🆕 专题一 产品新功能/新版本
1. VMware vSphere Kubernetes Service 3.4:扩展 Kubernetes 支持、Istio 服务网格和增强的多集群管理
vSphere Kubernetes Service 是什么
vSphere Kubernetes Service (VKS,原 TKGS) 提供用于在 vSphere Supervisor(正式名称为 vSphere with Tanzu)环境中配置和管理 Kubernetes 集群生命周期的组件。VKS 是 Broadcom 的企业级、 CNCF 认证和一致的 Kubernetes 运行时,它包含在 VMware Cloud Foundation 中(即:您无需支付额外费用)、受支持并且现在可用。
通过使用 vSphere Supervisor,可以将 vSphere 集群转变为在 vSphere 的专用资源池中运行 Kubernetes 工作负载的平台。在 vSphere 集群上启用后, vSphere Supervisor 会直接在虚拟机管理程序层中创建 Kubernetes 控制平面。然后,您可以通过部署 vSphere Pod 来运行 Kubernetes 容器,或者通过 TKG 服务创建上游 Kubernetes 集群并在这些集群中运行您的应用程序。
What's New in VKS 3.4
-
支持 Kubernetes 1.33
计划为特定版本的 vSphere Kubernetes releases (VKr) 提供扩展支持,从而支持从正式发布 (GA) 开始持续 24 个月 。这将帮助 VMware Cloud Foundation 客户在需要时更长时间地使用 Kubernetes 次要版本。首个提供扩展支持的版本是 VKr 1.33。扩展支持也适用于 VKr 中包含的核心软件包以及部分标准软件包。 -
多集群管理
VCF 客户现在可免费使用 Tanzu Mission Control Self-Managed。TMC-SM 提供全面的功能组合,助力平台和 DevOps 团队大规模管理其 VKS 集群。TMC-SM 1.4 正式发布,它新增了对 VKS 3.4(包括 VKr 1.33 及相关 ClusterClass 版本)的生命周期管理支持;此外,还提供了一个基于 UI 的全新安装程序,使团队能够快速启动并运行。 -
Istio 服务网格 – 零信任安全性、可观察性和高级流量管理
随着企业扩展其 Kubernetes 环境,安全可靠地管理微服务变得越来越复杂。Istio 为平台工程师提供了工具,用于保护服务通信、执行细粒度的流量管理以及实施一致的策略,从而构建具有弹性且易于管理的 Kubernetes 环境。VKS 3.4 将对 Istio 服务网格的支持引入 VKS 标准包中,并提供运行时支持,这超越了其他标准包提供的安装和升级支持。 -
支持 Ubuntu 24.04 LTS
VKr 1.33 将支持 Ubuntu 24.04,并将其作为受支持的操作系统版本之一,此外还支持 Photon OS 5.0 和 Ubuntu 22.04。
改名情况
| 原名 | 现名 |
|---|---|
| vSphere with Tanzu | vSphere IaaS Control Plane |
| Tanzu Kubernetes Grid Service (TKGS) | vSphere Kubernetes Service (VKS) |
拓展阅读
VMware vSphere Kubernetes Service (VKS) Versus VMs and Containers on Bare Metal
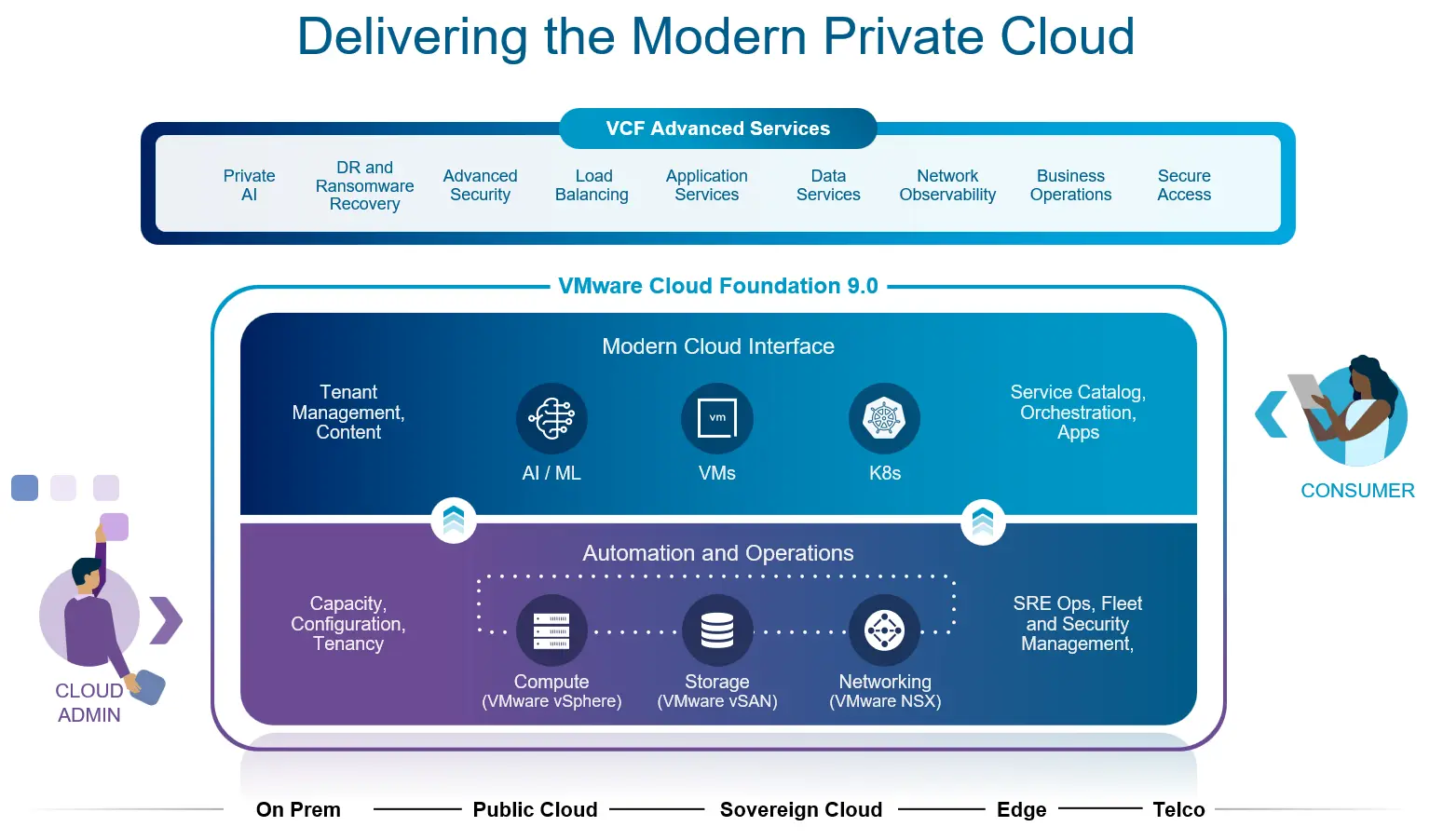
2. VMware Cloud Foundation 9.0
VMware Cloud Foundation 是什么
在官网,VMware Cloud Foundation 的一句话简介为:部署一种云运营模式,该模式结合了公有云的规模和敏捷性与私有云的安全性和性能。
文档中的介绍为:VMware Cloud Foundation 是一个统一的私有云平台,它将公有云的规模和敏捷性与私有云的安全性和性能相结合,从而提高生产力并降低总体拥有成本 (TCO)。通过集成的企业级计算、网络、存储、管理和安全性,实现基础架构的现代化,覆盖所有端点。借助自动化的基础架构和智能化运营,企业可以优化性能、降低成本并减少运营开销。借助自助服务 IaaS 平台,该平台提供现代化的云界面来运行虚拟机、容器和 AI 工作负载,从而加速创新。凭借内置的安全性和弹性,可以保障业务安全,确保业务连续性,并使团队能够专注于创新,而无需应对安全威胁。
VMware Cloud Foundation 所属的产品类别为 Cloud Infrastructure,该类别中一共有 41 款产品。其中有 11 款产品是 VMware Cloud Foundation / VCF 的组件或者高级服务:
| 产品 | 关系 |
|---|---|
| vSphere | 通过 vSphere 命名空间跨 VCF 实例群使用 Supervisor 资源和服务。 |
| VMware vSAN | 企业级存储虚拟化软件。 |
| NSX | 使用虚拟私有云 (VPC) 简化自助服务网络。 |
| VCF Operations | 启用租户操作(利用率、退款、警报)和工作负载操作。 |
| VCF Automation | 提供适用于应用程序团队的自助服务私有云。 |
| VMware Data Services Manager | 部署由 DSM 管理的开源数据库。 |
| VMware Private AI Foundation with NVIDIA | 部署支持 GPU 的 RAG 工作负载。 |
| VMware vDefend Distributed Firewall | 零信任微分段来保护云工作负载。 |
| VMware Avi Load Balancer | Azure VMware 解决方案中用于工作负载的软件定义负载均衡和 Web 应用程序防火墙。 |
| VMware Live Recovery | 统一本地和公共云之间的网络和站点恢复。 |
| VMware Tanzu Platform | 云原生应用平台。 |
从产品类型上看是私有云平台。VMware 自己撰写的 Top 5 Reasons to Deploy Private Cloud Infrastructure 对私有云平台进行了定义与优势介绍。私有云平台提供了一种通常与公有云相关的云运营模式,同时具备私有托管 IT 服务所特有的增强隐私、安全和控制。并且私有云不一定必须是企业内部部署的、自有或由企业管理的。虽然私有云基础设施和服务当然可以托管在组织自己的数据中心,但它们也可以托管在第三方托管设施或由提供私有云托管服务(并且可能也提供传统的公共共享多租户云基础设施)的云提供商处,并可以扩展到边缘位置。
私有化平台的优势在于:
- 增强安全性和合规性
- 更好的控制和定制化
- 成本效率和可预测性
- 提高性能和可靠性
- 治理的灵活性和可扩展性
VMware 为什么要推出 VMware Cloud Foundation
VMware 推出 VMware Cloud Foundation 的战略目标是构建一个全面集成、自动化、安全、且能同时支持传统与现代工作负载的混合云基础设施平台,帮助企业解决 IT 复杂性、提升运营效率、降低成本,并最终加速其数字化转型进程。可以从以下几个方面具体来看:
- 简化数据中心基础架构
- 传统数据中心部署计算、存储、网络和管理平台等组件复杂、耗时且容易出错,需要大量的 IT 人力和专业知识。
- VCF 将 VMware 的这些软件预集成、预验证并自动化部署。大幅简化了从部署到后续生命周期管理(打补丁、升级)的复杂性,将部署时间从数周缩短到数小时。
- 提供一致的混合云操作模式
- 许多企业同时拥有私有云和公有云,但两者之间的操作模式、工具和所需技能往往不一致,导致管理复杂、效率低下、应用迁移困难。
- VCF 提供了一个统一的、软件定义的基础架构层和操作模型,无论是部署在本地、公有云(如 VMware Cloud on AWS/Azure VMware Solution)还是边缘,都能保持一致。这使得应用可以无缝迁移,IT 团队可以使用熟悉的工具和流程管理所有环境。
- 同时支持传统与现代工作负载
- 企业需要同时运行传统的虚拟机(如 ERP、数据库)和新兴的容器化/云原生应用(如微服务、AI/ML)。管理两套不同的基础设施和工具集带来了巨大的挑战。
- VCF 通过集成 VMware Tanzu(包括 vSphere with Tanzu),使客户能够在同一个平台上同时运行和管理虚拟机和 Kubernetes 容器工作负载。它提供了一个开发者友好的 Kubernetes 平台,同时保留了 vSphere 在运行关键业务传统应用方面的优势。
- 增强安全性与弹性
- 随着网络威胁的增加和合规性要求的提高,确保数据中心的安全和业务连续性变得越来越复杂。
- VCF 内置了多层安全功能,如 NSX 的微隔离、数据加密、身份和访问管理 (IAM)。它还提供了高可用性、灾难恢复和备份能力,确保业务连续性和数据可靠性。
- 降低总体拥有成本 (TCO)
- IT 基础设施的部署、管理、维护和升级都需要大量人力和资本支出。
- 通过自动化、简化管理、优化资源利用以及提供订阅许可模式,VCF 有助于减少人工操作错误、提高运营效率、降低硬件需求,从而显著降低 TCO。
上面是对外的价值,下面从对内的价值进行分析。VMware 在虚拟化领域所处的地位在一定程度上看是独一无二的,但这份成就并不代表一劳永逸,近年来市场和技术迭代的速度越来越快,VMware 也需要想出对策积极应对。可以从几个角度反推 VMware 的决策思路:
- 巩固在虚拟化市场的领导地位
VCF 的推出是 VMware 从单一虚拟化产品供应商向提供集成化、自动化 SDDC(Software-Defined Data Center,软件定义数据中心)平台的转型。 - 应对公有云的挑战
公有云的崛起对传统数据中心模式构成了巨大挑战,许多企业开始将工作负载迁移到公有云。VMware 需要提供一个解决方案,既能满足客户在本地部署的需求,又能与公有云无缝集成。 - 拥抱容器和云原生,扩展市场份额
Kubernetes 和容器技术的兴起改变了应用开发和部署的方式。VMware 需要适应这一趋势,将其产品线扩展到云原生领域。 - 基于前面几点设计产品,提升产品价值、增加客户粘性
- 通过将 vSphere、vSAN 和 NSX 等核心产品打包成一个统一的解决方案,VCF 帮助 VMware 巩固了其在企业数据中心基础设施领域的领导地位,并引领了 SDDC 的发展方向。
- VCF 提供了一个与公有云(如 VMware Cloud on AWS、Azure VMware Solution、Google Cloud VMware Engine)保持一致的软件定义基础设施层。这使得客户可以在本地数据中心获得类似公有云的敏捷性和自动化能力,同时也能轻松地在不同云环境之间迁移工作负载,实现真正的混合云体验。这帮助 VMware 留住了那些希望利用公有云但又不想完全放弃现有投资的客户。
- VCF 通过集成 VMware Tanzu(特别是 vSphere with Tanzu 和 VKS),将 Kubernetes 能力直接引入到其核心虚拟化平台中。这使得 VCF 成为一个能够同时支持传统虚拟机和现代容器化应用的统一平台。这不仅帮助 VMware 抓住了云原生市场的新机遇,也吸引了更多的开发者和 DevOps 团队,扩大了其潜在客户群体。
- VCF 提供了一个预集成、预验证且高度自动化的解决方案。这大大简化了客户的采购决策(不再需要单独购买和集成多个组件)、部署过程和日常运营管理。通过降低复杂性、减少部署时间来提高运营效率和降低 TCO。
What's New in VCF 9.0
主要更新如下:
| 更新内容 | 相关组件 | 介绍 |
|---|---|---|
| 私有云操作的单一界面 | VCF Operations、VCF Installer | VCF Operations 提供了全新的操作体验。结合 VCF Installer 带来的全新构建体验,您将获得集成治理的快速部署,从而更快地投入运行,减少设置时间和复杂性,同时通过成本管理和策略执行,从第一天起就确保合规性和运营效率。 |
| 一个界面,带来云消费体验 | VCF Automation | VCF Automation 使 IT 团队和云服务提供商能够为应用程序团队提供自助式私有云。自助式私有云内置丰富的云服务,可用于配置虚拟机、Kubernetes、网络、卷、密钥存储、数据库、Harbor 容器注册表、外部 DNS、证书和 AI 工作负载。 |
| 原生运行容器、虚拟机和传统应用程序 | - | 借助 VMware Cloud Foundation 9.0,您可以获得一个统一的平台来原生运行容器、虚拟机和企业应用程序。Kubernetes 和虚拟化开箱即用,无需自行组装单独的技术栈。这种无缝集成使开发人员和 IT 团队能够立即开始构建和运行工作负载,从而简化工作流程并提高生产力。 |
| 主权、安全、合规的平台 | - | VMware Cloud Foundation 9.0 旨在满足最高的数据控制、合规性和弹性标准,确保企业在监管审查日益严格和地缘政治不确定性日益加剧的时代能够自信运营。VCF 9.0 提供无需权衡的数据主权,让您能够完全控制数据的存储、处理和访问位置和方式,同时保持云运营的敏捷性。 |
| 私有云成本透明度 | - | VMware Cloud Foundation 9.0 为私有云带来财务透明度,确保企业能够扩展业务,避免成本失控或隐性效率低下。VCF 提供深度成本可视性,让您能够通过开箱即用的洞察获得全面的财务透明度,这些洞察不仅涵盖基础架构,还涵盖软件许可、运营费用甚至物理数据中心成本,从而提供真实的总拥有成本 (TCO) 视图。 |
| 安全与合规 | vCenter、ESX 和 NSX 等 | 在 VCF 9.0 中,所有产品组件均已根据 NIST 推荐的加密模块标准 FIPS 140-2 和 140-3 进行更新。vCenter、ESX 和 NSX 等 VCF 组件默认以启用 FIPS 的模式运行,并且此模式无法停用。 |
| 许可相关 | VCF Operations | 您现在可以通过 VCF Operations 管理整个机群的许可证,并可以从 VCF Business Services 控制台( vcf.broadcom.com )(Broadcom 支持门户的一部分)管理多个 VCF Operations 实例的许可证。 |
VCF 9 的存储服务
- 所有 VCF 9 存储平台均已启用 Windows Server 故障转移群集 (WSFC),并使用群集 VMDK 支持。这消除了 WSFC 对专用物理 LUN 的需求,并简化了设置和管理群集虚拟机的流程。
- 多写入器支持共享磁盘使 Oracle RAC 集群能够在 vSphere 存储上获得支持。此功能在 vSAN 和 VMFS 上均受支持。
- 大型 VMDK 支持 – 所有存储类型均支持高达 62TB 的 VMDK,这与 vRDM 和 vVols 的先前限制相呼应。
- 基于存储策略的管理 (SPBM) – vSAN 提供 SPBM 作为存储管理的核心操作模型,以允许以虚拟机为中心的存储管理。
- 容器存储支持 – Kubernetes CSI 支持允许为 vSAN、VMFS 和 NFS 自动部署块存储。使用 VMFS 和 NFS 时,您需要为数据存储添加标签。vSAN 还支持使用 CSI 为容器提供 NFS 共享。
- 所有 VCF 存储系统(包括 NFS,这是 VMware Cloud Foundation 9 中通过 VAAI 实现的新功能)均支持通过 UNMAP/TRIM 从客户机操作系统进行空间回收。
- 静态数据和传输中数据加密 – vSAN 提供原生传输中数据加密以及透明静态数据加密。vCenter Server 内置原生密钥管理器,因此无需部署第三方 KMIP 服务器(但可以选择使用)。主机中的物理 TPM 也可用于缓存静态数据密钥,并为主机启用配置加密。第三方存储的静态和传输中加密可通过虚拟机加密启用。此外,NFSv4 现在已在 vSphere 9 中支持 krb5p 传输加密。
- 支持 vTPM 来公开一个用于存储虚拟机机密的安全位置。
