🆕 专题一 产品新功能/新版本
1. OpenShift Service Mesh 3.1
Introducing OpenShift Service Mesh 3.1
简介
Red Hat OpenShift Service Mesh 3.1 现已发布,并包含在 Red Hat OpenShift Container Platform 和 Red Hat OpenShift Platform Plus 中。此版本基于 Istio、Envoy 和 Kiali 项目,将 Istio 版本更新至 1.26 ,将 Kiali 版本更新至 2.11 ,并支持 OpenShift Container Platform 4.16 及更高版本。
重点更新
- Kubernetes Gateway API 支持(OCP 4.19+)
- 针对 x86 集群,正式支持 IPv4/IPv6 双栈
- 核心容器镜像(如 istiod 和 Envoy)将使用 UBI Micro base images
- Kiali 进行版本升级等更新
- 引入 Istio 的 Ambient Mode
2. Crossplane 2.0 发布
简介
Crossplane 是一个无需编写代码即可构建云原生控制平面的框架。它拥有高度可扩展的后端,让您能够构建一个无论在何处运行都能协调应用程序和基础设施的控制平面;它还拥有高度可配置的前端,让您能够控制其提供的声明式 API 的架构。
Crossplane 是云原生计算基金会的一个项目。
背景与目标
Crossplane 最初旨在让开发者能够自助访问云基础设施,但随着使用场景的扩展,发现基础设施和应用程序的管理仍然是分离的。Crossplane 2.0 旨在弥合这一差距。
Crossplane v1 的架构过于主观,Claim、集群范围资源和基础设施专用组合增加了复杂性。Crossplane 2.0 简化了这些概念。
新功能
- 应用程序支持 - Crossplane 2.0 超越了基础设施,可以管理应用程序和云资源
- 更广泛的组合功能 - 组合现在可以包含任何 Kubernetes 资源,而不仅仅是 Crossplane 定义的资源,从而实现全栈抽象
- 默认命名空间 - 复合资源 (XR) 和托管资源 (MR) 现在具有命名空间,从而提供更好的隔离并符合 Kubernetes 约定
- 声明式 Day 2 操作 - 新的操作类型支持一次性、计划和事件驱动的升级、备份和维护工作流
- 托管资源过滤 - 仅安装您需要的托管资源,而不是从提供商处获取所有内容
3. OpenSearch 3.2 发布
简介
OpenSearch 项目是一个由社区驱动、遵循 Apache 2.0 许可证的开源搜索和分析套件,可轻松提取、搜索、可视化和分析数据。开发者可以使用 OpenSearch 构建应用程序搜索、日志分析、数据可观测性、数据提取等用例。
主要功能
- 机器学习和人工智能
使用 AI/ML 工具创建尖端应用程序。 - 搜索
为您的应用程序构建更智能、更高效的搜索解决方案。 - 可观测性
识别并解决应用程序和基础设施中的问题。 - 安全分析
实时检测并应对安全威胁。
4. Kubernetes 1.34: Of Wind & Will (O' WaW) 发布
Kubernetes v1.34: Of Wind & Will (O' WaW)
简介
由我们周围的风和我们内心的意志所驱动的释放。
每个发布周期,我们都会承受一些我们无法掌控的风向 —— 工具、文档的状态,以及项目的历史遗留问题。有时,这些风会让我们充满动力,有时则会将我们推向侧面或减弱。
让 Kubernetes 持续前进的并非顺风顺水,而是我们水手们的意志:他们调整船帆、掌舵、规划航线,确保船只平稳航行。Kubernetes 的发布并非源于理想状态,而源于构建它的人、发布它的人,以及那些让 Kubernetes 保持强劲航行的熊 、猫、狗、巫师和好奇心 —— 无论风向如何。
此次发行的 《风与意志》(O' WaW) 向塑造我们的风和推动我们前进的意志致敬。

此版本包含 58 项增强功能。其中,23 项已升级至稳定版,22 项已进入 Beta 测试阶段,13 项已进入 Alpha 测试阶段。
主要更新
- 稳定:动态资源分配 (DRA) 的核心功能已正式发布,允许更强大地选择、分配、共享和配置 GPU、TPU、网卡等设备。
- Beta:kubelet 镜像凭证提供程序支持 Projected ServiceAccount 令牌,增强了私有容器镜像拉取的安全性,减少了对长期密钥的依赖。
- Alpha:支持 KYAML,一种更安全、更明确的 YAML 子集,专为 Kubernetes 设计,可作为 kubectl 的新输出格式。
功能逐渐稳定
- Job 控制器延迟创建替换 Pod,避免资源竞争。
- 从卷扩展失败中恢复的能力。
- VolumeAttributesClass 用于卷修改,允许在线调整卷参数。
- 结构化的身份验证配置,提高集群身份验证设置的可管理性和可审计性。
- 基于选择器的更细粒度的授权,实现最小权限原则。
- 通过细粒度控制限制匿名请求。
- 通过插件特定的回调实现更高效的重新排队。
- 有序的命名空间删除,确保安全和确定性的资源移除顺序。
- 流式传输 list 响应,提高 API 服务器的可扩展性。
- 弹性 watch cache 初始化,提高控制平面的健壮性。
- 放宽 DNS 搜索路径验证。
- Windows kube-proxy 中支持直接服务返回 (DSR)。
- 容器生命周期钩子的睡眠动作。
- Linux 节点交换支持。
- 允许环境变量中使用特殊字符。
- 将污点管理与节点生命周期分离。
Beta 阶段的功能
- Pod 级别的资源请求和限制。
- .kuberc 文件用于 kubectl 用户首选项。
- 外部 ServiceAccount 令牌签名。
- DRA 功能(包括管理员访问、优先级排序的资源声明和 kubelet 报告分配的 DRA 资源)。
- kube-scheduler 非阻塞 API 调用。
- Mutating Admission Policies。
- 可快照的 API 服务器缓存。
- 用于 Kubernetes 原生类型的声明式验证工具。
- 流式 informers 用于 list 请求。
- Windows 节点优雅关闭处理。
- Pod 原位调整大小改进。
Alpha 阶段的功能
- 用于 mTLS 身份验证的 Pod 证书。
- “受限” Pod 安全标准现在禁止远程探测。
- 使用 .status.nominatedNodeName 来表达 Pod 放置意图。
- DRA 功能(包括资源健康状态、扩展资源映射、可消耗容量和设备绑定条件)。
- 容器重启规则。
- 从运行时创建的文件加载环境变量。
升级、启用与移除
- 手动 cgroup 驱动程序配置已弃用。
- Kubernetes 将在 v1.36 中结束对 containerd 1.x 的支持。
- PreferClose 流量分配已弃用。
详细介绍
Kubernetes 1.34: Deep dive into new alpha features
Kubernetes 1.34 – Top Security Enhancements 💪
Tuning Linux Swap for Kubernetes: A Deep Dive
KEP-2831: Kubelet Tracing Finally Brings Node-Level Observability to Kubernetes
Kubernetes Will Solve YAML Headaches with KYAML
🎤 上一期简报中对新功能进行了简单的介绍,本期收集到一些功能的介绍文章,所以将继续总结。
节点
将资源健康状态添加到设备插件和 DRA 的 Pod 状态中
- 背景
此前,Kubernetes 缺乏一种机制来追踪通过动态资源分配 (DRA) 框架分配给 Pod 的设备健康状况。这使得故障排除变得异常复杂,因为很难确定问题是由故障设备(例如 GPU 或 FPGA)还是应用程序错误引起的。 - 改进
在 Pod 规范的 status 部分添加了一个新的 resourceHealth 字段,提供有关 Pod 所用资源的健康状况的信息。resourceHealth resourceHealth 显示以下值之一:Healthy、Unhealthy 或 Unknown。 - 示例
如果使用 GPU 的 Pod 由于硬件故障而进入 CrashLoopBackOff 状态,您现在可以使用 kubectl describe pod 检查 Pod 的状态,以确认 GPU 设备是否健康。或者,控制器可以检测到不健康的 Pod,并将其删除,然后其 ReplicaSet 将在另一个 GPU 上重新启动该 Pod。
容器重启规则,自定义 Pod 重启策略
- 背景
当 Pod 中的一个容器遇到了一个临时的、可恢复的错误,只需简单重启即可解决。之前,Kubernetes(遵循 Pod 的 restartPolicy = Never 这是批处理作业的常用设置)会将整个 Pod 标记为失败。然后,调度程序会启动一个昂贵且耗时的过程,终止 Pod 并重新调度它,很可能在一个全新的节点上进行。与此同时,其余 Pod 处于闲置状态,浪费了宝贵的计算时间。整个集群被迫回滚到最后一个已知的检查点,等待某个 Pod 重新上线。 - 改进
容器规范新增了 restartPolicyRules 部分,其中包含定义条件和操作的规则列表。在 Alpha 版本中,唯一可用的条件是容器的终止代码 (onExitCodes),唯一的操作是 Restart。
能够更细粒度地控制 Pod 内各个容器的重启。即使 Pod 已设置 restartPolicy = Never Kubernetes 现在也可以就地重启容器。这在重新创建 Pod 并将其重新调度到其他节点成本高昂的情况下尤其有用。 - 示例
如果容器在代码 42 下终止,则必须立即重新启动(参见下方示例)。如果容器在任何其他代码下终止,则将应用为整个 Pod 定义的标准重启策略。
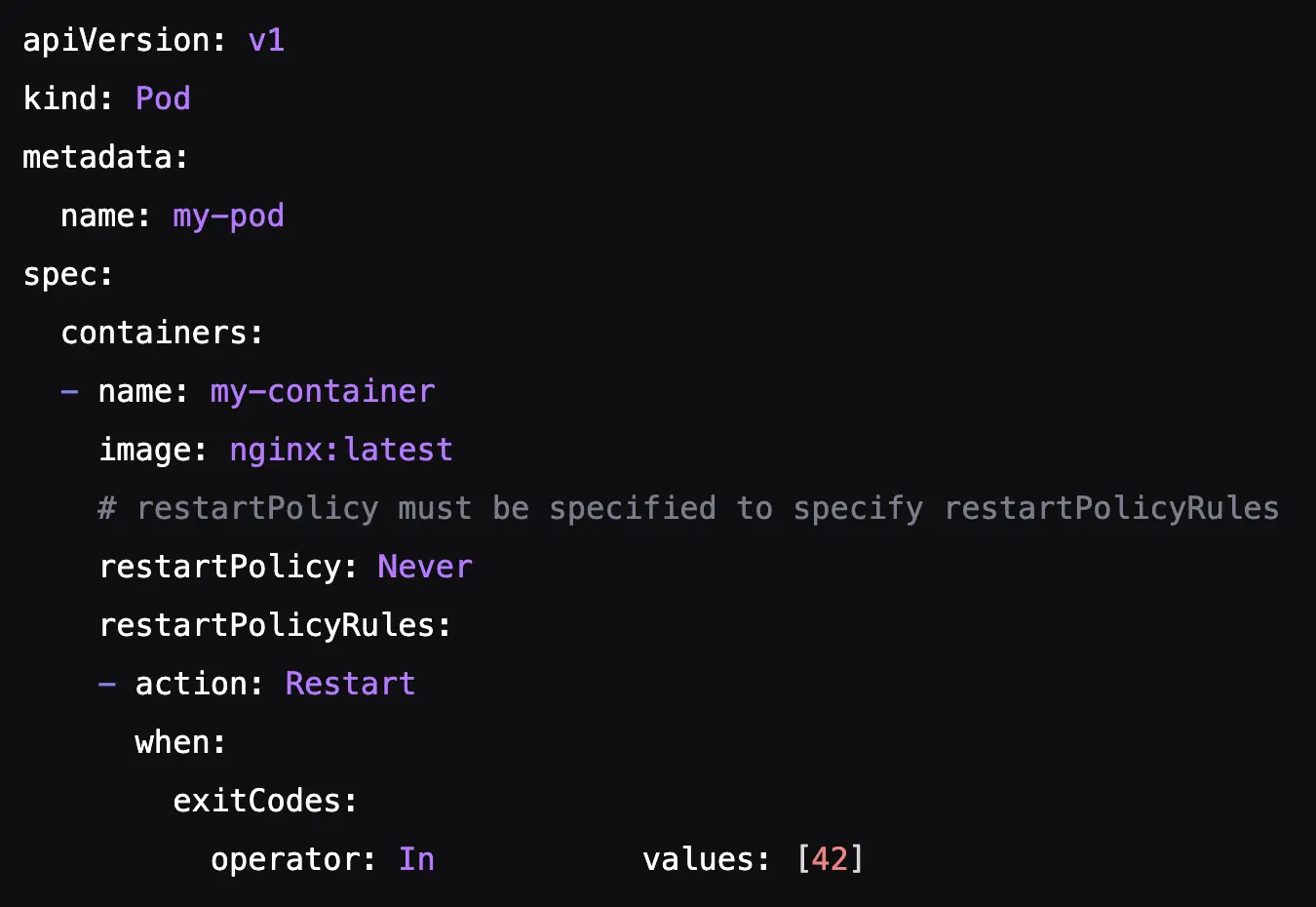
- 注意事项
此类容器重启不会被视为 Pod 故障。因此,它不会影响在更高控制器级别(例如 JobSet 中)定义的故障处理策略(也就是说,正在运行的作业不会失败)。kubelet 将强制执行这些规则,确保在 Pod 运行的节点上立即做出响应。此外,现有的指数退避机制将用于避免因反复故障而导致的无限重启循环。
添加 FileEnvSource 和 FileKeySelector,动态生成环境变量
- 背景
现有的通过 ConfigMap 或 Secret 填充环境变量的方法非常繁琐。当 initContainer 生成配置(例如临时访问令牌)时,需要将该配置传递给主容器。当前方法需要通过 API 服务器创建额外的 ConfigMap 或 Secret 对象。 - 改进
允许 initContainer 将变量写入共享 emptyDir 卷中的文件,这样主容器就可以在启动期间直接读取该文件,从而避免不必要的 API 调用。为此,在 Pod API( PodSpec )的 env.valueFrom 部分添加了一个新的 fileKeyRef 结构。 - 示例
在下面的使用示例中,initContainer 创建一个 /data/config.env 文件,其中包含变量 CONFIG_VAR=hello 。主 use-envfile 容器使用 fileKeyRef 从文件中读取 CONFIG_VAR 键的值,并将其设置为其 CONFIG_VAR 环境变量:
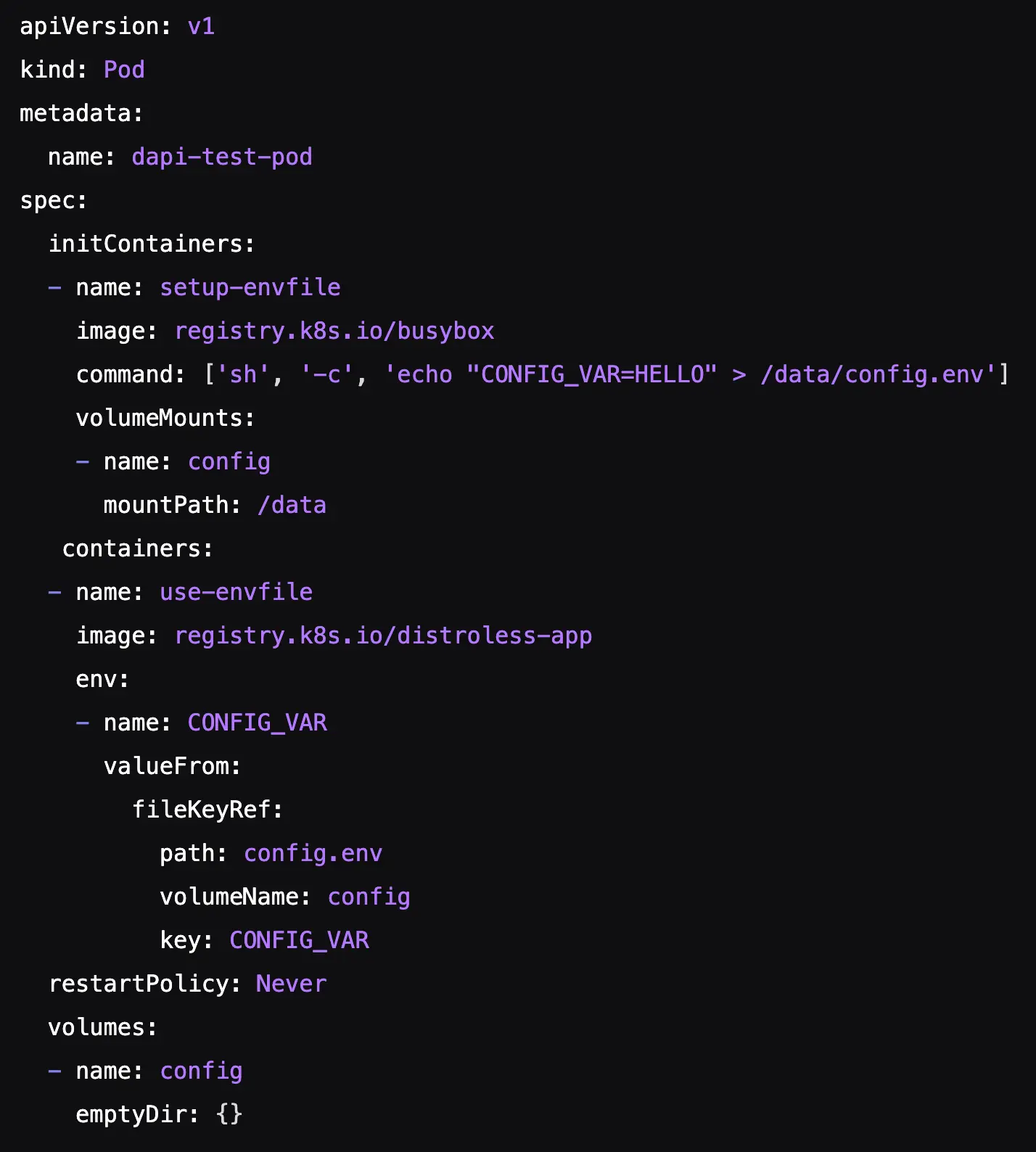
- 注意事项
- 将无法通过引用另一个变量来设置一个变量( VAR1=${VAR2} )。
- 在容器启动后更改 fileKeyRef 文件不会更新容器中的环境变量,也不会触发容器重启。
- 必须通过名称(键)指定所有变量。
调度
调度期间的异步 API 调用
- 背景
Kubernetes 调度器的性能至关重要。其主要瓶颈之一是对 kube-apiserver 的同步 API 调用。换句话说,调度器需要等待调用完成后才能执行其他操作,这会减慢整个过程的速度,尤其是在大型集群中。某些操作(例如 Pod 绑定)已经是异步的,但目前还没有一种统一的方法来处理所有 API 调用。 - 改进
在 kube-scheduler 内部引入一种新的通用机制,用于异步处理所有 API 调用。它通过一个管理队列并执行这些调用的特殊组件来实现这一点。
这意味着调度程序不再需要等待 API 调用完成。不仅如此,现在还可以跳过或合并某些调用。例如,如果某个 Pod 最初被标记为不可调度,然后几乎立即绑定到某个节点,则更新状态为不可调度的调用可能会被取消,因为该调用已经过期。
一个名为 APIQueue 的独立组件将管理所有异步 API 调用的队列。
调度器的插件和内部循环不会直接将调用发送到 APIQueue,而是会与调度器缓存进行交互。当发生 API 操作(例如 Pod 状态更新)时,它会首先在缓存中注册。之后,相关调用才会被传递到 APIQueue。
APIQueue 将在后台处理这些调用,因此不会阻塞主调度流程。这样,即使 Pod 的不可调度状态尚未到达 API,也可以将其放回调度队列。此外,APIQueue 可以合并或取消操作。例如,它可以将同一 Pod 的两个连续状态更新合并为一个 API 调用。
