gateway:CNCF 内部服务集群的实践
背景
CNCF 维护着一个 Kubernetes 集群,用于运行一些内部服务,例如 codimd、GUAC 和 kcp。随着 Kubernetes 社区宣布 ingress-nginx 进入退役阶段,这也直接影响到了上述集群。因此,我们开始评估替代方案。经过讨论后,我们决定继续沿用 Gateway API 方向,并选择其实现之一:Envoy Gateway。
Gateway API 与 ingress-nginx 的架构差异
ingress-nginx 的工作方式比较直接:通常只配一个 LoadBalancer 类型的 Service,由 Ingress Controller 接收所有入口流量,再根据 Ingress 对象的配置把请求分发到对应后端。相比之下,Gateway API 采用的是分层设计。
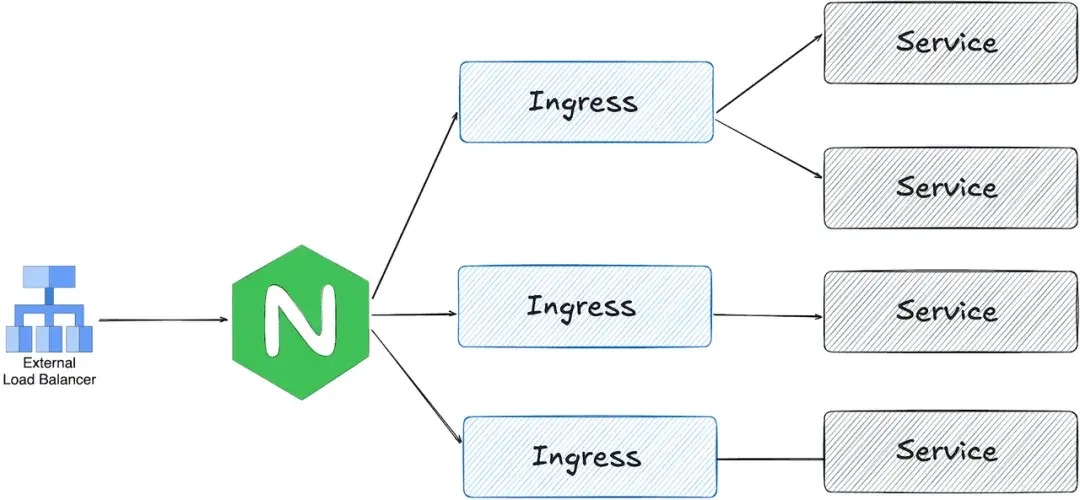
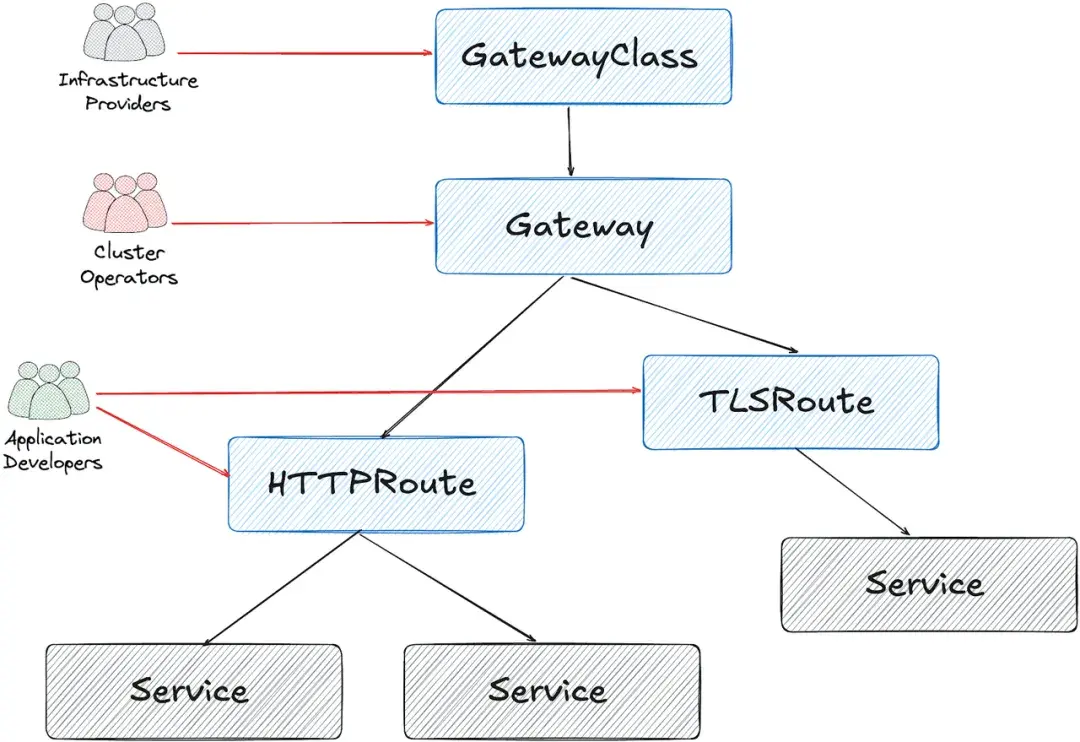
服务集群的配置方式
最终落地的配置主要包括:
- 使用 Envoy Gateway 的 GatewayClass
- 一个供 Guac、codimd 和 kcp 共享的 Gateway
- 用于配置 HPA、Service 类型及其他代理参数的 EnvoyProxy
- 每个服务对应的 HTTPRoute
- 允许 Gateway 跨命名空间访问 SSL 证书的 ReferenceGrant
- 用于处理后端 HTTPS 连接的 BackendTLSPolicy
迁移方案的选择
当时有两个选择:
- 新增一个使用独立公网 IP 的 Envoy Gateway,并通过 DNS 轮询让流量同时进入 ingress-nginx 和 Envoy
- 让 Envoy Gateway 直接复用当前 IP,一次性整体切流
虽然第一种方案更稳妥,但出于操作简单的考虑,我们最终选择了第二种。
证书处理
一开始选择继续复用由 ingress-nginx 注解机制触发生成的现有证书。但这里有个隐患:这些证书对象的 ownerReference 指向的是 Ingress。 这意味着,一旦删除对应的 Ingress,相关的 Certificate 以及它背后的 Secret 也会被级联删除。
由于证书可能存放在不同的命名空间,而 Gateway 通常部署在自己的命名空间中,为了允许 Gateway 访问这些证书 Secret,需要为每个存放证书的命名空间创建 ReferenceGrant 对象,明确授权 Gateway 进行跨命名空间引用。
在迁移当时,我们有意没有立即调整证书管理方式,而是优先缩小迁移范围,先复用现有证书。后续让证书真正由 Gateway API + cert-manager 接管。
总结
这次从 ingress-nginx 迁移到 Envoy Gateway,几个真正需要重点关注的问题是:
- 证书的归属关系,以及跨命名空间访问
- 云负载均衡器与 NodePort、健康检查、externalTrafficPolicy 之间的配合
- 面向 HTTPS 上游服务时的 Backend TLS 配置
Gateway API 的多层架构,相比 ingress-nginx 确实带来了更清晰的职责划分;但与此同时,也要求使用者理解更多资源对象,例如 ReferenceGrant 和 BackendTLSPolicy。
📄 专题四 报告查看与分析
💁♀️ 专题五 产品/方案介绍
1. Awesome Prometheus Alerts:951 条可直接复制粘贴的 Prometheus 告警规则
支持各种各样的报警规则,具体见原文。