- 精简配置 ——所有 VMDK 都支持,并且应该认真考虑将其作为所有 vSAN/NFS/VMFS 存储的默认设置。
- 压缩和重复数据删除 – 在 vSAN 上受支持,现具有全局重复数据删除功能。
- 数据库即服务 (DBaaS) – 数据服务管理器 (DSM) 9 可选支持多种数据库平台(MySQL、PostgreSQL、SQL Server)。VMware Cloud Foundation 9 提供强大的高级服务,能够以编程方式自动部署数据库集群、修补、维护和备份数据库,并自动执行大多数数据库管理功能。
- 快照支持 – vSAN Express 存储架构提供高性能快照,避免性能冲击,并使用 vSAN 数据保护功能实现长期保留,从而自动执行计划和不可变保留。此外,它还可以与 VMware Live Recovery 配合使用,在辅助群集上进行快照存储。
- 灾难恢复 – VMware Live Recovery(以前称为 SRM)允许将虚拟机副本安全、高效地复制和编排到辅助位置,以便在发生灾难恢复时快速恢复。
- 异步复制 – vSphere Replication 支持将具有快照恢复点的异步副本保存在辅助位置。
- 同步复制 – vSAN 和许多第三方存储平台都支持同步复制,以构建延伸集群。
- vSphere 备份 API(原 VADP) – 丰富的备份支持,支持基于更改块跟踪的自动、低影响备份。支持多种模式,包括网络模式、热添加模式和直接 SAN 模式。此外,还支持反向更改块跟踪还原。
- vStorage APIs for Array Integration (VAAI) – VMFS 和 NFS 均提供多种功能,支持特殊集成和卸载。
- vSphere APIs for IO Filtering (VAIO) – 此功能允许虚拟机根据策略安全地过滤其 IO。主要用于近实时备份和复制。
VCF 9 的 VPC
VMware Virtual Private Cloud in VMware Cloud Foundation 9.0: A New Era of Private Cloud Networking
背景
虚拟私有云 (VPC) 可在更广泛的 VCF 私有云中创建一个安全隔离的多租户网络环境。它使用户能够定义和管理自己的逻辑隔离网络,并配置自定义 IP 寻址、路由和安全策略。该模型可直接在 vCenter 中使用,提供应用程序所有者所需的自助式云体验,帮助他们快速自主地控制虚拟机和网络。
这一变革弥合了用户所需的按需灵活性与企业 IT 所需的强大监管之间的差距。通过委派网络创建,虚拟基础设施管理员和开发团队可以更快地开展工作。这使得网络和安全管理员能够保留集中治理并提供安全护栏,从而提供精简高效的云运营模式,显著加快应用程序的配置速度。
VMware VPC 架构旨在在 VMware Cloud Foundation 中实现多租户、自助式云运营模式。它在不同的管理角色之间建立了明确的职责分离,同时实现了安全、隔离的网络环境。
架构
在顶层,物理网络管理员管理底层物理网络资源。企业管理员负责监管整个 VMware Cloud Foundation 环境,建立中央治理和外部连接。在此层之下,NSX 项目管理员负责管理 NSX 中的租户(也称为 NSX 项目),并可委托其控制其各自的资源集。企业管理员和项目管理员的一项重要职责是为每个项目和 VPC 分配网络配额。
最后,VPC 管理员为其特定 VPC 创建和管理网络。VPC 管理员创建的任何安全或网络策略都完全包含在该 VPC 内,不会影响其他 VPC。但是,这些策略受企业或项目管理员设置的更广泛的安全和治理控制措施的约束。这种分层模型确保租户用户(VPC 管理员)能够自主、快速地部署和管理其应用程序,同时又不损害企业 IT 所需的强大监管能力。
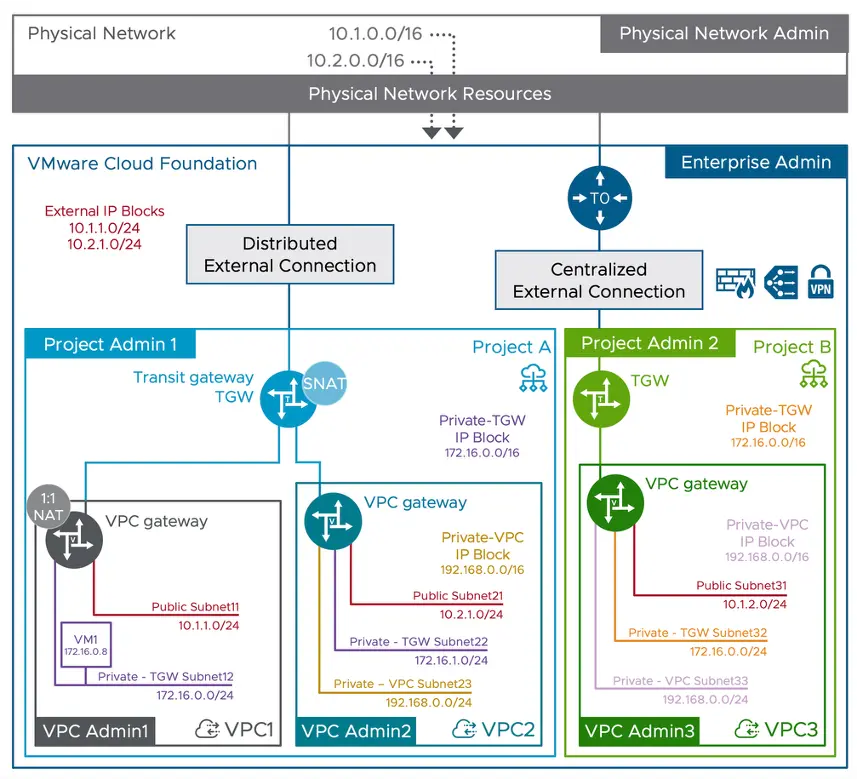
核心组件
- 虚拟私有云 (VPC):VPC 直接在 vCenter 中提供简化的自助服务网络模型,使用户能够使用自定义 IP 地址、路由和安全策略定义和管理自己的逻辑隔离网络。
- VPC 网关:VPC 的专用逻辑路由器,用于处理往返于 Transit Gateway 的南北向流量路由。它还管理 VPC 内所有子网之间的东西向流量路由。
- 子网:在 VPC 内,具有广播域中 IP 地址范围的网络,可以连接虚拟机网络适配器,无需配置物理环境。
- 子网访问模式:定义了子网的连接性。
- Public:采用公有访问模式的子网会对外公布,使连接的工作负载可直接在环境中使用。此网络可以使用 RFC 1918 IP 地址,以便在数据中心(而非互联网)内使用。这提供了无需 NAT 的直接连接。
- Private-VPC:子网在 VPC 内部相互隔离。这些私有子网的作用域是 VPC 内部。因此,连接到私有子网的虚拟机只能与该 VPC 内部的对等子网直接通信。可以通过外部 IP 地址配置 NAT,以访问该子网中的 IP 地址。
- Private-Transit Gateway:子网通过 Transit Gateway 路由流量,并可通过其他 VPC(同一 TGW 内)访问。一个常见的用例是访问连接到同一 TGW 的其他 VPC 中运行的共享服务。可以通过外部 IP 配置 NAT,以访问此子网中的 IP。
- 子网大小:指定子网的 IP 地址总数。需要注意的是,16 并非指 /16 子网掩码,而是指该子网中总共 16 个 IP 地址。由于部分地址已保留用于网络操作,因此虚拟机实际可用的 IP 地址数量将小于此值。
- VPC 管理员:具有管理和配置特定 VPC、其子网及相关服务的权限的用户角色。此访问权限可进一步限制为网络和安全等细粒度服务。
- NSX 项目:NSX 中租户的定义,用于对网络和安全对象进行分组,从而实现多租户以及管理控制和配额的委派,并构成 VPC 环境的基础。每个 NSX 项目都有自己的 Transit Gateway,并且每个 VPC 都必须属于某个项目。VCF 部署附带一个特殊的“默认”NSX 项目,可以通过 vCenter 使用和配置。但客户可以从 NSX UI 添加更多项目来组织其基础架构(例如:NSX 项目代表其组织的结构、站点位置、租户、应用程序等)。
- 中转网关 (TGW):共享网关,用于实现多个 VPC 之间的互通,并将南北向流量汇聚到外部网络。可启用高可用性,并支持 Active-Active 和 Active-Standby 架构。
- TGW 连接:定义与外部网络的连接。支持两种架构:集中式 (CTGW) 和分布式 (DTGW)。Transit Gateway 的南向连接始终与 VPC 网关连接,其北向连接可以直接连接到 vLAN(在 DTGW 架构中,也称为 Edgeless)或 NSX T0 路由器(在 CTGW 架构中)。
- 集中式(CTGW):通过 NSX T0 路由器将流量路由到集中式 NSX Edge 节点集群。它支持 NAT、DHCP、负载均衡器、网关防火墙、DFW 等服务。
- 分布式(DTGW):利用 vSphere 虚拟机管理程序本身的分布式路由功能来优化流量。由于不使用 NSX Edge 集群,占用空间更小,可以直接通过 vLAN 网络建立北向连接。支持分布式 DHCP、1:1 NAT、DFW 等分布式服务。它也被称为“无边界设计”。
- 项目管理员:负责管理特定 NSX 项目内的项目资源(如 VPC)、其用户、配额和权限的管理角色。
- 路由表:控制 VPC 内部、VPC 之间以及到外部网络的流量定向方式的系统,通过与网关和子网关联的路由表和转发表进行管理。您可以从 NSX UI 和路由器的 CLI 查看。
- IP 块:IP 块是可分配给特定项目和 VPC 的公共或私有 IP 地址范围,以便为子网和网络服务提供 IP 寻址服务。
- 外部 IP 块:外部 IP 地址块由企业管理员定义,可以公开给 NSX 项目。同一公共地址块可以公开给多个 NSX 项目。一系列公共或可外部路由的 IP 地址,用于公共子网上的虚拟机以及 1:1 NAT 等服务。
- 私有 – 传输网关 IP 块:租户管理员(NSX 项目管理员角色)可以定义私有 TGW IP 地址块并将其分配给特定的 VPC。私有 TGW 子网从这些地址块中获取 IP 地址。此 IP 地址块可在同一 TGW/NSX 项目中的多个 VPC 之间共享。
- 私有 – VPC IP CIDR:私有 VPC IP CIDR 的范围是 VPC 本身。VPC 管理员可以在创建 VPC 时分配此 CIDR。连接到私有 VPC 子网的虚拟机将从此处获取 IP。
VPC 上的集成网络和安全服务
- 核心网络和安全服务
- 集成 IPAM 的按需网络:用户可以按需创建自己的网络。NSX 会自动管理这些子网中的 IP 地址,从而简化 IP 地址管理 (IPAM),无需使用外部工具。
- DHCP 和 DHCP 中继:每个 VPC 都包含内置 DHCP 服务器功能,可自动为工作负载分配 IP 地址。它还可以配置为 DHCP 中继,以便与现有的外部 DHCP 服务器集成。
- 分布式和静态路由:NSX 的分布式路由功能可以最佳效率处理 VPC 内子网之间的流量。对于特定的流量工程需求,还可以在 Transit 网关上配置静态路由。
- 网络地址转换 (NAT):强大的内置 NAT 服务可用于控制访问。这包括用于从私有网络出站访问的源 NAT (SNAT) 和允许外部访问内部服务的 1:1 NAT。
- 网关防火墙:无状态网关防火墙在网关上运行,为进入或离开 VPC 的所有南北流量提供必要的外围安全。
- 可选的高级服务和附加组件
- vDefend 分布式防火墙 ( DFW ): NSX 的一项关键功能,可实现微分段。DFW 在每个工作负载的虚拟网卡上运行,支持随虚拟机迁移的精细安全策略,从而将工作负载彼此隔离,防止威胁横向扩散。
- 具有高级威胁防御功能的 vDefend 网关防火墙: 网关防火墙的功能可以通过高级威胁防御功能得到增强,包括入侵检测和防御系统 (IDS/IPS) 和状态第 7 层检查。
- AVI 负载均衡器: 提供企业级负载均衡,包括本地负载均衡、全局服务器负载均衡 (GSLB) 和 Web 应用程序安全,以确保应用程序的性能和安全性。
访问和管理 VMware VPC 功能
- VMware vCenter Server :对于虚拟机的日常运行及其网络连接仍然至关重要。虚拟机管理员使用 vCenter 将虚拟机连接到已在 VPC 中创建和定义的相应子网(网络)。
- VMware NSX 用户界面 (UI) :这是网络管理员和安全团队的主要界面,提供对平台各个方面的全面、精细的控制。架构师和管理员使用 NSX UI 对网关、路由、防火墙策略和其他高级服务进行详细配置。
- VMware Cloud Foundation (VCF) 自动化 :VCF 自动化了整个 VCF 堆栈的生命周期管理。VPC 环境的基础网络可以高度自动化且经过验证的方式进行配置。通过 VCF 自动化,VPC 可以作为自助服务目录项使用。这使得应用程序团队能够根据预定义的蓝图部署整个应用程序及其所需的隔离网络环境。
- VMware Cloud Foundation Operations :为 VPC 环境提供深度运维可见性和监控。它允许管理员跟踪网络性能、排除连接故障,并确保 VPC 结构及其内部运行的工作负载的运行状况和合规性。
- VMware Cloud Foundation Operations HCX :提供安全无缝的路径,将现有虚拟机工作负载从传统网络架构无中断迁移到新的 VPC 网段,无需更改 IP 地址或 MAC 地址,从而最大程度地减少停机时间。
- API 和基础设施即代码 (IaC) 工具 :对于 DevOps 方法,NSX(由 VCF 编排)提供强大的 REST API,可实现对 VPC 生命周期和监控的完全编程控制。此功能可由 NSX 的 Terraform Provider、 PowerCLI 以及 SDK (Python 和 Java)等工具利用,实现自定义自动化。
部署示例
- 优化的 vSphere 网络 :通过允许从 vCenter 进行网络配置和管理,简化了 VDS 之外的 vSphere 管理员的工作。
- 基于租户的 VPC :非常适合为不同客户或业务部门创建隔离环境的服务提供商或大型企业。
- 特定于应用程序的 VPC :每个主要应用程序都有自己的专用 VPC,确保其网络环境是定制的和隔离的。
- 基于生命周期的 VPC(开发/测试/生产) :为开发、测试和生产创建单独的 VPC,以确保隔离并实现对更改的安全测试。
- 安全区域 VPC :设计 VPC 来表示具有不同安全策略的特定安全区域(例如,DMZ、PCI 合规区域、内部信任区域)。
VCF 9 的内存分层性能
Memory Tiering Performance in VMware Cloud Foundation 9.0
Memory Tiering Performance VMware Cloud Foundation 9.0
Deployment Considerations of Memory Tiering in VMware Cloud Foundation 9.0
在 VCF 9.0 中,内存分层为虚拟机提供了单一的逻辑内存空间。然而,在底层,它根据虚拟机内存活动管理第 0 层 (DRAM) 和第 1 层(内存分层)内存类型。本质上,它的作用是将活动的“热”内存保留在 DRAM 上,将非活动的“冷”内存保留在 NVMe 上。
从虚拟机的角度来看,这看起来像是一个更大的内存空间。在后台,ESX 会动态管理跨 DRAM 和 NVMe 两层的内存页面布局。这确保了最佳性能。
在不同的企业工作负载上进行了测试,以验证内存分层的性能。使用了配备各种 DRAM 配置的 Intel 和 AMD 服务器。VCF 9.0 的默认 DRAM:NVMe 比率为 1:1。我们在所有测试中均使用此默认 1:1 比率。

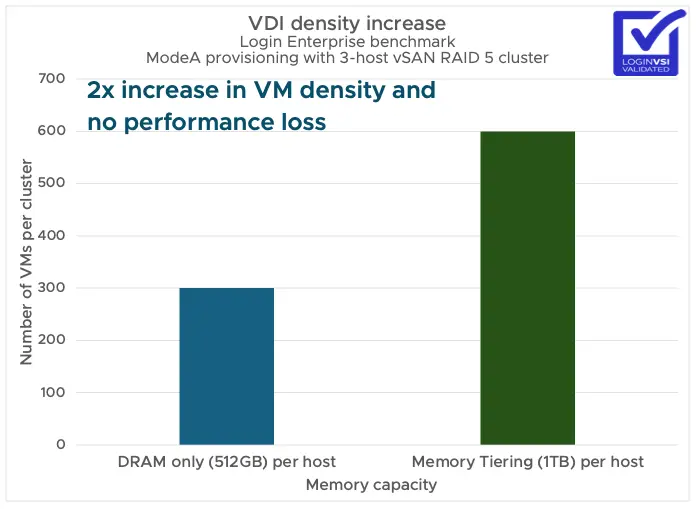
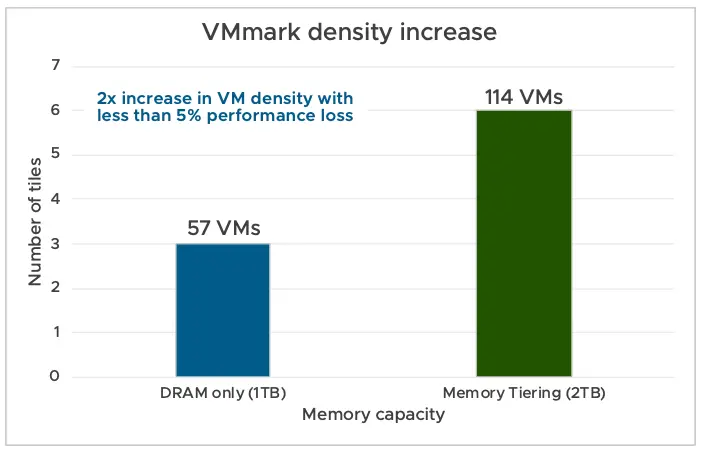
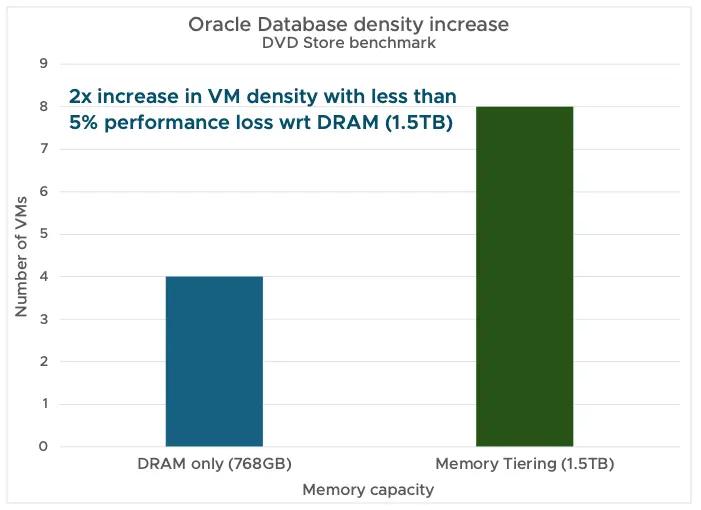
应该监控两个关键指标以确保内存分层具有良好的性能:
- 将活动内存保持在 DRAM 的 50% 或更低以获得最佳性能。
- 监控 NVMe 设备读取延迟。低于 200 微秒即可获得最佳性能。
内存分层为内存配置提供了新思路:
- 通过减少 DRAM 需求,它可以节省高达 40% 的 TCO。
- 它透明地工作,无需更改应用程序或客户操作系统。
- 它可以在不同工作负载类型中实现 2 倍的虚拟机密度提升。
- 它在灵活的基础设施内工作,可以适应不断变化的工作负载需求。
规划 VCF 9.0 部署
Planning a Successful VMware Cloud Foundation 9.0 Deployment
- 首先使用 VMware Private Cloud Maturity Model Assessment 工具评估组织的私有云成熟度,这有助于明确目标,找出优势和不足,制定私有云采用路线图。
- 学习与了解 VCF 的基本架构,包括 Workload Domain、VCF Instance、VCF Fleet 和 VCF Private Cloud 之间的关系,并解释了不同部署路径(例如,部署新的 VCF 实例、将现有 vCenter 环境整合到 VCF 管理域等)和设备模型(单节点和高可用性)。
- 规划和准备工作,特别是使用 VCF Planning and Preparation Workbook 工具进行环境规格设计和容量规划的重要性。这个Excel表格可以帮助用户根据自身需求动态调整配置。
- 进行部署前的配置、兼容性和连接性检查,建议使用 Broadcom 的 Configuration Maximums 工具和 Compatibility Guide 工具进行验证,并使用 VMware Ports and Protocols 工具检查端口和协议。
拓展阅读
VMware VCF 9.0 Finally Unifies Container and VM Management
What’s New in VMware Cloud Foundation 9.0
What’s New in VMware Cloud Foundation 9.0
Has VMware Finally Caught Up With Kubernetes?