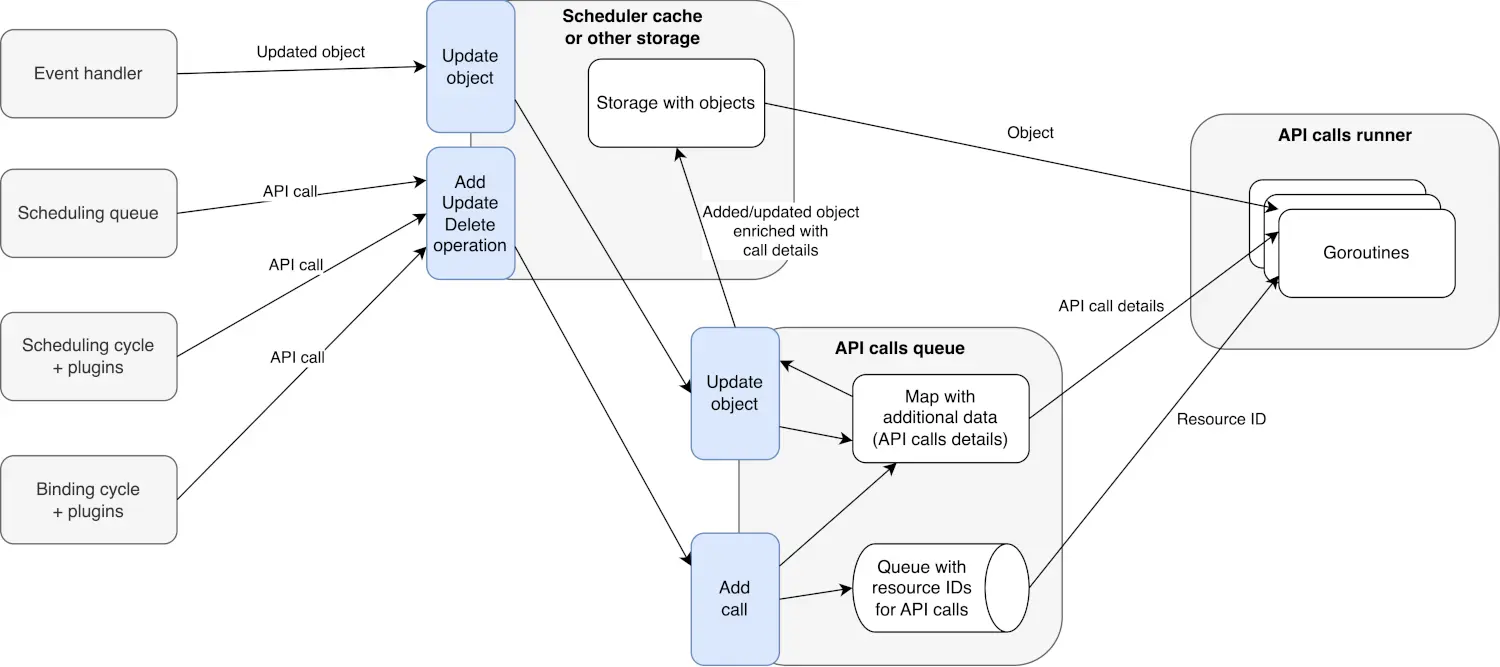
使用 NominatedNodeName 来表达预期的 Pod 位置
- 背景
Pod 绑定可能需要很长时间,有时甚至需要几分钟。在整个过程中,其他集群组件并不知道 Pod 将被调度到哪个节点。如果没有这些信息,它们可能会采取相互冲突的操作,例如,Cluster Autoscaler 可能会删除 Pod 即将被调度到的那个节点。此外,调度程序本身也可能会重启、丢失其 Leader 锁等等。由于调度决策仅存储在调度程序的内存中,因此新的调度程序会忽略之前的决策,并可能将 Pod 调度到其他节点。这将导致资源浪费和更长的延迟。 - 改进
此 KEP 极大地增强了 Pod 规范中的 NominatedNodeName 字段,将其从一个小众的抢占指示器转变为调度器与其他集群组件之间的双向通信通道。其主要目标是使 Pod 调度更加可预测且高效。
从现在开始,调度程序不仅可以发出信号表明其意图,而且 Cluster Autoscaler 或 Karpenter 等外部组件也可以影响调度决策。
调度程序现在将在 Pod 绑定周期开始时设置 NominatedNodeName,但仅当 Pod 在 Permit 或 PreBind 阶段需要执行长时间运行的操作(例如配置卷)时才会 PreBind 。PreBind 插件接口新增了一个轻量级的 PreBindPreFlight 函数,用于检查是否有必要设置 NominatedNodeName。如果所有插件都返回 Skip 状态,则调度程序将不会设置 NominatedNodeName 字段。
一个关键的行为变化是,如果节点暂时不可用或未满足要求(例如,仍在初始化中),调度程序将不再清除 NominatedNodeName 字段。这可以防止 Cluster Autoscaler 提供的有用提示被丢弃。现在,设置该字段的组件将负责更新或清除该字段。
最后,为了避免混淆并保持清晰,kube-apiserver 将在 Pod 成功绑定后自动清除 NominatedNodeName 字段。这样,该字段仅反映放置意图,而不是最终结果。 - 示例
外部组件现在可以正式使用 NominatedNodeName 来向调度器提供提示。例如,当 Cluster Autoscaler 为待处理的 Pod 启动新节点时,它可以提前设置它们的 NominatedNodeName。当调度器选择这样的 Pod 时,它会先检查该 Pod 是否可以调度到建议的节点,然后再检查其他节点。
DRA:通过 DRA 驱动程序处理扩展资源请求
- 改进
弥合了传统扩展资源与全新、更灵活的动态资源分配 (DRA) 框架之间的差距。其主要目标是使向 DRA 的过渡更加顺畅和轻松。这项新功能确保了现有应用程序的完全向后兼容性,使开发人员和管理员能够逐步采用 DRA,而无需立即重写所有清单。此外,您现在可以运行混合集群,其中相同的硬件在某些节点上使用旧的设备插件,而在其他节点上使用新的 DRA 驱动程序。 - 示例
集群管理员现在可以在 DeviceClass 规范中指定新的 extendedResourceName 字段,并为其分配扩展资源的名称,例如 example.com/gpu 。这告诉 Kubernetes,可以使用 DRA 管理的设备来满足对此资源的请求。 - 注意事项
由于可以通过资源声明或扩展资源来请求设备,因此集群管理员必须对一个设备类创建具有相同限制的两个配额,以有效地限制该设备类的使用量。
DRA:设备绑定条件
-
背景
常规 Kubernetes 调度程序假设 Pod 绑定时,节点上的所有资源均可用。然而,对于某些设备而言,情况并非总是如此,例如需要通过 PCIe 或 CXL 交换机动态连接的光纤连接 GPU,以及在使用前需要耗时重新编程的 FPGA。在设备尚未完全准备就绪之前,过早地将 Pod 绑定到节点会导致 Pod 启动失败,并需要手动干预。 -
改进
新的 BindingConditions 功能通过允许调度程序推迟最终的 Pod 绑定( PreBind 阶段)直到外部控制器确认所需资源已准备就绪来解决此问题。
设备提供商使用 ResourceSlice API 列出成功绑定必须满足的 BindingConditions 。它还可以设置 BindingFailureConditions ,如果触发该事件,则会取消绑定。因此,为了避免卡住,我们使用了一个 BindingTimeoutSeconds 计时器。如果计时器在设备准备就绪之前耗尽,则绑定将被取消,Pod 将返回队列并重新调度。
外部设备控制器的职责是更新 Pod 的 ResourceClaim 中这些条件的状态,让调度器随时了解其进度。这样,调度器就可以根据实时就绪情况做出绑定决策,而无需了解每个设备的具体运行情况。
如果设备准备失败,控制器会将 BindingFailureCondition 标记为 True 。调度程序随后会收到此消息,取消绑定,释放资源,并尝试再次调度 Pod,最好是调度到其他节点或通过其他资源。 -
使用场景
- 等待复杂设备。假设您正在部署一个需要专用设备(例如 FPGA)的应用程序。在使用之前,必须对 FPGA 进行重新编程以执行特定任务,这个过程需要几分钟。以前,调度程序会立即将 Pod 绑定到节点,而不知道设备尚未就绪。Pod 会启动,尝试访问 FPGA,然后崩溃,并卡在 CrashLoopBackOff 状态,直到初始化最终完成。现在,设备控制器可以通知调度器:“嘿,此节点上的设备目前正在初始化。” 看到此消息后,调度器不会急于进行绑定,而是等待该过程完成。如果初始化成功,调度器将收到 OK 消息并将 Pod 绑定到该节点。另一方面,如果该过程失败,控制器将报告失败,调度器将取消其放置决策,将 Pod 调度到其他节点。
- 按需连接资源。在此场景中,用户为其 Pod 请求一个 GPU。然而,该 GPU 是共享资源池的一部分,必须通过高速 PCIe 结构按需动态连接到节点。以前,调度程序会将未物理安装 GPU 的节点视为缺少 GPU 的节点。它无法知道资源是否可以动态附加,更不用说依靠它来做出决策了。这样的 Pod 永远不会在该节点上终止。现在,一个专门的控制器可以通知调度程序:“嘿,我有空闲的 GPU;我可以将一个 GPU 连接到这个节点,但我需要时间。” 当用户请求这样的 GPU 时,调度程序首先选择一个合适的节点并“预留”它,同时推迟 Pod 绑定。然后,它通知控制器继续执行连接操作。一旦控制器成功将 GPU 连接到节点并报告其已准备就绪,调度程序就会绑定该 Pod。如果连接因任何原因失败,调度程序将取消其放置位置的选择,并开始寻找其他选项。
-
注意事项
- 每个设备的 BindingConditions 和 BindingFailureConditions 的最大数量限制为 4。这确保调度程序可以在没有过多开销的情况下评估条件,并且 ResourceSlice 大小不会太大。
- 为了确保可靠的调度,外部控制器必须及时正确地更新 BindingConditions。任何延迟或错误都会直接影响调度的稳定性。
DRA:可消耗容量
- 背景
以前,只有当多个 Pod 或容器指向分配了该设备的单个 ResourceClaim 时,您才能共享该设备。 - 改进
允许独立的 ResourceClaims 获取同一底层设备的共享。这样,您就可以在完全不相关的 Pod 之间共享资源,即使它们属于不同的命名空间。
借助这一新机制,设备可以使用 ResourceSlice 的 devices 部分中的 allowMultipleAllocations 字段声明其允许多次分配。用户还可以使用 ResourceClaim 中新增的 CapacityRequests 字段向可共享设备请求特定的“容量”。
根据这些请求以及设备自身的共享策略,Kubernetes 调度器将计算实际消耗的容量(可能会四舍五入到最接近的有效值)。分配结果(包括消耗的容量)将反映在分配结果 (DeviceRequestAllocationResult) 的 ConsumedCapacities 字段中,并为每个共享分配一个唯一的 ShareID。
网络
放宽服务名称验证
- 背景
目前,与大多数其他 Kubernetes 资源(遵循 RFC 1123)相比,Kubernetes 中的服务名称遵循更严格的验证规则 (定义在 RFC 1035 中)。KEP-5311 放宽了服务对象名称的验证规则,使其与大多数其他资源适用的标准保持一致。 - 改进
可以通过 RelaxedServiceNameValidation 特性门控(默认禁用)激活此新行为。启用该特性门控后,新的 Service 对象将根据新的、更宽松的规则 (NameIsDNSLabel) 进行验证。因此,Ingress 资源 (spec.rules[].http.paths[].backend.service.name) 中服务名称字段的验证也会放宽。 - 注意事项
更新现有服务时,由于 metadata.name 字段不可变,因此不会重新验证其名称。这可以防止以后禁用特性门控时现有资源出现问题。
允许将任何 FQDN 设置为 Pod 的主机名
- 背景
默认情况下,Pod 的主机名就是其 metadata.name(例如, my-cool-pod-12345)。这是一个短域名,而不是 FQDN。虽然 Kubernetes 确实提供了 pod.spec.hostname 和 pod.spec.subdomain 字段来构建 FQDN,但它始终与集群的内部 DNS 绑定。例如,如果您设置 hostname: "foo" 和 subdomain: "bar" ,您将获得类似 foo.bar.my-namespace.svc.cluster.local 的 FQDN。
然而,目前还没有办法告诉 Pod:“嘿,你的主机名将是 database.my-company.com 。” 许多遗留或复杂的应用程序(例如某些数据库或身份管理系统,例如 FreeIPA)都期望它们所运行的操作系统具有特定的预定义 FQDN。在当前的实现中,Kubernetes 会自动在 Pod 名称中添加集群后缀(例如 .default.pod.cluster.local ),这会由于预期的 FQDN 与实际的 FQDN 不匹配而导致这些应用程序无法正常运行。 - 改进
在 PodSpec 中引入了一个新的 hostnameOverride 字段。如果设置了此字段,其值将用作 Pod 的主机名,覆盖当前的 hostname 、 subdomain 和 setHostnameAsFQDN 字段。指定的 FQDN 将被写入容器的 /etc/hosts 文件,以便应用程序正确标识自身。您可以通过 HostnameOverride 特性门控启用此新行为。 - 注意事项
- 此功能仅更改 Pod 内部的主机名(即 hostname 和 hostname -f 命令返回的值)。它不会在集群 DNS 中创建任何相应的 DNS 记录。因此,除非您手动配置 DNS,否则其他 Pod 将无法将此 FQDN 解析为 Pod 的 IP 地址。
- 主机名不能超过 64 个字节,这是 Linux 内核的限制。我们将添加 API 验证,以防止创建名称过长的 Pod。
- 您不能同时使用 hostnameOverride 和 setHostnameAsFQDN: true,因为它们的作用相反。API 会拒绝此类配置,并显示错误,指出这些字段互斥。如果您想更好地理解新功能的运作逻辑以及运作时间,请查看 KEP 设计细节部分中的表格。
- 如果 Pod 设置了 hostNetwork: true,它仍将使用其主机节点的主机名,并且 hostnameOverride 字段将被忽略。
授权
Pod 证书
- 背景
虽然 certificates.k8s.io API 提供了一种灵活的证书请求方式,但工作负载中的证书交付和管理必须由开发人员和集群管理员负责。 - 改进
实现了一个名为 PodCertificateRequest(CertificateSigningRequest 的精简版本)的新型 API 资源。此资源允许 Pod 直接向特定签名者请求证书,并在请求中包含其身份所需的所有必要信息。投影卷的新来源 PodCertificate 也是此 KEP 的一部分。将此卷挂载到 Pod 后,kubelet 可以执行完整的凭证管理周期:生成私钥、创建 PodCertificateRequest 、等待证书颁发,以及将密钥和证书链挂载到 Pod 的文件系统中。
作为此机制的主要用途,KEP 允许 Pod 通过 mTLS 向 kube-apiserver 进行身份验证,这是一种比服务帐户令牌更安全的替代方案。名为 PodIdentity 的新 X.509 扩展将 Pod 信息嵌入到证书中,包括其 UID、命名空间及其运行的主机。反过来,Kube-apiserver 会通过将这些证书映射到特定的 Pod 来识别和验证这些证书。
将 PSA 添加到 ProbeHandler 和 LifecycleHandler 的阻止设置 .host 字段
- 机制
ProbeHandler 和 LifecycleHandler 结构中的 Host 字段允许用户为 TCP 和 HTTP 探测指定自己的主机,由于 kubelet 可以被定向到任何 IP 地址,因此存在服务器端请求伪造 (SSRF) 攻击的风险。
