🆕 专题一 产品新功能/新版本
1. Gateway API 1.4:新功能
简介
Gateway API v1.4.0 为 Standard Channel 带来了三项新功能 (网关 API 的正式版发布渠道):
- 用于网关和后端之间 TLS 的后端 TLS 策略
- GatewayClass 状态中的 supportedFeatures
- Named rules for Routes 路由命名规则
并引入了三项新的实验性功能:
- 用于服务网格配置的网格资源
- 默认网关可减轻配置负担
- HTTPRoute 的 externalAuth 过滤器
升入 Standard Channel
后端 TLS 策略
BackendTLSPolicy 是一种新的网关 API 类型,用于指定从网关到后端 Pod 连接的 TLS 配置。在引入 BackendTLSPolicy 之前,没有 API 规范允许在从网关到后端的跃点上进行加密流量。
实现所支持的功能的状态信息
GatewayClass 状态新增了一个字段:supportedFeatures。此字段允许实现声明其支持的功能集。这为用户和工具提供了一种清晰的方式来了解给定 GatewayClass 的功能。
路由规则命名
这项增强功能使得路由规则能够在网关 API 生态系统中被明确识别和引用。
Experimental Channel 的变化
为 HTTPRoute 启用外部身份验证
此 Gateway API 版本在 HTTPRoute 中添加了一个实验性过滤器,该过滤器指示 Gateway API 实现调用外部服务来验证(以及可选地授权)请求。
网格资源
Gateway API v1.4.0 引入了一种新的实验性 Mesh 资源,它提供了一种配置网格级设置并发现给定网格实现所支持的功能的方法。此资源类似于 Gateway 资源,最初主要用于一致性测试,未来计划将其用途扩展到集群外的 Gateway。
引入默认网关
对于应用程序开发人员来说,一个常见的反馈是需要为每个南北向路由显式指定一个父网关。虽然这种显式指定可以避免歧义,但也增加了开发难度,尤其对于那些只想将应用程序暴露给外部世界,而不想操心底层基础设施命名方案的开发人员而言。为了解决这个问题,我们引入了默认网关的概念。
配置客户端证书验证
此版本更新了客户端证书验证的配置,解决了与连接重用相关的严重安全漏洞。HTTP 连接合并是一种 Web 性能优化技术,允许客户端重用现有的 TLS 连接来请求不同的域。虽然这减少了建立新连接的开销,但在 API 网关的上下文中却引入了安全风险。由于允许在多个监听器之间重用单个 TLS 连接,因此需要引入共享客户端证书配置,以避免未经授权的访问。
重大变更
标准 GRPCRoute - .spec 字段为必填项(技术性要求)
GRPCRoute 升级为标准资源后,引入了一个虽小但技术上具有破坏性的变更,即顶级 .spec 字段的出现。作为达到标准地位的一部分,Gateway API 加强了 GRPCRoute 自定义资源定义 (CRD) 中的 OpenAPI 模式验证,明确确保所有 GRPCRoute 资源都必须包含 spec 字段。此变更强制执行更严格的 Kubernetes 对象标准,并增强了资源的稳定性和可预测性。虽然用户不太可能尝试定义一个没有任何 spec 字段的 GRPCRoute,但任何可能依赖于宽松解释(允许 spec 字段完全缺失)的现有自动化流程或清单现在都将无法通过验证,并且必须更新以包含 .spec 字段,即使该字段为空。
HTTPRoute 中的实验性 CORS 支持 - allowCredentials 字段的重大变更
Gateway API 子项目对 HTTPRoute 中的实验性 CORS 支持引入了一项重大变更,涉及 allowCredentials 字段。 符合 CORS 政策。 该字段的定义严格遵循上游 CORS 规范,该规范规定了相应的 Access-Control-Allow-Credentials 标头必须表示布尔值。 此前,该实现可能过于宽松,可能会接受非标准或字符串表示形式,例如: 由于放宽了模式验证, true 。配置 CORS 规则的用户现在必须检查其清单文件,并确保 allowCredentials 的值正确。 严格遵守新的、更严格的规范。 任何不符合此更严格验证条件的现有 HTTPRoute 定义现在都将被 API 服务器拒绝。 需要进行配置更新以维持功能。
2. Linkerd 2.19:后量子密码学
简介
Linkerd 是一个超轻量级、安全至上的 Kubernetes 服务网格。Linkerd 无需任何代码更改即可为您的 Kubernetes 堆栈添加关键的安全性、可观测性和可靠性功能。
Linkerd 是云原生计算基金会 (CNCF) 的一个项目。
更新内容
本次版本带来了 Linkerd 安全性的重大提升:默认启用现代化的 TLS 栈,采用后量子密钥交换算法。支持 Windows 服务网格、后量子密码学、供应链安全、FIPS 140-3 认证及新的集群仪表盘。
“后 xx”
-
- 后量子密码学(英语:Post-quantum cryptography,缩写:PQC),又称为防量子、量子安全、抗量子计算,是密码学的一个研究领域,专门研究能够抵抗量子计算机进行密码分析攻击的加密算法(特别是公钥加密算法)。计算机与互联网领域广泛使用的公钥加密算法均基于三个计算难题:整数分解问题、离散对数问题或椭圆曲线离散对数问题。然而,这些难题均可使用量子计算机并应用秀尔算法破解,或是比秀尔算法更快,需求量子比特更少的其他算法破解。
- 后现代主义(英语:Postmodernism)是一个以“难以下定论”为特点的主义,主要发生在 20 世纪中期到 21 世纪前期,上接现代主义。后现代主义的追随者有意识的跳脱出约定俗成的框架之外,热衷于把自己的作品塑造为一种前所未闻的新形式。在后现代主义之后,世界各地的哲学、艺术、建筑、文学就分裂成各种流派,再无一个统一的风潮。
- 后摇滚(英语:Post-rock)在分类上尚有争议,有些人将其看作摇滚乐的一种。后摇的一个特点是,所用乐器一般与摇滚乐相同,但节奏、和声、旋律、音色及和弦进行都有别于传统摇滚。在后摇滚音乐里,许多常见的音乐产业传统现象都被颠覆改写,例如吉他不再是主要角色;没有歌词或主唱;打破传统歌曲长度,有些乐曲甚至长达二、三十分钟,后摇滚甚至想打破唱片工业创造一首脍炙人口单曲的愿望。
- 后朋克(英语:Post-punk,最初称为 New musick,直译:新音乐)源自 20 世纪 70 年代的摇滚音乐,是 1977 年末随着朋克摇滚而兴起的一种广泛的音乐流派。后朋克音乐家们背离了朋克的基本元素和原始的简约风格,转而采取了一种更广泛、更具实验性的方法,融合了各种前卫情感和非摇滚的影响。受到朋克活力和“自己动手做”(DIY)精神的启发,但又决心打破摇滚的陈腔滥调,艺术家们尝试了放克、电子音乐、爵士乐和舞曲等风格;回响和迪斯科的制作技巧;以及来自艺术和政治的理念,包括批判理论、现代主义艺术、电影和文学。
3. External Secrets Operator 1.0.0 正式发布
External Secrets Operator is now GA with version v1.0.0
External Secrets Operator 是一个 Kubernetes Operator,它集成了外部机密管理系统,例如 AWS Secrets Manager 、 HashiCorp Vault 、 Google Secrets Manager 、 Azure Key Vault 、 IBM Cloud Secrets Manager 、 Akeyless 、 CyberArk Conjur 、 Pulumi ESC 等等。该 Operator 从外部 API 读取信息,并自动将值注入 Kubernetes Secret 中。
🎤 在 2025 年 8 月的简报中,曾经摘录过 ESO 项目暂停,等待团队重建的消息。经过一系列的努力,三个月后,ESO 正式发布了 1.0.0 版本 :)
4. AWS Backup 支持 Amazon EKS 集群
Secure EKS clusters with the new support for Amazon EKS in AWS Backup
AWS Backup 与 Amazon EKS 简介
AWS Backup 是一项完全托管的服务,可集中管理并自动化跨 AWS 服务和混合工作负载的数据保护。它提供核心数据保护功能、勒索软件恢复功能,以及针对数据保护策略和操作的合规性洞察和分析。AWS Backup 提供经济高效、基于策略的服务,其功能可简化跨 AWS 环境的 EB 级数据保护。
Amazon Elastic Kubernetes Service (Amazon EKS) 是一项托管式 Kubernetes (K8s) 服务,可在 AWS 云和本地数据中心运行 Kubernetes。在云端,Amazon EKS 会自动管理 Kubernetes 控制平面节点的可用性和可扩展性,这些节点负责调度容器、管理应用程序可用性、存储集群数据以及其他关键任务。借助 Amazon EKS,您可以充分利用 AWS 基础设施的性能、规模、可靠性和可用性,以及与 AWS 网络和安全服务的集成。
简介
此前,客户在备份方面依赖自定义解决方案或第三方工具来备份其 EKS 集群,这需要为每个集群编写复杂的脚本并进行维护。AWS Backup 对 Amazon EKS 的支持消除了这些额外开销,提供了一个单一的、集中式的、策略驱动的解决方案,可以保护 EKS 集群(Kubernetes 部署和资源)以及有状态数据(仅存储在 Amazon Elastic Block Store (Amazon EBS) 、Amazon Elastic File System (Amazon EFS) 和 Amazon Simple Storage Service (Amazon S3) 中,而无需跨集群管理自定义脚本。在恢复方面,客户以前需要将 EKS 备份恢复到目标 EKS 集群,该目标集群可以是源 EKS 集群,也可以是新的 EKS 集群,这意味着需要在恢复之前预先配置 EKS 集群基础设施。借助这项新功能,在恢复 EKS 集群备份期间,客户还可以选择基于先前的 EKS 集群配置设置创建一个新的 EKS 集群,并将备份恢复到这个新的 EKS 集群,AWS Backup 将代表客户管理 EKS 集群的配置。
5. Helm v4.0.0 发布
简介
Helm 4 的首个稳定版本。
新功能
- 插件系统重设计:重新设计了插件系统,现在支持基于 Web Assembly 的插件,并且后渲染器(Post-renderers)也已成为插件。
- 服务端应用支持:全面支持 Kubernetes 的服务端应用(Server Side Apply)。
- 改进的资源监控:基于 kstatus 改进了资源监控,以支持等待(waiting)操作。
- 本地内容缓存:引入了本地内容缓存,例如用于 chart。
- 现代日志记录:通过 slog 实现了更现代的日志记录,使 SDK 日志能够与现代日志记录器集成。
- 可重现构建:支持 chart 归档的可重现构建。
- SDK API 更新:更新了 SDK API,包括支持多种 chart API 版本(新的实验性 v3 chart API 即将推出)。
与 Helm v3 的兼容性
- Helm v4 是一个主要版本,包含向后不兼容的更改,主要体现在 Helm CLI 的标志和输出以及 SDK 上。然而,这些变化不如从 Helm v2 到 v3 那样广泛,目标是使大多数工作流在 v3 和 v4 之间保持兼容。
- 现有的 Helm chart apiVersion v2(目前大多数 chart)在 Helm v4 中将继续得到支持,现有 chart 应该能够正常安装、升级和运行。
- 重要提示: 建议用户测试其 chart 的安装和升级,因为像服务端应用这样的新功能可能会影响使用体验。
未来计划
- 下一批补丁版本 3.19.3 和 4.0.1 将于 2025 年 12 月 10 日发布。
- 下一次要版本 3.20.0 和 4.1.0 将于 2026 年 1 月 21 日发布。
6. Red Hat OpenShift 4.20 发布,加速虚拟化和企业人工智能创新
Red Hat OpenShift 4.20 accelerates virtualization and enterprise AI innovation
简介
Red Hat OpenShift 4.20 现已正式发布。它基于 Kubernetes 1.33 和 CRI-O 1.33,并与 Red Hat OpenShift Platform Plus 一起,彰显了我们致力于提供值得信赖、全面且一致的应用平台的承诺。在 OpenShift 上,AI 工作负载、容器和虚拟化可以无缝共存,使企业能够在混合云环境中更快地进行创新,同时确保安全性。
重要更新
- 使用 LeaderWorkerSet 和 JobSet 分发和扩展 AI/ML 工作负载
- 使用 Red Hat OpenShift AI 3 进行原生 AI 路由
- 无需重启 Pod 即可更新 AI 模型
- 提供 OpenShift 和 Kubernetes 的 MCP 服务器开发者预览版,可通过自然语言管理集群和排除故障
- 通过 NVIDIA Bluefield DPU 加速 AI 工作负载
- 通过原生 OIDC 简化身份管理
- 在 OpenShift 上使用零信任管理工作负载身份
- 使用外部密钥操作员简化密钥管理
- 通过用户命名空间消除容器权限提升风险
- 使用 Istio 环境模式的无边车服务网格
- OVN-Kubernetes 现已提供原生 BGP 路由功能
- 支持升级前检查
- 支持带仲裁节点的两节点 OpenShift,降低边缘部署成本
- 虚拟化增强 (Red Hat OpenShift Virtualization 4.20)
- 扩展对 Oracle Cloud Infrastructure 的支持
拓展阅读
Red Hat OpenShift 4.20 Boosts AI, Security, Hybrid Cloud
7. KubeEdge 1.22.0:边缘资源管理能力提升
KubeEdge 1.22.0版本发布!边缘资源管理能力提升!