VCF Edge 9.0: Single Host Edge Site Deployment
Revolutionizing the Factory Floor: Introducing the Industrial vSwitch in VMware Cloud Foundation 9.0
Introducing Centralized Tag Management in VMware Cloud Foundation 9.0
3. VMware vSphere Supervisor 9.0.0:首个与 vCenter 分离的 Supervisor 版本
More Kubernetes, Less Waiting: Upgrade vSphere Supervisor Without updating vCenter
什么是 vSphere Supervisor
vSphere Supervisor 将 VMware Cloud Foundation 转变为一个统一的平台,可使用声明式 API 部署传统虚拟机工作负载或现代容器工作负载。它使云管理员能够定义资源边界,并通过策略、治理和标准化来管理平台,同时提供对云服务的一致自助访问。
版本价值
此版本标志着在简化 VCF 上 Kubernetes 生命周期的征程中迈出了重要的里程碑。2024 年 6 月,引入了 vSphere Kubernetes Service 与 Supervisor 的分离。这使得管理员无需升级 vSphere Supervisor 即可升级 vSphere Kubernetes Service。收到了来自客户的大量反馈,他们表示此版本简化了他们使用新 Kubernetes 版本的流程。通过此版本,将继续简化 Kubernetes 生命周期。
- 无需始终升级 vCenter 即可获取最新的 Supervisor 二进制文件 - 现在,vSphere Supervisor 与 vCenter 已解耦,能够独立交付 Supervisor 组件,而无需使用 vCenter 作为媒介。将继续致力于让客户更轻松地在 VCF 部署中管理和部署 Kubernetes。
- 轻松升级 Supervisor – 由于 Supervisor 独立于 vCenter 提供,现在每次升级 vCenter 时都可以从内容库下载并升级到新版本的 vSphere Supervisor 服务。需要从现有的 vCenter 启动更新到新版本的 Supervisor。
- 每个 Supervisor 版本均可运行多个 Kubernetes 版本 - 每个 Supervisor 版本通常支持多个 vSphere Kubernetes Service (VKS) 版本。这样,就可以部署 vSphere Kubernetes Service 集群,其 Kubernetes 次要版本号必须位于特定 Supervisor 版本的 VKS 列表支持的范围内。
为了增强平台完整性并保护 vSphere Supervisor 环境,从 Supervisor Kubernetes 版本 v1.30.10+vmware.1-fips-vsc9.0.0.0100 开始,VCF 在 Supervisor 平台内引入了签名的 Supervisor 服务构件和强制访问控制保护。此功能可确保所有 Broadcom 授权的服务都经过签名证书的验证,并将平台开放给第三方服务,这些服务将接受签名验证和运行时策略强制执行。
vSphere Supervisor 9.0.0.0100 引入了 ArgoCD 服务(一款领先的 GitOps 持续交付工具)作为 Supervisor 服务。
4. Argo Workflows 3.7 发布
重点
- 智能缓存与记忆化 — 节省计算时间,更透明地复用结果。
- 多控制器锁(信号量 + 互斥锁) — 跨集群扩展更有信心。
- 动态命名空间并行度 — 按命名空间调节资源使用。
- argoexec 非 root 执行 — 加强安全性。
- React Testing Library & UI 优化 — 测试覆盖更全面,界面更简洁。
- 提交前预览工作流 — 提早发现问题。
- 通过 API 按时间戳过滤工作流 — API 用户大批量筛选更高效。
拓展阅读
Kubecodex:使用 ArgoCD 的 GitOps 存储库结构标准。
5. KubeSphere 企业版 4.2.0 发布
KubeSphere 企业版 4.2.0 重磅发布,四大升级引领云原生变革
全新 UI 设计,打造极致用户体验
- 页面框架优化:全新的顶部导航支持全局视角切换,整合平台管理功能,侧边导航常驻展示并支持资源快速切换与搜索,大幅提升操作流畅性。
- 快捷访问功能:用户可自定义集群、企业空间及扩展组件入口,打造个性化界面,显著提高工作效率。
- 工作负载创建流程简化:企业空间新增工作负载模板,减少层级并预置参数,实现创建高效便捷。
- 扩展组件调用升级:工作负载详情页集成统一调用机制,通过弹窗操作关联资源,保持页面连贯性。
- Debug 体验增强:详情页直接展示并调试容器及副本,让故障排查更加高效。
场景化特性大幅提升,边缘 AI 与可观测双轮驱动
- 边缘计算套件 EdgeWize 3.1.0
- 运维能力增强:支持 KubeEdge 集群平滑迁移,通过 OTA 支持边缘节点的 KubeEdge / Docker 自动安装,显著提升系统稳定性与维护效率,让企业运维更省心。
- 云边协同:云边协同解决了云端与边缘设备网络隔离、通信受限等难题,通过高效安全的数据通道,实现数据与业务的无缝流转,助力企业释放边缘智能价值。
- AI 相关基础能力迁移:无缝支持多样化 AI 场景,推动边缘智能化升级。
- 可观测平台 WizTelemetry 2.0
- 链路追踪(Tracing):基于 OpenTelemetry 构建,支持服务拓扑自动生成、链路耗时与错误率分析,快速定位调用瓶颈。
- 网络可观测:实时生成四层网络与七层服务拓扑,结合 RED 指标与 HTTP 请求日志,深入掌握服务间通信与性能表现。
KSE 产品优化,网络与应用商店全面升级
- 网络隔离功能优化
- 项目网络策略只读展示:用户可直观查看企业空间和项目视角下的网络策略,快速排查问题。
- 企业空间/项目出站流量限制:补全双向管控,满足企业安全规范要求。
- 优化白名单配置流程:支持企业空间筛选,简化操作,减少选择困扰。
- 应用商店功能升级
- 中小企业及开源用户:跳过繁琐审核与上架流程,快速将应用注入商店,极大简化操作步骤。
- 大型企业:保留原有严格流程,满足权限与管控需求。
- 灵活便捷:兼顾不同企业场景,提供优化的应用管理体验。
扩展机制优化,架构灵活性再升级
- 敏捷交付,快速响应:支持功能模块的独立升级与发布,显著缩短新功能上线与问题修复的周期,提升整体交付效率。
- 架构灵活,按需扩展:提供丰富的扩展点与组件配置选项,满足多样化业务需求,支持平台能力的持续演进。
- 精准贴合业务场景:模块化设计使功能可组合、可裁剪,助力企业快速适配不同应用场景与使用习惯。
- 增强运维效能:简化运维流程,降低平台管理成本,提升系统稳定性与可控性。
KubeSphere 的价值支柱
- 企业级可靠性保障
- 经过 1000+ 头部客户真实生产环境验证
- 提供一站式保姆式专业技术支持服务
- 千锤百炼的稳定性与可靠性
- 云原生全栈能力
- 支持纳管云端、边缘、IDC 等任何地域或基础设施上的 K8s 集群
- 提供"三权分立"的多租户权限体系
- 实现资源与应用的细粒度统一管理、构建、运维与交付
- 极致的扩展性
- 基于 KubeSphere LuBan 架构的热插拔能力
- 50+ 扩展组件涵盖可观测性、AI、边缘计算、CI/CD 等核心领域
- 支持"积木式"定制专属操作系统
- 智能化运维体验
- 运维友好的向导式操作界面
- 智能化界面设计与功能整合
- 显著降低操作复杂性,提升交互效率
6. Kubernetes v1.34 预览
简介
Kubernetes v1.34 将于 2025 年 8 月底发布。此版本不会移除或弃用任何功能。
功能增强
-
DRA 核心目标稳定
DRA 提供了一种灵活的方式来分类、请求和使用诸如 GPU 或自定义硬件等设备。v1.34 版本中,DRA 的核心功能将达到稳定状态,resource.k8s.io/v1 API 将默认可用。这简化了 Pod 对设备的请求,并提供了更灵活的设备过滤和集中式设备分类。
-
用于镜像拉取认证的 ServiceAccount 令牌
kubelet 将可以使用 ServiceAccount 令牌进行镜像拉取认证,这将取代长期存在的镜像拉取密钥,降低安全风险,支持工作负载级别的身份,并减少运维开销。该功能将达到 Beta 版本并默认启用。
-
Deployment 的 Pod 替换策略
新增 .spec.podReplacementPolicy 字段 (alpha 版本),允许选择 TerminationStarted (旧 Pod 开始终止时创建新 Pod) 或 TerminationComplete (旧 Pod 完全终止后创建新 Pod) 策略,从而更好地控制资源消耗和滚动更新速度。
-
适用于 kubelet 和 API 服务器的生产级跟踪
kubelet 和 API Server 将提供基于 OpenTelemetry 标准的生产就绪追踪功能,这使得对节点级问题的调试更加容易,可以通过关联日志来追踪事件的生命周期,从而快速定位延迟和错误的来源。该功能将达到稳定状态。
-
服务的 PreferSameZone 和 PreferSameNode 流量分配
spec.trafficDistribution 字段新增 PreferSameZone (与现有的 PreferClose 等效) 和 PreferSameNode (优先将流量发送到与客户端位于同一节点的端点) 选项,该功能将达到 Beta 版本并默认启用。
-
支持 KYAML:一种 Kubernetes 风格的 YAML
KYAML 是一种更安全、更清晰的 YAML 子集,旨在解决 YAML 中的歧义问题。v1.34 版本的 kubectl 将支持 KYAML 作为输出格式。
-
具有 HPA 可配置容差的细粒度自动缩放控制
拓展阅读
KYAML 的简介与相关讨论:
- KEP-5295: Introducing KYAML, a safer, less ambiguous YAML subset / encoding
- KYAML: Looks like JSON, but named after YAML
📰 专题二 新闻与访谈
1. Higress 在 KubeSphere Marketplace 上架,助力企业构建云原生流量入口
Higress 上架 KubeSphere Marketplace,助力企业构建云原生流量入口
Higress 是什么
Higress 是基于 Istio + Envoy 架构构建的高性能、可扩展的云原生网关,具备流量治理、安全防护、协议转发、可观测性等核心能力。此次通过扩展组件方式入驻 KubeSphere Marketplace,不仅进一步降低部署门槛,也增强了与 K8s 场景的深度适配,支持用户以更低成本构建统一流量治理体系。
Higress 诞生于阿里巴巴内部,旨在解决 Tengine reload 影响长连接服务以及 gRPC/Dubbo 负载均衡能力不足的问题。在阿里云内部,Higress 的 AI 网关能力支撑着统一百炼模型工作室、机器学习 PAI 平台等核心 AI 应用以及其他关键 AI 服务。阿里云基于 Higress 构建了云原生 API 网关产品,为海量企业客户提供 99.99% 网关高可用保障的服务能力。
上架后的效果是什么
借助 KubeSphere 的图形化控制台,用户可以一键部署 Higress 并完成配置,实现可视化的服务治理与策略编排。操作步骤见原文。
2. Kubernetes 中的高性能网络 DraNet 进入 Beta 测试阶段!
DraNet Enters Beta! High-Performance Networking in Kubernetes
DraNet 是什么
DRANET 是一个 Kubernetes 网络驱动程序,它使用动态资源分配 (DRA) 为 Kubernetes 中要求苛刻的应用程序提供高性能网络。
主要特点:
- DRA 集成: 利用 Kubernetes 动态资源分配的强大功能。
- 高性能网络: 专为 AI/ML 应用等高要求工作负载而设计。
- 简化管理: 易于部署和管理。
- 增强效率: 优化资源利用率,提高整体性能。
- 集群范围的可扩展性: 有效管理大量节点之间的网络资源,以实现 Kubernetes 部署中的无缝操作。
Google 为什么选择 DraNet
DraNet 提供了一种原生且声明式的解决方案,显著简化了高性能网络接口的管理和配置,解决了现有 Kubernetes 网络解决方案在运行 AI 和 HPC 工作负载时存在的不足。主要体现在以下几点:
- 简化 RDMA 管理: 避免了 CNI 链和设备插件的复杂组合,提供统一且无缝的用户体验。
- 声明式接口调整: 允许直接在 Kubernetes 清单中设置接口属性,无需自定义脚本或 init 容器,从而简化了例如禁用 eBPF 程序或设置特定 NIC 参数等操作。
- 独立且安全: 作为独立二进制文件运行在无发行版容器中,减少了攻击面和安全更新频率。通过稳定的内核 API (netlink) 直接与内核交互,避免了对第三方项目的依赖,提高了弹性和性能。
- 轻量且快速: 小巧的容器镜像 (小于 50MB) 加快了节点启动时间,从而加快了工作负载的部署和扩展。
未来计划
目前 DraNet 处于 beta 版本,未来的计划是继续积极开发,最终发布 GA (General Availability) 版本。这与 Kubernetes 动态资源分配 (DRA) KEP 的成熟度密切相关。
3. Amazon EKS 宣布支持高达 10 万个节点的集群
Under the hood: Amazon EKS ultra scale clusters
Amazon EKS 支持高达 10 万节点集群,这使得单一 Kubernetes 集群能够运行多达 160 万个 AWS Trainium 芯片或 80 万个 NVIDIA GPU,从而解锁超大规模 AI/ML 工作负载。
Amazon 认为单一超大规模集群相比于多集群架构在 AI/ML 工作负载方面的优势,主要体现在降低计算成本、简化集中式运维以及提高 ML 框架兼容性三个方面。
EKS 还在以下方面进行超大规模的关键技术改进:
- 下一代数据存储 (etcd): 通过将 etcd 的共识后端从 Raft 迁移到 AWS 自研的 Journal 系统,并采用内存数据库 (tmpfs) 和键空间分区技术,显著提升了 etcd 的性能和可扩展性。
- 极高吞吐量 API 服务器: 通过 API 服务器和 webhook 调优、利用 Kubernetes 的一致性缓存读取、高效读取大型集合以及使用 CBOR 编码等技术,大幅提升了 API 服务器的读写吞吐量和效率。
- 闪电般快速的集群控制器: 通过最小化锁竞争、调度优化以及批量处理等手段,提高了 Kubernetes 控制器和调度器的处理效率。
- Karpenter 增强: 引入了静态容量支持和 Capacity Blocks,并优化了自动修复和漂移功能,以更好地支持超大规模 AI/ML 工作负载。
- 集群网络扩展: 使用 IP 前缀模式管理 IP 地址,并支持多网卡,从而提高了网络带宽和性能。
- 快速容器镜像拉取: 使用 Seekable OCI (SOCI) 快速拉取和并行解压技术,加快了容器镜像下载和解压速度。
测试结果见原文。
相关 Reddit 讨论:
EKS Ultra Scale Clusters (100k Nodes)
Amazon EKS Now Supports 100,000 Nodes
🎤 10 万个,oh my...