KEP 添加了新的 Pod 安全准入(PSA)策略,使集群管理员能够禁止创建使用 Host 字段的 Pod。此新策略将成为默认 Baseline 安全配置文件的一部分,使其更易于执行。从 API 中移除 Host 字段会破坏向后兼容性,因此目前没有移除计划。
CLI
KYAML
- 背景
YAML 虽然易于阅读,但也存在一些明显的缺点。例如,它依赖于空格缩进,要求用户仔细跟踪嵌套深度。此外,由于 YAML 中字符串两端的引号通常是可选的,因此某些字符串值会自动转换为其他数据类型。
例如,不带引号时,NO、no、N、YES、yes、Y、On 和 Off 会被解析为布尔值(哦,著名的“挪威问题”)。像 _42 和 4_2 这样的值会被解析为数字,而像 1:22:33 这样的字符串则会转换为 60 进制数字。这对于计算秒数很方便,但问题在于规范的作者忘记为这些六十进制数字设置最大值。因此,如果您输入六个用冒号分隔的数字(例如 MAC 地址),它们会被解析为一个非常大的时间间隔,而不是字符串。 - 改进
KYAML 通过以下方式解决上述问题:- 所有字符串始终用引号引起来,以避免意外的类型转换(例如,“no”不会转换为 false)。
- 它明确使用“流式”语法:列表使用 [],映射使用 {}。
- 降低对空格和缩进的敏感度使其更加健壮和防错。
至关重要的是,KYAML 仍然是一个有效的 YAML,这使得它与所有现有工具兼容(例如,任何 YAML 处理器都可以读取它)。
从长远来看,我们的提案是将 KYAML 定为 Kubernetes 项目中所有文档和示例的标准。这将推动生态系统在配置时采用更安全、更抗错的实践。
可观测性
Kubelet Tracing 为 Kubernetes 带来了节点级可观察性
- 背景
虽然 kubectl describe 和 kubelet logs 可以告诉你发生了什么,但要理解原因,通常需要关联多个日志条目和事件的时间戳。 - 改进
借助 KEP-2831 的分布式跟踪,您可以获得以下方面的结构化可见性:- Pod 生命周期操作:从调度到运行状态的精准计时
- 容器运行时交互:镜像拉取、容器创建和启动序列以及持续时间指标
- 卷操作:挂载/卸载操作以及与延迟数据的存储交互
- 资源管理:具有性能洞察的 CPU、内存和存储分配流程
其主要优势在于将这些操作视为相互关联的轨迹,而不是孤立的日志条目。单条轨迹即可显示镜像拉取耗时 45 秒,随后卷挂载耗时 10 秒,从而让您一目了然地了解 Pod 启动时间的具体耗时。与应用程序轨迹结合使用时,此功能尤为强大,可为您提供从用户请求到容器启动的真正端到端可观察性。
📰 专题二 新闻与访谈
1. ESO 项目发布暂停,直至维护团队重建
🚨 ESO Maintainer Update: We need help. 🚨
ESO 是什么
External Secrets Operator 是一个 Kubernetes Operator,它集成了外部机密管理系统,例如 AWS Secrets Manager 、 HashiCorp Vault 、 Google Secrets Manager 、 Azure Key Vault 、 IBM Cloud Secrets Manager 、 Akeyless 、 CyberArk Conjur 、 Pulumi ESC 等等。该 Operator 从外部 API 读取信息,并自动将值注入 Kubernetes Secret 中。
遇到了什么困难
贡献者与用户之间仍然存在严重的不平衡。近年来,该项目耗尽了太多维护者。尽管应用范围广泛,贡献者群体却未能随着用户群体的扩大而增长。目前,所有维护工作都由一个规模很小的维护团队负责:
- 审查和合并代码
- 修复错误、CVE 和增加依赖项
- 准备发布
- 运行 CI 基础设施
- 响应支持请求
- 保持治理和合规性
- 举办社区会议
未来的计划
仍然会做:
- 审查并合并社区 PR
- 贡献将在主分支上可用
如何帮助
金钱无法解决这个项目的可持续性问题。真正需要的是那些能够一起运营这个项目的、能够持续投入时间的长期贡献者。如感兴趣,可以填写表格。
2. CNCF 寻求 Kubernetes 可移植 AI/ML 工作负载的需求
CNCF Seeks Requirements for K8s-Portable AI/ML Workloads
背景
CNCF 正在创建一个项目,用于认证能够运行特定类型 AI 工作负载的 Kubernetes 发行版。但该项目需要先满足一系列要求和建议。他们正在寻求您的帮助。(Help Us Build the Kubernetes Conformance for AI)
其理念是复制 CNCF 为 Kubernetes 制定的一致性指南。到目前为止,已有超过 100 个 Kubernetes 发行版列入了该指南。
该工作组的目标是“定义 Kubernetes 集群必须提供的一套标准化的功能、API 和配置,以可靠、高效地运行 AI/ML 工作负载”。
这项工作还将为更广泛的“云原生 AI 一致性”定义奠定基础,包括云原生计算的其他方面,例如遥测、存储和安全。
谷歌、红帽和其他商业公司正在向该项目提供资源。
商品化 Kubernetes
早期的虚拟讨论中,总体目标是让 AI/ML 工作负载平台尽可能地商品化。“希望是最大限度地减少运行 AI/ML 工作负载所需的手动搭建(DIY)和特定于框架的补丁,”一位工作组成员写道。
该小组确定了三种适合 Kubernetes 的工作负载类型:
- 大规模训练和微调:关键平台要求包括访问高性能加速器、高吞吐量和拓扑感知网络、群组调度和可扩展的数据访问。
- 高性能推理:关键平台要求包括访问加速器、高级流量管理以及监控延迟和吞吐量的标准化指标。
- MLOps 管道:关键平台要求包括强大的批处理作业系统、用于管理资源争用的排队系统、对对象存储和模型注册表等其他服务的安全访问以及可靠的 CRD/操作员支持。
该草案还列出了一系列建议的做法(“应该”)和明确的要求(“必须”),其中许多是基于最近 Kubernetes 针对 AI 人群的增强功能。
认证计划
该认证计划将有一个公共网站,列出所有通过一致性测试的 Kubernetes 发行版。这些发行版将每年进行一次测试。每个发行版都将提供一份完整的基于 YAML 的一致性检查表。
CNCF 计划于今年 11 月 10 日至 13 日在亚特兰大举行的 KubeCon+CloudNativeCon North America 2025 上发布完成的一致性指南。
3. Open Policy Agent 创始团队已加入 Apple
Open Policy Agent 创始团队已加入 Apple
Note from Teemu, Tim, and Torin to the Open Policy Agent community
OPA is now maintained by Apple
OPA 是什么
OPA 是一个开源的、通用的策略引擎。它可以让你在整个技术栈中统一地、根据上下文来执行策略。简单来说,它帮助你集中管理和执行各种授权、准入控制和配置策略。
🎤 和后文中介绍的 Cerbos 很类似,同款竞品。
影响与效果
- OPA 仍是 CNCF 毕业阶段的开源项目,项目治理和许可没有变化。
- 维护者名单不变,唯一变化是部分维护者的组织从 Styra 变更为 Apple。
- Styra GitHub 会将以下工具被贡献给 CNCF OPA GitHub 组织,以进行更深入的开源社区协作,包括:
- Styra 的商业发行版 OPA, EOPA
- OPA 控制平面
- SDKs
- Regal
- OPA 官网仍由 CNCF 和更广泛的 OPA 社区维护,持续开放。Rego Playground 仍由 Styra 运营,功能不变。
- OPA 将继续按月发布版本。
4. Metal3 成为 CNCF 孵化项目
Metal³ 项目(发音为“Metal Kubed”)提供使用 Kubernetes 进行裸机主机管理的组件。您可以注册裸机,配置操作系统镜像,然后根据需要将 Kubernetes 集群部署到这些裸机上。之后,您的 Kubernetes 集群的运维和升级就交给 Metal³ 来处理。此外,Metal³ 本身就是一个 Kubernetes 应用程序,因此它在 Kubernetes 上运行,并使用 Kubernetes 资源和 API 作为其接口。
Metal³ 是 Kubernetes 子项目 Cluster API 的提供商之一。Cluster API 提供与基础设施无关的 Kubernetes 生命周期管理,而 Metal³ 则提供裸机实现。
Metal³ 项目的使命是为组织提供一个灵活的开源裸机配置解决方案,该方案将裸机的性能优势与 Kubernetes 所提供的易用性和自动化能力相结合。
市面上有许多优秀的开源工具可用于裸机主机配置,包括 Ironic。Metal 3 旨在基于这些技术,提供 Kubernetes 原生 API,通过同样运行在 Kubernetes 上的配置栈来管理裸机主机。我们相信,Kubernetes 原生基础设施,或者说像管理应用程序一样管理基础设施,是基础设施管理发展的重要一步。
💬 专题三 讨论与分享
1. 在假设某个设置合理之前,务必先检查它的“默认”设置
We spent weeks debugging a Kubernetes issue that ended up being a “default” config
“我们花了三周时间追踪 Kubernetes 预发布环境中一个奇怪的 DNS 故障。指标正常,Pod 运行正常,日志干净。但一些内部服务却随机出现名称解析失败的情况。”
“猜猜怎么了?根本原因是:kube-dns 默认设置的 CPU 限制很低,在中等负载下,它默默地卡住了。没有警报,没有日志,只是随机解析失败。”
“教训:在假设某个设置合理之前,务必先检查它的“默认”设置。Kubernetes 赋予你强大的功能,但它也假设你知道自己在做什么。”
🎤:相应地,产品在提供默认值也需要保证其合理性。
2. Kubernetes List API 的性能和可靠性
Kubernetes List API performance and reliability
一篇技术分享文章,具体见原文。
3. 保护节点:Cilium 主机防火墙简介
背景
Cilium 主机防火墙旨在精准锁定主机网络命名空间,提供可视化和控制,且将熟悉的 Kubernetes 声明式网络策略模型扩展到主机层面。
Kubernetes 原生网络策略不适用于主机层流量。这意味着任何直接进出节点的通信(如 SSH、kubelet 或外部监控代理)传统策略无法管控。虽然可以用 firewalld 或外部系统做防火墙,但规则管理复杂且缺少 Kubernetes 集成。Cilium 主机防火墙正是为解决这一问题而生。它基于 eBPF 技术,将主机防火墙能力直接内嵌到集群中。
原理
Cilium 将节点视为一种特殊端点,标签为 reserved:host。这样,我们可以像管理 Pod 一样管理节点流量。主机防火墙在网卡接口级别工作,你可以指定绑定的设备(eth0、eth1 等),也可以让 Cilium 自动检测。
最佳实践与排查建议
- 节点标签要明确:确保策略里的 nodeSelector 标签与节点实际标签匹配。
- 先用审计模式测试:避免误操作导致控制面或 SSH 访问中断。
- 观察监控日志:用 cilium-dbg monitor 及时了解被阻断或允许的包。
- 确认设备匹配:如果主机防火墙无效,检查 Cilium 是否管理了正确接口。
- Hubble 好帮手:Hubble 流日志对编写和调试策略非常有用。
4. 新版本即将发布:您可以通过以下方式帮助 Kubernetes
New release coming: here's how YOU can help Kubernetes
用户很少使用 Alpha 版本,即使是 Beta 版本,反馈也非常有限。可以为 Kubernetes 项目做的最有用的事情就是尝试 alpha 和 beta 功能,突破新 API 的极限,尝试突破它们,并发送反馈。例如:
- “我为 XYZ 尝试过并且效果很好”
- “我尝试了 ABC 但遇到了困难...”
无论是笨重的 API、糟糕的默认值、明显缺失的功能,还是设法诱骗它做错事,或者发现了一些极端情况,又或者它与其他功能配合不佳 - 请说出来。可以通过 GitHub、Slack、电子邮件,甚至在这里发帖!
6. VMware Cloud Foundation 相关文章摘录
VCF 发布后,VMware 在 8 月陆续发布了多篇博客进行介绍,下面摘录一些重点内容。
Tanzu Hub 的大规模管理和多基础视图
At-Scale Management and Multi-Foundation Views with Tanzu Hub
🎤 在本文中,"foundation" 指的是 Cloud Foundry 的一个部署实例。可以把它理解为一个独立的 Cloud Foundry 环境,包含运行应用程序所需的所有组件和服务。
Cloud Foundry 是 2011 年推出的一个开源平台即服务(PaaS),初衷是方便开发人员构建最早的容器化应用。Cloud Foundry 关注开发人员体验,为开发人员构建、部署和运行无状态云原生应用提供了一个平台。