KubeEdge 简介
KubeEdge 构建于 Kubernetes 之上,并将原生容器化应用编排和设备管理功能扩展到边缘主机。它由云端和边缘两部分组成,为云端和边缘之间的网络、应用部署和元数据同步提供核心基础设施支持。它还支持 MQTT,使边缘设备能够通过边缘节点进行访问。
借助 KubeEdge,可以轻松地将现有的复杂机器学习、图像识别、事件处理和其他高级应用程序部署到边缘。由于业务逻辑运行在边缘,因此可以在数据产生地本地安全地处理海量数据。边缘数据处理显著提高了响应速度,并保护了数据隐私。
KubeEdge 是由云原生计算基金会 (CNCF) 托管的毕业级项目。
新增特性
- 新增 hold/release 机制控制边缘资源更新
- Beehive 框架升级,支持配置子模块重启策略
- 基于物模型与产品概念的设备模型能力升级
- 边缘轻量化 Kubelet 新增 Pod Resources Server 和 CSI Plugin 特性开关
- C 语言版本的 Mapper-Framework 支持
- 升级 K8s 依赖到 1.31
8. SKS 1.5 发布:容器跨站点双活护航关键业务
发布背景
随着 Kubernetes 承载的业务从边缘、一般性应用,逐步深入到企业的核心生产系统,这也对服务连续性提出了前所未有的严苛要求。传统的单数据中心部署模式,在面对机房断电、网络中断等“站点级”故障时,其固有的脆弱性便暴露无遗。因此,“如何为容器化核心业务构建一个可靠的容灾体系?”——这一挑战已摆在众多 CIO 和 IT 负责人面前。 用户需要的不再是简单的备份恢复,而是真正具备自动故障切换能力的应用双活方案。
为应对上述挑战,SmartX 凭借在双活存储领域的深厚积累,将成熟的双活能力创新性地与容器平台深度融合,使 SKS 成为真正能够支撑企业关键任务的生产级平台。
支持双活部署,提升 Kubernetes 集群可靠性
SKS 1.5 新增基于 SmartX 超融合软件的双活集群部署能力,该功能通过将 Kubernetes 集群同时分布于优先、次级可用域,实现实时数据同步、资源动态调度与快速故障恢复。即使主域出现故障,系统也能在次域快速恢复服务,实现跨可用域的资源冗余与自动容灾切换,从而提升 Kubernetes 平台的容灾能力与业务连续性。
多租户增强,提升团队协作效率
新版本引入项目级与 Namespace 级资源配额管理(CPU、内存、存储、GPU),可在 UI 界面直观设定并实时统计资源使用情况。当使用量接近配额阈值时,系统将自动发出告警,避免资源竞争与系统风险。
可观测与审计能力增强,构建全维度可控平台
SKS 1.5 持续完善集群可观测性能力,新增审计功能,支持对用户、应用、Kubernetes API 及控制面活动的完整回溯,提升运维的安全性和合规性。用户可以根据实际需求灵活配置审计策略:在资源受限或 PoC 等场景下,选择精简策略仅记录核心元数据,以最小化资源消耗。此外 SKS 1.5 也支持基础策略、详细策略以及自定义策略以适配多种生产环境。
9. KubeVela 1.10.4:提升使用 KubeVela 部署的应用程序的可维护性
KubeVela 简介
KubeVela 是一个开箱即用的、现代化的应用交付与管理平台。
KubeVela 通过以下设计,使得面向混合/多云环境的应用交付变得非常简单高效:
- 完全以应用为中心 - KubeVela 创新性的提出了开放应用模型(OAM)来作为应用交付的顶层抽象,并通过声明式的交付工作流来捕获面向混合环境的微服务应用交付的整个过程,甚至连多集群分发策略、流量调配和滚动更新等运维特征,也都声明在应用级别。用户无需关心任何基础设施细节,只需要专注于定义和部署应用即可。
- 可编程式交付工作流 - KubeVela 的交付模型是利用 CUE 来实现的。CUE 是一种诞生自 Google Borg 系统的数据配置语言,它可以将应用交付的所有步骤、所需资源、关联的运维动作以可编程的方式粘合成一个 DAG(有向无环图)来作为最终的声明式交付计划。相比于其他系统的复杂性和不可扩展性,KubeVela 基于 CUE 的实现不仅使用简单、扩展性极强,也更符合现代 GitOps 应用交付的趋势与要求。
- 基础设施无关 - KubeVela 是一个完全与运行时基础设施无关的应用交付与管理控制平面。所以它可以按照你定义的工作流与策略,面向任何环境交付和管理任何应用组件,比如:容器、云函数、数据库,甚至 网络和虚拟机实例等等。
主要更新
- 支持 Kubernetes 1.31
- 资源存在性验证
- 健康领域的原生线索
- 增强状态报告
- 应用程序状态指标
- 依赖关系感知工作流
- 彩色日志记录支持
10. K0s 1.34:延续将 k0s 打造为生产就绪、精简且一致的 Kubernetes 发行版的努力
K0s 简介
k0s 是一个开源的、功能齐全的 Kubernetes 发行版,它配置了构建 Kubernetes 集群所需的所有功能,并打包成一个单独的二进制文件,方便用户使用。由于其设计简洁、部署选项灵活且系统要求不高,k0s 非常适合:
- 任何云
- 裸金属
- 边缘计算和物联网
重点更新
- Windows 节点改进。虽然 Windows 支持尚未达到生产就绪状态,但在此版本中它仍在不断完善,改进了节点生命周期、进程管理和集群一致性。
- IPv6 单栈。K0s 1.34 为现代或资源受限的部署引入了仅支持 IPv6 的集群(alpha 版本)。
- 特性门控。引入了 k0s 特性门控 ,允许在不修改代码的情况下选择性地启用实验性功能。这简化了在正式发布前对新功能进行受控测试和验证的过程。目前,仅针对 IPv6 单栈引入了特性门控。
- 核心组件更新
- 命令行界面和配置改进
11. Podman Desktop 1.23 版本发布
新功能和改进:
- 专用网络页面:可在独立页面管理网络,完全无需使用终端命令。
- 可自定义的列和仪表盘模块:仅显示你关心的内容,自由调整列和模块顺序。
- 增强搜索功能:更快找到容器、镜像和文档,无需在菜单中反复查找。
- Podman 机器新增 rootless/rootful 指示器:在“资源”区域直观显示机器的权限模式。
- 支持托管配置:IT 团队可统一部署预设配置,管理员可获得开箱即用的管理版 Podman Desktop。
- 为 Podman 机器创建 Docker context:增强与 Docker 工具的兼容性。
12. Kubernetes v1.35 抢先看
废弃和移除
cgroup v1 支持
Linux 节点上,容器运行时通常依赖 cgroup(控制组)。Kubernetes 自 v1.25 起已对 cgroup v2 提供稳定支持,作为对原始 cgroup v1 的替代。cgroup v1 曾是最初的资源控制机制,但存在已知不一致和限制。支持 cgroup v2 后,实现了统一的控制组层级,提升资源隔离,并为现代特性奠定基础,故旧版 cgroup v1 支持将被移除。
cgroup v1 支持移除只会影响运行在不支持 cgroup v2 的旧 Linux 发行版节点,相关节点上的 kubelet 将无法启动。管理员需将节点迁移到启用 cgroup v2 的系统。
kube-proxy 中 ipvs 模式的废弃
Kubernetes 很早以前在 kube-proxy 中实现了 ipvs 模式,因其负载均衡性能优于 iptables 模式而被采用。但由于技术复杂性和需求分歧,维护 ipvs 与其他模式的功能一致性变得困难,导致技术债务增加,且不利于支持新网络功能。
因此,Kubernetes 计划在 v1.35 中废弃 kube-proxy 的 ipvs 模式,简化代码库。对于 Linux 节点,推荐使用的 kube-proxy 模式已是 nftables。
Kubernetes 废弃 containerd v1.x 支持
虽然 v1.35 仍支持 containerd 1.7 及其他 LTS 版本,但因自动 cgroup 驱动检测机制,SIG Node 社区已正式确定 containerd v1.x 的最终支持时间表。v1.35 是最后支持该版本的 Kubernetes 版本(对应 containerd 1.7 EOL)。
这是最后警告:如果你还使用 containerd 1.x,必须在升级 Kubernetes 到下一个版本前切换到 2.0 或更高版本。可通过监控 kubelet_cri_losing_support 指标,检测集群中是否有节点使用即将不支持的 containerd 版本。
重点新特性
节点声明特性(alpha)
调度 Pod 时,Kubernetes 通过节点标签、污点和容忍匹配工作负载需求与节点能力。但升级时控制平面与节点版本不一致,导致节点特性兼容性难管,可能让 Pod 被调度到不支持所需特性的节点,导致运行失败。
节点声明特性框架为节点声明支持的 Kubernetes 功能提供标准机制。启用该 alpha 功能后,节点通过 .status.declaredFeatures 字段向控制平面报告支持的功能,调度器、准入控制器及第三方组件可基于此信息进行调度和 API 验证,确保 Pod 仅调度到兼容节点。
该机制减少手动标签管理,提升调度准确率,且可与 Cluster Autoscaler 集成,实现更智能的扩容决策。特性声明与 Kubernetes 功能开关绑定,方便安全推广和清理。
Pod 资源原地更新(GA)
Pod 资源原地更新功能毕业为 GA,允许用户调整 Pod 的 CPU 和内存资源,无需重启 Pod 或容器。之前这类调整需重建 Pod,影响有状态或批处理应用稳定性。
CRI 也有改进,Windows 及未来运行时支持 UpdateContainerResources API,ContainerStatus 可报告实时资源配置。整体提升 Kubernetes 的弹性扩缩容能力,减少中断。该功能自 v1.27 alpha 起步,v1.33 升级为 beta,v1.35 计划稳定。
Pod 证书支持(beta)
微服务间通常需要强身份认证,实现基于 mTLS 的安全通信。Kubernetes 提供的 Service Account Token 只适用于 API 认证,非通用工作负载身份。
之前需依赖 SPIFFE/SPIRE 或 cert-manager 等外部项目管理证书。KEP-4317 设计了原生 Pod 证书支持,允许 kubelet 通过投影卷自动请求并挂载短期唯一证书,简化服务网格和零信任网络策略的部署。
污点的数值比较支持
Kubernetes 扩展污点和容忍机制,新增数值比较操作符,如 Gt(大于)、Lt(小于)。
此前容忍只支持等于或存在匹配,不适合数值属性(如可靠性 SLA)。新支持后,Pod 可容忍满足特定数值阈值的节点,例如要求 SLA 污点值大于 950。
该机制比节点亲和性更强大,支持 NoExecute 效果,节点数值低于阈值时自动驱逐 Pod。
用户命名空间支持
Pod 内可用 securityContext 降权,但容器内进程通常仍以 root(UID 0)运行,且此 UID 映射到宿主机 root。此设计存在容器逃逸风险。
KEP-127 引入 Linux 用户命名空间支持,动态将容器 root 映射为宿主机上的非特权高 UID。容器内仍拥有 root 权限,但宿主机上是普通用户,极大提升安全性。
支持将 OCI 镜像挂载为卷
Pod 配置时常需携带数据、二进制或配置文件。以前多将数据打包进镜像,或用 init 容器下载解压到 emptyDir。
Kubernetes v1.31 增加 image 卷类型支持,允许 Pod 直接从 OCI 镜像仓库拉取并解包数据卷,解耦数据与镜像,简化流程。该卷类型自 v1.33 进入 beta,v1.35 可能默认启用。
拓展阅读
Kubernetes 支持原生 Gang Scheduling : 适应 AI/ML 工作负载
13. runc v1.4.0 -- "路漫漫其修远兮,吾将上下而求索!"
runc v1.4.0 -- "路漫漫其修远兮,吾将上下而求索!"