4. 思科向 Linux 基金会捐赠 AGNTCY 项目
Cisco Donates the AGNTCY Project to the Linux Foundation
AGNTCY 项目为代理协作提供了完整的基础架构堆栈——可跨任何供应商或框架运行的发现、身份、消息传递和可观察性。它是基础层,可让专业代理相互查找、验证功能并协同解决复杂问题。该项目来自思科内部的 Outshift 孵化器,并于 2025 年 3 月开源。它包括规范、代码和服务,从类似于用于代理通信和代理目录的 DNS 系统的发现层,到用于验证代理身份的工具、可观察性框架以及用于调用和配置远程代理的协议 。
AGNTCY 并非旨在取代 Google 的 Agent2Agent 或 Anthropic 的 MCP 等协议,而是致力于构建支持智能体安全可靠通信的完整基础设施,以避免 AI 智能体生态系统因厂商壁垒而碎片化,最终目标是建立一个“代理互联网”,实现分布式智能体间的竞争与协作。
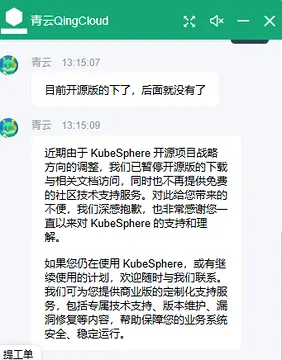
5. KubeSphere 暂停开源版的下载与文档访问
💬 专题三 讨论与分享
1. Fluentd 与 Fluent Bit 的对比
A Guide To Migrating From Fluentd To Fluent Bit
特性对比
| 特性 | Fluentd | Fluent Bit |
|---|---|---|
| 简介 | Fluentd 是一个数据收集器,它统一了数据收集和使用,以便更好地理解和利用数据。它具有丰富的插件生态系统。 | Fluent Bit 是一个轻量级日志处理器和转发器,特别为高吞吐量、低 CPU 和内存消耗的场景而设计。 |
| 编写语言 | Ruby,最初旨在帮助用户将数据推送到 Hadoop 等大数据平台。 | C,专注于在小型系统(容器、嵌入式 Linux)中实现超高性能。该 |
| 架构 | 采用分布式架构,在安装和部署主二进制文件后,才会安装插件。 | 集成式插件架构。项目借鉴了 Fluentd 的插件,并选择了作为核心二进制文件一部分的完全嵌入式插件。 |
| 性能 | 较低 | 高 |
| 自定义处理 | 使用 Ruby 脚本,性能瓶颈明显。 | 使用 Lua 脚本,高性能,可用于大规模处理。 |
| 监控 | 需要额外配置监控插件,维护成本高。 | 内置监控功能,提供更全面的指标信息。 |
用户从 Fluentd 切换到 Fluent Bit 的原因:
- 使用相同的资源,获得更高的性能
- OpenTelemetry 全面支持日志、指标和跟踪,Prometheus 也支持指标
- 更简单的配置和路由能力到多个位置
- 更快添加自定义处理规则
- 集成监控以更好地了解性能和数据流
拓展阅读
简要:本版本引入了强大的 OpenTelemetry 接口,提升编码解码能力;增强 Lua 脚本支持 OTLP 元数据访问;支持非 UTF-8 日志的字符编码转换;新增 AWS IAM 对 Kafka/MSK 的支持,同时带来性能提升、NFS-tail 修复及其他多项改进。
Fluent Bit, a Specialized Event Capture and Distribution Tool
总结:Fluent Bit 是一个专门用于捕获和分发事件的工具。它能够处理日志、指标和追踪信息,并以接近实时的速度处理这些事件,从而实现事件驱动。Fluent Bit 的特点在于它能够帮助我们快速识别和解决系统问题,无论是简单的日志信息还是复杂的分布式系统故障。它能够从多个来源收集数据,并将其聚合到一个安全的地方,从而避免数据丢失,并提供完整的系统视图。此外,Fluent Bit 易于将数据分发到不同的工具,以便进行不同的任务处理,例如告警和分析。Fluent Bit 是 CNCF 的毕业项目,拥有良好的社区支持和广泛的应用。
2. 通过自定义聚合增强 Kubernetes Event 管理
Kubernetes Event 的挑战
在 Kubernetes 集群中,从 Pod 调度、容器启动到卷挂载和网络配置, 各种操作都会生成 Event。虽然这些 Event 对于调试和监控非常有价值, 但在生产环境中出现了几个挑战:
- 量:大型集群每分钟可以生成数千个 Event
- 保留:默认 Event 保留时间限制为一小时
- 关联:不同组件的相关 Event 不会自动链接
- 分类:Event 缺乏标准化的严重性或类别分类
- 聚合:相似的 Event 不会自动分组
Event 聚合系统的价值
- 传统的 Event 聚合过程: 工程师浪费数小时筛选分散在各个命名空间中的成千上万的独立 Event。 等到他们查看时,较旧的 Event 早已被清除,将 Pod 重启与节点级别问题关联实际上是不可能的。
- 在自定义 Event 中使用 Event 聚合器: 系统跨资源分组 Event, 即时浮现如卷挂载超时等关联模式,这些模式出现在 Pod 重启之前。 历史记录表明,这发生在过去的流量高峰期间,突显了存储扩缩问题, 在几分钟内而不是几小时内发现问题。
这种方法的好处是,实施它的组织通常可以显著减少故障排除时间, 并通过早期检测模式来提高系统的可靠性。
具体如何构建等具体信息见原文。
3. 主权云是什么
简介
主权云是一种帮助组织遵守特定地区和国家法律的云计算。
背景
随着越来越多的企业寻求混合云解决方案来助力其数字化转型,云环境(尤其是用户如何访问、存储和使用云环境中的数据)正变得越来越重要。随着云计算在全球范围内的持续扩张,传统的地理界限(例如国界)已不足以保护敏感数据。
主权云,一个涵盖数据主权、运营主权和数字主权的概念。主权云帮助企业在遵守运营所在地区的法律法规的同时,建立客户信任,发展业务。
主权云保护什么
主权云主要保护消费者和组织数据。虽然许多法规主要侧重于保护个人身份信息 (PII) ,具体取决于行业、地区或业务用例,但它们也可以保护知识产权 (IP)、 软件、商业机密、财务信息等。由于不同国家和地区的云数据隐私法规各不相同,因此对于主权云可以保护的内容,并没有一个统一的、公认的定义。具体方法往往因行业、地点和业务需求而异。
一些主权云框架处理数据驻留问题 ,即数据受其存储地所在国家/地区的法律法规约束。另一些框架则处理数据主权问题,即存储的数据受其收集地所在国家/地区的法律约束。最终,主权云方法不仅可以帮助企业遵守与其最敏感数据相关的法律,还能帮助他们保持弹性。
主权云的优势
- 更多的组织控制
- 更好的合规性
- 更严格的用户限制
- 提高运营弹性
- 高度安全的加密
关键成果
-
数据主权
企业对其数据的控制权,确保数据遵守数据生成地或存储地的法律法规。 -
运营主权
企业对其云基础设施和运营流程的控制权,确保服务的持续性和可靠性。 -
数字主权
企业对其所有数字资产(数据、软件、内容和数字基础设施)的控制权和管理能力。
拓展阅读
The Sovereign Cloud Imperative
4. 处理带设备 Pod 的故障
Navigating Failures in Pods With Devices
背景
AI/ML 工作负载的兴起给 Kubernetes 带来了新的挑战。这些工作负载通常严重依赖于专用硬件,任何设备故障都可能严重影响性能并导致令人沮丧的中断。正如 2024 Llama 论文中所强调的那样,硬件问题(尤其是 GPU 故障)是导致 AI/ML 训练中断的主要原因。
然而,Kubernetes 对资源的认知仍然非常静态。资源要么存在,要么不存在。如果存在,Kubernetes 会假设它会保持完整功能——Kubernetes 缺乏对处理全部或部分硬件故障的良好支持。这些长期存在的假设,加上整体设置的复杂性,导致了各种故障模式。
了解 AI/ML 工作负载
一般来说,所有 AI/ML 工作负载都需要专用硬件,具有严格的调度要求,并且在空闲时成本高昂。AI/ML 工作负载通常分为两类:训练和推理。以下是这两类工作负载特征的简化视图,它们与 Web 服务等传统工作负载有所不同:
-
训练
这些工作负载资源密集,通常会占用整台机器,并以多个 Pod 组的形式运行。训练作业通常“运行至完成”——但这可能需要几天、几周甚至几个月的时间。任何一个 Pod 发生故障都可能导致所有 Pod 重启整个步骤。 -
推理
这些工作负载通常长时间运行或无限期运行,规模可能小到足以占用节点的部分设备,也可能大到跨越多个节点。它们通常需要下载包含模型权重的大型文件。
故障模式
1. Kubernetes 基础设施
在节点上调度 Pod 时,事件的顺序如下:
- 设备插件被调度到节点上
- 设备插件通过本地 gRPC 注册到 kubelet
- Kubelet 使用设备插件来监测设备并更新节点的容量
- 调度器根据更新后的容量将用户 Pod 放置到节点上
- Kubelet 请求设备插件为用户 Pod 分配设备