- 背景
- 重复工作:每个 Foundation 独立管理,导致重复建设和资源浪费。
- 可见性不足:缺乏统一视图,难以全面了解应用健康状况、资源利用率和潜在问题。
- 运营成本增加:随着业务扩展,维护多个 Foundation 的复杂性迅速上升。
- 治理和合规性:不同团队和环境的差异导致策略执行不一致,增加合规风险。
- Tanzu Hub 的方案与特点
- 统一管理界面:提供跨所有 Cloud Foundry Foundation 的单一界面,用于监控、治理和优化。
- 集中可见性:提供遥测数据、配置和运行时洞察,无需访问每个 Foundation。
- 集中控制:允许平台工程团队跟踪合规性、强制执行策略并自动化访问控制。
- 内置和可定制的 Runbook:快速响应告警,提供故障排除和上下文感知能力。
- 主要功能
- 多 Foundation 视图:从主屏幕即可查看告警、容量、应用实例状态、内存消耗等。
- Foundation 分组和标签:可以按地区、业务部门、网络分段等对 Foundation 进行分组和标记,以便更灵活地管理。
扩展阅读:Observability and Visibility at Scale with Tanzu Hub
使用 Tanzu Hub 进行更智能的工作负载放置和容量管理
Smarter Workload Placement and Capacity Management with Tanzu Hub
- 容量管理的重要性
在现代应用环境中,管理资源和容量是一项持续的挑战。随着这些环境的分布式程度不断提高,容量管理不善的影响也日益凸显。过度利用会导致性能下降、无法满足 SLA 以及持续的资源浪费,而利用不足则会导致成本增加和资源浪费。 - Tanzu Hub 的容量管理功能
- 实时监控:连接 Tanzu Platform 后,Tanzu Hub 可以实时显示 Diego cell 的容量利用率、指标和性能数据。
- 容量分析和告警:内置的容量分析和告警功能可以提前发现资源过度使用或未充分利用的情况。
- 逻辑分组:可以对应用和基础架构进行逻辑分组(Foundation Groups 和 Business Application),方便管理和理解资源消耗情况。
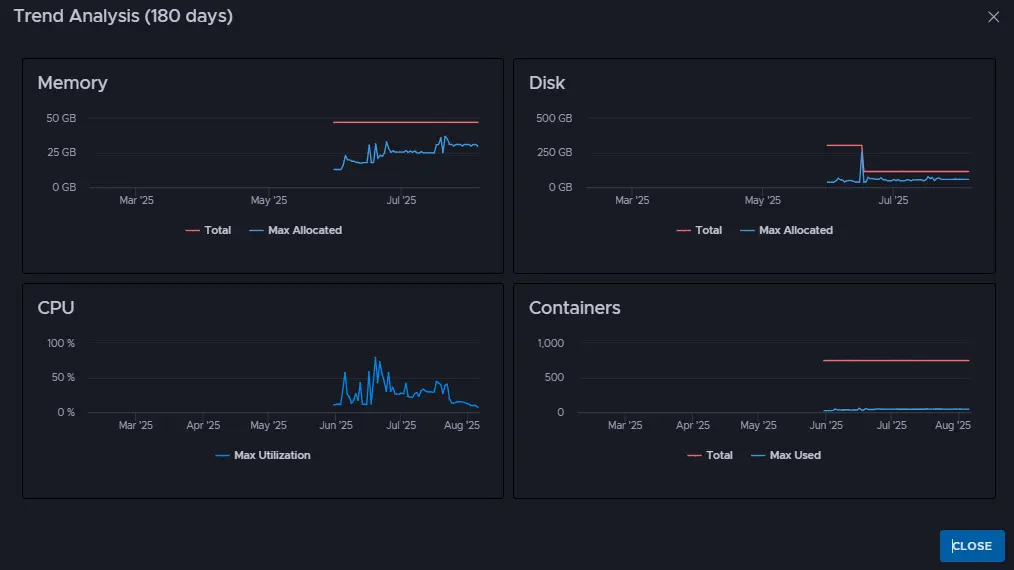
VMware Cloud Foundation 中的 Kubernetes 多集群管理
Kubernetes Multi-Cluster Management in VMware Cloud Foundation
作为 VMware 统一私有云战略的一部分,VMware Cloud Foundation (VCF) 现已包含 Kubernetes 多集群管理功能。
自 2025 年 5 月起,所有拥有有效 VCF 订阅的客户均可免费使用 Tanzu Mission Control 自管理版 (TMC-SM)。立即生效,如果拥有有效的 VCF 订阅,即可开始使用 TMC-SM 管理在 VCF 5.x/vSphere 8.x 环境中运行的 K8s 集群。
- 为什么需要多集群管理
随着容器和 Kubernetes 的广泛应用,复杂性也随之增加。平台团队难以跟上云原生生态系统的快速变化。TMC-SM 旨在通过其资源层次结构和数据模型,简化 Kubernetes 操作,并提高控制、效率和安全性。 - Tanzu Mission Control Self-Managed 1.4.2 正式发布
- 精细的 RBAC
- 策略管理
- 集群生命周期管理
- 数据保护
- 软件包管理
- 持续交付
- 集群检查
- TMC-SaaS 的变化和向自主管理的过渡
由于 VCF 战略侧重于私有云和打包软件产品,TMC 的 SaaS 版本将于 2025 年 11 月 15 日停止服务 (EoL)。建议 TMC-SaaS 客户迁移到 TMC Self-Managed。Broadcom 提供迁移指南和支持。
Tanzu Platform 10.3 助力下一代 AI 应用
Powering the Next Generation of AI Applications with Tanzu Platform 10.3
VMware Tanzu Platform 10.3 版本在以下几个方面进行了增强:
- 增强平台安全性、可观察性和协作性
- 漏洞洞察仪表板:提供对 Tanzu 产品和组件中 CVE 影响的透明度,帮助团队快速识别受影响的组件版本和可用的补丁,简化补丁状态报告流程。
- Tanzu Hub 升级:提供基础架构健康状况的清晰洞察,加速故障排除。
- 数据服务仪表板:提供对 MySQL、Postgres、RabbitMQ、Valkey 和 GemFire 等关键数据服务的资源使用情况、延迟、吞吐量和潜在问题的可见性。
- 服务发布功能:允许开发者将应用程序作为平台上的精选服务发布到服务市场,改善团队协作,简化架构并增强应用程序的可扩展性。
- 为人工智能应用带来治理和控制
引入了新的企业治理功能 ,包括 AI 模型配额功能和架构更新。 - 现代应用程序可提高业务速度
- 通过模型上下文协议 (MCP) 将 Application Advisor 与热门开发者 IDE 集成。
利用 Tanzu Data Intelligence 统一数据,加速 AI 应用交付
Unify Your Data to Accelerate AI Application Delivery with Tanzu Data Intelligence
2025.8.26,VMware 新推出了 VMware Tanzu Data Intelligence,这是一个统一的数据平台,旨在帮助企业无缝访问、管控和激活所有数据,无论这些数据位于何处。Tanzu Data Intelligence 可以提供这一基础,将数据湖和仓储引擎、流水线、高并发查询引擎和智能缓存集成到一个统一的系统中,并针对现代工作负载进行全面托管和优化。
- 五大行业变革使数据智能成为必需品
- 云原生思维转向 AI 原生思维。
- 数据种类、速度和数量都在不断增加。
- 现代应用程序需要实时、高并发的数据访问。
- 自然语言界面正在强化 SQL 的价值并使数据民主化。
- Postgres 作为数据接口正变得无处不在。
- 统一的企业级 AI 就绪数据平台
- 摄取和工作流程编排
- 联合查询服务
- 容器计算服务
- 实时数据服务
- 高级分析和 AI/ML
📄 专题四 报告查看与分析
1. [Spectro Cloud] Kubernetes in the AI era - The Spectro Cloud 2025 State of Production Kubernetes
下面摘取部分结论。
采用情况日趋成熟和多样化
- 65% 的人表示他们的雇主已经使用 K8s 超过五年。
- 51% 的 K8s 采用者拥有 >20 个集群和 >1,000 个节点。
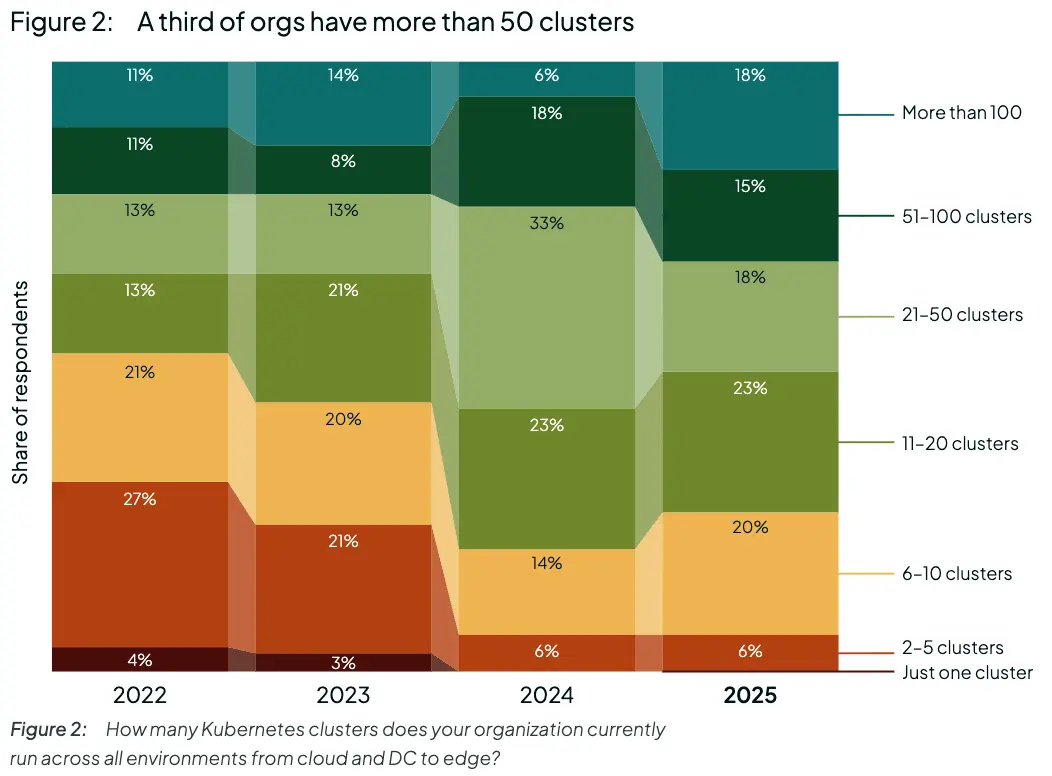
- 普通组织在 5 个以上不同的云和其他环境中拥有集群。
- 多云策略是集群部署的最大驱动力。
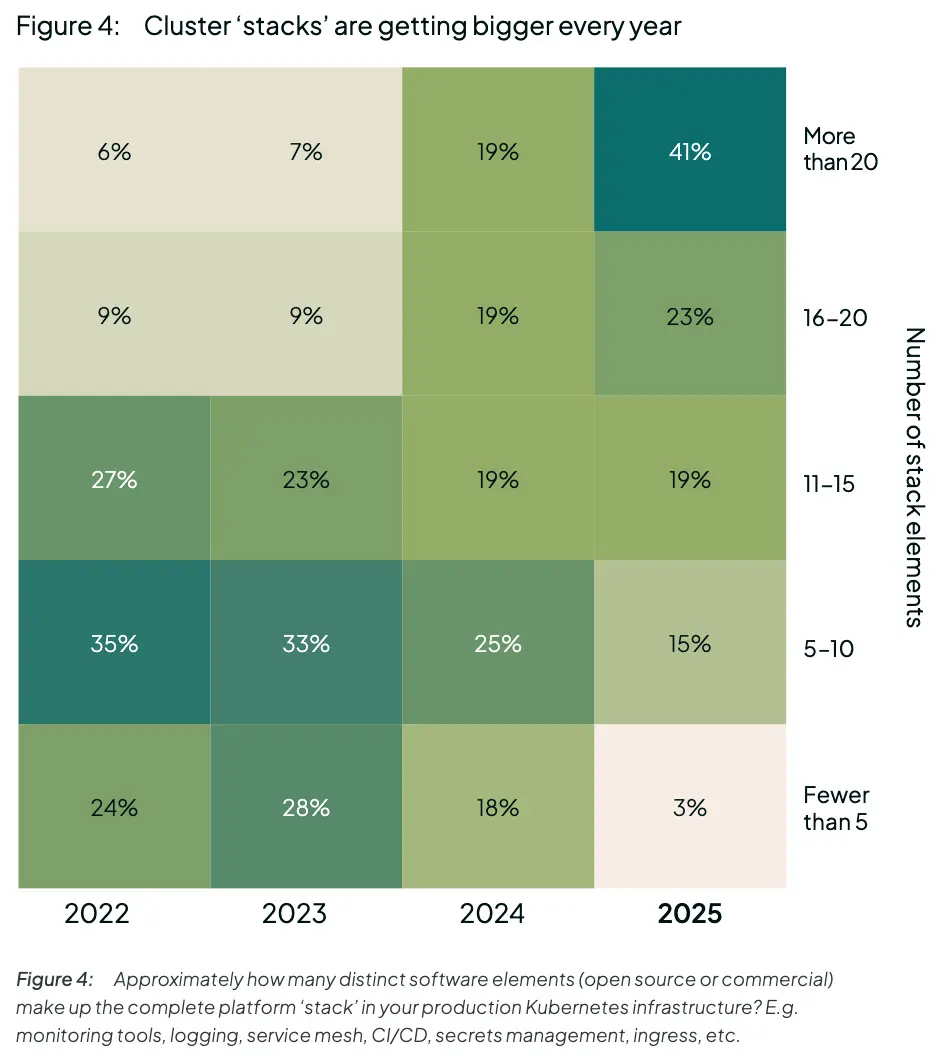
- 三分之二的组织在其 K8s 堆栈中拥有 15 多个不同的软件元素。
为传统虚拟机工作负载提供可行的解决方案
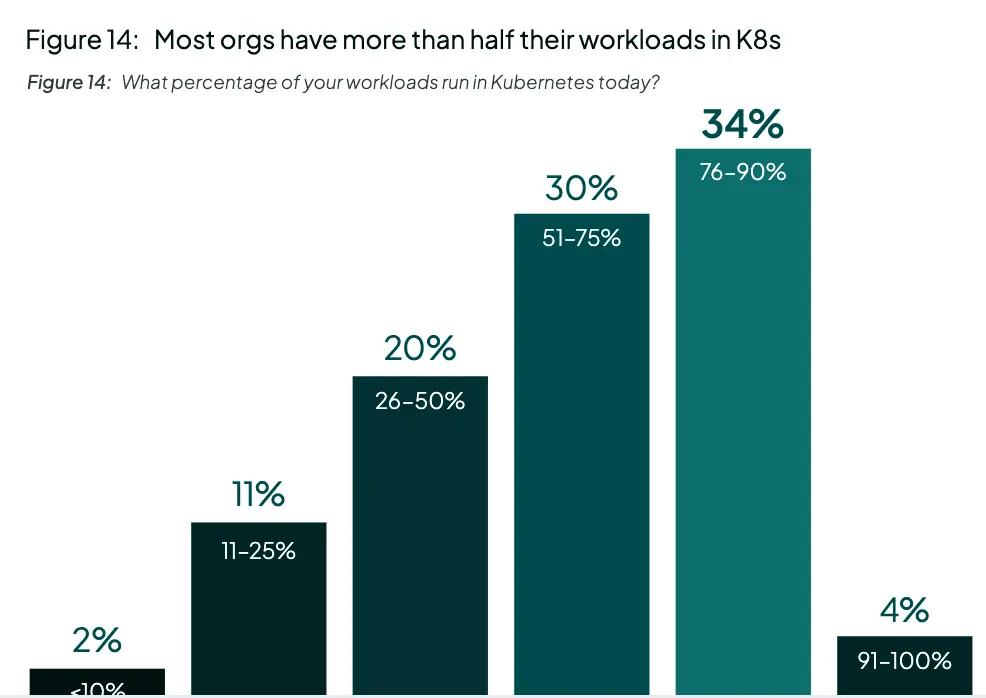
- 目前,68% 的采用者有一半以上的应用工作负载在 K8s 中。
- 31% 的人计划将剩余的旧式虚拟机迁移到 Kubernetes——这是最受欢迎的策略。
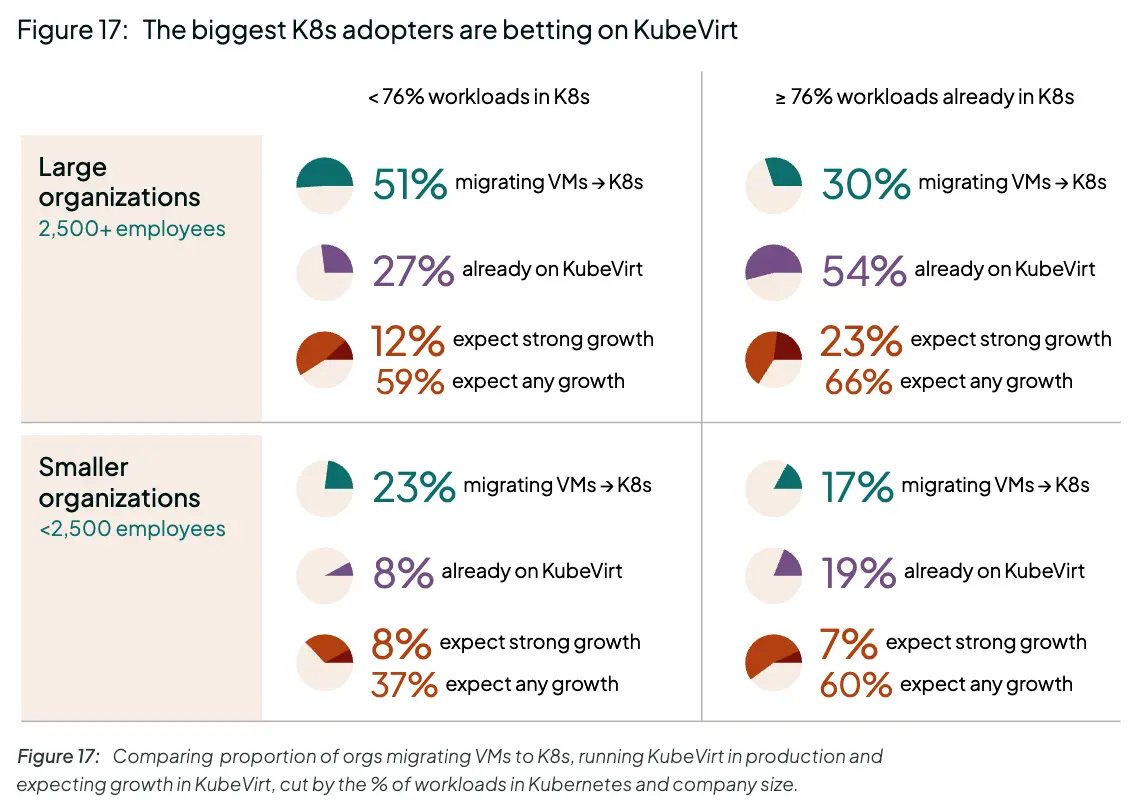
- 86% 的人听说过 KubeVirt,26% 的人目前在生产中使用它。
- 那些全力投入 Kubernetes 的人更有可能使用 KubeVirt 并计划迁移。
人工智能成为焦点,推动边缘发展
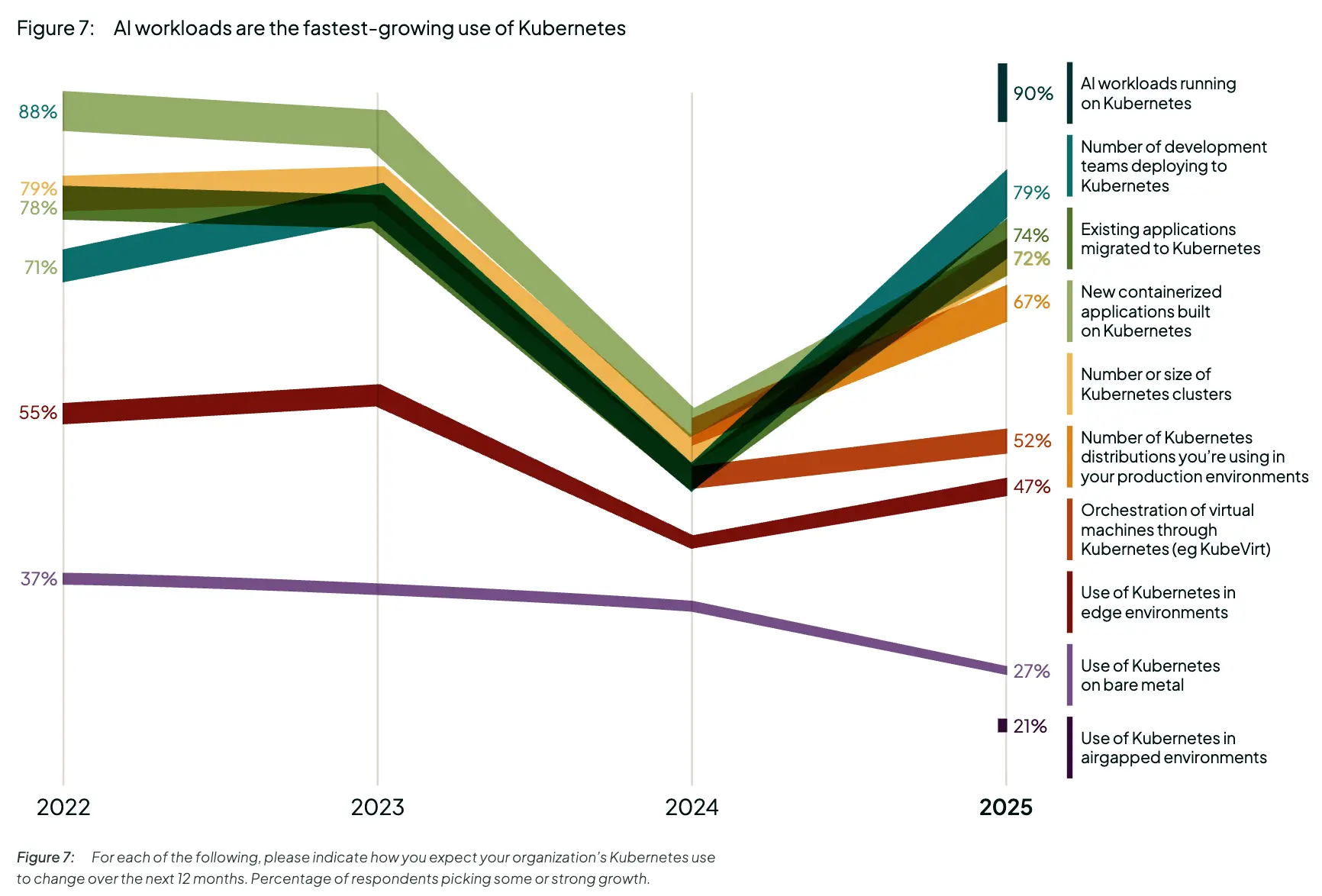
- 成本是 K8s 面临的首要挑战。88% 的受访者表示,他们的 K8s TCO 在去年有所增长。
- 人工智能是解决成本问题的首要机会。92% 的人表示他们正在投资人工智能成本优化工具。
- 增长预期又回来了。90% 的人预计明年他们在 K8s 上使用的 AI 工作负载将会增长。
- 人工智能正在推动边缘 K8s 的采用。目前 50% 已部署到边缘,平均有 50 个站点。
运营:进步,而非完美
- 80% 表示他们拥有成熟的平台工程功能。
- 50% 的人承认他们的集群是雪花,并且他们的 K8s 操作工作高度手动。
- 59% 的人表示他们可以在 24 小时内修补整个 K8s 基础设施。
- 当中央平台团队管理将应用程序部署到集群的工具/管道时,组织在 DORA 指标上的表现会好得多。
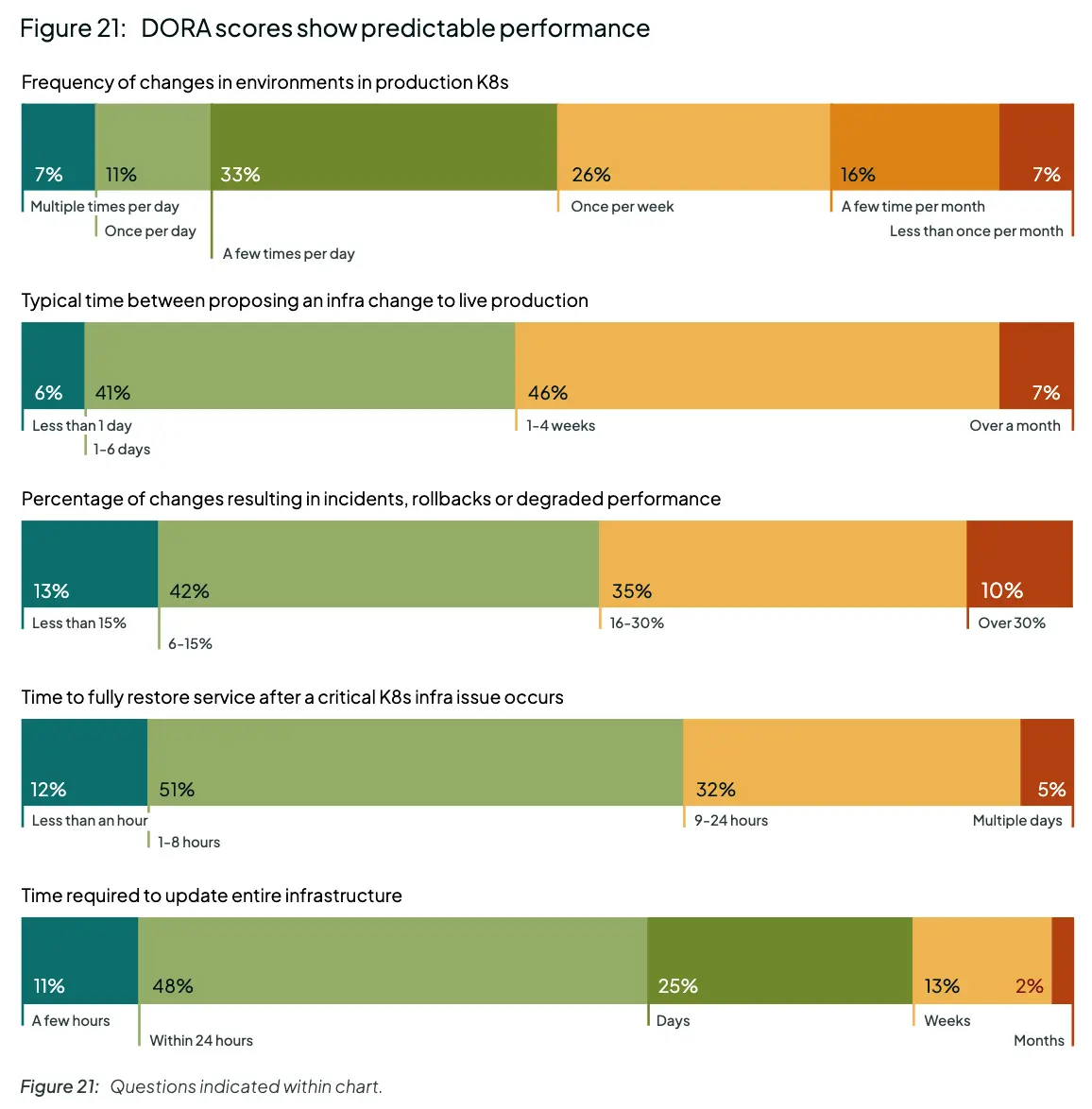
拓展阅读
State of Production Kubernetes 2025
2. [Gartner] Magic Quadrant for Cloud-Native Application Platforms
Magic Quadrant for Cloud-Native Application Platforms
市场定义/描述
背景
2024 年,云原生应用平台市场收入超过 35 亿美元,全球支出同比增长 16.4%,达到两位数。预计到 2029 年,该市场收入将突破 70 亿美元大关,2024 年至 2029 年的五年复合年增长率(按固定汇率计算)为 15.1%。
云原生应用平台的核心能力是为应用代码提供云原生的运行时环境。本次魔力象限的供应商正是基于这一核心能力进行评估的。此外,评估还考虑了其他能力,例如无服务器函数、在抽象基础设施上部署容器、AI 推理支持、与 AI 应用开发平台的集成、与数据库、事件代理、CDN、边缘基础设施、API 网关、内容管理服务、ERP 系统以及开发者工具的集成。
简介
Gartner 将云原生应用平台定义为:为应用程序提供托管的应用程序运行时环境,并提供集成功能来管理云环境中应用程序或应用程序组件的生命周期。它们通常支持分布式应用程序部署,并支持云原生操作(例如弹性、多租户和自助服务),而无需开发团队配置基础设施或管理容器。
云原生应用平台旨在促进现代云原生或云优化应用程序的部署、运行时执行和管理,而无需管理任何底层基础设施。此外,它们还旨在提高开发人员的工作效率,加快开发和部署周期,并通过更轻松地按需扩展来提升运营效率。
云原生应用平台为应用程序提供结构化的执行环境,有效隐藏底层基础设施和计算资源的复杂性。它们还为常用语言(例如 Java、.NET、Node.js、PHP、Python、Go 和 Ruby)提供供应商支持的应用程序运行时和框架版本。通过抽象与基础设施管理相关的复杂性,云原生应用平台使产品团队能够更快地交付客户价值。
云原生应用平台支持开发人员有以下使用场景:
- 大容量事务应用程序 —— 开发人员使用云原生应用程序平台来创建和运行需要高性能、可扩展性和弹性的应用程序。
- API 优先共享服务 —— 开发人员使用云原生应用平台创建 API 优先服务,从而支持微服务架构。
- 解耦的 Web UI/UX —— 开发人员使用云原生应用程序平台来创建现代、交互式和响应式的用户体验、渐进式 Web 应用程序或嵌入式移动组件。
- 云迁移 —— 开发人员使用云原生应用平台将遗留堆栈应用程序迁移到云中,而无需立即重建。
- 人工智能代理和应用程序 —— 开发人员使用云原生应用程序平台构建人工智能代理和应用程序,即使用人工智能技术在数字或物理环境中感知、做出决策、采取行动和实现目标的自主或半自主软件实体。
典型的云原生应用平台优势包括:
- 卓越运营:云原生应用平台消除了基础设施管理的复杂性,使组织能够专注于创新和核心业务目标,从而提高效率。
- 更易于扩展:云原生应用程序平台通过使用自动化并确保应用程序能够动态扩展以满足需求,同时最大限度地减少人工干预,即使在高峰负载期间也能提供无缝性能,从而提高可靠性和用户体验。
必备特性
该市场的必备特性包括:
- 应用程序运行时服务(包括语言运行时支持)适用于多种应用程序类型,包括 Web 应用程序、移动后端、微服务、AI/ML 模型和分析应用程序,无需配置基础设施或创建和维护自定义容器镜像。
- 云原生应用程序的自动化部署(例如与 DevOps 集成)。
- 自动缩放(负载平衡、可扩展性和多个实例的运行)。
- 应用程序监控和可观察性 —— 支持监控和可观察性以提高服务级别目标;收集生产遥测数据(日志、指标、事件、跟踪)。
- 完全托管服务 —— 供应商(服务提供商)负责云原生应用平台的维护、监控、更新和故障排除。这包括支持、安全、备份和性能优化。它允许用户只专注于可部署在云原生应用平台上的应用程序。
常见特性
该市场的共同特点包括:
- 能够大规模部署、管理、配置和操作容器。
- 财务管理能力,有效控制和优化成本。
- AI 辅助运行时环境。这包括服务的智能配置和编排,以及跨工作负载的有效资源分配。
- IDE 扩展和开发工具,支持软件工程团队为云原生应用平台构建应用程序。
- 无服务器计算无需管理应用程序或服务实例及其分配的计算资源,它可以根据应用程序需求自动扩展,并根据使用的计算时间收费,从而提高效率和成本效益。无服务器计算涵盖多种模型,包括函数即服务 (FaaS) 和无服务器容器编排。