runc 简介
runc 是一个符合 OCI (Open Container Initiative) 运行时规范的低级容器运行时,它负责创建和运行容器。它的核心功能是根据 OCI 规范来设置容器的隔离环境(例如 cgroups、namespaces、seccomp 等)并执行容器进程。
新的发布和支持政策:
- runc 1.2.z 分支现在只接收高严重性 CVE 修复,并将于 2026 年 4 月底停止支持。
- runc 1.3.z 分支现在只接收安全和“重要”的错误修复。
- 鼓励用户尽快迁移到 runc 1.4.0。
- 预计 runc 1.5.0 将在 2026 年 4 月下旬发布。
弃用
- 弃用 cgroup v1。
- 弃用 libcontainer/utils 中的 CleanPath、StripRoot、WithProcfd 和 WithProcfdFile 函数。
重大变更
- pids.limit 的处理方式已更新,以符合 OCI 运行时规范。现在,最大限制值 0 将被视为实际限制(由于 systemd 的限制,它将被视为与 1 相同)。此变更预计只会影响明确将 pids.limit 设置为 0 的用户。
📰 专题二 新闻与访谈
1. CNCF 宣布 Crossplane 毕业
Cloud Native Computing Foundation Announces Graduation of Crossplane
Crossplane 是什么
Crossplane 是一个云原生控制平面框架,无需编写代码即可构建控制平面。Crossplane 拥有高度可扩展的后端,无论应用程序和基础设施运行在何处,都能对其进行编排;同时,它还拥有高度可配置的前端,允许您定义其提供的声明式 API。
关键信息
- Crossplane 已正式从 CNCF 项目生态系统中毕业,这证明了其成熟度、广泛应用和强大的社区,以及其在平台工程中的重要性。
- Crossplane 拥有来自 450 多个组织的 3000 多名贡献者,在贡献者参与度和作者贡献方面,在所有 CNCF 项目中排名前 10%。
- Crossplane 已发布了 100 多个版本,包括最近的 Crossplane v2.0,该版本引入了更完善的架构,用于构建完整的应用程序控制平面,并增强了对 AI 驱动操作的支持。
- Crossplane 现在已是一个成熟的 CNCF 项目,目前已可用于生产制造。
2. 2025 Kubernetes 指导委员会的选举结果
Announcing the 2025 Steering Committee Election Results
Kubernetes 指导委员会由 7 个席位组成,其中 4 个席位在 2025 年进行选举。新任委员会成员任期为 2 年,所有成员均由 Kubernetes 社区选举产生。
- Kat Cosgrove (Minimus)
- Paco Xu (DaoCloud)
- Rita Zhang (Microsoft)
- Maciej Szulik (Defense Unicorns)
已有成员:
- Antonio Ojea (Google)
- Benjamin Elder (Google)
- Sascha Grunert (Red Hat)
3. KServe 成为 CNCF 孵化项目
KServe becomes a CNCF incubating project
KServe 是什么
KServe 是一个标准化的分布式生成式和预测式 AI 推理平台,支持在 Kubernetes 上进行可扩展的多框架部署。它被设计成一个统一的平台,用于在 Kubernetes 上进行生成式和预测式 AI 推理。KServe 既足够简单,可以快速部署,又足够强大,能够处理企业级 AI 工作负载,并提供高级功能。
关键里程碑和生态系统增长
KServe 最初于 2019 年由 Google、IBM、Bloomberg、NVIDIA 和 Seldon 在 Kubeflow 项目下合作开发。2022 年 2 月,该项目被捐赠给 LF AI & Data 基金会 。同年 9 月,KServe 项目从 KFServing 更名为独立项目 KServe,并从 Kubeflow 中分离出来。随后,KServe 于 2025 年 9 月入驻 CNCF,成为其孵化器项目。
云原生领域的集成
KServe 可与众多 CNCF 项目无缝对接,包括:
- Kubernetes:KServe 从根本上来说是一个用于在 Kubernetes 上进行可扩展的多框架部署的平台。它使用 Kubernetes 自定义资源定义 (CRD) 简化了机器学习模型的部署。
- Envoy:KServe v0.15 引入了对 Envoy AI Gateway 的初始支持,这是一个基于 Envoy 构建的 CNCF 开源项目。
- Kubeflow:KServe 于 2019 年由 Google、IBM、Bloomberg、NVIDIA 和 Seldon 合作,在 Kubeflow 项目下诞生。尽管它于 2022 年 9 月从 Kubeflow 分离出来,成为独立的 KServe 项目,但它仍然与 Kubeflow 生态系统保持联系。
- vLLM:KServe v0.15 中对 vLLM 后端进行了重大增强,以更好地服务于生成式 AI 模型。
- llm-d:KServe 通过新的 LLMInferenceService CRD 提供与 llm-d 的集成,以支持分离式服务、前缀缓存、智能调度、变体自动扩缩容等功能。
- LMCache:KServe 集成了用于分布式键值 (KV) 缓存的 LMCache 库。
- Kubernetes Gateway API:KServe 支持 Kubernetes Gateway API,以及与 Envoy Gateway 的集成。
- Knative:KServe 通过其 Knative 集成支持无服务器部署,可根据请求量提供自动扩展,并支持缩减至零和从零开始缩减,以及金丝雀发布。
- Istio:KServe 与 Istio 集成,以便能够利用服务网格功能。
- 广泛的服务运行时:KServe 是一个多框架平台,为流行的预测 AI 框架提供支持,包括 TensorFlow、PyTorch、scikit-learn、XGBoost、ONNX 等。
拓展阅读
KServe Joins CNCF To Standardize AI Model Serving on Kubernetes
4. CNCF 宣布 Knative 毕业
Cloud Native Computing Foundation Announces Knative’s Graduation
Knative 是什么
Knative 是一个基于 Kubernetes 的平台,它提供了一整套用于构建、部署和管理现代无服务器工作负载的中间件组件。Knative 扩展了 Kubernetes 的功能,提供了更高层次的抽象,从而简化了云原生应用程序的开发和运维。
Knative 于 2018 年由 Google 创建,并于 2022 年作为孵化项目加入 CNCF。其项目路线图包括桥接传统系统、扩展 AI 和云原生集成,并计划采用 Gateway API 和 OpenTelemetry 等新技术。
拓展阅读
Knative Has Finally Graduated From the CNCF
5. Ingress NGINX 退役通知:你需要了解的内容
关键信息
为了保障生态系统的安全,Kubernetes SIG Network 和安全响应委员会宣布即将退役 Ingress NGINX。项目将持续提供有限维护,直到 2026 年 3 月。之后将不再发布新版本、修复漏洞或更新安全问题。现有的 Ingress NGINX 部署仍可正常使用,安装资源也会继续保留。
我们建议尽快迁移到其他替代方案。推荐迁移至 Gateway API,这是 Ingress 的现代替代方案。如果必须继续使用 Ingress,Kubernetes 文档中列出了许多其他 Ingress 控制器。以下内容介绍了 Ingress NGINX 的历史、现状及后续步骤。
Ingress 与 Ingress NGINX
Ingress 是 Kubernetes 中最早且用户友好的网络流量管理方式。(Gateway API 是实现同类目标的较新方案。)要让 Ingress 在集群中工作,必须运行一个 Ingress 控制器。市面上有多种 Ingress 控制器,满足不同用户和场景需求,有些针对特定云厂商,有些则通用。
Ingress NGINX 是 Kubernetes 项目早期开发的 Ingress 控制器示例。凭借极大的灵活性、丰富的功能以及独立于特定云和基础设施的特点,它迅速流行起来。此后,社区和云原生厂商开发了许多其他 Ingress 控制器,但 Ingress NGINX 始终是最受欢迎的之一,广泛部署于各大托管 Kubernetes 平台和众多用户集群。
退役原因
Ingress NGINX 的功能广泛且灵活,导致维护难度大。随着云原生软件的不断发展,曾被视为有用的选项,如通过“snippets”注解添加任意 NGINX 配置,现被视为严重安全隐患。昔日的灵活性,如今成了难以克服的技术负担。
尽管用户众多,Ingress NGINX 一直面临维护力量不足的问题。多年间,仅有一两位维护者利用业余时间(下班后和周末)进行开发。去年,维护团队宣布计划逐步停用 Ingress NGINX,并与 Gateway API 社区合作开发替代控制器 InGate。不幸的是,该公告未能吸引更多人参与维护或开发工作,InGate 项目未能成熟,未来也将被退役。
拓展阅读
What Ingress Controller are you using TODAY?
We get ~4 months to move off of Ingress NGINX ?
Ingress NGINX Retirement: What You Need to Know
My number one issue with Gateway API
RESULTS of What Ingress Controller are you using TODAY?
120 Days Until Ingress NGINX Dies: Traefik is the Only True Drop-in Replacement
kgateway 帮助你选择 Ingress NGINX 替代方案
Tutorial: Implement a Nginx Gateway Fabric as an Alternative to Ingress
CNCF Retires the Ingress Nginx Controller for Kubernetes
Migration from ingress-nginx to nginx-ingress good/bad/ugly
Ingress NGINX Retired: Get An Architectural Upgrade with VMware Avi for Kubernetes
6. CNCF 推出认证 Kubernetes AI 一致性计划,旨在规范 Kubernetes 上的 AI 工作负载
CNCF Launches Certified Kubernetes AI Conformance Program to Standardize AI Workloads on Kubernetes
- CNCF 和 Kubernetes 开源社区正在启动 Kubernetes AI 一致性认证计划,以创建开放的、社区定义的标准,用于在 Kubernetes 上运行 AI 工作负载。
- 随着企业越来越多地将人工智能工作负载部署到生产环境,他们需要一致且可互操作的基础架构。这项举措有助于减少碎片化,并确保跨环境的可靠性。
- Kubernetes 和整个云原生生态系统中的平台供应商、基础设施团队、企业 AI 从业者和开源贡献者需要一个共同的基础,以寻求可互操作且可用于生产的 AI 部署。
7. CNCF 推出 CNPE 认证,定义云原生平台工程新标准
背景
随着企业在提升软件交付效率的同时不断强化安全性和稳定性需求,平台工程已成为现代云战略的基石。获得 CNPE 认证能够证明您具备设计与运营企业级平台所需的先进专业知识。此类平台能够在确保可靠性与稳定性的前提下,为整个企业持续创新提供支撑。CNPE 认证也证明您有能力成为引领企业大规模软件构建与交付方式的可信赖工程技术领导者。
CNPE 是什么
CNPE 是开源云原生平台工程专家 CNPE(Certified Cloud Native Platform Engineer)的简称。该认证面向希望从平台构建进一步迈向平台架构设计的 IT 专业人士。
CNPE 的价值
CNPE 认证能够证明您具备设计、保障和优化企业级复杂云原生平台所需的先进且市场需求旺盛的技能。
通过 CNPE 认证,您将被认可为能够胜任以下核心平台工程职责的专业人才:
- 构建并运营可扩展的内部开发者平台(IDP),以支持企业级高影响力生产工作负载;
- 为云原生平台进行架构设计、安全防护与性能优化,实现高性能、高可靠性与高效率;
- 打造高效的开发者体验,加速应用交付节奏,同时确保全平台的安全与高标准运营规范。
适用人群
CNPE 认证候选人通常正在担任,或期望未来从事以下岗位的专业人士:
- 首席平台工程师或平台架构师:负责设计与运营企业级内部开发者平台(IDP);
- 高级 DevOps、SRE 或云工程负责人:承担平台战略、安全体系、自动化和开发者体验建设;
- 工程团队负责人或技术经理:推动组织内软件交付流程标准化,确保平台可在组织规模下稳定可靠扩展。
考试情况
CNPE 是 120 分钟,基于实操的考试,每位考生报名参加考试后,将在 12 个月内拥有两次考试机会。
CNPE 认证考试包括以下这些核心领域及其在考试中的权重:
- 平台架构与基础设施:15%
- GitOps 与持续交付 :25%
- 平台 API 与自助服务能力: 25%
- 可观测性与运维: 20%
- 安全与策略执行: 15%
8. Google Kubernetes Engine (GKE) 构建了已知最大的 Kubernetes 集群,有 13 万个节点
How Google Does It: Building the largest known Kubernetes cluster, with 130,000 nodes
GKE 目前已支持 65,000 个节点的大型集群 ,在 KubeCon 大会上,GKE 分享了我们已成功在实验模式下运行了一个 130,000 个节点的集群 ——是官方支持和测试上限的两倍。
关键架构创新:
- 优化的读扩展性:通过“缓存一致性读 (Consistent Reads from Cache)”和“API 服务器可快照缓存 (Snapshottable API Server Cache)”特性,大幅减少了 API 服务器对中央对象数据存储的读取请求负载,确保了大规模下的响应速度。
- 优化的分布式存储后端:基于 Google Spanner 的专有键值存储,在 13 万节点规模下,仍能高效处理 13,000 QPS 的租约对象更新,未出现瓶颈。
- Kueue 高级作业排队:作为作业排队控制器,Kueue 为 Kubernetes 带来了批处理系统能力,能基于公平共享策略、优先级和资源配额进行“全有或全无”的作业调度,尤其适用于复杂的 AI/ML 混合工作负载管理。
- 调度未来展望:Kubernetes 社区正致力于将工作负载感知调度和原生“组调度 (Gang Scheduling)”语义引入核心,进一步优化大规模、紧密耦合应用的编排。
GCS FUSE 数据访问: 通过 Cloud Storage FUSE、Anywhere Cache 和 Managed Lustre 等技术,为 AI 工作负载提供高效、低延迟的数据访问,如同本地文件系统一般。
🎤 四个月前 Amazon EKS 刚宣布支持 10 万个节点。
9. GKE 现已成为 CNCF 认证的 Kubernetes AI 合规平台
Kubernetes AI 一致性计划的主要目标是简化 Kubernetes 上的 AI/ML,保证 AI 工作负载的互操作性和可移植性,并在标准基础上构建不断增长的 AI 工具生态系统。
像 GKE 这样符合 Kubernetes AI 标准的平台可以为您处理底层复杂性,提供一套经过验证的功能,以可靠高效地运行 AI/ML 工作负载。以下是 GKE 为您管理的一些关键需求:
- 动态资源分配 (DRA):实现对加速器更灵活、细粒度的资源请求。
- 智能加速器自动扩缩:
- 集群自动扩缩 (Cluster Autoscaling):在基础设施层面,根据需求自动增删带有加速器的节点。
- 水平 Pod 自动扩缩 (HPA):在工作负载层面,可根据 GPU/TPU 利用率等自定义指标自动扩缩 Pod 数量。
- 丰富的加速器性能指标:提供详细的性能数据,用于深入洞察和有效的监控与自动扩缩。
- 强大的 AI 算子支持:确保 Kubeflow 或 Ray 等复杂 AI 算子能够可靠地安装和运行。
- 分布式工作负载的“全有或全无”调度:支持 Kueue 等方案,确保分布式 AI 作业仅在所有所需资源可用时才启动,避免死锁和资源浪费。
💬 专题三 讨论与分享
1. Prometheus 与 OpenTelemetry 集成所需的修复
Fixes Required for Prometheus’ OpenTelemetry Integration
背景
OpenTelemetry 与 Prometheus 兼容性之间因多种原因存在一些冲突。
从最基本的层面上说,设计理念存在差异。OpenTelemetry 更可描述为基于推送的指标系统,当生产内容、运行时和监控网络发生变化时,会发布指标数据,一种“推”的逻辑。相比之下,Prometheus 不断将指标数据汇入时间序列图表 —— 正是 Grafana 以其吸引人的面板而闻名的类型。一种“拉”的逻辑。
拓展阅读:Prometheus and OpenTelemetry Just Couldn’t Get Along
在 Prometheus 上使用 OpenTelemetry 仍存在的问题
- 丢失核心优势:服务发现与主动拉取(Pull)模型。Prometheus 的强大之处在于它能通过服务发现自动找到监控目标,并主动拉取数据。这个过程会生成一个 up 指标,用于判断目标是否健康,这是告警的关键。使用 OpenTelemetry 的推送(Push)模型后,这个机制就丢失了。你很难区分一个服务是宕机了,还是仅仅没有发送数据。
- 性能问题。在一个 Go 语言的基准测试中,使用 OpenTelemetry SDK 的性能比 Prometheus 原生客户端库慢了最多 22 倍。对于需要频繁运行的观测性代码来说,这是一个巨大的性能开销。
- SDK 的复杂性。OpenTelemetry 的 SDK 非常复杂,Volz 将其比作遥测领域的 “XML” 或 “CORBA”,因为它试图一次性解决所有问题,导致自身变得臃肿和难以优化。
- 语义约定冲突。
未来可能的计划
- 为了解决健康检查问题,未来的工作可能会涉及合成的 OTLP 摄入量指标。Volz 表示,该功能将利用服务发现,并将预期数据与输入数据关联起来,在数据缺失时生成上行指标。
- 未来与 OpenTelemetry 团队合作时,引入类似的标准化命名结构。
2. 非开发者如何为 Prometheus 做出贡献
How Non-Developers Can Contribute to Prometheus
背景
对于非开发者,在开源领域工作,容易担心自己力不从心。工作在一个高度以开发者为中心的领域,却没有开发背景。
但这种焦虑最终证明是多余的。如果你也有同样的不确定感,这篇文章就是为你准备的。作者会分享你可能面临(或已经面临)的挑战,为什么你的贡献很重要,以及如何在 Prometheus 社区中找到自己的位置。
非技术贡献者面临的挑战
- 技术贡献者远多于非技术贡献者。即使是非技术人员,通常也有技术背景,或者在这行业工作时间足够长,能理解发生了什么。当每次对话都涉及你不懂的概念时,很容易感到害怕。
- 开源项目很少像招聘广告那样详细说明非技术需求。你几乎找不到标题为“需要:有人面试用户并撰写案例研究”或“招聘社区经理组织每月聚会”。相反,你更可能看到的是 GitHub 上积压的漏洞、功能请求和代码重构的问题。即使你拥有宝贵的技能,你也不知道它们在哪里需要,如何表达你的价值,或者你的贡献是否会被视为关键任务还是只是加分。
- 缺乏可见的非技术贡献者。很难找到非技术贡献者,因为他们的贡献往往不像项目展示工作那样隐形。GitHub 贡献图统计提交次数。更新日志列出代码变更和修复错误。只有当你创建了被合并的拉取请求时,才会显示“贡献者”标签。所以,即使有人组织活动、支持用户或进行研究,他们的工作也不会像代码那样以显眼的方式呈现。
- 典型的“贡献指南”会带你如何搭建开发环境、创建分支、运行测试以及提交拉取请求。但它很少解释如何贡献文档改进、设计反馈应该放在哪里,或者社区支持如何组织。从加入到首次贡献之间存在显著差距。数百人分布在数十个频道中。谁是维护者,谁只是社区成员?哪个频道适合回答你的问题?需要指导时,你应该找谁?