- Kubelet 创建一个用户 Pod,并将已分配的设备附加到该 Pod

异常情况可能为:
- Pod 在其生命周期的各个阶段都无法进入
- Pod 无法在完好的硬件上运行
- 调度耗时过长
Kubelet 已经实现了重试、宽限期和其他技术来改进它。路线图部分详细介绍了 Kubernetes 项目跟踪的其他边缘情况。然而,所有这些改进只有遵循以下最佳实践才能发挥作用:
- 尽早配置并重启 kubelet 和容器运行时(例如 containerd 或 CRI-O),以免中断工作负载
- 监控设备插件健康状况并仔细规划升级
- 不要让不太重要的工作负载加重节点的负担,以防止设备插件和其他组件中断
- 配置用户 pod 容忍度来处理节点就绪情况
- 仔细配置和编写优雅终止逻辑,以免阻塞设备太久
2. 设备故障
目前,Kubernetes 中对设备故障的处理非常有限。设备插件仅通过更改可分配设备的数量来报告设备故障。Kubernetes 依赖于诸如存活探测或容器故障之类的标准机制,允许 Pod 将故障情况传达给 kubelet。然而,Kubernetes 不会将设备故障与容器崩溃关联起来,并且除了在连接到同一设备的情况下重启容器之外,没有提供任何缓解措施。
3. 容器代码失败
当容器代码失败或发生其他问题时,例如内存不足,Kubernetes 知道如何处理这些情况。这包括容器的重启,或者如果 Pod 的 restartPolicy: Never,则会使 Pod 崩溃并将其调度到另一个节点上。Kubernetes 在定义何为故障(例如,非零退出代码或存活探针失败)以及如何对这类故障做出反应(通常是“始终重启”或“立即使 Pod 失败”)方面,表达能力有限。
这种程度的表达能力通常不足以应对复杂的 AI/ML 工作负载。AI/ML Pod 最好在本地甚至就地重新调度,因为这样可以节省镜像拉取时间和设备分配时间。AI/ML Pod 通常互连,需要同时重启。这又增加了一层复杂性,对其进行优化通常可以显著节省 AI/ML 工作负载的运行成本。
4. 设备性能下降
并非所有设备故障都会对整体工作负载或批处理作业造成致命影响。随着硬件堆栈变得越来越复杂,硬件堆栈某一层的配置错误或驱动程序故障可能会导致设备正常运行,但性能滞后。一台设备的性能滞后可能会拖慢整个训练作业的速度。
Kubernetes 目前无法准确描述此类故障,而且由于它是最新的故障模式,硬件供应商提供的检测最佳实践并不多,第三方工具也不足以修复此类情况。
通常,这些故障是根据观察到的工作负载特征来检测的。例如,特定硬件上 AI/ML 训练步骤的预期速度。这些问题的补救措施高度依赖于工作负载的需求。
改进路线图
具体见原文。
5. 云原生环境中的镜像兼容性
背景
在电信、高性能或 AI 计算等必须高度可靠且满足严格性能标准的行业中,容器化应用通常需要特定的操作系统配置或硬件支持。 通常的做法是要求使用特定版本的内核、其配置、设备驱动程序或系统组件。 尽管存在开放容器倡议 (OCI) 这样一个定义容器镜像标准和规范的治理社区, 但在表达这种兼容性需求方面仍存在空白。为了解决这一问题,业界提出了多个提案,并最终在 Kubernetes 的节点特性发现 (NFD) 项目中实现了相关功能。
NFD 是一个开源的 Kubernetes 项目,能够自动检测并报告集群节点的硬件和系统特性。 这些信息帮助用户将工作负载调度到满足特定系统需求的节点上,尤其适用于具有严格硬件或操作系统依赖的应用。
容器镜像是基于基础镜像构建的,基础镜像提供了最小的运行时环境,通常是一个精简的 Linux 用户态环境, 有时甚至是完全空白或无发行版的。 当应用需要来自主机操作系统的某些特性时,就会出现兼容性问题。这些依赖可能表现为以下几种形式:
- 驱动程序: 主机上的驱动程序版本必须与容器内的库所支持的版本范围相匹配,以避免兼容性问题,例如 GPU 和网络驱动。
- 库或软件: 容器必须包含某个库或软件的特定版本或版本范围,才能在目标环境中以最优方式运行。 高性能计算方面的示例包括 MPI、EFA 或 Infiniband。
- 内核模块或特性: 必须存在特定的内核特性或模块,例如对写入保护巨页错误的支持,或存在对 VFIO 的支持。
- 以及其他更多形式...
虽然在 Kubernetes 中容器是这些需求最常见的抽象单位,但兼容性的定义可以进一步扩展,包括 Singularity 等其他容器技术以及来自 spack 二进制缓存的二进制文件等 OCI 工件。
容器化应用被部署在各种 Kubernetes 发行版和云平台上,而不同的主机操作系统带来了兼容性挑战。 这些操作系统通常需要在部署工作负载之前预配置,或者它们是不可变的。例如,不同云平台会使用不同的操作系统。每种操作系统都具有独特的内核版本、配置和驱动程序,对于需要特定特性的应用来说,兼容性问题并不简单。 因此必须能够快速评估某个容器镜像是否适合在某个特定环境中运行。
解决方案
OCI 镜像兼容性工作组正在推动引入一个镜像兼容性元数据的标准。 此规范允许容器作者声明所需的主机操作系统特性,使兼容性需求可以被发现和编程化处理。 目前已在 Kubernetes 的 Node Feature Discovery 中实现了其中一个被讨论的提案,其目标包括:
- 在 OCI 镜像清单中定义一种结构化的兼容性表达方式。
- 支持在镜像仓库中将兼容性规范与容器镜像一同存储。
- 在容器调度之前实现兼容性自动验证。
这个理念目前已在 Kubernetes 的 Node Feature Discovery 项目中落地。这种解决方案通过 NFD 的特性机制和 NodeFeatureGroup API 将兼容性元数据集成到 Kubernetes 中。 此接口使用户可以根据硬件和软件暴露的特性将容器与节点进行匹配,从而实现智能调度与工作负载优化。
具体见原文。
6. Rancher 相关的三篇文章
1)Rancher Desktop 搭配 SUSE Application
Rancher Desktop 搭配 SUSE Application
Rancher Desktop 是一款开源桌面应用,简化了容器化应用的开发流程,提供本地 Kubernetes 集群和容器管理功能,支持多种容器运行时、跨平台兼容,并能模拟生产环境,方便开发者快速迭代。其核心优势包括:
- 精选开源组件:SUSE 提供经过测试和验证的开源软件版本,确保长期可维护性与稳定性。
- 安全与合规:SUSE 持续发布补丁与安全更新,帮助企业满足合规要求,强化安全防护。
- 透明可追溯:每个应用都附带软件清单(SBOMs)、来源证明(符合 SLSA Level 3 标准)以及已知漏洞(CVEs)列表,确保用户对组件的来源和风险一目了然。
- 开发工具集成:涵盖了常用的开发框架和工具,覆盖从编写代码到部署上线的全流程。
- 企业级支持:SUSE 提供专业的技术支持服务,助力开发与运维团队快速排障,降低宕机风险。
Rancher Desktop 是一款开源桌面应用,提供本地 Kubernetes 集群和容器管理功能。它专为开发者打造,简化了容器化应用的开发流程。其亮点功能包括:
- 轻松搭建本地 Kubernetes:一键启动本地集群,集成 kubectl、 helm 等常用工具,省去复杂配置。
- 多容器运行时支持:支持 containerd 和 Moby(Docker Engine),开发者可自由选择适配项目需求。
- 资源可控:支持为本地集群分配 CPU 和内存,优化性能同时保障主机系统流畅运行。
- 跨平台支持:兼容 Windows、macOS 和 Linux,适应不同开发者的操作系统环境。
- 贴近生产环境:本地开发环境高度模拟生产环境,快速验证修改,缩短迭代周期。
将 SUSE Application Collection 与 Rancher Desktop 结合使用,可以构建一个完整的、安全可靠的本地开发环境,从而提高开发效率和安全性,并满足企业对合规性的要求。
2)多团队共用集群太乱?用 Rancher+K3k 实现一人一套环境
多团队共用集群太乱?用 Rancher+K3k 实现一人一套环境
多团队共用集群的典型挑战:
- 资源冲突
多个团队抢占 CPU、内存等资源,极易导致某个任务拖慢甚至中断其他团队的工作流。 - 安全风险
一组的错误配置或漏洞可能波及到整个集群的安全,比如服务暴露、证书误用等问题。 - 配置受限
不同团队有不同需求,可能需要特定版本的 Kubernetes 或自定义的 Admission 配置,但由于共用集群,这些都难以实现。 - 运维干扰
即使划分了 namespace,很多组件如 Operator、CRD Controller 等还是全局生效,一个团队部署的全局资源可能误伤其他团队。
K3k 是在 Kubernetes 集群中部署 Kubernetes 工具,它提供了一种在 kubernetes 集群上运行多个嵌入式隔离的 k3s 集群的方法。K3k 的主要目标是为用户提供一个极其简单的方式来创建和管理 K3s 集群,尤其是对于需要在本地或开发环境快速启动集群的场景下,K3k 显得尤为强大。