- 自动更新和安全补丁,使云原生应用平台保持最新和安全,不会中断服务,从而降低漏洞风险和维护工作量。
- 多语言部署支持多种编程语言和框架。
- 能够通过标准 API 轻松地与 DBMS、事件代理和缓存等外部服务集成。
- 高可用性和灾难恢复:当本地主机区域发生故障时,通过自动关闭或切换到其他应用程序实例或切换到其他计算区域来确保高可用性。这包括但不限于数据备份和自动故障转移,从而增强应用程序的可靠性和连续性。
评估标准
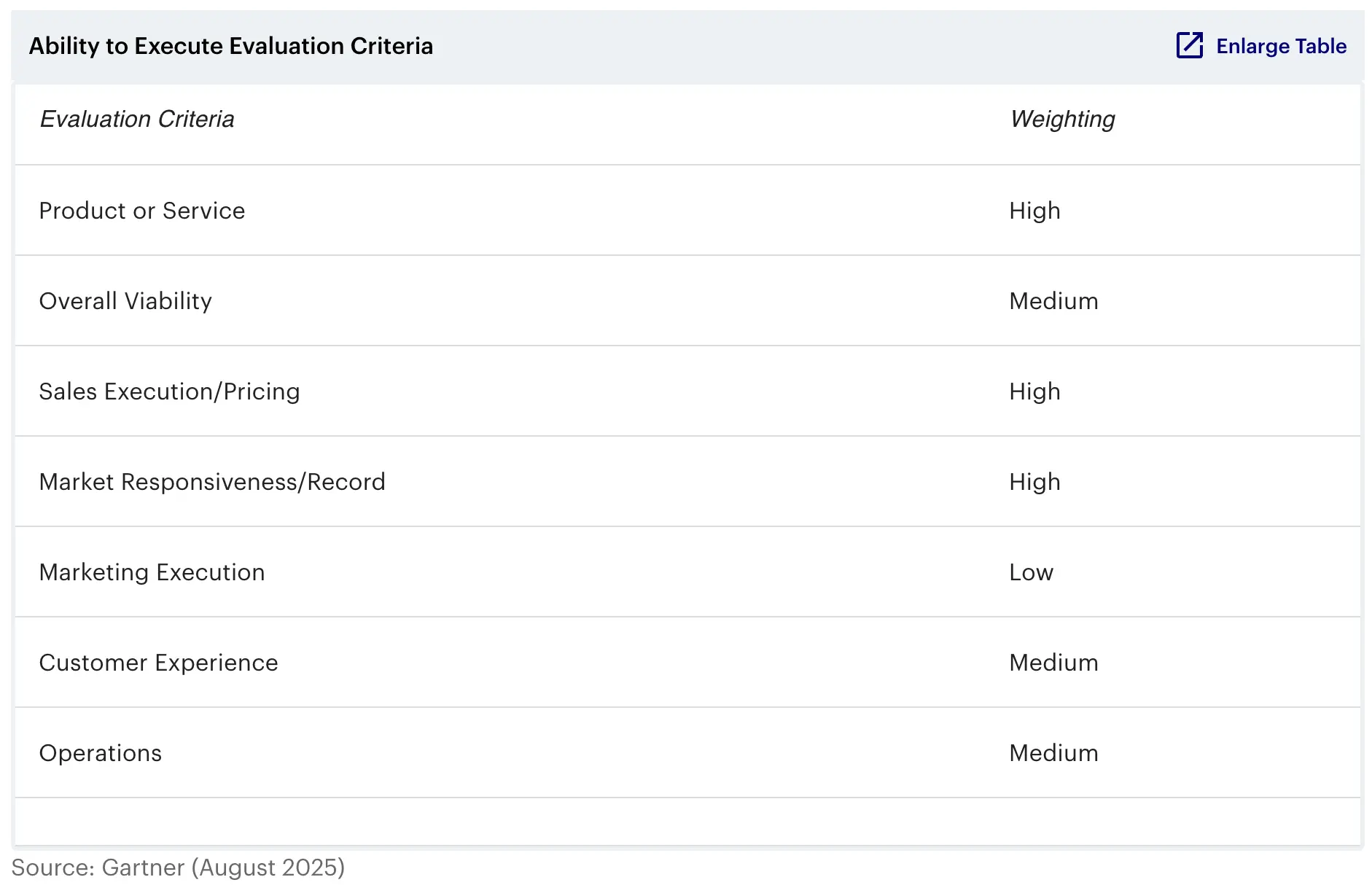
简介
- 产品/服务:此标准评估在特定市场中竞争或服务的核心产品和服务,包括当前的产品和服务能力、质量和功能集,以及是以原生方式提供还是通过 OEM 协议/合作伙伴关系提供。它旨在了解供应商的云应用运行时能力以及对各种编程语言和框架的支持。此外,它还评估云原生应用平台的可扩展性和可用性、提供监控和可观察性功能的能力,以及强大的安全和治理能力 。最后,但同样重要的是,此标准旨在了解供应商提供有效成本管理工具的能力。
- 整体生存力:此标准评估组织的生存力,包括其整体财务状况、业务部门的财务和实际成功,以及持续投资产品的可能性。它寻求有关供应商财务状况的全面信息,包括风险投资资金、盈利能力、经济下行策略、未来 12 个月的投资计划、2024 财年的年收入以及 2025 财年和 2026 财年的预计收入。此外,它还评估客户和市场参与度,重点关注 2024 年和 2025 年前两个季度的客户留存率、按并发用户数计算的最大安装量以及过去 12 个月内的任何相关业务收购。最后,此标准考察组织结构和员工队伍,包括致力于该产品的全职员工数量,以及过去一年中高级管理层的任何变动。
- 销售执行/定价:此标准评估组织在所有售前活动和支持结构中的能力,包括交易管理、定价与谈判、售前支持以及销售渠道的整体效率。它力求深入了解客户群,例如大型企业中使用该产品的五大决策者、当前客户数量、不同行业的细分情况以及与大型企业客户关系的持久性。此外,它还评估定价模式,包括不同定价模式的变体,例如按需付费、长期承诺和固定价格。最后,此标准还会考察与产品相关的任何免费或试用服务,以了解客户获取策略以及潜在客户在做出购买决策之前如何评估产品。
- 市场响应能力和业绩记录:该标准评估企业在机遇发展、竞争对手行动、客户需求演变和市场动态变化的情况下做出响应、调整方向、保持灵活性并取得竞争成功的能力,包括提供商对不断变化的市场需求的响应历史。它寻求有关公司积极参与开源社区的详细信息、为解决方案市场做出贡献的客户和合作伙伴的百分比以及合作伙伴市场的同比增长率。此外,它还评估用于倾听和响应客户需求的机制,并提供有效利用这些机制的具体案例。最后,该标准考察产品针对不同市场的定制程度,以及公司通过早期进入市场并拥有竞争对手现在才赶上的平台功能来进行创新的能力。
- 营销执行:此标准评估旨在传达组织信息、影响市场、推广品牌、提升产品知名度并在客户心中建立积极认同感的方案的清晰度、质量、创造力和有效性。它力求清晰地描述产品如何定位给开发团队、开发者使用该产品的主要原因以及使其在市场中脱颖而出的关键差异化因素。此外,它还评估 2025 年的预计营销预算、过去一年开展的主要营销活动、搜索引擎曝光策略以及在各种在线和社交媒体渠道上与关注者/订阅者的互动策略。最后,此标准考察组织在 2024 年和 2025 年前两个季度赞助或举办的线下、线上/线下混合会议,识别主要竞争对手,并突出组织区别于竞争对手的独特差异化因素。
- 客户体验:此标准评估帮助客户实现预期结果的产品、服务和项目,包括高质量的互动、技术支持和客户支持。它寻求有关开发人员培训计划、入职时间表、成功衡量标准、实施资源和用户培训需求的详细信息。此外,它还评估客户支持结构、专职全职等效人员 (FTE)、支持可用性、服务等级协议 (SLA)、响应时间、近期中断和合作伙伴参与度,包括企业在紧急系统故障时可获得的服务和支持的选项。最后,此标准考察组织的客户成功计划、留存策略、用户社区支持、投资回报率衡量标准以及用于衡量客户成功计划有效性的指标和基准。
- 运营:此标准评估组织履行目标和承诺的能力,重点关注其结构、技能、经验、程序和系统的质量。它寻求有关服务等级协议 (SLA) 的详细信息,包括系统正常运行时间、升级策略、发布时间、企业技术支持全职当量 (FTE) 的增长率,以及用户更新时间选项。此外,它还评估员工培训、合作伙伴员工培训 、全球运营和支持中心、入职速度以及与客户的正式沟通流程。最后,此标准考察托管策略的差异化以及产品包含的认证。
权重
象限简介
| 象限 | 位置 | 简介 |
|---|---|---|
| 领导者 Leaders | 第一象限 | 领导者凭借其提供适合战略性采用的平台和清晰的路线图脱颖而出。他们可以服务于广泛的用例,尽管并非在所有领域都表现出色,也未必是特定需求的最佳提供商,甚至可能根本不支持某些用例。该市场的领导者拥有可观的市场份额和众多可参考的客户。 |
| 挑战者 Challengers | 第二象限 | 挑战者企业具备满足当前部分市场需求的有利条件。他们提供针对特定用例的优质平台,并拥有成功交付的记录。然而,他们尚未足够迅速地适应市场挑战,并且可能缺乏远大的抱负。 |
| 远见者 Visionaries | 第三象限 | 远见卓识者对未来有着清晰的愿景,并在开发独特技术方面投入巨资。他们的平台尚处于发展阶段,并且拥有许多尚未普及的功能。尽管他们可能拥有众多客户,但他们可能尚未充分满足广泛的用例需求,或者业务覆盖的地域范围有限。 |
| 利基市场参与者 Niche Players | 第四象限 | 利基市场参与者或许是特定用例或其运营区域的优秀提供商,但最终应将其视为专业提供商。他们通常无法很好地服务于广泛的用例,或缺乏宏大的发展路线图。有些利基市场参与者可能在邻近市场拥有稳固的领导地位,但在该市场中发展的能力有限。 |
魔力象限
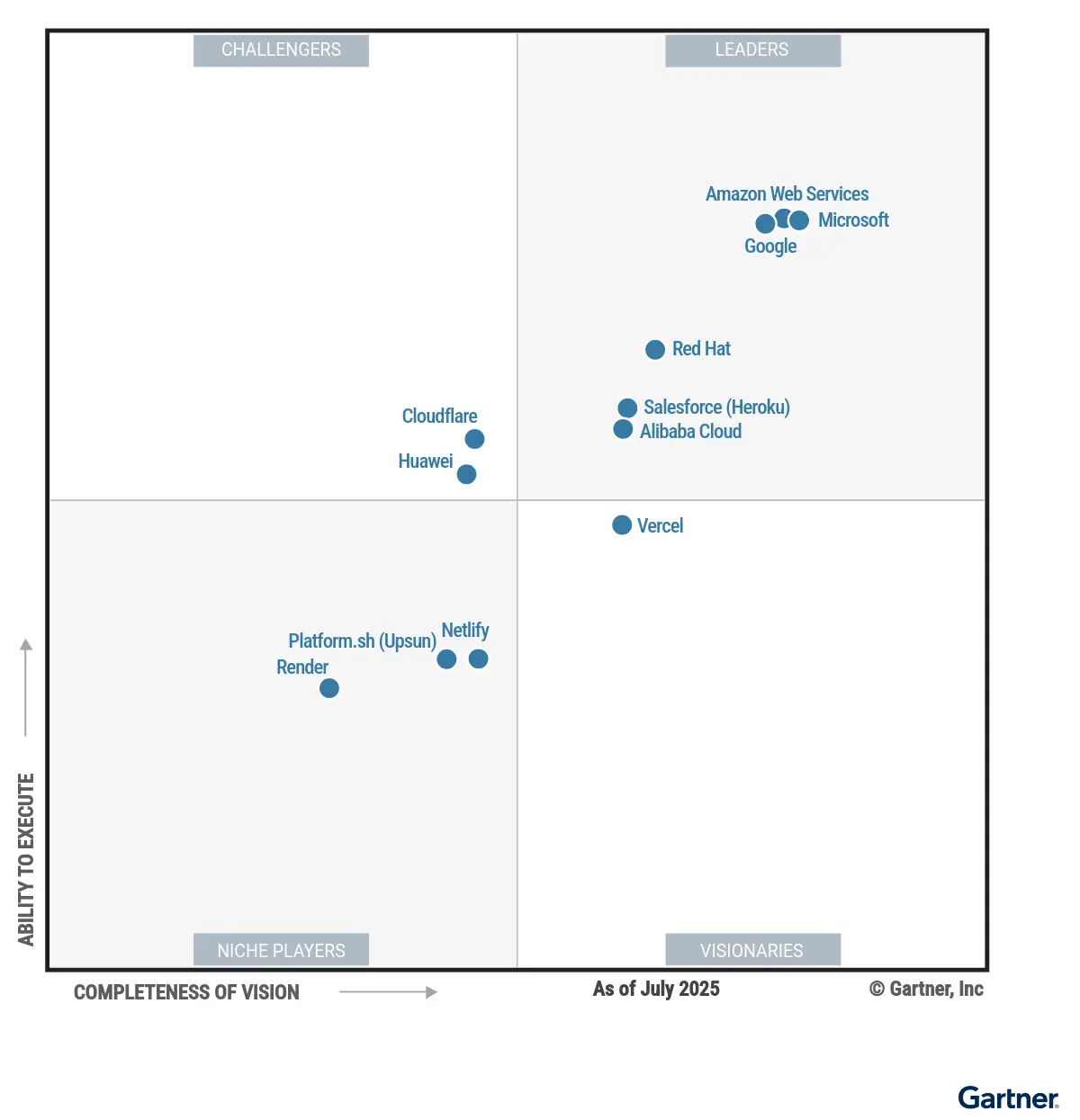
厂商介绍:
阿里云
领导者。
- 简介
它提供无服务器应用引擎 (SAE),支持现代 Web 应用程序和传统云迁移;函数计算,支持无服务器函数;以及容器计算服务 (ACS),一个支持容器的无服务器平台。此外,它还提供其他相关的云平台服务,涵盖 API 管理、AI 应用开发、集成、身份管理、可观察性和数据管理。、
阿里云的业务主要在中国,服务于各行各业、各种规模的客户。该公司正在阿里云生态系统内投资人工智能能力、人工智能开发者工具和计算性能优化。 - 优势
- 产品或服务:阿里云为现代应用程序开发提供全面的平台。开发者可以使用自定义容器或容器计算服务上的预建模板构建和部署现代 Web 应用程序。阿里云还通过集成函数计算、SAE 以及模型工作室和 AI 平台等高级 AI 服务,支持创建 AI 代理和智能应用程序。
- 创新:阿里云平台提供创新功能,帮助客户优化计算成本和性能。对于 AI 工作负载,其无服务器 GPU 提供按需付费、空闲计费、细粒度分配和毫秒级快照等功能。公司还推出了集成 ModelScope 和 Hugging Face 的一键式 AI 应用模板,并推出了用于统一、多供应商 LLM 编排和 API 密钥管理的 AI 网关。
- 市场洞察:阿里巴巴即将推出专注于人工智能驱动平台、无服务器容器解决方案和高级安全工具的产品,展现了其对最新趋势的敏锐洞察。其产品满足了软件工程师的首要需求——可扩展性、无缝的人工智能/机器学习集成和效率,同时支持现代化和全新开发。凭借强大的人工智能开发工具、无服务器编排和实时处理能力,阿里巴巴赋能团队快速构建、部署和扩展智能人工智能代理和应用程序。
- 注意事项
- 销售执行:阿里云主要依赖直销,而非销售合作伙伴或第三方市场。虽然这种方式有助于其在中国获得客户,但却限制了其接触与第三方系统集成商合作的客户的能力。
- 地理战略:阿里云主要在中国运营,并主要专注于中国市场。虽然该公司已开始向美国、欧洲和南美扩张,但这些地区的客户在评估阿里云时,应考虑贸易壁垒的增加、政策不确定性和地缘政治风险。
- 产品策略:阿里云平台缺乏原生提供的企业系统(例如 Microsoft、Oracle、Salesforce、SAP)应用连接器。这些连接器集成主要依赖于 Dapr 等第三方解决方案。
Amazon Web Services
领导者。
- 简介
它提供 AWS Lambda、AWS App Runner、AWS Amplify 和 AWS Elastic Beanstalk。AWS 还提供其他相关的云平台服务,用于 API 管理、AI 应用程序开发、集成、身份管理、可观察性和数据管理。这些服务支持无服务器功能、原生代码、容器和云迁移用例。
AWS 的业务遍布全球,服务于各个行业、各种规模的客户。该公司正在投资人工智能 (AI) 能力,持续强化其 AI 开发者工具,并在 AWS 生态系统内优化计算性能。 - 优势
- 产品或服务:AWS 的云原生应用平台为现代应用程序开发提供了灵活的选项。这些选项包括用于无服务器计算的 AWS Lambda、用于容器化 Web 应用程序的 AWS App Runner、用于前端 Web 和移动应用程序的一系列工具和服务的 AWS Amplify,以及用于支持云迁移的 AWS Elastic Beanstalk。AWS 通过将计算产品与 Amazon Bedrock 集成,使用户能够构建 AI 代理和应用程序。
- 创新:AWS 最近推出了对 Python 和 .NET 的 Lambda SnapStart 支持,这显著缩短了其无服务器平台的冷启动时间,而无需额外配置资源。在 AI 领域,AWS 正在通过 Amazon Bedrock 等产品赋能开发者构建和扩展智能应用程序。AWS 同时支持基于 CPU 和 GPU 的工作负载,确保各种 AI 应用程序都能获得强大的性能和可扩展性。
- 市场洞察:AWS 支持主流语言和框架,并支持函数、容器或原生代码的部署,展现了其对 AI 开发最新趋势的洞察。广泛的计算选择,加上 Amazon SageMaker(用于 AI/ML 训练和管理)和 Amazon Bedrock (用于 LLM 推理)等服务的原生集成,使软件工程团队能够高效地构建、部署和管理 AI 代理。
- 注意事项
- 平台复杂性:AWS 提供众多功能重叠的服务。客户需要深入了解 AWS 平台服务,才能选择符合自身需求的服务。例如,在 Amazon ECS 和 AWS Fargate 或 AWS Lambda 之间做出选择可能会令人困惑,因为每项服务都针对不同的用例和运营模型而设计,但这些区别并不明显。
- 运营:AWS 不提供正式的最终用户延迟保证,也不会协商超出其公开声明的正常运行时间 SLA (例如 Lambda 的 99.95%)。用户应验证 AWS 是否能够满足其正常运行时间和延迟要求。
- 产品策略:AWS Lambda 是 AWS 独有的技术,因此 AWS Lambda 客户需要重新设计其应用程序,然后才能将其迁移到其他云提供商。不过,AWS 提供了广泛的云平台服务,可以减少使用多个云平台的需求。
Cloudflare
挑战者。
- 简介
它提供 Cloudflare 开发者平台,该平台包含 Cloudflare 连接云中的 Pages、Workers 和 Workers AI 服务。Cloudflare 使用户能够构建由 AI 推理服务支持的无服务器应用程序,并将其部署到 Cloudflare 无服务器基础设施中分布在全球的 330 多个接入点。
Cloudflare 的业务遍布全球,其开发者平台的客户往往是各个行业的中型企业。Cloudflare 正致力于扩展其开发者平台的功能,以支持 AI 应用的开发。 - 优势
- 销售执行/定价:Cloudflare 创新的基于 CPU 的定价模型确保客户仅按有效计算时间付费。例如,当客服人员等待 LLM 或其他 API 的响应时,客户无需付费。此定价模型为 AI 和事件驱动型工作负载提供了一条经济高效的途径。
- 地理战略:Cloudflare 利用其庞大的边缘站点网络在全球范围内提供低延迟、高性能的计算服务,建立了强大的市场影响力。其强大的安全产品,包括 DDoS 防护、Web 应用程序防火墙 (WAF)、机器人程序管理、API 安全和零信任访问 (SSE/SASE),使其成为安全、可扩展互联网基础设施领域值得信赖的领导者。
- 创新:Cloudflare 通过 Workers AI 快速扩展了其平台,在边缘实现了 GPU 驱动的机器学习和 LLM。2025 年第三季度,Cloudflare 将扩大其容器平台的访问权限,该平台已在部分企业投入生产,以支持更多容器化工作负载。Workers 针对 JavaScript 进行了高度优化,可提供近乎即时的冷启动和高效的边缘执行。
- 注意事项
- 产品或服务:Cloudflare 开发者平台缺乏对 Java 和 .NET 的原生支持,但提供对 JavaScript、Python、Rust 和 WebAssembly 的原生支持。这限制了它对于那些希望在这些成熟且知名的平台上直接迁移旧版企业应用程序或继续构建云原生应用程序的组织而言的适用性。不过,Cloudflare 的容器平台正在解决这个问题,该平台于 2025 年 6 月发布,目前处于 Beta 阶段。