这些 Gap 为什么存在
大多数情况下,这些差距并非有意为之。项目不会刻意排斥非技术贡献者,也不会让他们更难参与。
在大多数情况下,一小群开发者会开发一些有用的东西,并决定将其开源。他们邀请认识可能需要的人(通常是其他开发者)来贡献。项目在这些网络中自然发展。它成为一个开发者社区,为开发者开发工具,某些功能目前还没被要求。
- 营销?这个消息自然会在技术圈里传播开来。
- 社区管理?社区规模小且自组织。
- 用户体验设计?他们是熟悉命令行界面的开发者,所以可能不会完全考虑使用图形界面的体验。
这个项目是在一个不需要这些技能的背景下发展出来的。
转变发生在某人,通常是非技术贡献者,看到潜力后介入说:“你建立了有价值的东西,发展了一个令人印象深刻的社区。但你可能忽略了什么。文档如何降低进入门槛。社区管理如何留住贡献者。用户调研如何指导你的路线图。”
非技术贡献为何重要
- 需要易于理解的文档。根据我与工程师合作的经验,大多数人更愿意专注于构建而不是写文档,这也可以理解。对系统了如指掌的工程师,往往写出假设新手没有的文档。对开发者来说完全合理的内容,对第一次接触的人来说可能难以理解。从终端用户的角度(而非构建者)角度测试产品的技术写作者,可以弥合这一差距,降低进入门槛。
- 需要组织。GitHub 的问题待办列表中有数百个未被分流的未完成项目。维护者花费宝贵时间分析用户实际需求,而不是构建解决方案。项目经理或有分析经验的人可以将混乱转化为清晰的路线图,让维护者专注于构建解决方案。
- 需要社区的支持。想象一下,有个用户加入了 Slack 工作区,兴奋地想贡献。他们不知道从哪里开始。他们提出的问题被信息流淹没。他们默默离开了。项目刚刚失去了一个潜在贡献者,因为没有人欢迎他们并指引他们走向正确方向。
这些情况正是非技术贡献可以帮助预防的。良好的文档降低了进入门槛,这意味着更多的采用率、更多的反馈和更好的功能。积极的社区管理保留了那些本可能流失的贡献者,这意味着分布式知识和维护者的倦怠减少。组织和分流将零散的输入转化为可作的优先事项。
你可以做出贡献的实用方法
- 加入用户体验工作
- 撰写博客
- 改进和维护文档
- 协助组织会议
- 倡导与宣传
3. 符合规范的 Kubernetes 更新可用性在不同服务之间差异显著
Conformant Kubernetes Update Availability Varies Significantly Across Services
背景
企业通常希望尽快集成最新的 Kubernetes 功能或安全升级。然而,ReveCom 的分析显示,云原生计算基金会 (CNCF) 发布 Kubernetes 更新与企业通过本地云基础设施提供商或超大规模云服务商的 Kubernetes 平台全面部署这些更新之间存在 2 到 7 个月的滞后。这意味着企业可能需要等待关键的安全补丁、性能增强功能,以及一些重要的全新功能。ReveCom 将这种发布节奏上的差异称为“滞后差距”。不同平台提供商和超大规模云服务商之间的滞后差距大小差异显著。
“符合规范的 Kubernetes”(Conformant Kubernetes)
“符合规范的 Kubernetes”状态是指 Kubernetes 发行版已通过官方一致性测试 ,确保其符合 Kubernetes 核心 API 规范,并与上游 Kubernetes 的行为保持一致。CNCF 负责管理认证,使用户对不同 Kubernetes 发行版的互操作性、可移植性和可靠性充满信心。供应商必须通过这些测试才能获得“认证 Kubernetes”标识。
最近三个主要 CNCF Kubernetes 版本(1.33、1.32 和 1.31)的支持滞后情况
在分析最近三个主要 CNCF Kubernetes 版本(1.33、1.32 和 1.31)的支持滞后情况时,可以发现两个截然不同的群体。
第一群体是领跑者,由超大规模云服务提供商组成:Google Kubernetes Engine (GKE)、Azure Kubernetes Service (AKS) 和 Amazon Elastic Kubernetes Service (EKS)。它们展现了令人印象深刻的敏捷性,通常能在 41 到 87 天的短时间内将新版本全面推送给客户。
作为主要挑战者之一的 VMware Cloud Foundation (VCF) 将其 vSphere Kubernetes Service (VKS) 的发布周期与这一超大规模云服务基准保持一致,平均为 57 天。与之形成鲜明对比的是,Red Hat OpenShift (RHOS) 则明显落后,平均支持延迟长达 192 天。
适配的工作
服务提供商必须跟踪上游变更并集成自身的组件:etcd、容器运行时 (CRI)、CoreDNS、kube-proxy、控制平面标志以及底层内核和节点镜像。 网络和存储堆栈(CNI 实现和 CSI 驱动程序)以及云控制器、负载均衡器、GPU/驱动工具包和操作系统镜像都必须重建和验证。
安全修复通常通过反向移植更快地实现,但仍然需要符合 FIPS 标准的构建、符合 CIS 标准的默认设置、已签名的镜像和 SBOM,以及在所有受支持版本中进行 CVE 分类。所有这些都必须能够大规模运行,支持多租户控制平面、各种实例类型和极其庞大的 Pod 数量,并实现零停机升级、安全回滚和版本偏差保证。版本发布后,会经过一致性测试和金丝雀发布,然后才会全球可用,之后还会更新 CLI、文档、计费和支持材料。
简而言之,在托管平台上部署“符合最新 CNCF 标准的 Kubernetes”需要大量的工程和运维工作。这正是企业付费的原因所在:它提供了额外的可靠性、安全性和兼容性保障。
就 OpenShift 而言,这种巨大的差距归根结底源于其架构理念。OpenShift 不仅仅是一个 Kubernetes 发行版;它是一个高度定制化的一体化平台即服务 (PaaS)。虽然这种高度集成提供了一致的用户体验,但也带来了巨大的工程开销。每个新的上游 Kubernetes 版本都必须针对整个专有的 OpenShift 技术栈进行严格的测试、修改和验证——从其服务网格和监控工具到其独特的操作系统。
4. 一位资深可观测性专家谈人工智能的“迷人”潜力
An Observability Veteran on AI’s ‘Intoxicating’ Potential
可观测性的迭代本质
如果能够根据系统发出的数据(遥测数据)推断其运行状态,则该系统是可观测的。遥测数据有很多种类型,称为信号。最常用的是日志、指标和跟踪数据。
遥测数据并非凭空产生。我们的系统必须在正常运行过程中生成遥测数据。运行我们应用程序的运行时环境可以配置为开箱即用地生成大量遥测数据,容器编排、操作系统等等也是如此。我们还可以向应用程序添加专用逻辑(称为检测),以创建额外的遥测数据。我将其视为我们预先提供的应用程序逻辑,用于调试其他应用程序逻辑。
我们的应用程序生成的遥测数据并非总是完美无缺,需要进行处理:我们需要过滤遥测数据(包括垃圾邮件),因为其中很多数据实际上并无太大用处。我们需要为遥测数据添加上下文信息 ,因为生成遥测数据的应用程序可能无法获取足够的信息来正确提供所有必要的元数据。此外,如果根据不同的用例或信号使用不同的可观测性后端,我们还需要确保将正确的遥测数据转发到正确的后端。
遥测数据到达可观测性后端后,我们必须通过查找系统故障迹象来检测异常情况。一旦检测到异常 ,我们就必须对系统进行故障排除。
遥测数据处理中的人工智能
遥测数据生成后,必须对其进行处理并路由以进行分析。人工智能可以在遥测数据处理方面提供帮助,具体体现在以下几个方面:
- (垃圾邮件)过滤遥测数据:并非所有遥测数据都具有同等价值。特别是,自动检测生成的遥测数据并非始终有用,往往只有在解释其他地方检测到的异常情况时才变得不可或缺。
- 信息删减:几乎没有哪个系统从未通过日志或遥测元数据发送过敏感数据。人工智能应该能够检测到许多此类情况并采取相应措施,尽管我尚未在实践中看到这种情况。
- 改进遥测:添加缺失的上下文,填补元数据空白(例如修复日志中缺失的严重性),并将重要信息提取为可以单独排队的属性(例如,通过自动检测日志模式)。
- 聚合遥测:指标并非万能灵药,它们只是以相对较少的数据点来表示系统重要方面的一种经济有效的方式,但在这个过程中会丢失大量信息。
人类和人工智能在处理遥测数据方面存在一个本质区别:人工智能需要更高的一致性。作为人类,我们能够记住自己弄错了元数据,并且用三种不同的方式调用同一个东西。如果我们在同一个故障排除过程中同时遇到 team.id 和 team.identifier,我们就知道肯定有问题了。
人工智能会直接接受信息,因为它缺乏直觉,而且在很大程度上缺乏积累经验的能力。此外,人工智能通常不会提出澄清问题,尽管这种情况可能会改变。正因如此,语义约定对人工智能代理至关重要:它们通常缺乏开发者在一次次失望中积累起来的、对人类易犯错误的理性认知。
人工智能在故障排除中的应用
故障排除是人工智能真正开启下一阶段可观测性的关键所在。借助检索增强生成(RAG)和先进的确定性诊断工具,现代模型可以在几分钟内调试出一些令最有才华的技术专家困惑半小时的问题。
GenAI 可以生成查询、仪表盘或警报,从而减轻系统故障期间人工操作员的认知负担。这可以使故障排除更加普及:它大大降低了门槛,使所有开发人员都能更有效地解决问题。当问题无需占用其他工作时间即可解决时,经验丰富的开发人员就能腾出更多时间。
关于人工智能时代可观测性设计的思考
- 人工智能像人类一样进行故障排除,但规模更大 。大型语言模型由于基于人类内容训练,能够模拟我们的工作方式,而且处理能力远超人类。这意味着,如果人类拥有更完善的故障排除基础工具,人工智能的故障排除能力也会更强。(在当前的人工智能领域,这些基础工具通常是 MCP 服务器中的工具。)反之亦然:如果人工智能在我们的可观测性工具中缺少某些高级功能,人类也可能同样缺乏这些功能。
- 人工智能是强大的用户群体。 复杂系统的故障排除几乎总是由少数知识渊博的人员负责,这使得他们需求量很大(压力也很大)。人工智能有潜力解释、赋能和教育人们,从而进一步传播先进知识。
- 人工智能可以减轻认知负荷。 它无需使用充斥着图表和数字的仪表盘,就能呈现简洁明了的分析结果,理想情况下还能使用通俗易懂的语言,并可根据需要提供支持性证据。
可观测性工具也必须针对人工智能这一用户群体进行设计:
- 人工智能的可访问性。越来越多的可观测性工具引入了内置人工智能代理,有些构建于模型上下文协议 (MCP) 服务器之上,有些则使用外部无法访问的专有 API。