K3k 具备以下两种模式:
- Virtual Mode(虚拟模式)
每个虚拟集群都有独立的 K3s Server 进程,具备完整隔离性,适用于高安全性要求场景。 - Shared Mode(共享模式)
共享模式使用 K3s server 作为控制平面,并采用 agentless servers configuration[1],K3k server 将不运行 kubelet、容器运行时或 CNI 显著节省资源,适合资源紧张的开发测试场景。
Rancher 原生集成 K3k 带来的能力包括:
- 在 Rancher UI 中选择宿主集群,一键创建 K3k 虚拟集群
- 支持选择虚拟或共享模式
- 自动为每个虚拟集群生成独立的 kubeconfig,实现真正隔离
- 将虚拟集群作为 Rancher 集群视图中的“一级公民”,可统一纳管、统一审计、统一权限管控
- 与现有 DevOps、CI/CD 流程无缝衔接
3)722 个版本的旅程,RKE 即将告别,未来交给 RKE2 与 K3s
Rancher 社区双周报| 722 个版本的旅程,RKE 即将告别,未来交给 RKE2 与 K3s
RKE EOL
RKE 将于 2025 年 7 月 31 日正式结束生命周期(EOL)。这标志着 RKE 自 2018 年 1 月首次发布以来的七年旅程进入尾声,同时也为广大用户迈向 RKE2 或 K3s 开启了新的篇章。
RKE 使用的 Docker 运行时已不再被 Kubernetes 官方维护,自 1.24 起彻底移除。相比之下,RKE2 默认采用 containerd,不仅提升运行效率,也更符合当前主流的容器标准。
强烈建议仍在使用 RKE 的用户尽快规划迁移至 RKE2 或 K3s。但 RKE 无法原地升级为 RKE2 或 K3s,迁移需新部署目标集群并迁移业务工作负载。推荐优先评估现有集群状态与工作负载类型,制定分阶段迁移计划。
K3k v0.3.3
支持 air-gap 离线环境部署,增强私有化场景适配;
引入 VirtualClusterPolicy 资源用于管理虚拟集群策略,将原 ClusterSet 重命名并明确作用域为 Cluster;
增强网络与服务暴露能力,支持自定义 dnsConfig、 LoadBalancerConfig 与 NodePortConfig;
- 修复 HA 初始化缩容问题、ephemeral 容器兼容性、k3kcli 命令删除逻辑等;
CLI 新增支持命令如 k3kcli cluster list 与 policy list,增强可观测性;
RKE2 发布了四个补丁版本
RKE2 近期发布了四个补丁版本,分别是 v1.30.14+rke2r1、v1.31.10+rke2r1、v1.32.6+rke2r1、v1.33.2+rke2r1,重点聚焦组件更新、安全加固与兼容性优化,建议各版本用户尽快关注并升级:
- CNI 插件更新:统一升级 canal、flannel、cilium、multus 和 whereabouts 插件,增强网络组件稳定性和兼容性。
- Windows 节点支持增强: uninstall.ps1 脚本支持静默卸载和非交互执行,便于自动化管理。
- etcd 独立配置支持:新增 support profile:etcd,用于增强 etcd 层面的配置灵活性。
- 核心依赖更新:包括 etcd、containerd、runc、crictl、cloud provider 等,提升整体安全性与执行效率。
- 控制面插件图表升级:更新 CoreDNS、Metrics Server、Ingress-NGINX 等 Helm Chart,并修复相关 CVE 漏洞。
- 测试体系优化回补:合入多项测试框架改进,增强发布稳定性。
- K3s 版本同步更新:与对应分支的 K3s 保持一致,保证用户在轻量集群场景下的使用体验。
- Kubernetes 补丁版本集成:升级至各主版本线的最新 Kubernetes 补丁(如 v1.30.14、v1.31.10 等),同步上游稳定性修复。
Harvester v1.5.1
版本聚焦于安全更新、组件升级与兼容性优化,建议用户根据所用分支及时升级。
NeuVector v5.4.5
版本聚焦于系统稳定性、扫描可靠性与安全检测能力的持续优化,建议用户升级以获得更好的安全防护体验。
7.保障 Kubernetes 1.33 Pod 安全:用户命名空间隔离的影响
保障 Kubernetes 1.33 Pod 安全:用户命名空间隔离的影响
通过 Linux 内核的用户命名空间机制,将容器内的 UID/GID 重新映射到宿主机的非特权用户,从而实现进程隔离,防止横向攻击,并降低容器逃逸的风险。即使容器内运行 root 用户,在宿主机上也表现为非 root 用户,有效限制了对宿主机的访问权限。
虽然默认启用,但需要 Kubernetes 集群版本不低于 1.33,工作节点使用 Linux 内核 6.3 或以上版本,并支持 idmap 挂载,容器运行时也需满足特定版本要求(例如 containerd ≥ 2.0 或 CRI-O ≥ 1.25)。
启用该功能只需在 Pod 定义中设置 hostUsers: false。
具体见原文。
8. 裸机 Kubernetes:性能优势几乎消失
Bare-Metal Kubernetes: The Performance Advantage Is Almost Gone
过去十年,裸机在运行 Kubernetes 和容器基础设施时,相比虚拟机抽象层上的容器,展现了性能优势。与虚拟机 (VM) 或容器不同,裸机节点是指没有任何虚拟化层的机器。物理服务器直接在物理基础设施上运行操作系统或应用程序,而不是通过虚拟机管理程序或容器引擎。这两种环境对容器的规模部署、隔离和其他考虑因素有着重要的影响。人们认为裸机的开销更小。
在裸机配置中,命名空间仅强制执行“软”资源限制。软资源限制是指操作系统不严格执行的分配。通过命名空间,如果其他工作负载需要这些资源,则可以超出这些限制。这意味着,虽然资源(例如 CPU 和内存)已分配给容器或进程,但并不能保证它们可用。其他进程可能会占用这些资源,从而可能影响性能。
当时,技术方案是合理的。但自那时起,IT 复杂性不断增加,技术团队需要支持多种工作负载、实施更严格的安全措施、满足更严格的 SLA,并采用云运营模式。现在,性能差距显然正在缩小。
基于虚拟机的部署在虚拟机管理程序级别强制执行“硬”资源限制(例如 CPU、内存和磁盘)。硬资源限制是严格执行的,这意味着分配的资源将被保留,并且不能被其他工作负载使用,无论系统上其他地方的需求如何。这种严格的执行方式为租户之间提供了强大的隔离。虚拟机隔离与硬资源限制之间的关系是直接的。由于虚拟机隔离是通过虚拟机管理程序强制执行硬资源限制来实现的,因此公有云提供商可以更精确地保证服务级别协议 (SLA)。
与此同时,如果没有通过硬资源限制实现虚拟机隔离,“吵闹邻居”问题将变得更加普遍。在多租户环境中,CPU 或内存密集型工作负载的性能干扰可能会降低其他工作负载的体验,因为单靠软资源限制无法阻止一个工作负载对另一个工作负载的影响。例如,在分析来自望远镜馈送的大量天体物理数据时,一个行为异常的容器可能会垄断资源并影响整个集群的稳定性。
此前,在裸机和虚拟机上运行的 Kubernetes 之间存在显著的性能差距,但最近的基准测试表明,这种差距正在变得越来越小。因此,这些结果进一步质疑了依赖裸机而非容器化基础设施的主要优势。然而,性能基准测试表明,这些优势已经减弱。

根据基准测试(ReveCom 尚未验证这些结果,但很快就会验证),在虚拟机层上运行的容器表明其性能已基本赶上裸机服务器。Broadcom VMware 基准测试报告将 vSphere 8 与裸机硬件进行了比较,结果显示两者之间的差异几乎可以忽略不计,并且延迟更低,具体取决于 CPU 配置。具体见:VMware vSphere 8.0 Virtual Topology: Performance Study。
对于使用 vGPU 的 AI/ML 工作负载, MLperf 基准测试显示, 与裸机相比,Broadcom 的 VMware Cloud Foundation VM 平台实例可保留 99% 的性能 。具体而言,测试结果基于在 SuperMicro SuperServer SYS-821GE-TNRT 和 Dell PowerEdge XE9680 上使用 MLCommons 和 VMware vSphere 8.0 U3 虚拟化的 MLPerf Inference v5.0 工作负载。这些结果表明,在 GPU 环境中运行 AI/ML 工作负载的虚拟化可显著降低成本。
对于绝大多数工作负载而言,在裸机上运行 Kubernetes 和容器所能获得的性能优势微乎其微。当然,这并不意味着它们永远不会带来好处——只是在权衡裸机部署固有的风险和虚拟化带来的优势时,它们并不适用于大多数用例。