- 产品策略:Cloudflare 尚未提供本研究中领导者通常提供的一些高级功能和集成。该平台缺乏一个全面的预建连接器市场以及深度 SaaS 或遗留系统集成,这可能需要客户付出额外的努力。
- 市场理解:Cloudflare 对边缘计算和无服务器架构的关注与现代发展趋势相符,但许多组织仍然依赖于难以迁移到边缘原生环境的遗留系统。Cloudflare 对遗留工作负载的支持有限,这可能会降低其对需要此类支持的组织的吸引力。
领导者。
- 简介
它提供 Google Cloud Run,一个支持函数和容器的无服务器平台;Firebase,支持现代 Web、移动和全栈应用程序;以及 Google App Engine,支持云迁移。它还提供众多服务, 支持 API 管理、AI 应用程序开发、集成、 身份管理、可观察性和数据管理。谷歌支持大多数语言和后端框架,而 Google Cloud 构建包则简化了容器的创建。
谷歌的业务遍布全球,服务于各个行业、各种规模的客户。该公司正在投资强化其开发者工具,并优化其生态系统内的计算性能。 - 优势
- 产品或服务:谷歌的云原生应用平台为现代应用开发提供了灵活的选项,包括适用于无服务器计算和容器化工作负载的 Cloud Run,以及适用于现代 Web、移动和全栈应用的 Firebase。这些产品还通过与 Vertex AI(用于模型训练和推理)和 Gemini(用于 AI 开发者工具)集成,使团队能够构建、运行和编排 AI 代理和应用程序。Google App Engine 支持更传统的三层架构,并提供了一个可直接迁移的平台。
- 市场洞察:Google Cloud Run 支持多种编程语言并提供量身定制的构建包支持,为开发者提供了灵活性和选择。这有助于避免供应商锁定,并支持应用程序在任何支持容器的云环境中迁移。
- 创新:谷歌持续推出平台创新,例如用于可扩展 AI/ML 推理的 Cloud Run GPU;用于事件驱动架构的 Eventarc,拥有超过 150 个原生事件源;以及用于基于 SQL 的强大大规模遥测数据分析的 Log Analytics。此外, Gemini Cloud Assist 为开发和运营提供 AI 驱动的辅助,帮助客户加速创新并简化应用程序生命周期管理。
- 注意事项
- 产品策略:由于高度集成的产品组合,谷歌的工作流程比其他领先的云平台更具规范性。对于习惯于通过组合多种云服务来构建复杂定制解决方案的客户来说,谷歌这种固执己见的做法可能会带来一些限制。
- 运营:Google 不提供正式的最终用户延迟保证,也不会协商超出其公开声明的正常运行时间 SLA(例如 Cloud Run 的 99.95%)。客户和潜在客户应验证 Google 是否能够满足其正常运行时间和延迟要求。
- 地理战略:谷歌目前在中国缺乏专用数据中心和云可用区,这阻碍了其为中国客户提供本地支持和满足数据驻留要求的能力。
Huawei
挑战者。
- 简介
它提供云应用引擎 (CAE)、ServiceStage 和 FunctionGraph,为现代应用程序开发提供平台,并为 Web 应用程序和后端服务提供运行时环境。华为的云原生应用平台支持多种语言、后端框架以及容器和原生代码的部署。
华为的业务主要在中国,并在东南亚、拉美和欧洲、中东和非洲地区也有一些业务。其 CAE 客户往往是各个行业的中型企业。华为正在扩展其服务组合,并将 AI 功能集成到其平台中,以提升开发者体验和运营效率。 - 优势
- 创新:华为在 CDN 边缘节点上推出了基于 WebAssembly 的无服务器功能,实现了快速、安全和轻量级的边缘部署,并为 LLM 添加了原生计算能力。华为还推出了 TaurusDB,这是一款兼容 MySQL 的云原生数据库,具有计算和存储分离的特性,可支持每秒数百万次的查询,满足高要求应用程序的需求。
- 整体可行性:华为持续将至少 23% 的收入再投资于研发。这笔巨额投资支持了其云服务产品组合的持续发展。尤其注重通过基于云和 CDN 的部署模型,增强 CAE 作为无服务器应用平台的功能、ServiceStage 作为平台工程中心的功能,以及 FunctionGraph 作为云边混合功能的功能。
- 市场洞察:华为洞察行业向 AI 代理工作流的转变,扩展了其 CAE 和 FunctionGraph 服务,以原生支持 AI 工作负载,包括部署在边缘的工作负载。这使得华为能够满足客户在 AI 驱动和边缘原生应用场景中的新兴需求。
- 注意事项
- 产品策略:华为的集成产品组合具有规范的工作流程,可能比本研究中的其他平台更具限制性。虽然华为的自主平台有利于追求效率的组织,但希望获得定制解决方案最大灵活性的客户可能会发现华为的方法适应性较差。
- 地理战略:华为主要专注于中国市场。虽然华为已开始向欧洲和南美扩张,但经济制裁限制了其进入美国和其他一些市场。客户应确保华为能够支持其所在地区的部署,并验证其本地服务支持的成熟度。
- 运营:该平台目前在开发者社区中的知名度和影响力有限,这可能会影响用户参与度和生态系统的增长。客户和潜在客户应评估平台当前的社区支持水平和生态系统成熟度是否符合其需求。
Microsoft
领导者。
- 简介
它提供 Azure 应用服务以支持云迁移,提供 Azure Functions 和 Azure 容器应用以支持函数和容器,以及 Azure 静态 Web 应用以支持多种 Web 框架和语言。微软还提供其他相关的云平台服务,用于 API 管理、AI 应用程序开发、集成、身份管理、可观察性和数据管理。
微软的业务遍布全球,服务于各行各业各种规模的客户。该公司正在投资 AI 推理能力和 AI 原生开发者体验,并优化计算性能和可扩展性。 - 优势
- 产品或服务:微软为现代应用程序开发提供了灵活的选项,包括用于无服务器容器和微服务的 Azure 容器应用、用于无服务器事件驱动计算机的 Azure Functions 以及用于构建现代 Web 应用程序的 Azure 静态 Web 应用。微软通过将 Azure 容器应用和 Azure Functions 与 Azure AI Foundry 集成,使用户能够构建 AI 代理和应用程序。
- 创新:微软持续推出创新功能,尤其是在 Azure 容器应用中。其动态会话提供对沙盒环境的安全访问,以便独立于其他应用程序运行代码;其无服务器 GPU 支持按需运行 AI 和 ML 工作负载,无需基础设施管理。Azure 容器应用还与 Azure AI Foundry 原生集成,用于 AI 模型推理。
- 市场洞察:微软对人工智能发展的关注体现了其对当前市场趋势的敏锐洞察。借助适用于代理工作流的 Azure AI Foundry,客户可以高效地构建和部署人工智能代理及应用程序。
- 注意事项
- 运营:微软不提供正式的最终用户延迟保证,也不会协商超出其公开声明的正常运行时间 SLA (例如,Azure 容器应用的正常运行时间 SLA 为 99.95%)。客户和潜在客户应验证微软是否能够满足其正常运行时间和延迟要求。
- 平台复杂性:微软提供众多功能重叠的服务。客户需要对 Azure 平台服务有深入的了解,才能选择符合自身需求的服务。例如,在容器应用和 Azure Kubernetes 服务 (AKS) 之间做出选择,或者在 Azure Functions 上运行容器可能会令人困惑,因为每项服务都是为不同的用例和运营模型而设计的。但这些区别并非显而易见。
- 产品策略:Azure Functions 已针对 Microsoft Azure 运行进行了优化,因此如果客户希望将其应用程序迁移到其他云提供商的平台,则需要重新设计其应用程序。不过,微软提供了广泛的云平台服务,这可能会减少使用多个云平台的需求。
Netlify
利基市场参与者。
- 简介
它提供用于构建和部署 Web 应用程序的 Netlify Core、用于可视化编辑 Web 内容的 Netlify Create 以及用于统一应用程序内容的 Netlify Connect。Netlify 提供各种前端 Web 应用程序框架和模板,这些框架和模板构成其可组合 Web 平台的一部分,用于支持现代 Web 应用程序的交付。Netlify 还提供其他相关的云平台服务,例如 Blob 存储、KV 存储和持久边缘缓存,旨在为开发人员提供跨前端架构的更大灵活性。
Netlify 的业务主要在美国和欧洲。其客户往往是各行各业的中小型企业。该公司正在投资简化开发流程,以提升开发者体验 。 - 优势
- 产品或服务:Netlify Core 提供支持 AI 的部署辅助和持久的边缘缓存,Netlify Connect 提供具有可扩展 GraphQL API 的联合数据层,Netlify Create 提供可视化/AI 辅助的内容编辑。Netlify 还提供网站可视化编辑,并支持和推广可组合 Web 方法(以前称为 Jamstack),这是一种现代前端架构风格。
- 市场洞察:Netlify 的战略方向与云原生平台市场的发展相契合。Netlify 计划持续改进其平台,以支持更广泛的开发者角色管理智能代理增强型工作流程,并重点关注代理体验 (AX),以简化编排并抽象化基础架构的复杂性。Netlify 正在投资开发针对 AI 原生应用程序的可观察性工具,这些工具能够洞察代理行为、流量和性能。
- 销售执行/定价:Netlify 提供灵活的集成包,方便用户快速构建应用程序。Netlify 采用分层定价模式,提供免费的专业版和企业版套餐,潜在客户可以低价甚至免费试用该平台,然后根据自身组织的需求选择最合适的套餐。Netlify 正在从传统的基于基础设施的定价模式转向基于价值的套餐模式,从而更好地适应快速原型设计。
- 注意事项
- 产品策略:Netlify 并非设计用于托管基于 Java 或 .NET 构建的容器化微服务架构。然而,它提供了后端功能,例如无服务器函数以及与框架(例如 Next.js、Astro 或 Remix)的兼容性,这些功能支持与前端相关的应用程序和 AI 原生工作负载的现代后端用例。
- 营销策略:平台可见性仍然是一个挑战;人们仍然认为 Netlify 仅适用于静态网站或前端开发人员,这限制了与企业平台工程团队的互动。为了克服这个问题,Netlify 正在通过增加开源贡献、参与开发者活动以及发布技术博客来加强社区参与。
- 总体生存能力:Netlify 是一家由风险投资支持的供应商,其市场中充斥着众多资金雄厚的大型竞争对手。虽然 Netlify 的规模小于一些企业级竞争对手,但它已获得超过 2 亿美元的风险投资。为了在市场上保持竞争力,Netlify 需要继续扩大市场份额,并拓展到南美、亚太地区(包括中国)和中东等新地区。
Platform.sh (Upsun)
利基市场参与者。
- 简介
它提供 Upsun,这是一个以开发者为中心的平台,使用基于 Git 的部署流程支持各种应用程序框架。Upsun 还提供数据库、缓存和搜索的托管服务,并集成了应用程序性能监控功能。Platform.sh 支持跨 AWS、Azure、Google Cloud、IBM 和 OVHcloud 的多云部署。
Platform.sh 的业务主要集中在北美、欧洲和亚太地区。其客户通常是中型网络代理机构以及各行各业大型企业的业务部门。该公司正在投资提供财务激励措施,以鼓励在低碳排放地区部署项目。 - 优势
- 产品或服务:Platform.sh 提供无与伦比的灵活性,让客户能够跨区域使用多云。Upsun 是一个自助服务平台,支持跨所有主流云提供商的可扩展架构。它还通过最大限度地减少供应商锁定,增强了多云的可移植性。
- 市场理解:Platform.sh 秉承以开发者为中心的理念,提供高度灵活的 Git 解决方案。Upsun 提供所有应用程序代码、数据和服务的全栈项目克隆功能,使客户能够更高效地复制环境。它使团队能够高效地扩展单个应用程序,优化资源利用率,而不会影响整体系统性能。
- 营销策略:Platform.sh 将自己定位为可持续发展和成本效益的倡导者,这引起了许多组织的共鸣。其碳足迹建模报告可帮助客户了解其部署的影响。Upsun 通过其 “绿色区域折扣”计划 ,为在低碳排放地区部署项目提供财务激励。
- 注意事项
- 创新:Platform.sh 的产品路线图包含有限的 AI 创新,例如 MCP 服务器,以增强其平台功能。该公司的主要重点是提高其现有平台的弹性以及基于 LXC 的容器运行时功能。
- 营销执行:Platform.sh 面临着持续的挑战,即证明其集成的端到端多云平台比使用不同工具构建的定制解决方案具有更大的价值和简单性。
- 地理策略:Platform.sh 主要面向美国和欧洲的客户,也有一些亚太地区的客户。它在其他地区的实施和托管支持有限。潜在客户应确认 Platform.sh 是否能够有效地服务其所在地区的组织。
Red Hat
领导者。
- 简介
红帽是该魔力象限的领导者。它为众多不同的超大规模企业提供 Red Hat OpenShift 云服务 :AWS 上的 Red Hat OpenShift 服务 (ROSA)、Microsoft Azure Red Hat OpenShift (ARO) 以及 Google Cloud Platform 上的 Red Hat OpenShift Dedicated。Red Hat OpenShift 也提供 IBM Cloud 服务,并且可作为自主管理的本地软件进行部署。
红帽的业务遍布全球,服务于各种规模、各个行业的客户。该公司正在投资扩展对 AI 工作负载的支持,利用托管控制平面等功能优化成本,并拓展区域可用性和实例类型。 - 优势