- 人工智能驱动的故障排除必须基于确定性。大型语言模型并非如此。即使输入相同,它们也会生成不同的输出,这会导致各种错误结果。然而,可观测性具有一定的结构,能够帮助人类应对复杂系统产生的海量遥测数据:我们拥有信号、语义约定、文档以及分析数据的能力,这些都能够有效地大规模部署。我们为人工智能提供的工具越先进、越确定(例如通过 MCP 服务器),发生错误的可能性就越小。
5. 企业客户现在可以在 VMware Cloud Foundation 上部署 NVIDIA Run:ai
Enterprise customers can now deploy NVIDIA Run:ai on VMware Cloud Foundation
Run:ai 是什么
Run:ai 通过在整个 AI 生命周期中进行动态编排来加速 AI 操作,最大限度地提高 GPU 效率,扩展工作负载,并无缝集成到混合 AI 基础架构中,无需任何人工干预。与今年初被 NVIDIA 收购。
NVIDIA Run:ai on VCF
在 VCF 上部署 NVIDIA Run:ai 最有效且集成的方式是使用 VKS,它提供企业级、经云原生计算基金会 (CNCF) 认证的 Kubernetes 集群,这些集群完全托管且自动化。NVIDIA Run:ai 随后部署到这些 VKS 集群上,从而创建一个从硬件到 AI 应用的统一、安全且高弹性的平台。
价值不仅在于运行 Kubernetes 本身,更在于将其运行在一个能够解决企业基础挑战的平台之上:
- 通过 VCF 降低 TCO:减少基础设施孤岛,利用现有工具和技能,无需重新培训和改变流程,并提供跨基础设施组件的统一生命周期管理。
- 一致的运营:基于熟悉的工具、技能和工作流程,实现集群和 GPU 操作员的自动化配置、升级和大规模生命周期管理。
- 大规模运行和管理 Kubernetes:使用内置的、经 CNCF 认证的 Kubernetes 运行时和全自动生命周期管理,大规模部署和管理 Kubernetes 集群。
- 24 个月支持:对 vSphere Kubernetes (VKr) 的每个次要版本提供支持,可减轻升级压力,稳定环境,并使团队能够专注于交付价值,而不是不断地计划升级。
- 通过设计实现更好的隐私、安全和合规性:借助内置的隐私、治理、合规性以及在集群级别部署具有灵活安全态势的隔离 Kubernetes 环境的能力,自信地运行敏感和受监管的 AI/ML 工作负载。
- 使用 VCF 进行容器网络部署:裸机 Kubernetes 网络通常结构扁平、配置复杂且需要大量人工干预。在大型集中式 Kubernetes 集群中,为具有不同需求的应用程序提供可靠的连接是一项挑战。VCF 网络部署通过使用 Antrea 来实现容器网络部署,Antrea 是一个基于 CNCF 沙箱项目 Antrea 的企业级容器网络接口 (CNI)。启用 VKS 后,Antrea 将作为默认 CNI 部署,提供集群内网络、Kubernetes 网络策略执行、集中式策略管理以及来自 NSX 管理平面的跟踪流操作。虽然 Antrea 是默认的 CNI 选项,但用户也可以选择 Calico 作为替代方案。
- vDefend 高级安全功能:共享集群中的不同应用程序通常需要不同的安全态势和访问控制,而大规模地始终如一地执行这些控制非常困难。适用于 VCF 的 VMware vDefend 附加组件通过启用 Antrea 集群网络策略和东西向微隔离(细化到容器级别)来扩展高级安全功能。这使得 IT 人员能够使用软件定义的零信任策略,以编程方式隔离 AI 工作负载、数据管道和租户命名空间。这些功能对于合规性至关重要,并且能够防止在发生安全漏洞时进行横向移动,而这种粒度级别的安全控制在物理交换机上实现起来极其复杂。
- 借助 VMware vSphere 实现卓越的弹性和自动化:这不仅仅是便利,更是基础架构稳健性的关键所在。运行关键的多日培训作业的裸机服务器发生故障,可能会造成大量时间损失。VCF 由 vSphere HA 提供支持,可自动在另一台主机上重启这些工作负载。
- 除了高可用性 (HA) 之外,vMotion 还允许在不中断 AI 工作负载的情况下进行无中断硬件维护,而动态资源调度器 (DRS ) 则可动态平衡资源以防止出现热点。这种自动化恢复能力在静态的裸机环境中是根本不存在的。
- vSAN AI 工作负载具有灵活且策略驱动的存储需求,从用于训练的高 IOPS 暂存空间到用于数据集的弹性对象存储,不一而足。vSAN 允许您使用存储策略,针对每个工作负载定义这些需求(例如,性能、容错性)。这避免了创建更多基础架构孤岛和管理多个分散的存储阵列,而这在裸机部署中很常见。
- NVIDIA Run:ai 优势:
- 最大化 GPU 利用率在此坚实的基础上,NVIDIA Run:ai 支持跨团队的动态 GPU 分配、GPU 部分共享和工作负载优先级排序,从而确保强大而可靠的基础架构也能以最有效的方式得到利用。
- 可扩展的 AI 服务 :它支持部署大型语言模型(推理)和其他复杂的 AI 服务(分布式训练、微调),并能够随着用户需求的波动在资源上高效扩展。
架构图
NVIDIA Run:ai 控制平面的部署有两种安装选项:
- SaaS:在此架构中,NVIDIA Run:ai 控制平面托管在云端(参见 https://run-ai-docs.nvidia.com/saas )。本地运行的 NVIDIA Run:ai 集群与托管的控制平面建立出站连接,以运行 AI 工作负载。此配置需要从集群到 Run:ai SaaS 控制平面建立出站网络连接。
- 自托管:NVIDIA Run:ai 的控制平面安装在本地(参见 https://run-ai-docs.nvidia.com/self-hosted ),位于 VKS 集群上,该集群可以与计算工作负载共享,也可以专用于 NVIDIA Run:ai 控制平面。此选项还提供断开连接的安装方式。
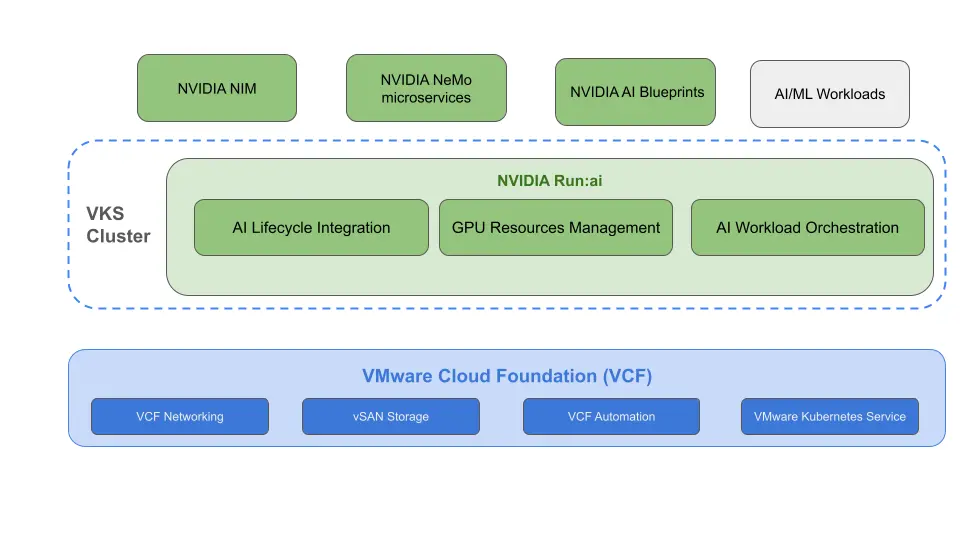
部署场景
- 在已启用 vSphere Kubernetes Service 的 VCF 实例上安装 NVIDIA Run:ai
- 将 vSphere Kubernetes 服务与现有 NVIDIA Run:ai 部署集成
拓展阅读
Kubecon: VCluster’s K8s Platform to Manage GPUs as a Service
6. 凿刻容器实践指南:更小、更快、更安全
Practitioners’ Guide to Chiseled Containers: Smaller, Faster, Safer
背景
容器化彻底改变了团队构建和部署应用程序的方式,但也带来了新的运维挑战。传统的容器镜像通常包含远超必要的组件 —— 例如 shell 工具、包管理器和运行中的应用程序永远不会使用的库。这种臃肿会增加镜像大小、降低部署速度并扩大攻击面。
为了满足现代性能和安全需求,业界应考虑转向更精简、更确定性的镜像。而精简容器 —— 仅包含运行应用程序所必需的组件,不包含其他任何内容的镜像 —— 正是实现这一目标的新途径。
什么是凿刻容器
凿刻容器是通过从基础镜像中移除大部分非必要组件而构建的——不包含 shell、包管理器,也不包含应用程序严格要求之外的任何运行时依赖项。这一概念已在 Ubuntu 生态系统中得到应用,该系统通过自动化流程“剔除”不必要的层,同时保持相同的运行时行为和稳定性。同样的原理也适用于其他 Linux 发行版和框架。
例如,Canonical 的基准测试表明,与标准 Ubuntu 基础镜像相比,.NET 应用程序的镜像大小最多可减少 90%, Java 工作负载的镜像大小最多可减少 50%。更小的镜像意味着更快的部署速度、更少的 CVE 漏洞以及更容易的合规性。
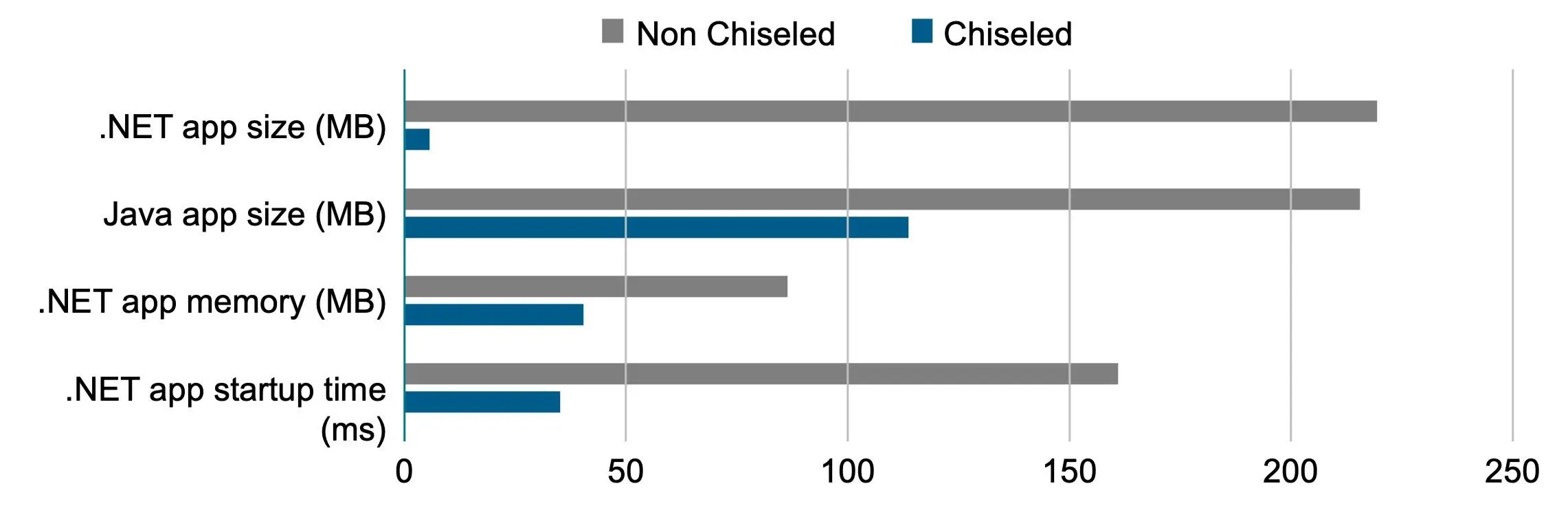
为什么企业要采用凿刻容器
- 安全性和合规性:通过移除 shell、编译器和软件包工具,精简容器显著降低了常见 CVE 漏洞的风险。据 Ubuntu 称,与传统镜像相比,这种方法可将容器的攻击面减少高达 80%,从而大幅降低漏洞风险。这简化了补丁工作流程,并帮助团队根据其监管要求(例如安全技术实施指南 (STIG) 和联邦信息处理标准 (FIPS))保持合规性。
- 性能和效率:更小的镜像文件可以直接转化为更快的拉取速度、更短的启动时间和更低的带宽及存储成本。这些对于大规模微服务或边缘工作负载尤为重要。
- 操作简便:Chiseled 容器从设计上就具有确定性和不可变性。由于无需 shell 或包管理器,运行时修改是不可能的,这确保了跨环境构建的一致性,并消除了经典的“在我机器上运行正常”的问题。
- 可持续性:更精简的镜像消耗更少的计算和网络资源,从而降低成本和环境足迹。
极简镜像的推荐使用场景
- 受监管的工作负载:医疗保健、金融和公共部门的工作负载受益于安全、可预测、可审计的运行时环境。
- 电子商务和突发容量:Chiseled 容器使电子商务和其他突发性应用程序能够在流量高峰期间快速扩展,通过更快的启动速度和更低的开销来降低成本和能源消耗。
- 边缘和物联网部署:最小镜像可在有限的连接上快速部署,并在资源受限的设备上高效运行。
7. Headlamp 2025 年项目亮点
Headlamp in 2025: Project Highlights
新进展
- 加入 Kubernetes SIG-UI
- AKS 桌面预览
- Linux 基金会导师计划
新功能与改进
- 支持多集群视图
- 支持项目功能
- 优化导航
- 优化搜索
- 增强 OIDC
- 支持原生 Helm 仓库
- 提升性能、优化使用体验
插件与可扩展性
- 支持 AI 助手
- 新增与更新相关插件
- 插件开发优化
8. 绘制 Kubernetes 架构图的素材与工具汇总
Awesome Kubernetes Architecture Diagrams
里面汇总了在画图中需要的多种素材与内容:
- Kubernetes 图标集 (KIS)
- 绘图工具
- 图表即代码
- 生成工具
9. 什么是 Kube-Proxy?为什么要从 iptables 迁移到 eBPF?
What is Kube-Proxy and why move from iptables to eBPF?