如上所述,裸机始终存在安全隐患。工作负载运行在同一个内核上,因此一旦攻击者访问服务器操作系统,就意味着整个工作负载(所有工作负载)都可被访问。相反,当容器在虚拟机上运行时,由于虚拟机的隔离配置,受到威胁的单个容器、集群或应用程序仍保持隔离。
📄 专题四 报告查看与分析
1. [Red Hat] The state of virtualization
背景
Red Hat 赞助了一项由 Illuminas 进行的调查,调查对象是来自美国、英国和英语亚太地区(APAC)的 1,010 名 IT 决策者(ITDM)和虚拟化实践者。调查旨在揭示当前虚拟化平台的现有痛点,识别阻碍迁移到替代平台的关键障碍,并确定未来成功的虚拟化应具备哪些特征。红帽与 Illuminas 合作,通过对从第三方数据库获取的受访者进行 15 分钟的在线访谈,收集并分析了数据。该调查于 2025 年 3 月和 4 月进行。
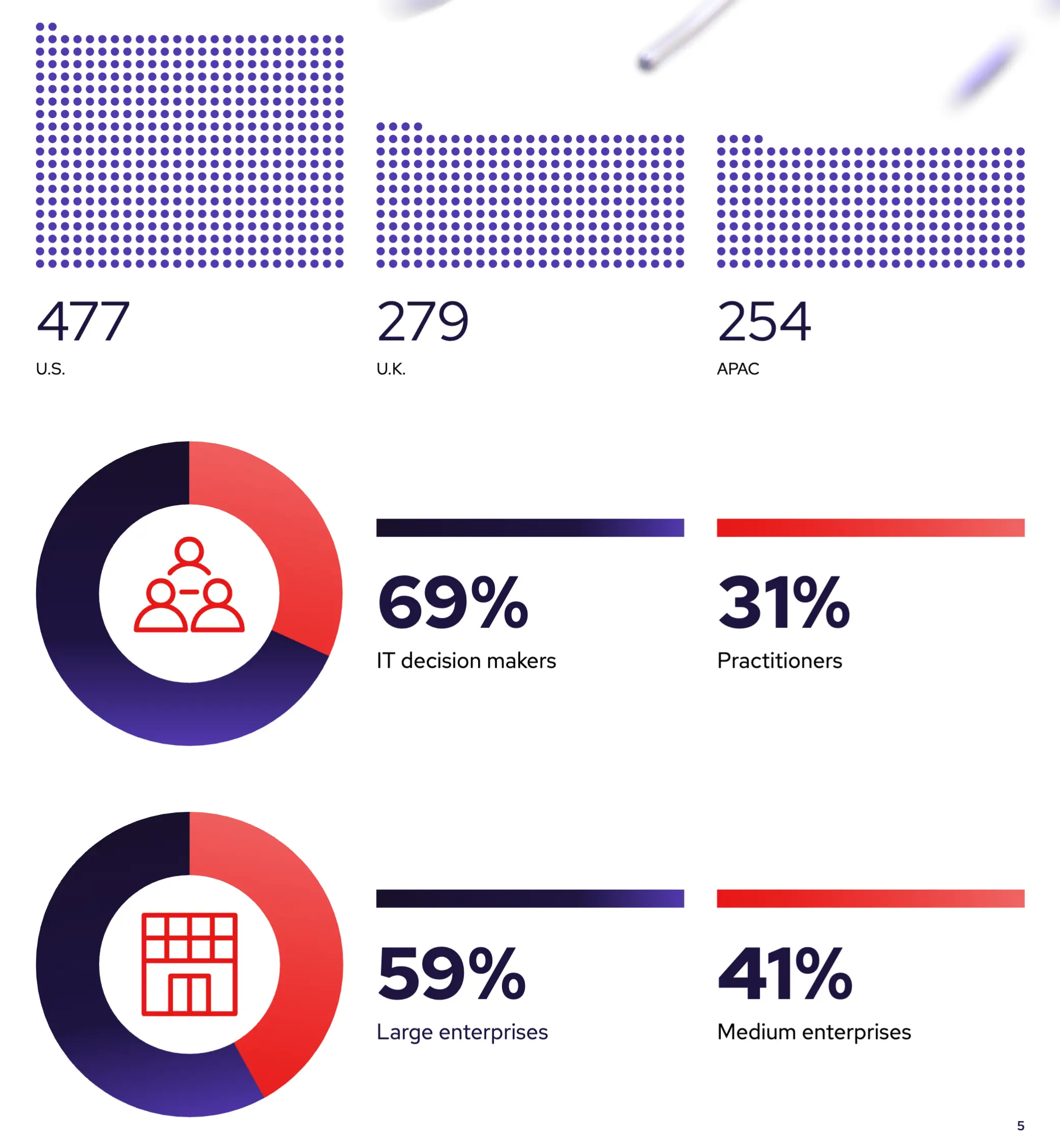
主要结论
企业 IT 是云端驱动和虚拟化
72% 的组织正在使用多云,85% 的组织正在使用混合云模式。这凸显了组织 IT 环境中通常需要同时管理的多样化基础架构,并表明组织渴望实现云平台之间的互操作性以提高效率。
为了保持竞争优势,企业正在优化混合虚拟化基础架构。虚拟化工作负载在各种各样的环境中运行,包括混合云提供商和本地数据中心。虚拟化工作负载运行环境的日益多样化凸显了对混合云解决方案的需求,这些解决方案能够在混合云和多云环境中提供标准化运营和精简管理。
公有云使用情况:
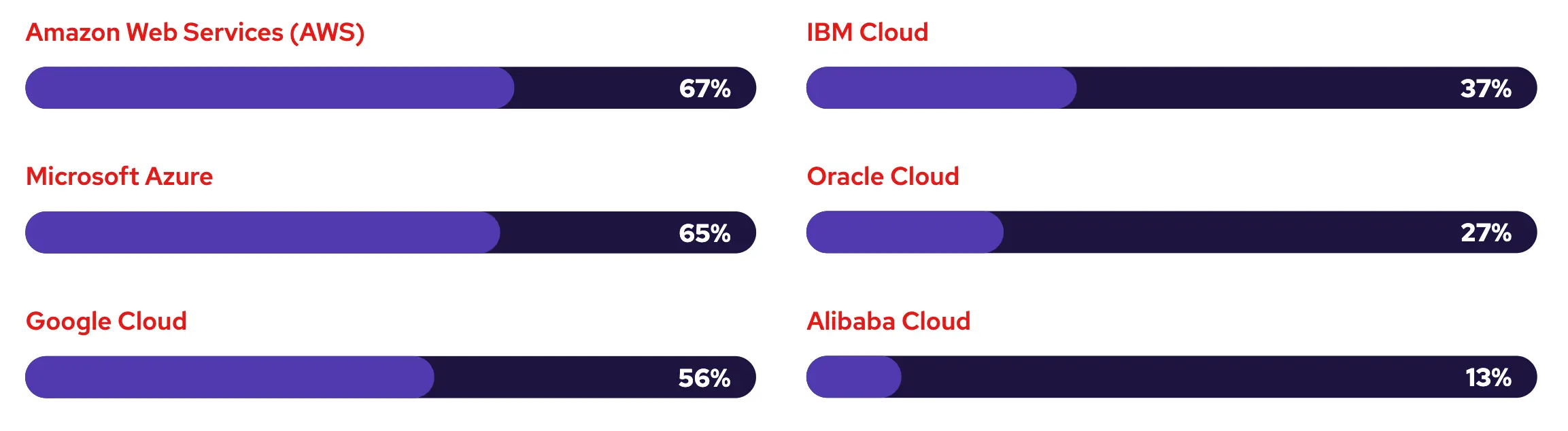
受访者确认,其 IT 基础架构的绝大部分已实现虚拟化,并应用了各种虚拟化技术。服务器虚拟化已被广泛采用且成熟,84% 的组织表示正在使用。其他类型的虚拟化,包括存储(81%)和网络(77%)虚拟化,也在组织中得到广泛采用,因为它们允许通过软件提高灵活性和对抽象物理堆栈的控制。
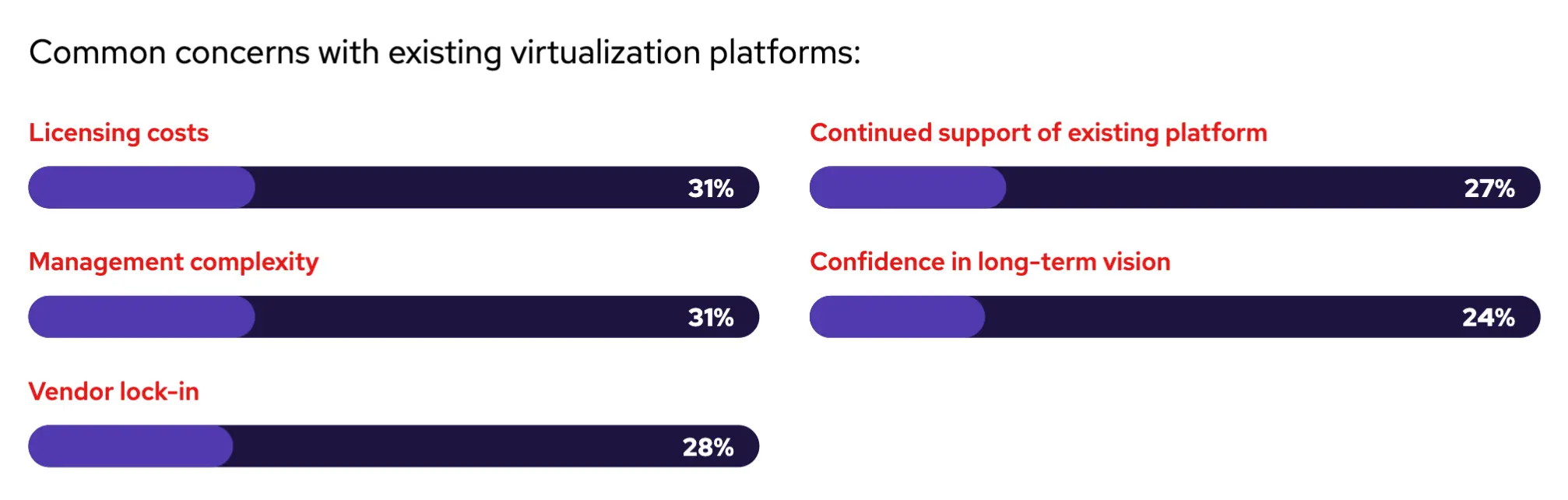
常见问题促使人们重新评估现有的虚拟化平台
受访者被要求指出他们对现有虚拟化平台的主要顾虑。受访者的回答涵盖了所有组织的各种因素,其中三分之一的受访者表示,许可成本和管理复杂性是他们现有虚拟化平台的主要顾虑。这可能源于许多因素,包括供应商许可证变更、价格上涨、具有不一致工具的多样化应用程序和环境以及过时的软件。对现有平台的持续支持(27%)和对长期愿景的信心(24%)也被认为是首要关注的问题,这表明对现有虚拟化平台的不信任。
虚拟化将继续存在,但平台需求正在不断发展
受访者被要求指出他们的组织在多大程度上已完全实现或超越了特定的虚拟化效益。总的来说,各组织对虚拟化在各种用例中能带来的成果感到满意。实现云战略(72%)、改进灾难恢复(72%)以及减少对硬件的依赖(68%)是一些被识别出的关键效益。
这表明了虚拟化在当今技术栈中持续的价值,它能简化和增强业务运营,并解释了为什么虚拟化与容器一起,在许多关键工作负载(包括业务关键型应用程序、数据库、文件存储和备份、高性能计算以及网络)中的使用量正在增长或至少保持稳定。

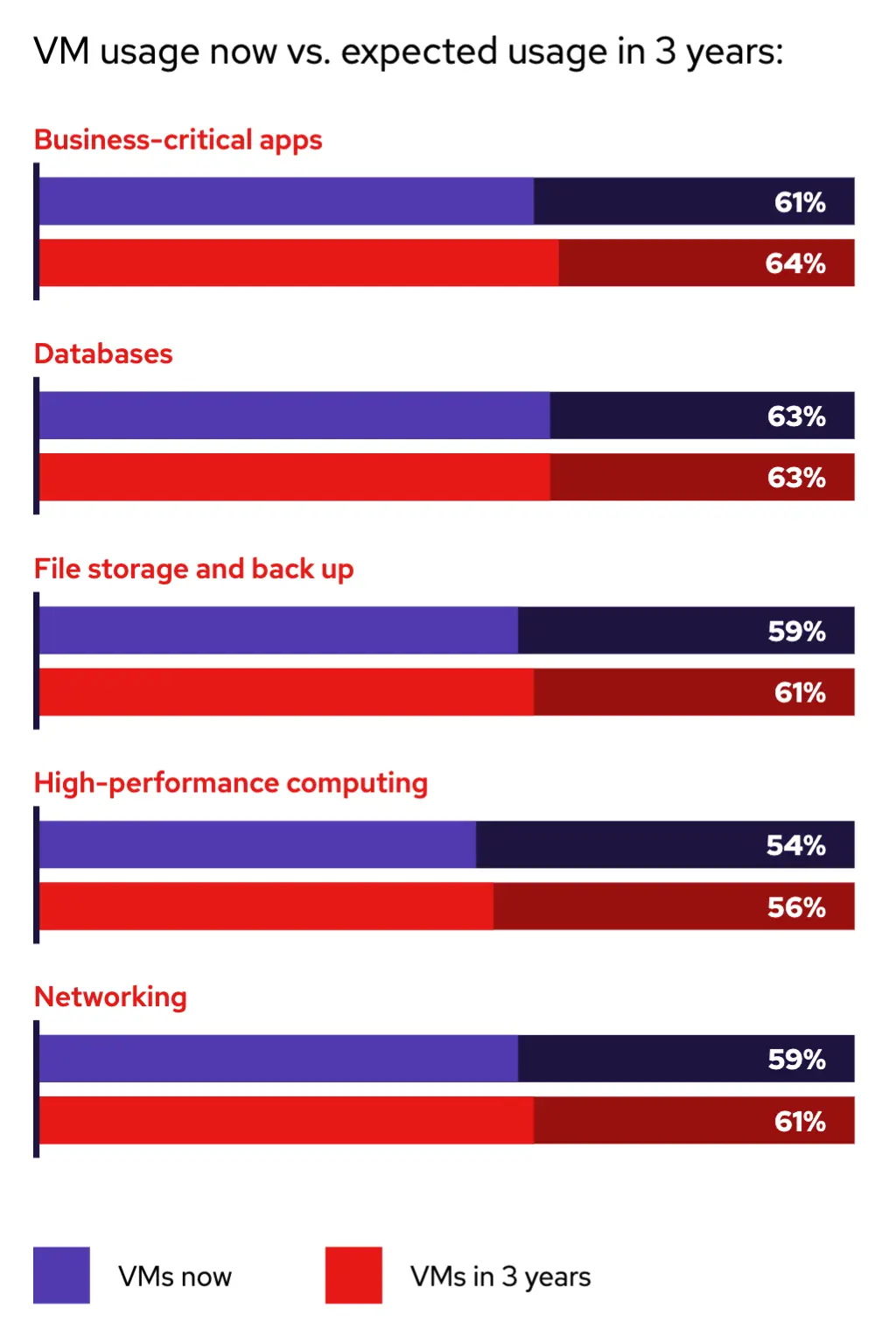
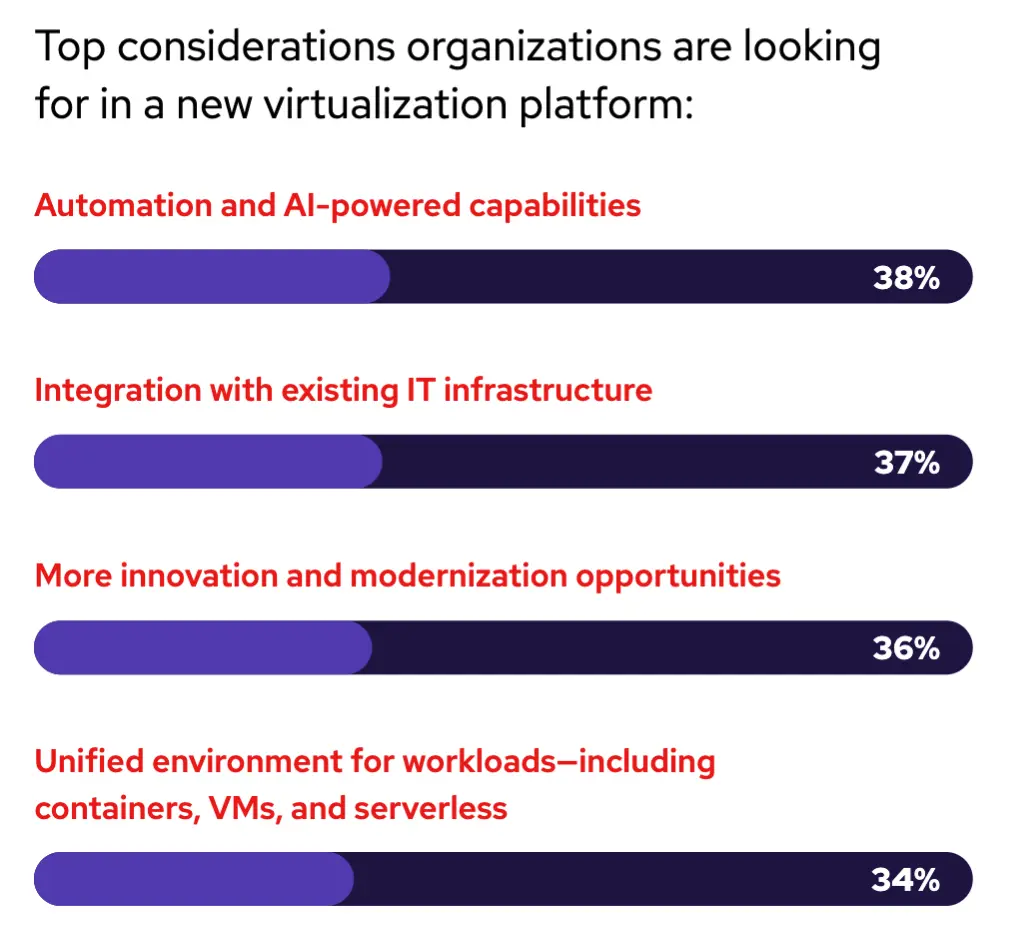
受访者预计将继续部署虚拟化工作负载和容器。研究表明,由于虚拟机将继续作为许多当前 IT 环境的支柱,虚拟化使用量预计将保持相对稳定。然而,预计未来几年,容器在一系列工作负载中的采用率也将上升。为了降低虚拟化和基于容器的平台的管理和维护成本方面的运营效率低下,许多组织正在寻找一个可以同时支持虚拟机和容器的统一平台,并可以选择在合适的地方应用现代应用程序开发和交付方法,因为容器预计未来 3 年工作量将增长 7%。

工作负载迁移不可避免,但过程并不总是顺利
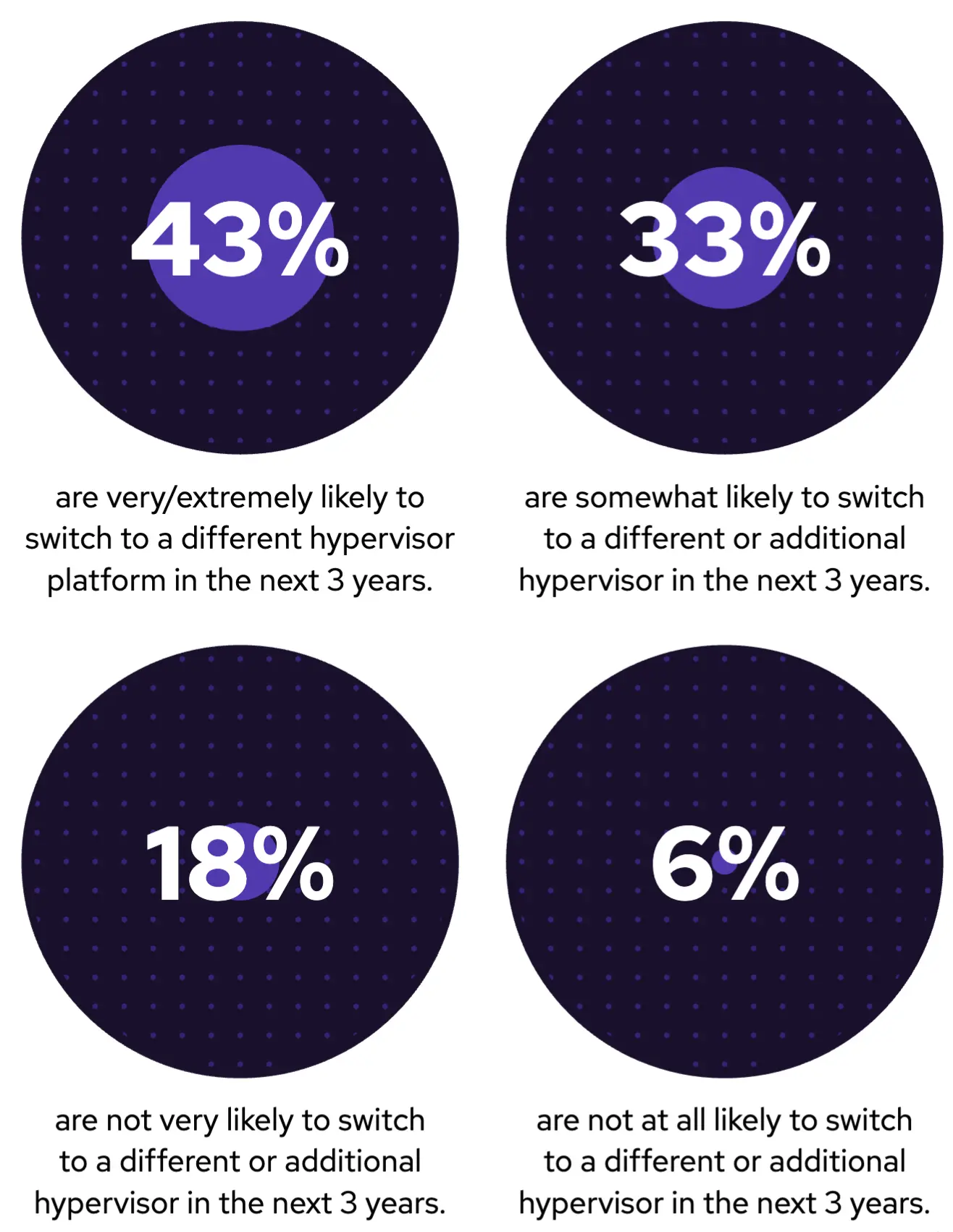
大多数受访企业表示,他们可能会在未来 3 年内迁移到其他虚拟机管理程序平台,其中 43%的企业表示“非常/极有可能”,33%的企业表示“有一定可能性”。如前所述,现有虚拟化平台面临的挑战涵盖了许可成本、管理复杂性等诸多方面(参见洞察#2)。
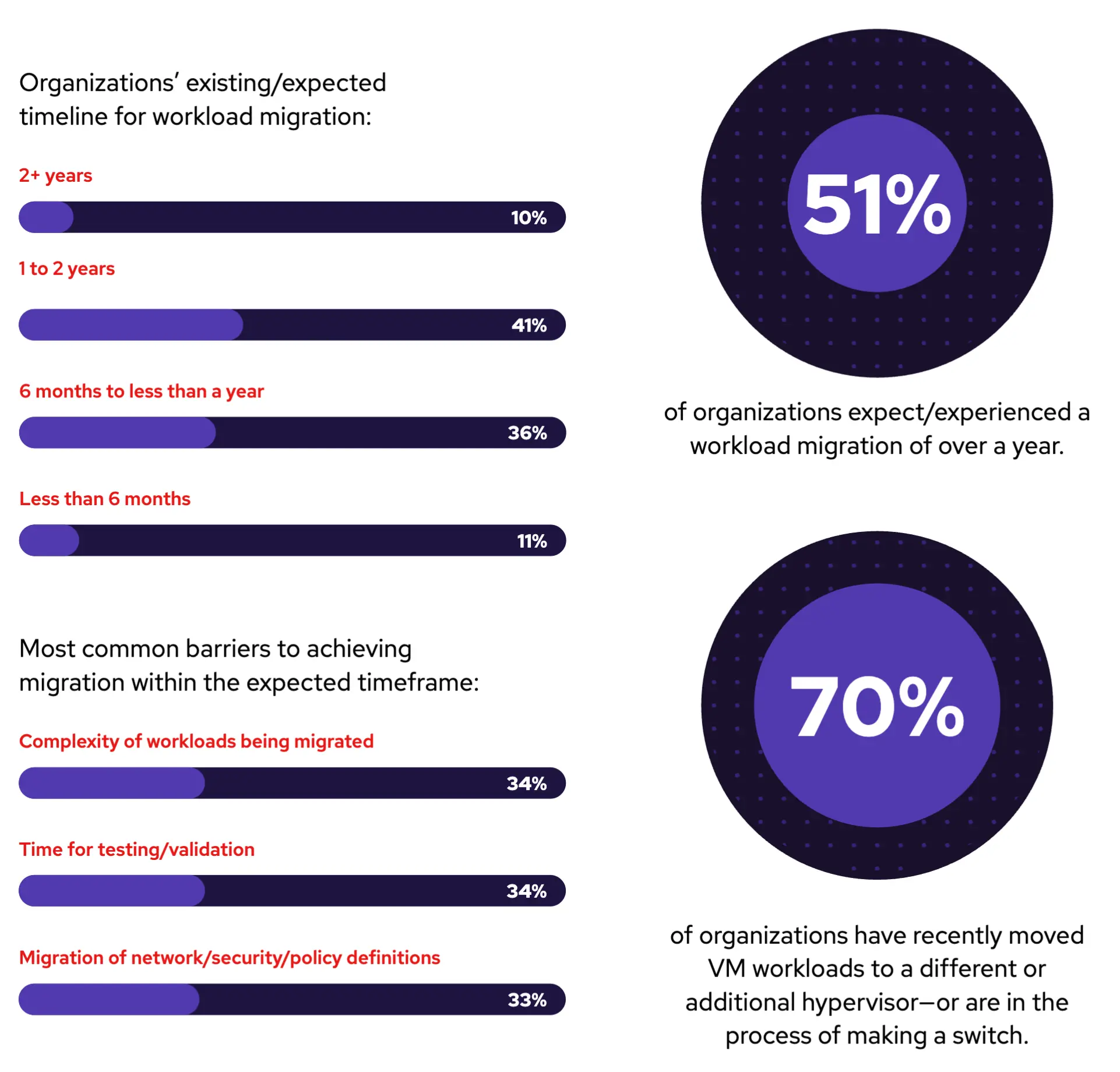
本次调查数据显示,大多数组织已经经历或预计将经历长达一年或更长时间的迁移,其中工作负载复杂性(34%)和测试验证时间(34%)是主要挑战。这意味着,组织越早开始规划将虚拟机管理程序迁移到能够高效执行迁移的平台上,就能获得更高的效率。
IT 的未来拥抱复杂性和多样性
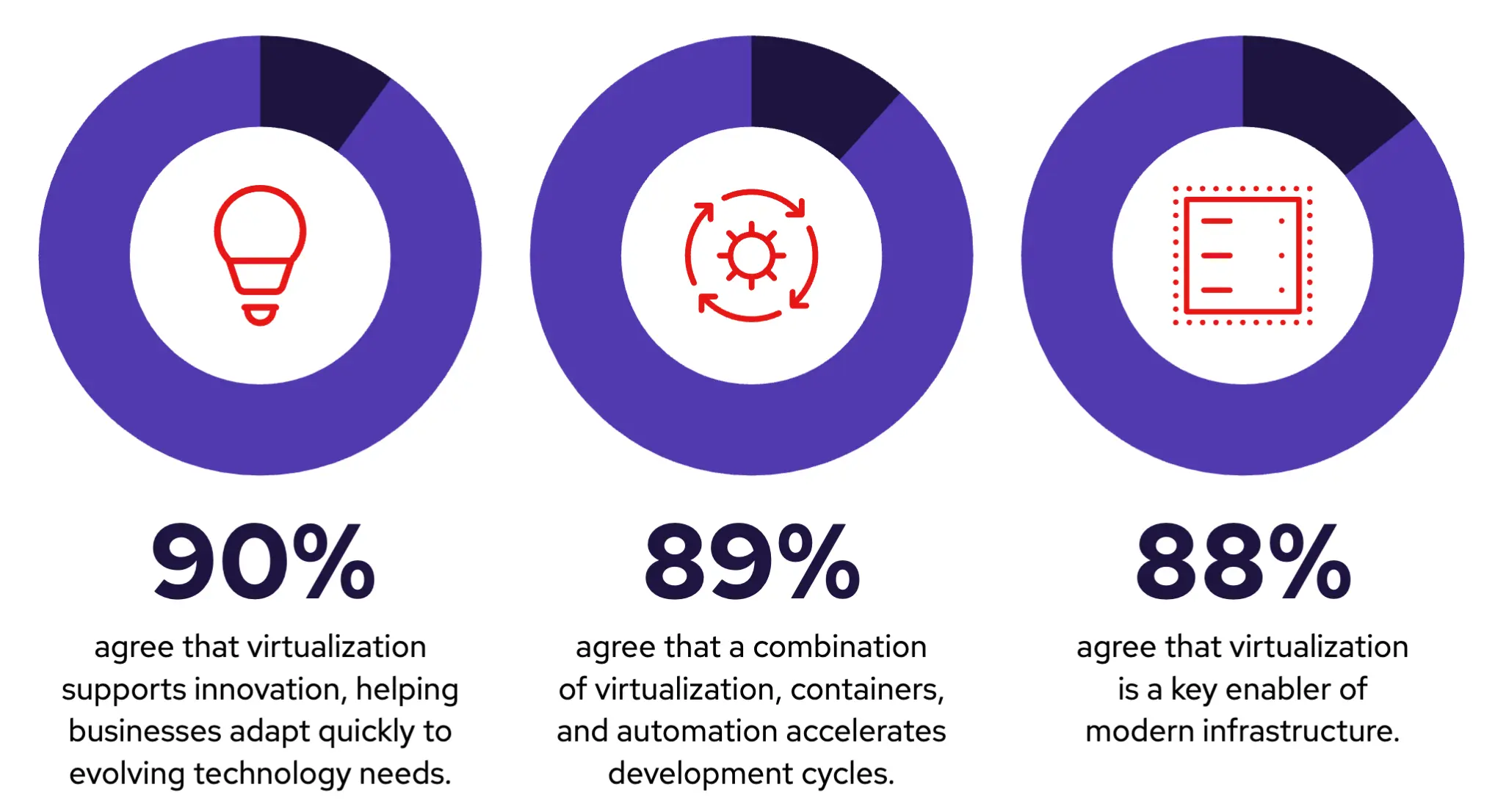
本次调查显示,几乎所有组织都重视虚拟化,因为它能够支持创新,包括适应不断变化的技术需求和管理现代基础架构。随着混合云和多云环境中虚拟化的持续迁移,以及基于容器的工作负载的日益普及,大多数组织都将虚拟化视为创新未来的关键推动因素。
由于容器提供了轻量级、可跨环境移植的选项,并能够通过现代集成支持高级工作负载,因此越来越多的组织正在扩展其对容器和现代开发实践的采用,并投资于自动化工具也就不足为奇了。许多受访者表示,他们对统一平台的兴趣日益浓厚,以便在混合云和多云环境中管理日益多样化的工作负载。
受访者表示,生成式人工智能将成为未来虚拟化管理和运营的关键贡献者。

2. Alphabet 2025 年 Q2 业绩
Alphabet Announces Second Quarter 2025 Results
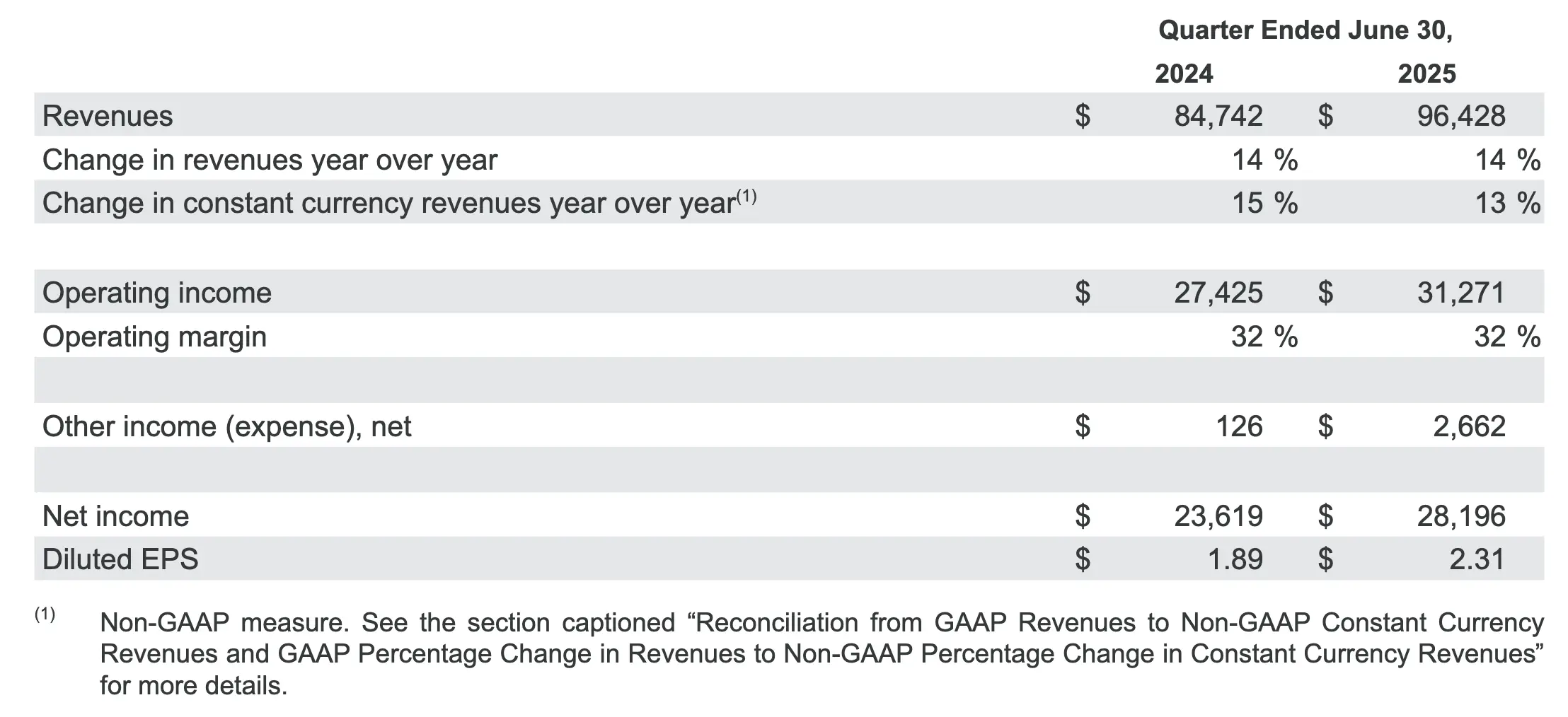
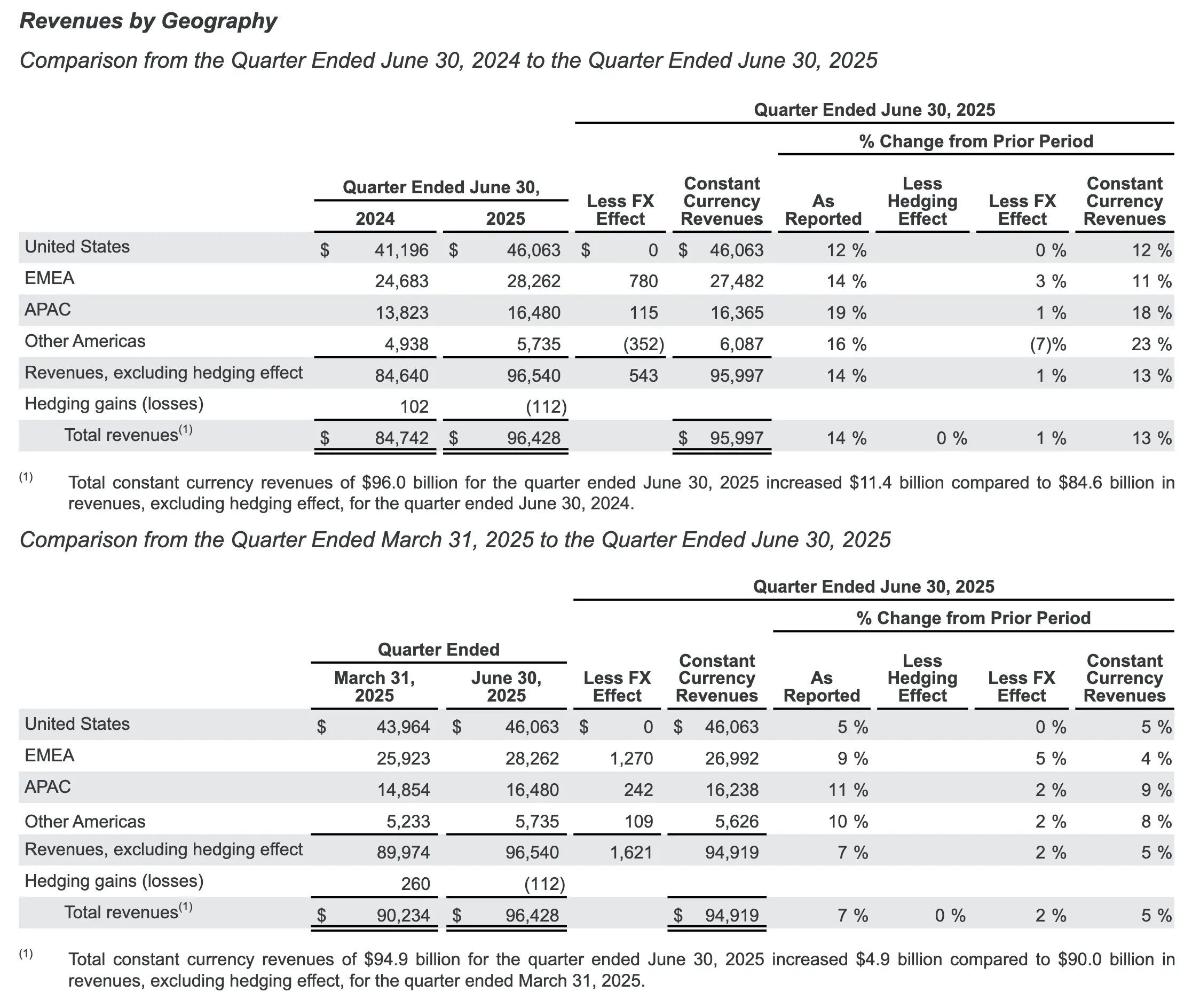
小结
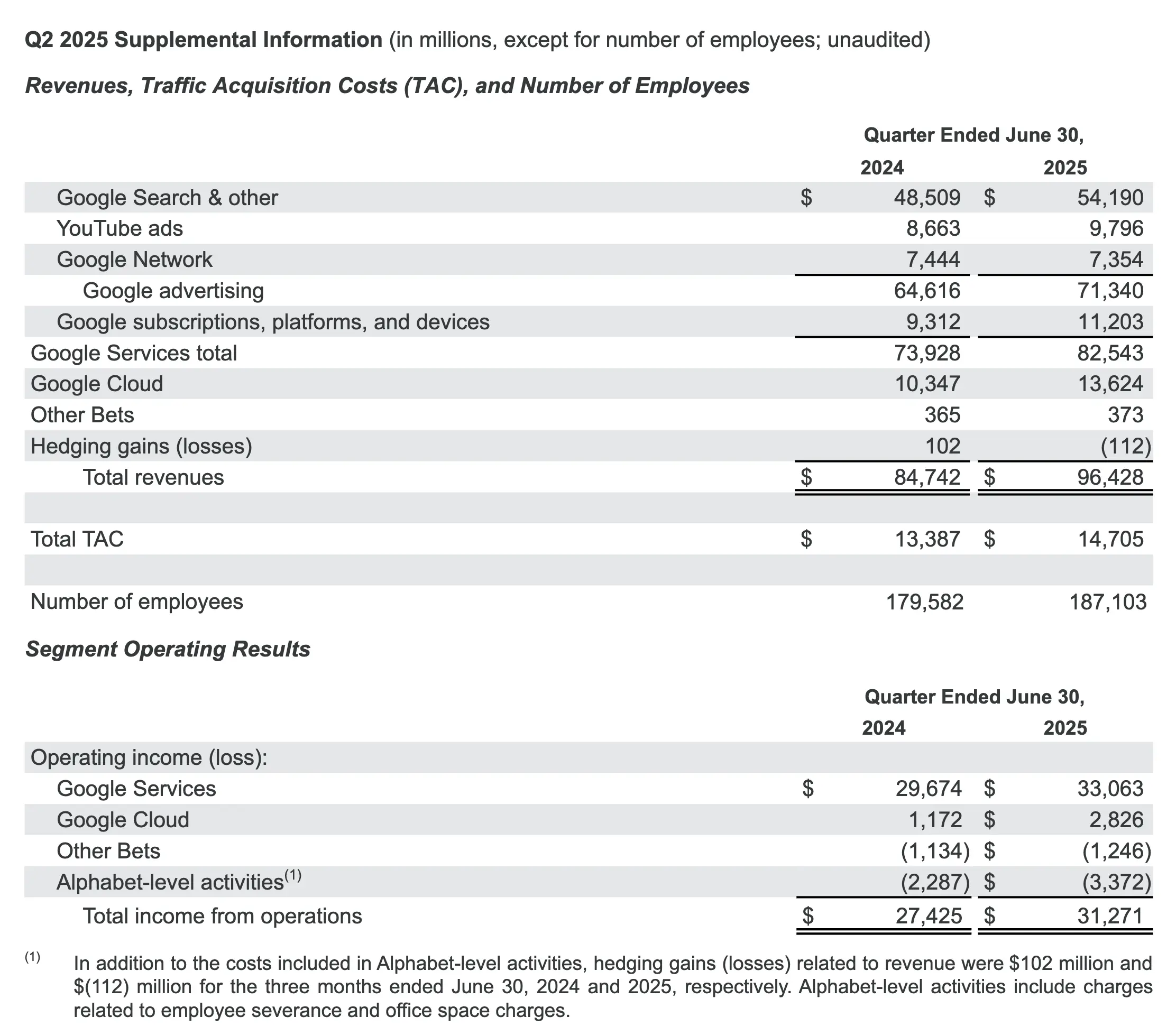
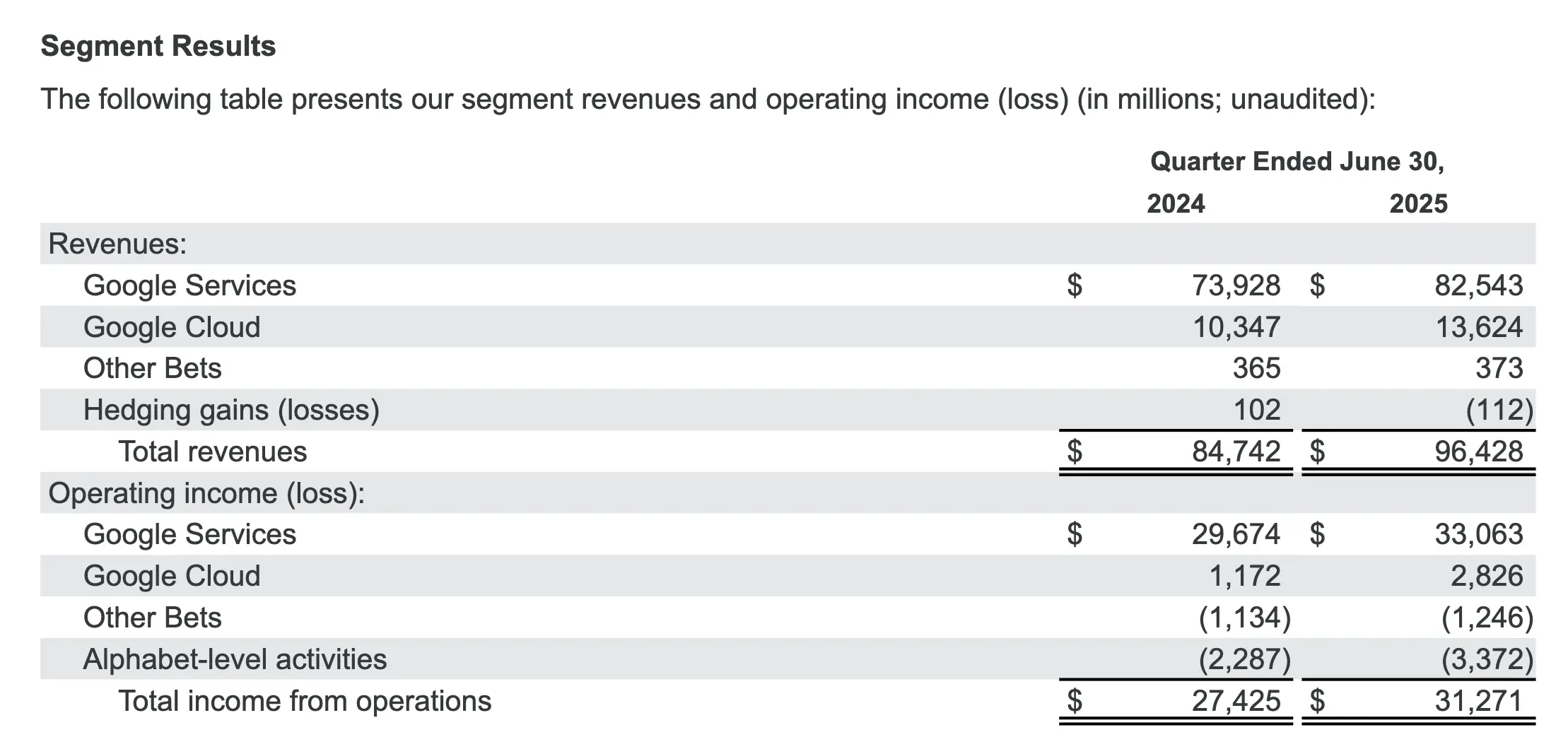
- Alphabet 合并营收同比增长 14%,按固定汇率计算增长 13%,达到 964 亿美元,反映出整个业务的强劲增长势头。谷歌搜索及其他业务、YouTube 广告、谷歌订阅、平台和设备以及谷歌云在第二季度均实现了两位数增长。
- 谷歌服务收入增长 12%,达到 825 亿美元,反映出谷歌搜索及其他、谷歌订阅、平台和设备以及 YouTube 广告的强劲表现。
- 谷歌服务包括广告、Android、Chrome、设备、Google 地图、Google Play、搜索和 YouTube 等产品和服务。Google 服务的收入主要来自广告;消费者订阅产品(例如 YouTube TV、YouTube Music 和 Premium、NFL Sunday Ticket 以及 Google One)的收费;应用销售和应用内购买;以及设备。
- 谷歌云收入增长 32%,达到 136 亿美元,这主要得益于谷歌云平台 (GCP) 的核心 GCP 产品、人工智能基础设施和生成式人工智能解决方案的增长。
- 谷歌云为企业客户提供基础设施和平台服务、应用程序和其他服务。Google Cloud 的收入主要来自于 Google Cloud Platform 服务、Google Workspace 通信和协作工具以及其他企业服务的消费费用和订阅。
- 总营业收入增长 14%,营业利润率为 32.4%。营业利润率受益于强劲的收入增长和费用基础的持续优化,但部分抵消了与部分法律事务原则上和解相关的费用。
- 净收入增长 19%,每股收益增长 22%,达到 2.31 美元。
数据
🎤 不是很看得懂,就简单放几张截图,更多信息可以直接看原文。
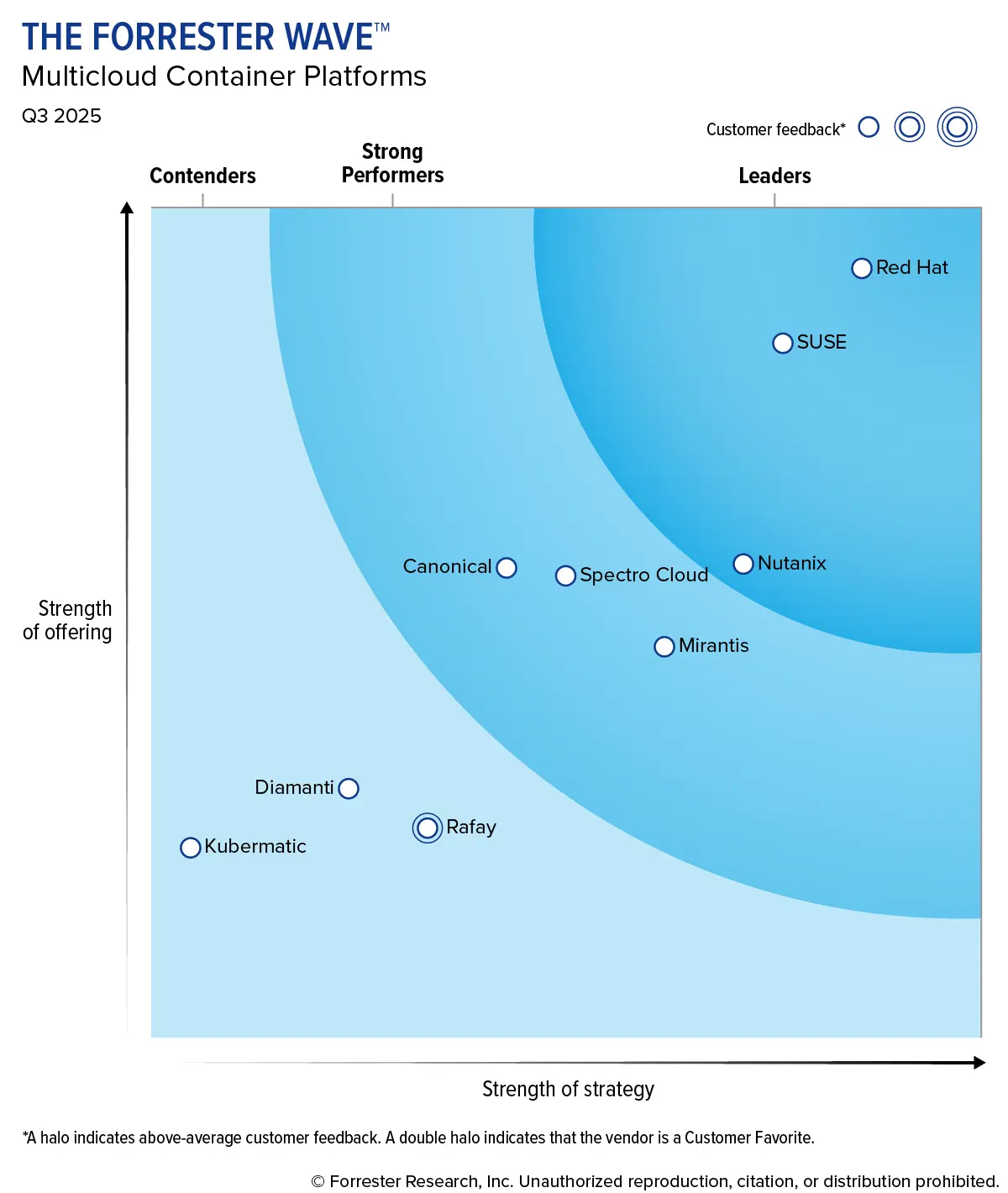
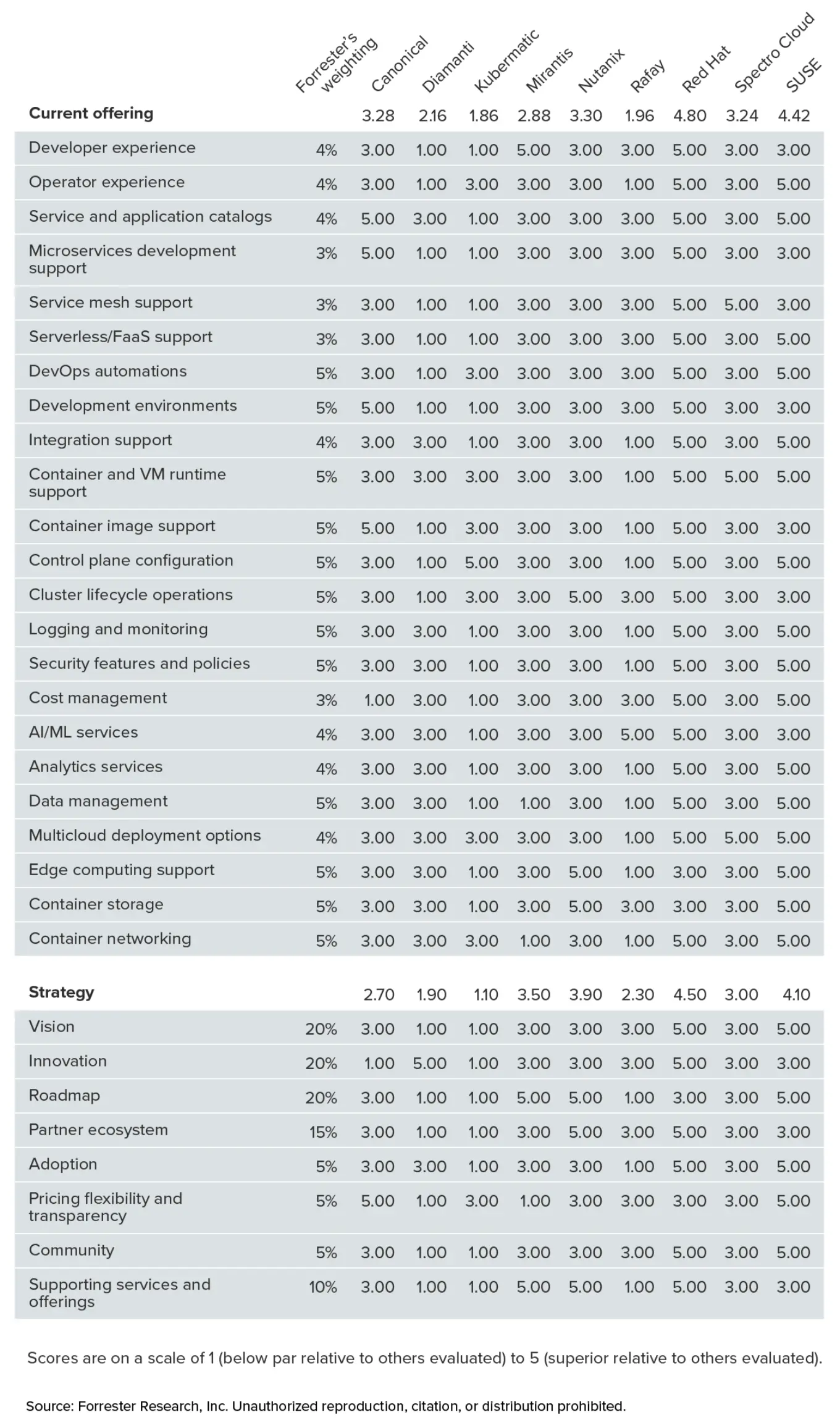
3. [The Forrester Wave] Multicloud Container Platforms, Q3 2025
The Forrester Wave™: Multicloud Container Platforms, Q3 2025
背景
在过去十年中,Linux 生态系统通过 Kubernetes 发展成为一个分布式操作系统 (OS) 和平台,催生了多云容器平台市场。该市场目前涵盖三个细分领域:企业 IT 平台(Nutanix、Red Hat、SUSE)、专注于 AI 的新型平台即服务 (PaaS) 提供商(Mirantis、Rafay)和专注于运营技术 (OT) 的供应商(Diamanti、Kubermatic),以及像 Canonical 和 Spectro Cloud 这样帮助客户构建自有平台的赋能者。多云容器平台始终需要通过提供卓越的容器化应用编排以及其他差异化的云原生技术来证明其价值——在公有云成本之上向客户收取费用。虽然多云容器平台凭借超越原生云的功能而获得了关注,但无服务器和自动化容器服务的兴起提高了标准。本评估探讨了多云容器平台如何应对挑战,例如加倍投入面向云、数据中心和边缘的企业级平台,或瞄准从 AI 到工业运营等特定用例。