- 产品策略:红帽为客户提供高度灵活的平台运行环境;在云服务提供商和本地平台之间相对轻松的移植性;以及在其自有平台上提供低摩擦的集成服务。OpenShift 提供多种托管语言运行时和 DevOps 工具,以支持函数、容器和原生代码的部署。
- 市场洞察:红帽灵活的多云战略表明,它认识到云原生市场正在快速发展,以支持人工智能驱动的应用。Kubernetes 持续演进为一个全面的应用平台,是其转型的关键环节。红帽还认识到,通过将 IBM Watson Code Assistant 与 Red Hat Ansible Lightspeed 平台集成,可以提高开发人员的工作效率。
- 商业模式:红帽与 AWS、谷歌云和微软 Azure 建立了牢固的合作伙伴关系,共同设计和运营 OpenShift。这使得客户可以直接从超大规模提供商处购买,收到单一账单,并充分利用云承诺支出。红帽还打造了一个由独立软件供应商、系统集成商和行业合作伙伴组成的广泛平台生态系统和市场,客户可以在此购买 OpenShift。
- 注意事项
- 销售策略:红帽与 AWS、谷歌云和微软 Azure 等超大规模云提供商合作,但同时也与它们竞争。这种动态鼓励客户在红帽的云原生应用平台和这些云提供商直接提供的解决方案之间进行选择,找到最符合自身需求的解决方案。
- 产品或服务:Red Hat 的托管服务产品与超大规模云原生服务的集成度不如超大规模云厂商自身的 PaaS 产品。例如,ARO 与 Microsoft Azure 云服务的集成度不如 Azure App Service、Azure Functions 和 Azure Container Apps 的集成度高。
- 营销执行:Red Hat 面临的持续挑战是证明其集成的端到端多云平台比使用不同工具构建的定制解决方案具有更大的价值和简单性。
Render
利基市场参与者。
- 简介
它提供了一个云原生应用平台,可自动化运维角色,使开发人员能够专注于构建代码,而不是设置云基础设施。Render 支持 Docker 容器和基础设施即代码 (IaC) 功能。
Render 的业务主要在北美,其客户往往是各个行业的中小型企业。该公司正在投资合规性和认证等企业优先事项,扩大其地理覆盖范围,并更加注重开发人员体验。 - 优势
- 市场洞察:Render 完美契合中小型企业的需求。其高度集成的平台使客户能够交付云应用程序,并提供具有自动扩展和高可用性的在线体验。Render 的产品路线图清晰地展现了对市场方向的理解,包括 AI 增强调试、用于 AI 代理的持久工作流引擎以及用于高级应用程序的 GPU 计算等功能。
- 产品策略:Render 的 Blueprint 提供原生 IaC 功能,可自动重新部署任何受影响的服务以应用新配置。这消除了用户了解基础架构的需要。客户将受益于这种简化的开发体验。
- 市场响应能力:Render 在去年推出了一系列新功能,直接解决了客户最关心的问题。这些功能包括统一账户管理、OpenTelemetry 流式传输到其他可观察性工具以及符合 HIPAA 标准的账户。
- 注意事项
- 创新:Render 缺乏竞争对手平台上常见的 AI 功能,例如访问 LLM 或支持 AI 代理的运行时环境。Render 计划在其产品路线图中弥补这些功能方面的不足。
- 地理战略:Render 在美国和欧洲以外的客户很少,但计划扩展到亚太地区。该公司目前提供英语支持,但其国际覆盖范围和基础设施能力足以应对全球部署。
- 总体生存能力:Render 是一家由风险投资支持的供应商,其市场中有许多资金雄厚的大型竞争对手。虽然规模小于一些企业级同行,但 Render 已获得超过 1.57 亿美元的风险投资。为了保持生存,它需要扩大市场份额、拓展新区域并交付新功能。
Salesforce (Heroku)
领导者。
- 简介
它提供的 Heroku 平台支持使用构建包和容器部署原生代码。Heroku 还提供其他相关的云平台服务,用于数据管理、可观察性和身份管理,以及通过 Salesforce 提供的附加服务,用于集成平台/API 管理(MuleSoft)、AI 代理(Agentforce)和数据管理(Data Cloud)。
Heroku 的业务遍布全球,拥有来自各个行业、规模各异的客户。Heroku 持续专注于云原生和多语言应用开发,同时深化与 Salesforce 生态系统的整合,以增强 SaaS 功能。 - 优势
- 产品策略:Heroku 通过集成支持更多 Agentforce 用例,简化了通过 Heroku AI 部署自定义 AI 应用程序的过程,并通过基于 Kubernetes 的架构(从用户抽象而来)提高了可扩展性和可靠性。新增的 .NET 和 Jupyter Notebook 支持增强了其对企业开发者的吸引力,而通过 AppLink 与 Salesforce Data Cloud 和 Agentforce 更紧密的集成则增强了其功能。Heroku Connect 还支持无缝访问实时客户数据。
- 客户体验:Heroku 持续投入,致力于提升易用性、扩展教学内容并增强支持。开发者将受益于更新的文档、全新的 AI 教程以及 Heroku AI 和 .NET 支持等新兴功能的简化入门流程。
- 营销策略:Heroku 扩展了其营销策略,使其与更广泛的 Salesforce AI 战略保持一致,并进一步强化了开发者营销。其宣传重点突出 Heroku 的 AI 创新、降低运营复杂性以及提高开发者生产力。这种方法增强了 Heroku 在商业和技术决策者心目中的信誉。
- 注意事项
- 产品或服务:Heroku 没有内置专门的无服务器功能支持。虽然开发人员可以使用轻量级测功机或外部工具模拟无服务器行为,但这不如真正的无服务器架构高效、可扩展且经济实惠。因此,Heroku 更适合长期运行的应用程序,而不是事件驱动的工作负载。
- 销售策略:虽然 Heroku 是 Salesforce 的一部分,但它的价值并不总是能够在更广泛的 Salesforce 交易中得到有效整合或传达,从而导致错失交叉销售机会。
- 销售执行/定价:虽然 Heroku 的前期定价简单明了,但其按 dyno(计算单元)的固定定价模式灵活性较低。缺乏精细的基于使用量的计费方式,使得团队更难为复杂的微服务架构优化成本,特别是与那些拥有更高级计费和监控功能的平台相比。
Vercel
远见者。
- 简介
它提供了一个以 Web 为中心的平台,支持多种 Web 框架和语言。Vercel 平台提供边缘计算功能 ,包括 CDN、 WAF、全局运行时和缓存功能。Vercel 还支持自动部署和自动扩展功能。
Vercel 的业务主要在美国和欧洲,其客户往往是各行各业的中小型企业。Vercel 正在投资以前端为中心的创新,并辅以人工智能技术,以改善 Web 应用程序的性能、架构和开发人员体验,并提高其平台的稳定性和可扩展性。 - 优势
- 产品或服务:Vercel 支持 40 多个 Web 框架,并使用框架定义的基础架构进行复杂的前端部署。其嵌入式 AI 产品(例如 v0 和 AI SDK)使客户能够更快地开发和部署 AI 应用程序。Gartner Peer Insights 调查的受访者一致称赞其易用性、可靠性和性能,这有助于提高开发人员的生产力并缩短产品上市时间。
- 创新:Vercel 率先推出 Fluid 计算,允许多个调用共享单个函数实例,从而减少空闲计算时间并降低成本。Vercel 还计划投资 AI 代理服务市场,并开发内部 AI 代理,以优化平台并提升开发者体验。
- 市场洞察:Vercel 的框架定义基础架构及其深度集成的 AI 功能清晰地表明,其清楚地认识到云原生应用平台市场正快速向 AI 原生工作流演进。Vercel 正有效地将自身定位为一个高性能平台,用于构建和运行支持 AI 的 Web 应用程序。
- 注意事项
- 产品提供策略:Vercel 不支持容器,优先考虑前端和 AI 网关技术。对于更复杂的微服务架构(主要用 Java 或 .NET 编写),Vercel 客户应单独采购后端,或依赖现有后端,并使用 Vercel Functions 进行集成。
- 营销执行:Vercel 持续面临的挑战是改变人们认为强大的基础设施必须使用低级工具手工构建的观念。克服拥有传统架构的组织的这种疑虑,以及对迁移风险、工作流程变更和再培训的担忧,是一个巨大的挑战。
- 客户体验:Gartner Peer Insights 的调查受访者表示,Vercel 的基于角色的访问控制 (RBAC) 和可观察性有限,并且该平台缺乏强大的后端工具。由于 Vercel 高度重视 JavaScript/Typescript 生态系统,客户可能还会发现很难从传统的 Java 和 .NET 技术栈迁移。
纳入与移出
厂商变动
新增阿里云,移出 Mia-Platform。
纳入与移出标准
为了有资格纳入这个魔力象限,每个供应商都需要满足以下标准:
- 市场参与
- 满足云原生应用平台的市场定义。
- 所有符合此纳入标准且在本魔力象限和关键能力研究中评估的功能,必须自 2025 年 4 月 1 日起向所有客户全面开放,并有完整记录。针对特定客户的定制开发不符合条件。“全面开放”是指产品或服务以面向公众的价格表/卡的形式提供,供客户直接购买。提供商必须能够提供其云原生应用平台定价页面的链接。
- 将解决方案直接销售给付费客户,无需他们寻求专业服务。供应商必须至少为这些功能提供一线支持,包括使用捆绑的开源和闭源软件。
- 展示有效的产品路线图以及解决方案的上市和销售策略。
- 提供电话、电子邮件和/或网页客户支持。他们必须提供英语(作为产品默认语言或可选本地化语言)的合同、控制台/门户、技术文档和客户支持。
- 平台功能
云原生应用平台必须为应用程序提供基于云的托管应用运行时环境,并提供集成功能来管理应用程序或应用组件的生命周期 。它们通常还必须支持分布式应用部署,并支持云式运维(例如弹性、多租户和自助服务),而无需基础设施配置或容器管理。云原生应用平台必须是企业级的,并致力于为客户提供高可用性和灾难恢复技术支持,服务于企业级项目。
所选平台必须使用其本机运行时环境支持现代全栈框架,而无需自定义包装器和兼容层。 - 规模
供应商必须在 2025 年 5 月 31 日之前满足以下尺寸要求组合之一:- 过去 12 个月内,其云原生应用平台的平台许可和/或订阅收入至少为 4000 万美元,并且其云原生应用平台产品至少有 100 个付费企业客户组织(至少有 1000 名员工),不包括其他相关产品。
- 过去 12 个月内,其云原生应用平台的平台许可和/或订阅收入至少为 1500 万美元,且其云原生应用平台的收入和/或客户群的复合年增长率至少为 50%,不包括其他相关产品。
供应商必须在以下三个或更多地区拥有直接客户(即不通过经销商): - 北美
- 南美
- 欧洲
- 中东和非洲
- 亚太
此外,供应商必须在 Gartner 为本魔力象限确定的客户兴趣指标(CII)中排名前 20 位。
值得关注的厂商
-
博通
博通提供 VMware Tanzu 平台,这是一款以软件产品形式出售的云原生应用平台,客户可以在本地或自行选择的云基础架构上自行操作。VMware Tanzu 平台提供构建包工具和部署自动化功能,用于创建和配置容器,并将其部署到基于开源 Cloud Foundry 的弹性应用程序运行时中。该平台原生支持多种语言,包括 Go、Java、JavaScript、.NET、PHP、Python 和 Ruby。博通通过提供代理的公共和私有服务绑定(包括模型、MCP 服务器、企业 API 以及矢量数据库、缓存、流媒体和消息传递服务)来帮助用户构建 AI 代理。博通不符合本次研究的条件,因为它不提供托管应用程序运行时,而是依赖于现有的公共或私有 IaaS 服务。 -
Mia-Platform
Mia-Platform 帮助企业支持开发者自助服务,简化云原生和云优化应用的部署和管理。该平台是支持 DevOps 的技术能力和流程的统一中心。Mia-Platform 的业务主要在欧洲,其客户往往是各行各业的大中型企业。该公司正在投资改进其开发者工具、部署自动化功能和运行时性能优化,以使软件工程师能够专注于应用程序开发。由于 Mia-Platform 未达到收入和收入增长的标准,因此未纳入本次研究。 -
Clever Cloud
Clever Cloud 提供云原生应用平台,原生支持并运行超过 15 种编程环境,包括 JavaScript、PHP、.NET、Java、Python、Rust 等,以及自动扩展容器。Clever Cloud 提供托管服务市场,涵盖数据库、消息队列、存储、身份管理、AI 服务,并内置对持续交付、监控和云迁移的支持。这些服务支持原生代码、容器和云迁移用例。由于 Clever Cloud 未达到云原生应用平台细分市场的收入和收入增长标准,因此未纳入本研究。 -
Fastly
Fastly 的边缘云平台赋能用户在边缘构建、交付和保护无服务器应用程序。除了计算服务外,Fastly 还提供一系列相关的云服务,包括应用程序安全数据存储、边缘可观测性、AI 和 CDN 解决方案。这些服务同时支持原生代码和无服务器功能,为开发者提供灵活性。Fastly 未包含在本次研究中,因为它未达到云原生应用平台边缘计算细分市场的收入和收入增长标准。
💁♀️ 专题五 产品/方案介绍
1. k8sgpt:用于扫描 Kubernetes 集群、诊断和分类问题的工具
简介
k8sgpt 是一种用于扫描 Kubernetes 集群、诊断和分类问题的工具,使用简单的英语。它将 SRE 经验编入分析器中,并帮助提取最相关的信息,用 AI 来丰富它。