背景
不妨将 kube-proxy 比作指挥家,iptables 则如同交响乐团,统领着 Kubernetes 网络这首复杂的交响乐。然而,随着交响乐团的壮大和乐曲的日益复杂,iptables 开始出现响应上的偏差。本篇博客将深入剖析 kube-proxy 和 iptables 在 Kubernetes 网络中的角色,并探讨 Linux 内核社区为何将 eBPF 视为更现代化的选择。摆脱 iptables 的技术债务。
kube-proxy 是什么,它如何使用 iptables
Kube-proxy 是 Kubernetes 中的网络组件,安装在集群中的每个节点上,负责促进 Service 和 Pod 之间的通信。它的主要作用是维护 Service 到 Pod 映射的网络规则,从而实现与 Kubernetes 集群之间的通信。Kube-proxy 充当 L3/L4 网络代理和负载均衡器,利用 iptables 或 IPVS(IP 虚拟服务器),其中 iptables 是默认选项。
Kube-proxy 安装在每个节点上,确保网络流量从 Service 流向相应的 Pod。当创建新服务或端点时,它会抽象化底层 Pod 的 IP 地址,允许其他 Service 使用该服务的虚拟 IP 地址与其通信。
顾名思义,kube-proxy 充当网络代理。它管理路由流量所需的网络规则,包括在必要时进行网络地址转换 (NAT),以确保数据包到达其预期目的地。对于具有多个 Pod 以实现高可用性或可扩展性的 Service,kube-proxy 充当负载均衡器。它将传入流量分配到各个 Pod,以确保工作负载均衡和资源高效利用。
iptables 是二十多年前在 Linux 内核中开发的一个数据包过滤和防火墙工具。它能够根据用户定义的规则(基于 IP 地址或端口规则(TCP/UDP))分析、修改和过滤网络数据包。可以将 iptables 看作是一组用于过滤或修改数据包的内核模块。这些模块会将回调函数附加到 netfilter 钩子上,以执行一系列规则。在早期性能要求不高的时候,iptables 凭借其数百(甚至数千)条检查和重定向数据包的规则,尽职尽责地作为默认的网络安全和流量管理工具。
iptables 规则组织成 iptables 表和 iptables 链 。iptables 链是规则的有序列表,当数据包经过该链时,规则会按顺序执行。iptables 表用于将规则链分组,iptables 共有五个表,分别涵盖过滤 (Filter)、网络地址转换 (NAT)、数据包修饰 (Mangle)、原始数据 (Raw) 和安全 (Security) 功能。
在规模较小的部署中,iptables 可以很好地管理服务和 Pod 之间的通信。然而,随着集群规模和复杂性的增加,kube-proxy 基于 iptables 的方法在延迟和性能方面的局限性就显现出来,其顺序操作的时间复杂度为 O(n)。这种架构设计显著增加了 kube-proxy 管理哪怕只有一百个服务的小型集群所需的开销——这已经暗示了我们为什么可能需要用 eBPF 之类的工具来替换 iptables。iptables 的性能依赖于顺序算法,它会逐条遍历规则表中的规则,将规则与观察到的流量进行匹配。这意味着执行时间会随着新增规则的数量线性增长,随着服务和端点的增加,性能瓶颈会迅速显现。数据包必须遍历每条规则才能找到匹配项,这会引入延迟并导致稳定性问题。
iptables 最初设计用于基本的防火墙功能,并非为了应对 Kubernetes 规模下复杂的网络环境。随着网络需求从 2000 年代初期发展到如今的 Kubernetes 时代,iptables 的性能问题变得越来越难以忽视。Kubernetes 资源的短暂性意味着新的 IP 地址会在几秒钟内被创建、丢弃和回收。多年来,社区一直在努力改进 iptables,并开发了 ipset 等工具。以及最近的 IPVS 但 IPVS 只是暂时掩盖了 iptables 的问题,而不是提供真正的万灵药。
为什么 eBPF 是 Kubernetes 网络的标准
是一种用途广泛且高效的技术,在 Linux 网络中迅速普及。它允许在 Linux 内核中直接进行可编程处理,从而能够以极高的速度和灵活性完成各种网络、可观测性和安全相关的任务。
eBPF 则使用高效的哈希表,几乎可以实现无限扩展。如下图所示,延迟越低,性能越好。深入分析性能基准测试随着微服务数量的增长,iptables 的延迟问题日益突出,而 eBPF 接近 O(log n) 的时间复杂度优势也得以展现,表明其有能力取代 kube-proxy 和 iptables。
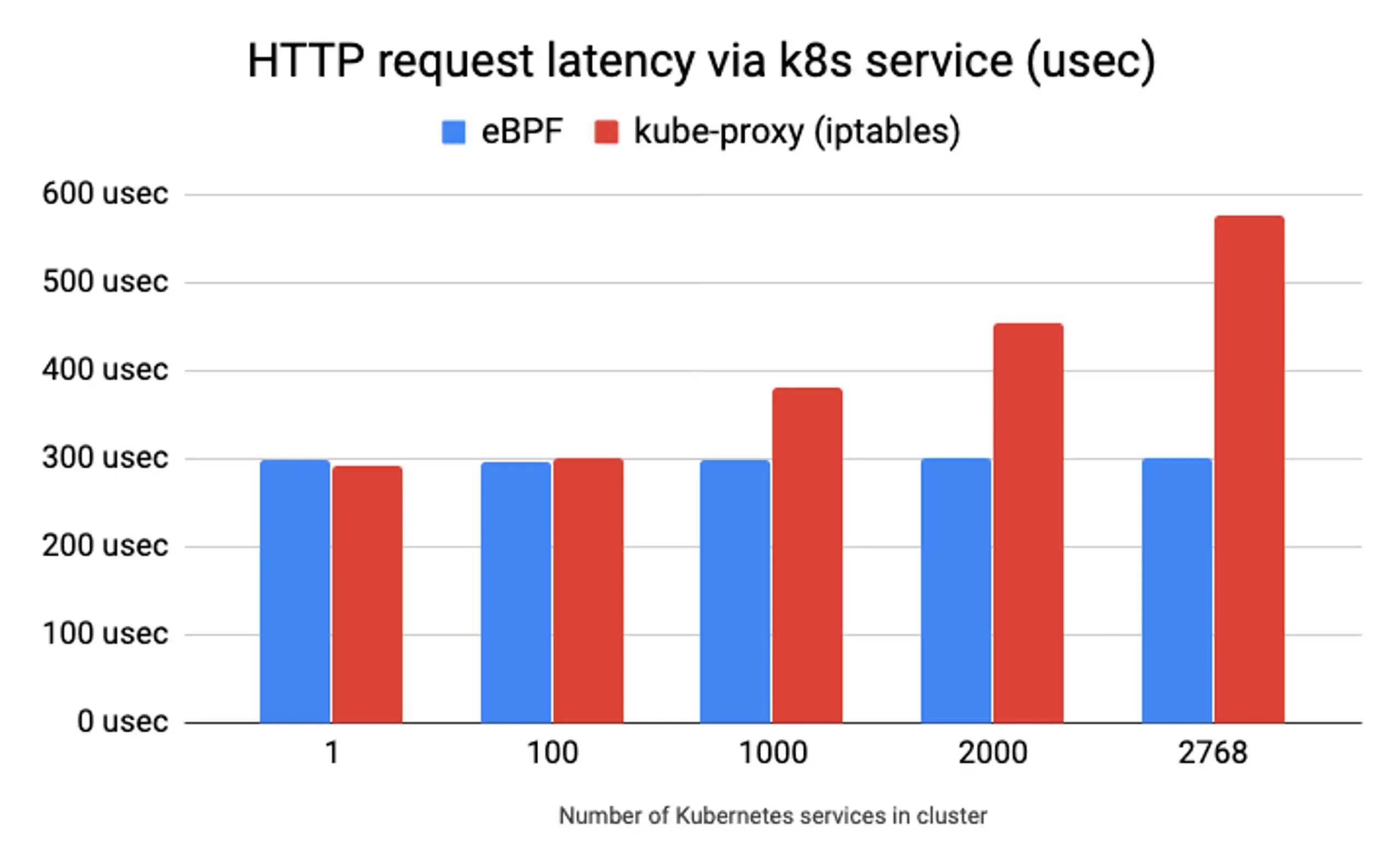
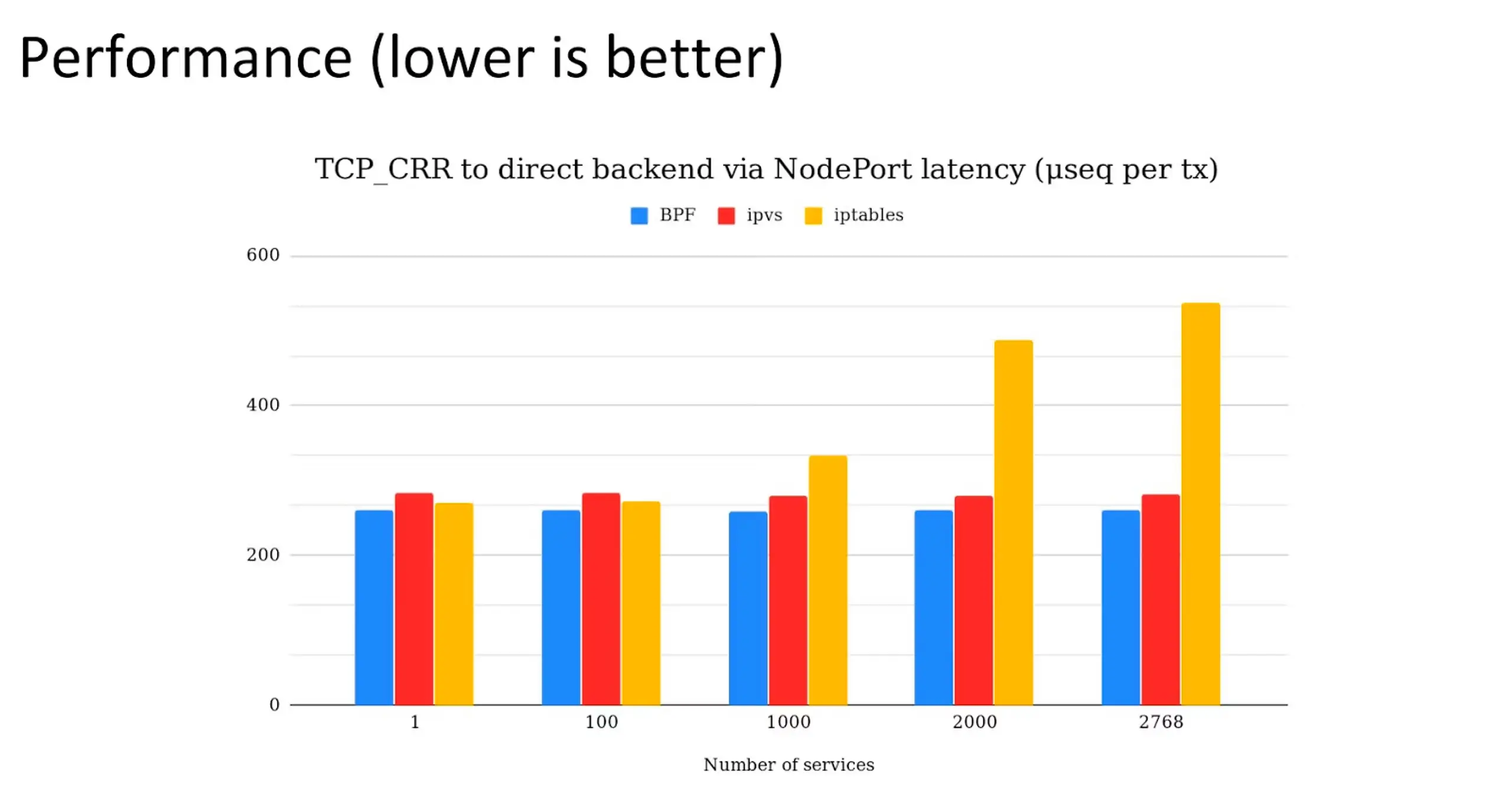
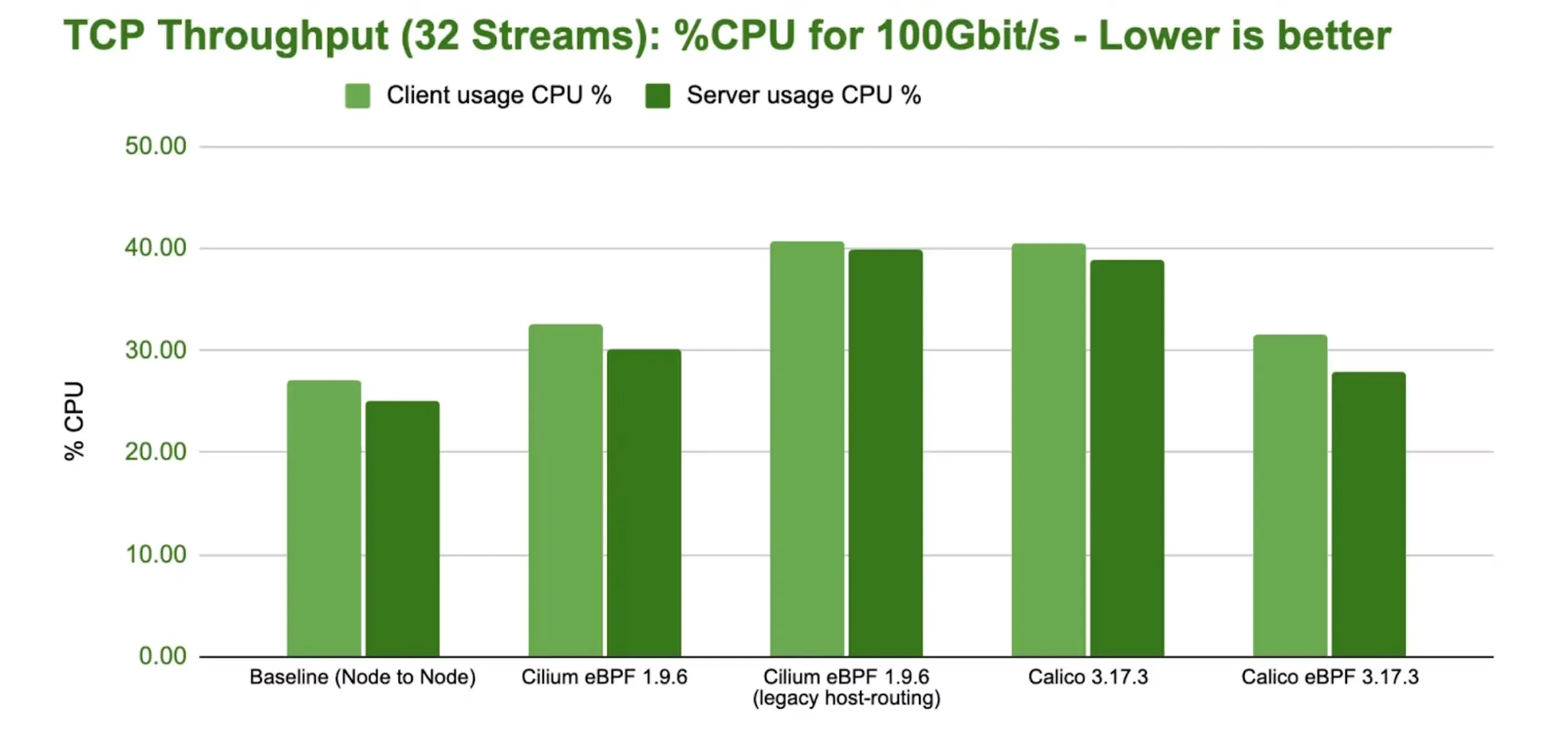
如何替换 iptables 并将 eBPF 引入 Kubernetes
目前,将 eBPF 引入 Kubernetes(并进而替换 kube-proxy)的行业标准是通过 Cilium。 Cilium 完全替代了 kube-proxy , 而且功能远不止于此。目前,Cilium 是 CNCF 上唯一正式毕业的 CNI。包括 Azure 、 AWS 和 Google Cloud 在内的主要云服务提供商已弃用 kube-proxy,转而使用 Cilium 作为其推荐的 CNI。
Cilium 数据平面为 kube-proxy 提供了一个全面的替代方案, 使从 iptables 过渡到 eBPF 程序变得轻松便捷。在右侧,Cilium 会在每个 Kubernetes 节点上安装 eBPF 和 XDP(快速数据路径)程序,从而绕过 iptables 的开销。这种方法最大限度地减少了开销和上下文切换需求,实现了高效的数据包处理,最终降低了延迟和 CPU 开销。
10. Kubernetes 配置最佳实践
Kubernetes Configuration Good Practices
本博客汇集了经过实践检验的 Kubernetes 配置最佳实践。这些小习惯能让你的 Kubernetes 配置更简洁、更一致、更易于管理。无论你是新手还是日常部署应用的老手,这些小技巧都能确保集群稳定运行,让你的后续工作更加轻松。
通用配置实践
- 使用最新的稳定版 API,可以使用 kubectl api-resources 进行检查
- 将配置信息存储在版本控制系统中
- 请使用 YAML 格式而非 JSON 格式编写配置
- 保持配置简单简洁
- 将相关对象分组在一起
- 添加有用的注释
工作负载管理
- 对那些应该始终运行的应用程序使用 Deployment
- 使用 Job 来执行应该完成的任务
服务配置与网络
- 在依赖 Service 的工作负载(如 Deployment)之前创建 Service
- 使用 DNS 进行服务发现
- 除非绝对必要,否则请避免使用 hostPort 和 hostNetwork
- 使用无头服务进行内部发现
有效使用标签
- 使用语义标签
- 使用通用的 Kubernetes 标签
- 操作标签以进行调试
kubectl 使用技巧
- 应用整个目录
- 使用标签选择器获取或删除资源
- 快速创建部署和服务
📄 专题四 报告查看与分析
1. [Forrester] Modernize Or Fall Behind: Rethinking IT Infrastructure For A Competitive Edge(Broadcom 委托定制研究)
Modernize Or Fall Behind: Rethinking IT Infrastructure For A Competitive Edge
🎤 推广虚拟机和容器统一管理的文章。
未来 12 个月排名前列的 IT 项目
IT 领导者正大力推进网络安全建设,54% 的受访者强调,他们将努力确保基础设施在日益增长的网络威胁面前保持安全和弹性。近半数 (46%) 的受访者还计划在未来一年内对其 IT 基础设施进行现代化改造。超过三分之一 (37%) 的受访者致力于简化 IT 基础设施管理,以提高效率并降低运营复杂性,从而释放资源用于创新。对精简管理的重视凸显了以统一且经济高效的方式集成和管理各种基础设施平台(例如虚拟机和容器管理解决方案)的迫切需求。

部署的独立虚拟机和容器管理解决方案实例数量
三分之二的企业拥有 11 个或更多虚拟机和容器管理解决方案实例。IT 基础设施必须能够无缝扩展,以应对业务增长、季节性高峰或用户行为的突然变化。
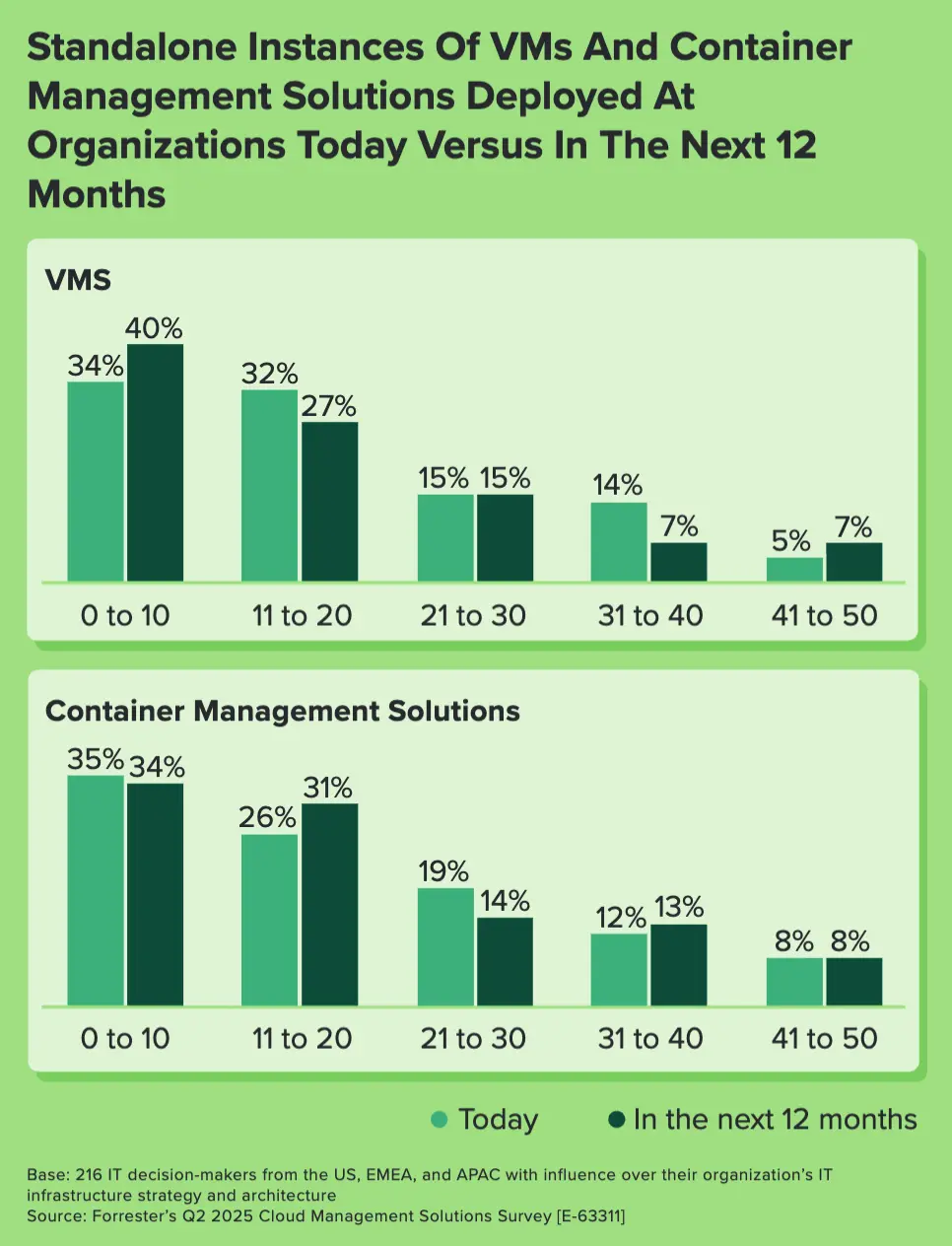
组织在管理 IT 基础设施方面面临的挑战
由于虚拟机和容器管理解决方案满足的需求各不相同,但又相互关联,因此企业在管理它们时面临着诸多挑战。例如,受访者指出,两者都面临的最大挑战是运维复杂性高以及与现有系统集成困难。值得注意的是,34% 的受访者认为数据和系统孤立是有效管理虚拟机的一大难题,而 32% 的受访者则表示缺乏管理支持容器管理解决方案的不同服务器平台所需的技能。这进一步凸显了采用统一且精简的 IT 基础设施方法的必要性。

关于基础设施的陈述
尽管对统一化的需求很高,但许多 IT 领导者在管理日益增长的虚拟机和容器平台方面仍面临挑战。84% 的受访者表示,他们难以监管用于管理这些解决方案的不同工具和平台。造成这种困境的原因是虚拟机和容器管理解决方案在组织内部的快速普及。
日益增长的复杂性促使决策者寻求更高效的方式来简化其 IT 运维。我们的研究表明,85% 的 IT 决策者希望拥有一个能够同时管理虚拟机和容器解决方案的统一平台。此外,83% 的 IT 领导者希望该平台能够与现有系统无缝集成,并支持新技术的应用。

统一平台的价值
展望未来,超过 80% 的受访者期望这一单一平台能够带来多项变革性益处,例如提高可扩展性 (87%)、简化不同 IT 基础设施的管理 (82%) 以及为传统和云原生应用程序提供灵活的 IT 基础设施 (81%)。
大多数受访者认为该平台不仅能加速 DevOps 流程(86%),还能提高应用团队的敏捷性(84%)。它提供针对特定应用的优势,从而增强组织敏捷应对不断变化的业务需求的能力。

统一平台的收益
受访者认为,这不仅可以降低运营成本(52%)和提高投资回报率(49%),还可以提高组织满足业务需求的敏捷性(46%),并加强安全和合规工作(44%)。
尽管经济形势不明朗导致预算限制仍然是一个关键问题,但我们的研究发现,其他挑战往往先于预算限制出现,例如缺乏管理单一平台所需的技能以及对改变现有 IT 基础设施的抵触情绪。克服这些挑战对于企业充分发挥单一统一平台的潜力至关重要。
2. Gateway API 基准测试
Gateway API Benchmarks - Part 2
作者做了两次基准测试对一系列产品进行对比:
- 第一次:Cilium, Envoy Gateway, Istio, Kgateway, Kong, Traefik, Nginx
- 第二次:Agentgateway、Envoy Gateway、Istio、Nginx
从报告呈现出来的结果看,Istio 和 Agentgateway 分别表现较好。
具体可以阅读原文。
3. [G2] 最佳基础设施即服务 (IaaS) 提供商
Best Infrastructure as a Service (IaaS) Providers
G2 是什么
G2 是一个点对点软件评论市场,企业可以在这里发现、评论和比较软件和服务。
基础设施即服务(IaaS)简介
定义
基础设施即服务 (IaaS) 是一种云计算模式,它将 IT 基础设施外包。IaaS 提供商购买并管理昂贵的物理计算资源,同时提供各种云服务作为回报。企业实际上是租用提供商的处理能力,用于虚拟化服务器、存储数据和处理网络流量。
IaaS(基础设施即服务)使企业无需购买、构建或托管即可创建和使用虚拟硬件工具。这些工具以虚拟化服务器、数据库或带宽以及其他工具的形式外部提供。
🎤 尽管在下面提供了分类,这篇文章的定义还是较为偏向于公有云。
分类
- 公有云:在选择基础设施即服务 (IaaS) 提供商时,公有云是最具成本效益的途径,因为它可以帮助企业减少硬件和维护方面的前期投入。公有云的技术优势包括可扩展性、可靠性和更丰富的功能集。公有云在初创企业和小企业中广受欢迎;然而,对于受数据安全法规(例如 HIPAA、PCI 等)监管的行业而言,公有云可能并非最佳选择。
- 私有云:私有云为传统 Web 应用程序提供更高的安全性和兼容性,并且比公有云更容易迁移。私有云可以部署在企业内部数据中心;然而,大多数使用私有云的中型企业和大型企业都选择使用第三方 IaaS 服务提供商。私有云在金融、医疗保健和商业等行业中非常受欢迎,因为这些行业对数据安全的要求高于其他行业。
- 混合云:混合云结合了上述两种方案的优势。对于希望在安全性和成本之间取得平衡的大型企业和其他公司而言,混合云是一种理想的选择。这种 IaaS 模式允许企业在公有云中处理 Web 应用程序的某些部分,同时在私有云中存储和处理机密数据。
IaaS 的共同特点
- 虚拟机 (VM):IaaS 软件提供虚拟化的网络、应用程序和操作系统。这些解决方案利用提供商的物理资源来提供模拟工具。虚拟机扩展了用户对操作系统和主机环境的访问权限,而无需昂贵的硬件。
- 存储管理:IaaS 软件提供数据存储、数据库配置和扩展的管理工具。这些解决方案使用户能够访问各种数据库和云存储应用程序,并可根据使用量的增长进行扩展。云存储对于防止数据丢失尤为重要。
- 网络:IaaS 软件使用户能够配置网络、分发内容、平衡负载和管理流量。网络功能允许用户选择数据连接方式和网络通信方式。
- 云迁移:IaaS 软件支持在部署和维护期间进行数据和虚拟机迁移。数字化转型促使许多企业从本地基础设施转向云端解决方案。云迁移工具简化并加速了系统迁移到云端的过程。
- 分析:IaaS 软件使用户能够分析存储、性能和连接情况。分析功能可以通过管理流量和资源分配来帮助用户优化性能。一些 IaaS 解决方案还具备大数据分析功能,可以帮助用户处理海量数据集。
- 维护:IaaS 软件支持对现有虚拟机进行维护,以提升功能和安全性。维护功能帮助用户集中控制其用户、终端以及他们访问的虚拟机。
- 数据库管理:IaaS 软件支持管理不同类型的数据库和集成方式。数据库支持使用户能够访问云数据库并进行同步,从而实现实时更新。
IaaS 面临的挑战
- 安全性和合规性:在评估过程中,买方需要考虑计划在 IaaS 解决方案中处理的数据。敏感数据,例如知识产权、医疗记录和支付信息,需要严格的安全控制。由于支付卡行业数据安全标准 (PCI DSS) 和健康保险流通与责任法案 (HIPAA) 等法规对机密数据的存储和传输方式作出了规定,受这些法规约束的企业必须确保其 IaaS 提供商能够满足这些标准。
- 现有基础设施:拥有现有云基础设施的企业需要考虑迁移到新云解决方案或与之集成所需的成本和工作量。虽然对于拥有现有基础设施的企业来说,迁移到私有云可能更容易,但公有云提供更广泛的功能集和更低的成本。此外,一些 IaaS 提供商围绕其解决方案提供完整的生态系统,这也会影响购买决策。
最佳基础设施即服务 (IaaS) 提供商概览
- 领导者:Google Compute Engine
- 最佳表现者:UltaHost
- 最易于使用:DigitalOcean
- 最热门:VMware Cloud Foundation
- 最佳免费软件:Amazon EC2
不同维度 Top 5
G2 分数
- Google Compute Engine
- Amazon EC2
- LogicWeb
- VMware Cloud Foundation
- DigitalOcean
受欢迎
- Amazon EC2
- Google Compute Engine
- LogicWeb
- VMware Cloud Foundation
- DigitalOcean
满意度
- Google Compute Engine
- DigitalOcean
- LogicWeb
- VMware Cloud Foundation
- Amazon EC2
💁♀️ 专题五 产品/方案介绍
1. kueue:Job 队列管理器
简介
Kueue 是一个云原生 Job 队列系统,适用于 Kubernetes 集群中的批处理、高性能计算、人工智能/机器学习及类似应用。
使用 Kueue 构建具有配额和层级结构的多租户批处理服务,以便在组织内的团队之间共享资源。Kueue 会根据可用配额决定 Job 何时等待以及何时何地运行。
Kueue 可与标准的 kube-scheduler、cluster-autoscaler 以及 Kubernetes 生态系统的其他组件协同工作。这种组合使 Kueue 既可在本地运行,也可在云端运行,从而支持异构、可互换且动态配置的资源。
功能简介
- Job 管理:支持基于优先级的 Job 排队,支持基于不同策略的作业队列优先级管理。
- StrictFIFO (严格的先入先出)
- BestEffortFIFO (尽力而为的先入先出)
- 高级资源管理:包括资源类型可互换性(resource flavor fungibility)、公平共享(Fair Sharing)、队列分组(cohorts)以及不同租户间的多种抢占(preemption)策略。
- 集成:内置支持常见的作业类型,例如 BatchJob、Kubeflow 训练作业、RayJob、RayCluster、JobSet、普通 Pod 和 Pod 组(Pod Groups)。
- 系统洞察:内置 Prometheus 指标,用于帮助监控系统状态;并提供按需可见性端点,用于监控处于待处理状态的工作负载。
- 准入检查:一种机制,允许内部或外部组件影响工作负载是否可以被准入。
- 高级自动扩缩支持:通过 AdmissionChecks 集成 cluster-autoscaler 的 provisioningRequest 功能。
- 带就绪 Pod 的全有或全无:基于超时机制实现的全有或全无调度(All-or-nothing scheduling)。
- 部分准入和动态回收:一种机制,允许作业根据可用配额以降低的并行度运行,并在 Pods 完成后释放配额。
- 混合训练和推理:同时管理批处理工作负载和 serving 工作负载(如 Deployments 或 StatefulSets)。
- 多集群作业分派:被称为 MultiKueue,允许搜索可用容量并将作业分载到主集群之外。
- 拓扑感知调度:允许通过感知数据中心拓扑结构进行调度,以优化 Pod 间通信的吞吐量。
拓展阅读
Red Hat OpenShift is joining the Kueue
2. Kubeflow SDK:用于大规模运行 AI 工作负载的 Python 化接口
介绍 Kubeflow SDK:用于大规模运行 AI 工作负载的 Python 化接口
背景
扩展 AI 工作负载不应依赖分布式系统和容器编排的深厚专业知识。无论是在本地硬件上原型设计,还是部署到生产 Kubernetes 集群,都需要一个统一的 API,既屏蔽基础设施复杂度,又保留灵活性。Kubeflow Python SDK 正是为此而生。