该工具于 2023 年春季推出,并于同年年底作为沙盒项目被 CNCF 接受,旨在帮助解决各种与 Kubernetes 相关的问题。
作用
K8sGPT 扫描 Kubernetes 集群,帮助诊断问题并提供修复建议。为此,它利用 SRE(站点可靠性工程)知识(例如,如何提取有关当前 Kubernetes 集群状态和现有问题的所有必要信息)以及 GenAI 模型来处理这些数据,并为解决问题提供有用的指导。
假设集群中有一个待处理的 Pod。运行 K8sGPT 可以让您获取问题的详细分析、可能原因列表以及后续故障排除和修复的命令。它还会为提示添加上下文,让您可以像与专家交流一样与其进行聊天。当然,您可以使用像 ChatGPT 这样的现成在线聊天机器人,但 K8sGPT 可以显著简化这一流程。
安装方式
- 安装为一个简单的控制台工具。可以通过命令调用它并获得响应。
- 安装为 Kubernetes 集群操 operator。在这种情况下,K8sGPT 将在后台运行,并将结果提供给结果类型的专用 CR(自定义资源)。当需要保留扫描历史记录以及希望自动扫描无法手动捕获的问题(例如在控制台模式下)时,此选项非常有用。
主要功能
- analyze 帮助发现 Kubernetes 集群中的问题
- cache 用于处理分析结果的缓存
- filters 允许设置过滤器来分析 Kubernetes 资源
- explain 寻求人工智能的帮助
拓展阅读
K8sGPT for Kubernetes troubleshooting: How AI helps in different cases
2. Heroku:用于部署、管理和扩展应用程序的 AI PaaS
简介
Heroku 是一个云应用平台 (PaaS),旨在简化 AI 应用的构建、部署、管理和扩展。
特点
- Heroku 运行时
Heroku 在 dynos 中运行您的应用程序 - 智能容器,在可靠、完全托管的运行时环境中执行。 - Heroku PostgreSQL
Heroku 值得信赖、安全且可扩展的完全托管 PostgreSQL 数据库即服务,针对开发人员进行了优化。 - Heroku 键值存储
您喜爱的 Redis 具有更强大的开发人员体验,由 Heroku 的运营专家全面管理和提供服务。 - 可扩展性
使用 Heroku 可以立即扩大或缩小规模,从小型业余项目到黑色星期五准备就绪的企业电子商务网站。 - Heroku 元素
使用附加组件扩展您的应用程序,使用构建包自定义您的语言堆栈,并使用按钮启动您的项目。 - Heroku 团队
使用我们的团队协作平台高效管理人员、应用程序级权限、软件交付和计费。 - 快速回滚
自信地部署,因为您知道可以立即将代码或 Postgres 数据回滚到先前的状态。 - 应用指标
Heroku Metrics 为您提供有关应用程序运行时特性的强大洞察力。 - 持续交付
Heroku Flow 通过使持续交付变得简单、直观和高效,简化了应用程序发布体验。 - GitHub 集成
每个拉取请求都可以启动一个一次性的 Review App 进行测试,并在每个 GitHub 推送上手动或自动部署一个特定的分支。 - 可扩展性
使用 Heroku 的创新技术 Buildpacks 定制你的堆栈。你可以自行构建,也可以从社区数百个已构建的版本中选择一个。 - 安全性与合规性
Heroku 定期执行审计并维护 PCI、HIPAA、ISO 和 SOC 合规性 - 我们是提供满足高合规性要求的引人入胜的应用程序的最简单途径。
3. Canine:Heroku 的现代开源替代品
简介
Canine 是一个易于使用的直观的 Kubernetes 集群部署平台。是基于 Kubernetes 构建的开源 Heroku 替代品。
- 简单的集群管理 —— 以最少的配置连接到任何 Kubernetes 集群
- 项目组织 —— 将相关服务、工作人员和资源组合在一起
- 持久存储 —— 轻松管理有状态应用程序的卷
- 一键附加组件 —— 使用预配置设置部署数据库和其他服务
- 无缝集成 —— 连接 GitHub、监控工具等
特点
- Github 集成
当你推送到 Github 时,Canine 会提取你的代码并构建你的应用程序 - 一键部署和回滚
在一个地方管理您的部署和回滚 - SSL 证书管理
Let's Encrypt SSL 证书会自动为您的应用程序配置和管理 - 简化 Kubernetes
只需单击一下即可部署可在容器中运行的任何应用程序 - 任何工作负载
从单个代码库部署 Web 应用程序、后台作业甚至 cron jobs - 附加组件
使用流行的开源项目扩展您的应用程序的功能,完全免费 - 无供应商锁定
支持超过 200 家云服务提供商,告别价格欺诈 - 轻松自动缩放
轻松升级服务器,只需单击一次,无需停机。不需要时,可缩减规模 - 协作
团队套餐无需额外付费。想邀请谁就邀请谁,我们也乐意接待!
开发背景
“这一切始于我厌倦了使用 Heroku、Render、Fly 等平台来托管我在各个 PaaS 供应商上构建的 Web 应用所带来的高昂开销。我发现 Kubernetes 更灵活,功能更强大,更能满足我的需求。对我来说,最好的例子是:基本上所有 PaaS 供应商都要求为每个进程支付服务器容量(2GB),但每个进程可能无法占用全部资源,因此最终会导致资源配置过剩,无法像 Kubernetes 那样将尽可能多的进程调度到资源池中。”
“对于 4GB 的机器,各个提供商的成本为:
- Heroku = $260
- Fly.io = $65
- Render = $85
- Digital Ocean - Managed Kubernetes = $24
- K3s on Hetzner = $4
在工作中,我们在 Heroku 上运行了 6 个实例,大约 120GB 的数据,每年的成本接近 40 万!迁移到 Kubernetes 后,成本降到了更合理的 3 万/年。”
“但我仍然怀念那种在一个地方完成所有部署的便利,以及为中小型工程团队提供合理的默认设置,所以我尝试构建 Devex 层。我知道像 Argo 这样的现有工具存在,但它既过于复杂,又缺少某些功能。”
“Canine 最棒的地方(也是我希望社区会更加欣赏它的原因)在于它能够充分利用庞大且不断发展的 Kubernetes 生态系统。例如, Helm Charts 可以让你非常轻松地在集群中启动第三方应用程序,从而轻松实现自托管。我将其集成到 Canine 中,立即就能够部署大约 15000 个 Charts。Telepresence 可以非常轻松地与你的资源建立私有连接,而证书管理器则使 SSL 管理变得非常简单。我完全被震撼了,几乎所有我能想到的东西都有现成的、支持良好的软件包。”
拓展阅读
I'm building an open source Heroku / Render / Fly.io alternative on Kubernetes
3. Sveltos:简化插件和应用程序的部署和管理的插件控制器
简介
Sveltos 是一个 Kubernetes 插件控制器 ,它简化了跨多个集群(无论是在本地、云端还是多租户环境中)的 Kubernetes 插件和应用程序的部署和管理。
Sveltos 在管理集群中运行。它帮助用户以编程方式将 Kubernetes 插件和应用程序部署和管理到集群中的任何集群(包括管理集群)。
Sveltos 支持多种附加格式,包括 Helm charts 、原始 YAML/JSON 、 Kustomize 、 Carvel ytt 和 Jsonnet 。
价值
Sveltos 的构建旨在应对各种 CI/CD 工具带来的挑战。Sveltos 旨在补充甚至取代现有的 GitOps 工具,它与 Flux CD 的集成显著增强了 GitOps 的规模化能力。
Sveltos 的主要功能包括多租户、基于代理的漂移通知和同步以及资源优化。这些功能可确保 Kubernetes 附加组件和应用程序的安全 、 可靠和稳定部署,同时降低本地和云环境中的运营成本。
主要功能
- 可观察性:Sveltos 提供不同的通知端点。其他工具可以使用这些通知来执行其他操作或触发工作流。支持的类型包括 Slack、Teams、Discord、WebEx 和 Kubernetes 事件。
- 模板化:轻松修补渲染的资源!Sveltos 允许将 Kubernetes 插件和应用程序以模板形式呈现。在部署到托管集群之前,Sveltos 会使用从管理集群或托管集群收集的信息实例化模板。这允许在多个集群之间进行一致的定义,同时最大限度地减少调整和管理开销。
- 精心编排的部署顺序:Sveltos CRD(自定义资源定义)按照其在定义文件中出现的顺序进行部署。这确保了可预测且可控的部署顺序。
- 多租户:Sveltos 的创建考虑到了多租户概念。Sveltos ClusterProfile 和 Profile 资源允许平台管理员实现完全隔离或租户共享集群。
- 事件:Sveltos Event Framework 允许使用 Lua 语言部署插件和应用程序以响应特定事件。这允许根据不同的需求和用例进行动态且适应性强的部署。
- 托管服务
拓展阅读
Sveltos v1.0.0 is just released
4. Cerbos:为应用程序提供外部化、基于策略的运行时授权
简介
Cerbos 是一个与您的产品同步演进的授权层。它使您能够以简单直观的 YAML 策略为您的应用程序资源定义强大且上下文感知的访问控制规则;并通过您的 Git-ops 基础架构进行管理和部署。它提供高可用性 API,您可以通过简单的请求来评估策略并为您的应用程序做出动态访问决策。
使用场景
- 与同事协作,在完全互动的私人游乐场中制定和分享政策
- 快速高效地将策略更新分发给您的整个 PDP 团队
- 为客户端或浏览器内授权构建特殊策略包
- 在无服务器和边缘部署中轻松与 Cerbos 集成
特性
- 在几分钟内建立角色和权限
- 预建集成和策略
- 权限感知数据过滤
- 超越 RBAC/ABAC
- 轻松迭代
- 人类可读
- 在安全的环境中试验策略并实时获得模拟结果
- 使用 GitOps 实现 CI/CD 工作流程。减少人为错误并增强安全性
- 无状态且可扩展
- 无风险部署
- 捕获您的 Cerbos 策略尝试的所有操作和做出的所有决策。符合 ISO27001、SOC2 和 HIPAA 标准
- 集中管理和实时策略部署,以保持整个应用程序的授权同步
- 决策是在运行时以亚毫秒为单位在本地做出的,无需任何云查找
- 自托管,兼容隔离、高安全性环境。使用无服务器功能或 Sidecar 模型进行部署
5. EDKA:在 Hetzner 上搭建和管理 Kubernetes 集群
简介
Edka 能够在标准云虚拟机和 Kubernetes 之上自动创建可投入生产的平台即服务 (PaaS)。它通过提供预配置的开源插件,将 Kubernetes 集群转变为功能齐全的 PaaS,从而减少了在 Kubernetes 上运行应用程序所需的手动工作量。
Edka 可帮助您在自己的 Hetzner Cloud 帐户上配置和管理 Kubernetes 集群。即使断开与 Edka 的连接,您也可以继续手动或使用其他工具(例如 kubectl 管理集群。
特性
- 即时配置和扩展
在几分钟内部署一个强化的、可用于生产的 k3s Kubernetes 集群,并轻松跨区域自动扩展。 - GitOps 部署
连接您的 GitHub 或 GitLab 存储库以实现自动化 CI/CD、在每个拉取请求上预览环境以及无缝推出。 - 可扩展的附加组件
一键安装数据库、入口控制器、可观察性工具等,以定制您的基础设施。 - 监控与分析
通过内置仪表板实时了解性能、资源使用情况和成本指标。 - 安全备份(即将推出)
只需单击即可将您的集群、数据库和持久卷备份和恢复到 S3。 - 全面控制和成本效益
基于 CNCF 的开放标准,可实现可移植性,不受供应商锁定,并可节省高达 70% 的成本。
6. Gardener:为多云环境提供同构的 Kubernetes 集群
简介
Gardener 是一个 Kubernetes 扩展,用于实现自动化系统管理。它提供了一个精简、可扩展且支持多云环境的 API 服务器,集成了现有的云提供商和开源云计算库。Gardener 旨在支持大规模系统的可扩展性和弹性,能够管理跨多个云提供商(AWS、GCP、Azure、OpenStack、阿里云等)的数千个 Kubernetes 集群。
主要特点
- 多云:Gardener 支持广泛的云提供商,允许您在不同的云环境中部署和管理 Kubernetes 集群。
- 自动化操作:Gardener 自动执行管理 Kubernetes 集群所涉及的许多日常任务,例如更新、备份和扩展。
- 可扩展性:Gardener 被设计为可扩展的,允许您添加对新的基础设施提供商、操作系统、网络插件等的支持。
- 安全且合规:Gardener 确保 Kubernetes 集群安全且符合必要的标准。
- 一致性:Gardener 管理的所有 Kubernetes 集群均符合 CNCF 的一致性测试。
- 开源:Gardener 完全开源。我们欢迎社区的贡献,并相信协作开发的力量。
🤔 专题六 有意思的事与 Meme
Nothing funny this month.