作为 AI 从业者,你可能遇到过这样的烦恼:起初在笔记本上本地训练模型,后来需要更多算力时,却得重写代码支持分布式训练。你要容器化代码,每次微小改动都要重建镜像,写 Kubernetes YAML,操作 kubectl,还要切换不同 SDK——一个训练用,一个调参用,还有一个管道用。每步都用不同工具和 API,思维负担很重。
这些复杂度拖慢了效率,分散了注意力,最终阻碍了 AI 创新。Kubeflow 社区成立了 Kubeflow SDK & ML Experience 工作组(WG),专门解决这些问题。
简介
SDK 位于 Kubeflow 生态之上,作为统一接口层。你用 Python 写代码,SDK 自动转成对应的 Kubernetes 资源——生成自定义资源(CR),处理编排,管理分布式通信。你无需了解 Kubernetes,就能享受 Kubeflow 和分布式 AI 计算的强大功能。
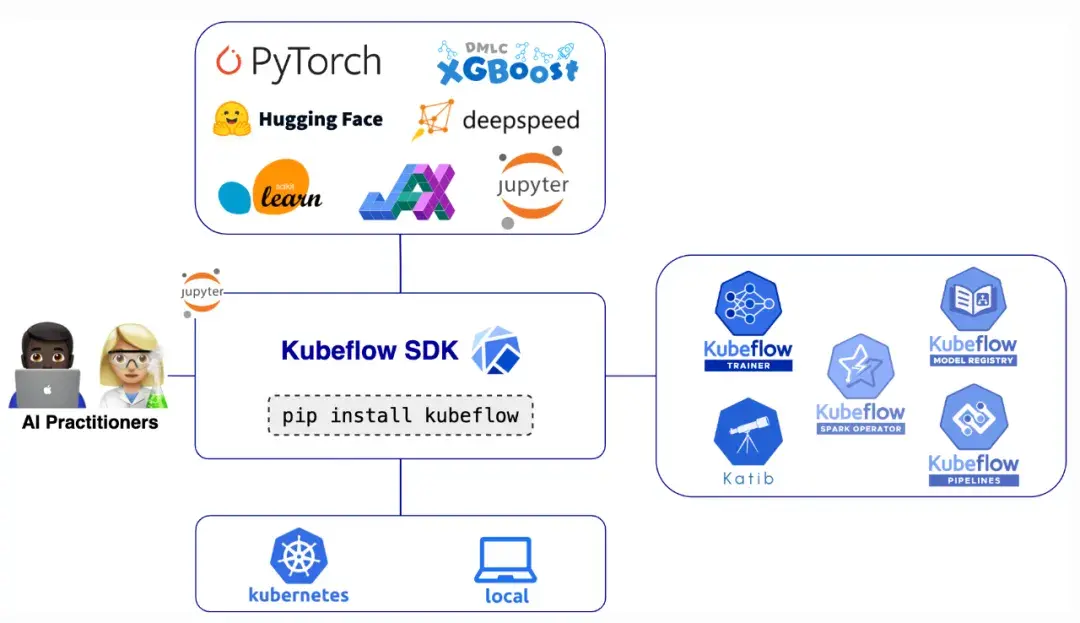
设计原则
- 统一体验:单一 SDK 通过一致的 Python API 访问多个 Kubeflow 项目
- 简化 AI 工作负载:屏蔽 Kubernetes 复杂度,使用熟悉的 Python API 跨项目无缝操作
- 面向规模:同一套 API 支持从本地笔记本到拥有数千 GPU 的大规模生产集群
- 快速迭代:开发与生产环境切换无缝,减少摩擦
- 本地开发优先:无需 Kubernetes 集群,只需 pip 安装即可本地开发支持
在 Kubeflow 生态中的角色
SDK 不替代任何 Kubeflow 组件——它提供统一的使用方式。Kubeflow Trainer、Katib、Spark Operator、Pipelines 等依然负责具体执行。SDK 通过统一的 Python API 简化它们的调用,让你用熟悉的语言全程操控。
这样分工明确:
- AI 从业者用 SDK 通过 Python 提交作业和管理流程,不用直接写 YAML 或操作 Kubernetes
- 平台管理员继续管理基础设施,安装组件、配置运行环境、设置资源配额,基础设施无变化
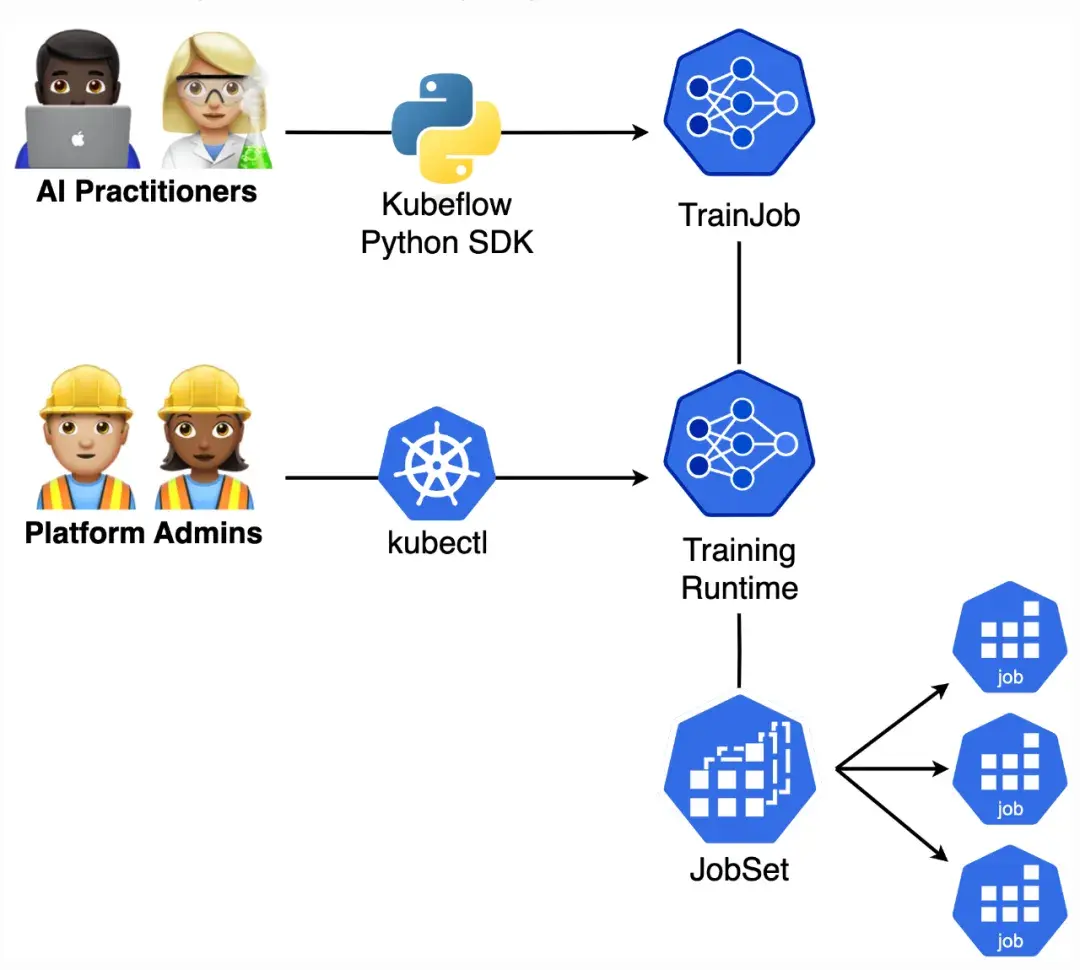
未来计划
- Pipelines 集成:推出 PipelinesClient,构建端到端 ML 工作流,复用 SDK 训练、调参和部署原语
- Model Registry 集成:统一管理模型资产和版本
- Spark Operator 集成:通过 SparkClient 实现数据处理和特征工程
- 完善文档:提供完整的 SDK 文档、示例和 API 参考
- 本地执行支持 Optimizer:本地运行调参实验,后续扩展至 Kubernetes
- 工作区快照:捕捉完整开发环境,复现实验和分布式训练
- 多集群支持:单一 SDK 管理多 Kubernetes 集群训练作业
- 分布式数据缓存:通过初始化器配置实现大规模数据集内存缓存
- 更多内置 Trainer:支持 TorchTune 之外的其他微调框架如 Unsloth、torchforge、Axolotl、LLaMA-Factory 等
3. K3k:Kubernetes 中的 Kubernetes
简介
K3k(Kubernetes in Kubernetes)是一款工具,可让您在现有的 Kubernetes 环境中创建和管理隔离的 K3s 集群。它支持高效的多租户、简化的实验流程和强大的资源隔离,并允许您在同一物理主机上运行多个轻量级 Kubernetes 集群,从而最大限度地降低基础设施成本。K3k 提供“共享”模式(优化资源利用率)和“虚拟”模式(通过专用的 K3s 服务器 Pod 提供完全隔离)。这使您可以获得完整的 Kubernetes 体验,而无需管理单独的物理资源。
特点与优势
- 资源隔离:确保工作负载隔离,防止团队或应用程序之间发生资源争用。K3k 允许您为每个嵌入式集群定义资源限制和配额,从而保证一个团队的工作负载不会影响其他团队的性能。
- 简化多租户:轻松为不同用户或项目创建专用的 Kubernetes 环境,简化访问控制和管理。为每个团队提供独立的集群,包括独立的命名空间、基于角色的访问控制 (RBAC) 和资源配额,无需管理多个物理集群的复杂性。
- 轻量级且快速:利用 K3s 的轻量级特性,快速启动和销毁集群,从而加速开发和测试周期。只需几秒即可启动一个新的 K3k 集群,在干净的环境中测试您的应用程序,并同样快速地销毁它,从而简化您的 CI/CD 流水线。
- 优化资源利用率(共享模式):通过在同一物理主机上运行多个 K3s 集群,最大限度地利用您的基础设施投资。K3s 的共享模式可让您高效地共享底层资源,从而降低开销并最大限度地降低成本。
- 完全隔离(虚拟模式):为了增强安全性和隔离性,K3k 的虚拟模式为每个嵌入式集群提供专用的 K3s 服务器 pod。这确保了工作负载的完全分离,并消除了任何潜在的资源争用或安全风险。
- Rancher 集成:使用 Rancher 简化 K3k 集群的管理。利用 Rancher 直观的用户界面和强大的功能,轻松监控、管理和扩展您的嵌入式集群。
🤔 专题六 有意思的事与 Meme
1. 一位用户误以为 Kubernetes 官方文档发生了巨大改动
Po 主认为旧版文档格式很好,但不理解为什么新文档为某些对象完全移除了 YAML 示例。
一位贡献者好心地联系了 Po 主并发送了链接: https://github.com/kubernetes/website/issues/47108#issuecomment-2217464050。之后 Po 主检查了浏览器,发现不知什么原因 cookie can_Google 被设置为 false。把它改成 true 后,一切就恢复正常了。
帖子中的内容如下:
我们已经接受了新的 PageFind 搜索可能不如它所取代的 Bing 搜索这一事实。然而,Bing 每月要花费 CNCF 数千美元,因此不再是一个合理的选择。在评估了几个替代方案后,PageFind 是我们能找到的最佳选择。
PageFind 的目标是为中国用户提供服务(因为谷歌在中国被屏蔽),而 Google Programmable Search 则服务于其他所有用户。我们使用 ipinfo.io 服务来检测用户的位置。由于该服务可能对中国用户屏蔽,因此如果出现错误,我们会假定该用户位于中国。遗憾的是,如果用户使用了会屏蔽 ipinfo.io 的广告拦截软件,那么他们也会被假定位于中国。
2. 从维护者的角度谈开源维护
A Note About Open Source Maintenance From The Perspective of a Maintainer
Po 主看到这样的观点:
我认为 Kubernetes 贡献者面临一个问题:每个人都想开发新功能,却没有人愿意参与维护工作。Kubernetes 生态系统的这种持续变动让我质疑它对中小企业的可行性。
但其实 Po 主投入了无数时间修补 CI、构建、测试和发布等各种漏洞,这种评论让他恼火。
所以 Po 主建议考虑投入一些时间或付费给那些已知会为你所使用项目做出贡献的发行版/服务/支持承包商。
开发者社区文档:https://www.kubernetes.dev/
入门指南:https://www.kubernetes.dev/docs/guide/
🎤 从 Developer Activity Counts by Companies 这个表可以看出,贡献 Top N 的开发者全是大公司的人。
3. Ingress-NGINX 的网关 API - Gateway API 维护者的视角
Gateway API for Ingress-NGINX - a Maintainer's Perspective
Gateway API 的稳定性是否不如 Ingress?
Gateway API 已正式发布(GA),至今已有两年多的时间。它提供了一个“标准通道”(默认通道),其稳定性与 Ingress API 不相上下,从未发生过任何重大变更,甚至没有 API 版本弃用。
迁移到不同的 Ingress 控制器而不是 Gateway API 是否会更容易?
如果未使用任何 ingress-nginx 注解,则可能会出现这种情况。不过,Ingress-NGINX 拥有许多功能强大且应用广泛的注解。如果选择迁移到其他 Ingress 控制器,鉴于核心 Ingress API 的功能有限,可能需要迁移到另一套特定于实现的注解。
Po 主等投入了大量时间,致力于在 Gateway API 中直接提供更多可移植的功能,并确保无论底层数据平面如何,所有实现都能提供一致的体验。
Gateway API 缺少所需要的 Ingress-NGINX 功能
虽然 Gateway API 支持的功能比核心 Ingress API 多得多,但 Ingress-NGINX 支持的注解列表已经非常丰富了。如果发现 Gateway API 缺少您需要的功能,请告知 Po 主等 —— 可以提交 issue、参加开源软件会议,或者直接在本帖下留言。
从 Ingress 迁移到 Gateway API 听起来工作量很大
ingress2gateway 目前正在进行大量工作,以改善迁移体验。Po 主等正在努力添加对最常用的 Ingress-NGINX 注解的支持,以帮助实现自动化迁移。
4. 以可视化动画的方式学习 Kubernetes Pod 和服务概念
Learn Kubernetes pod and service concept in visual animated way
Po 主用 Gemini 3 创建了这个示例。它展示了 Pod 创建工作流程、服务创建流程,以及 curl 请求流量的流向,并配有动画和步骤说明。