总结
- 领导者
- RedHat
- SUSE
- Nutanix
- 表现强劲
- Mirantis
- Spectro Cloud
- Canonical
- 竞争者
- Rafay
- Diamanti
- Kubermatic
4. [Stack Overflow] The 2025 Developer Survey
The 2025 Developer Survey 是一份关于软件开发现状的权威报告。Stack Overflow 已开展十五年,共收到来自 177 个国家/地区的超过 49,000 份回复,涵盖 62 个问题,涉及 314 种不同的技术,其中包括新增的 AI 代理工具、LLM 和社区平台。这项年度开发者调查提供了全球开发者社区需求的重要快照,重点关注他们正在使用或想要深入了解的工具和技术。
具体内容见原文。
💁♀️ 专题五 产品/方案介绍
1. 2024 年下半年的 13 个 CNCF 沙盒新项目
Exploring Cloud Native projects in CNCF Sandbox. Part 4: 13 arrivals of 2024 H2
安全与合规
1. Ratify:验证制品安全元数据的验证引擎
原始所有者/创建者:Deis Labs(2017 年被微软收购)
Ratify 提供了一个框架,用于集成需要验证参考制品(reference artifacts)的场景,并提供了一组可供参与制品批准(artifact ratification)的各种系统使用的接口。
Ratify 的功能:
- 全面验证
Ratify 提供全面的验证框架,可帮助您确保所有参考工件均符合安全性和合规性标准。借助 Ratify,您可以验证签名、校验和,并确保您的工件保持最新状态且不存在已知漏洞。 - 灵活配置
Ratify 提供灵活的配置系统,允许您自定义验证策略以满足您的特定需求。您可以轻松定义自己的签名验证、工件验证等策略,Ratify 将在您的 Kubernetes 环境中自动强制执行这些策略。 - 轻松集成
Ratify 旨在与您现有的 Kubernetes 环境无缝集成。只需几个简单的步骤,即可轻松安装 Ratify 并开始验证参考工件。此外,Ratify 提供了一组可供各种系统使用的接口,让您可以轻松地将 Ratify 集成到您现有的工具链中。
2. Cartography:开源基础设施地图绘制工具
原所有者/创建者:Lyft
Cartography 是一个 Python 工具,它通过 Neo4j 数据库提供的直观图形视图整合基础设施资产及其之间的关系。
- 发现资产
自动发现跨提供商和区域的所有云资源。 - 映射依赖关系
可视化服务、资源和基础设施组件之间的关系。 - 查找安全问题
通过分析和数据丰富来识别风险和合规性问题。
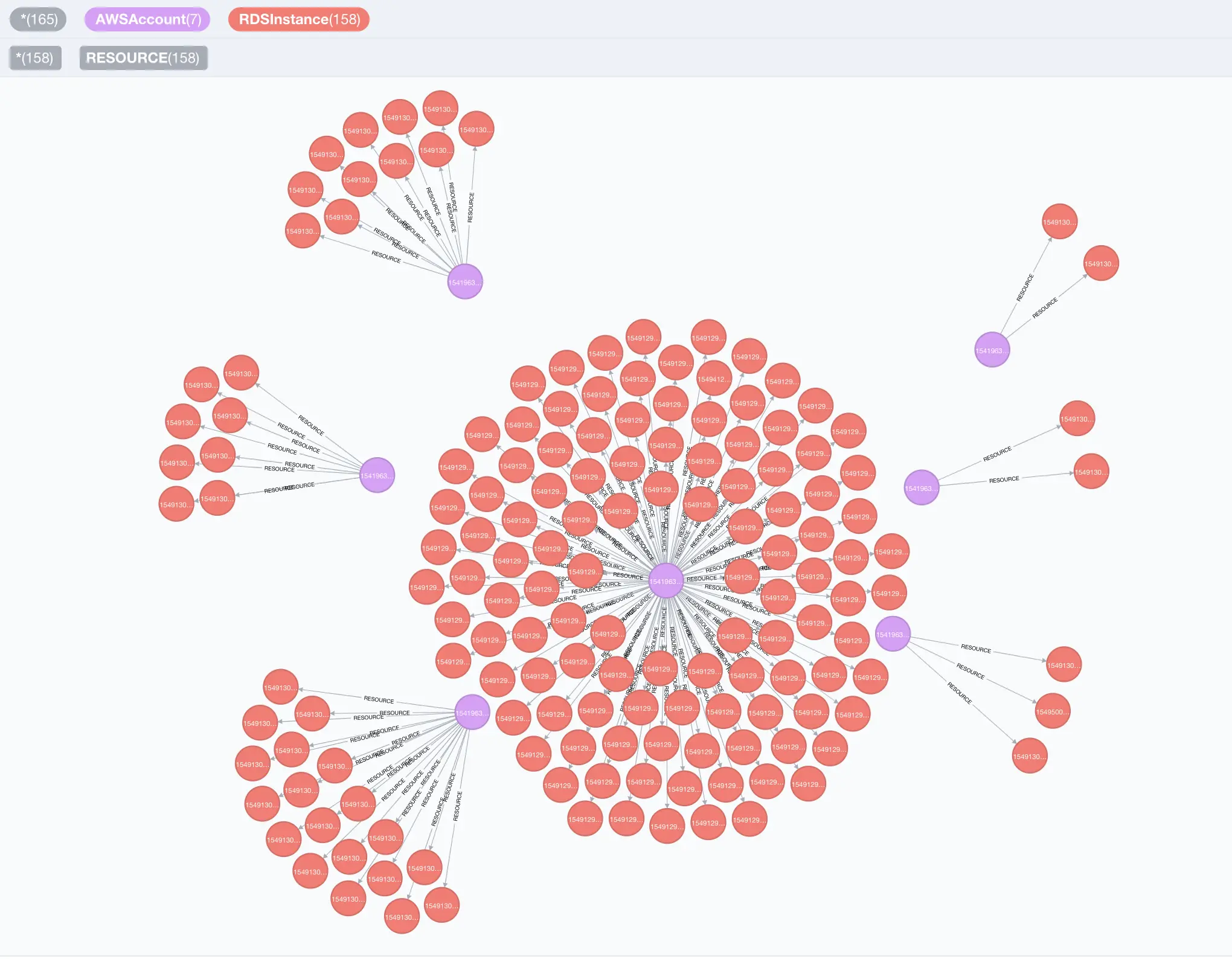
Cartography 让用户以可视化的方式探索您的基础设施。它非常擅长揭示资产之间原本隐藏的依赖关系,以便验证有关安全风险的假设。服务所有者可以生成资产报告,红队成员(模拟攻击者的团队)可以发现攻击路径,蓝队成员(防御和响应攻击者的团队)可以识别需要改进的安全领域。所有人都可以通过 Web 前端界面使用该图表进行手动探索,或通过调用 API 以自动化方式进行探索,从而受益匪浅。
Cartography 并非市面上唯一的安全图表工具,但它的独特之处在于功能齐全,且通用性强,可扩展性强,能够帮助任何人更好地了解自身风险敞口,无论他们使用何种平台。与其他相关工具不同,Cartography 专注于单一核心场景或攻击向量,因此更注重灵活性和探索性。
Cartography 是:
- 一个简单的 Python 脚本,从多个提供商处提取数据并将其批量写入 Neo4j 图形数据库。
- 一个强大的分析工具,可以捕获环境的当前快照,构建一个独特有用的清单。
- 经过多家公司在生产中的实践检验。
- 使用自己的自定义插件直接进行扩展。
- 提供有用的数据平面,可以在其上构建自动化和 CSPM(云安全态势管理)应用程序。
Cartography 不是(不具备):
- 近乎实时的能力。
- 本身并不能捕捉数据随时间的变化。
调度与编排
3. HAMi:异构 AI 计算虚拟化中间件
原始所有者/创建者:4paradigm
HAMi(异构 AI 计算虚拟化中间件)前身为 k8s-vGPU-scheduler,是一个“一体化”图表,旨在管理 Kubernetes 集群中的异构 AI 计算设备。它可以提供异构 AI 设备共享的能力,并在任务之间提供资源隔离。
HAMi 致力于提高 Kubernetes 集群中异构计算设备的利用率,并为不同类型的异构设备提供统一的复用接口。
特点:
- 兼容 Kubernetes 原生 API
零变化升级:与 Kubernetes 的默认行为兼容 - 开放和中立
由互联网、金融、制造、云服务商等联合发起,与 CNCF 共同致力于开放治理 - 避免供应商锁定
与主流云提供商集成;不受专有供应商编排的约束 - 资源隔离
提供容器内资源的硬隔离,容器内的任务不能使用超出其配额的资源 - 支持多种异构计算设备
提供多种厂商 GPU、MLU、NPU 的设备共享 - 统一管理
统一监控系统,可配置调度策略(binpack、spread 等...)
架构图:
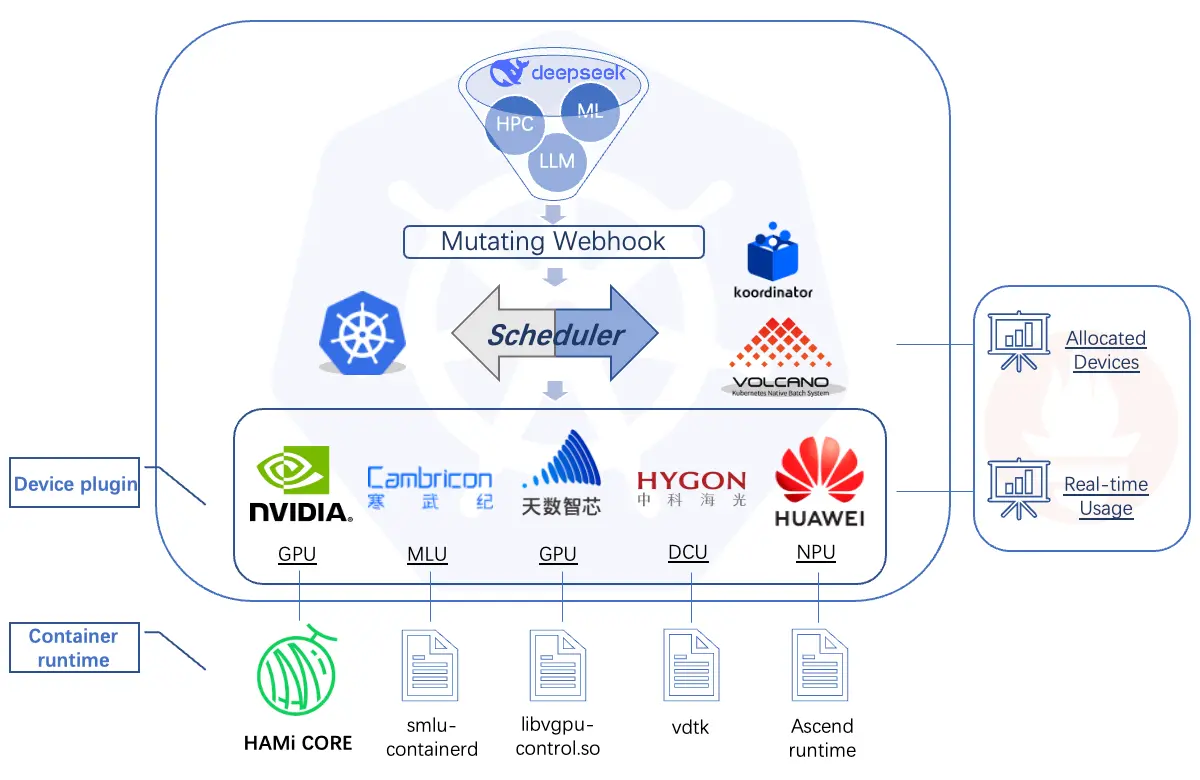
更多见 vGPU 是伪命题?NVIDIA 官方为什么不自己出细粒度共享呢?、KAI-Scheduler vs HAMi:GPU 共享的技术路线分析与协同展望。
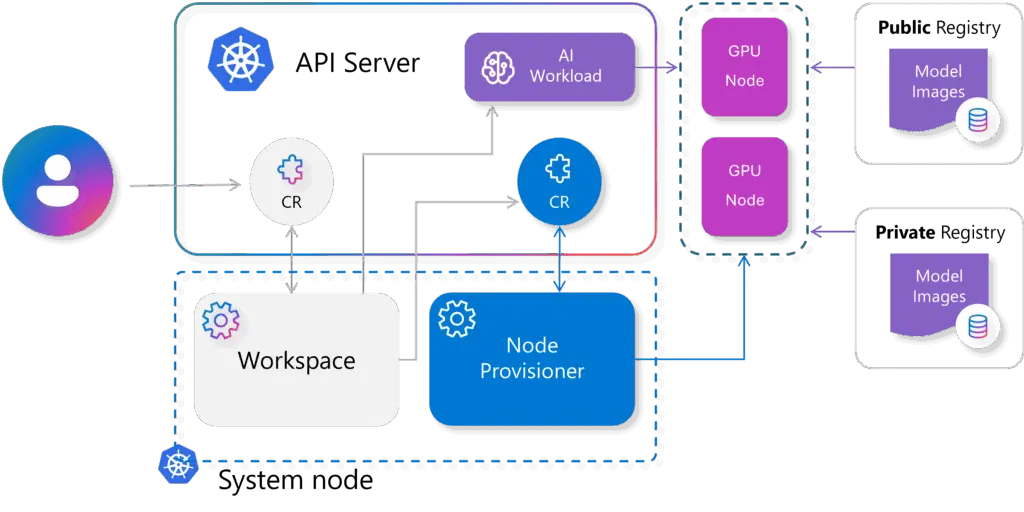
4. KAITO:Kubernetes AI 工具链 Operator
- 原始所有者/创建者:微软
KAITO 是一个操作器 Operator,用于自动化 Kubernetes 集群中的 AI/ML 模型推理或调优工作负载。目标模型是流行的开源大型模型,例如 phi-4 和 llama。与大多数基于虚拟机基础设施的主流模型部署方法相比,KAITO 具有以下关键差异化优势:
- 使用容器镜像管理大型模型文件。提供与 OpenAI 兼容的服务器来执行推理调用。
- 提供预设配置,避免根据 GPU 硬件调整工作负载参数。
- 为流行的开源推理运行时提供支持:vLLM 和 transforms。
- 根据模型要求自动配置 GPU 节点。
- 如果许可证允许,则在公共 Microsoft 容器注册表 (MCR) 中托管大型模型图像。
架构图:
服务网格
5. Kmesh:高性能 Service Mesh 数据平面
原始所有者/创建者:华为
Kmesh 是一个高性能的服务网格数据平面。它旨在解决 Istio 现有的两个问题:代理层不必要的延迟开销和高资源消耗。为此,它利用 eBPF 实现流量编排,包括动态路由、授权和负载均衡。重要的是,无需对最终用户应用程序进行任何代码更改即可受益于 Kmesh 带来的优化。
Kmesh 使用 Istio 作为其控制平面,并且可以以两种模式运行:
- 提供完整体验的内核原生模式。它将 L4 和 HTTP 流量治理委托给内核,因此无需通过代理层传递数据。
- 双引擎模式,适合那些喜欢增量式过渡的用户。它添加了 Waypoint 来管理 L7 流量。此模式需要在环境模式下运行 Istio。
架构图:

更多见 Kmesh:高性能 Service Mesh 数据平面。
6. Sermant:基于 Java 字节码增强技术的无代理服务网格
原始所有者/创建者:华为
Sermant 是一个无代理服务网格,它利用 Java 字节码增强功能来解决以微服务形式构建的大规模 Java 应用程序中的服务治理问题(基于 Spring Cloud、Apache Dubbo 等)。它提供许多功能,例如动态配置、消息传递、心跳、服务注册、负载均衡、基于标签的路由、流量控制、分布式追踪等。
服务代理
7. LoxiLB:基于 GoLang/eBPF 的开源云原生负载均衡器
LoxiLB 是一款功能丰富的 Kubernetes 负载均衡器,旨在实现基础设施无关(即支持本地、公有云和混合云环境)、高性能和可编程性。它主要专注于作为服务型负载均衡器运行,但也支持其他场景。该项目利用 eBPF 作为其核心引擎。
LoxiLB 不仅能够安装在各种基础架构中,还能与任何 Kubernetes 发行版和 CNI(包括 Flannel、Cilium 和 Calico)兼容。它支持 Kubernetes 的双栈 NAT64 和 NAT66 协议,以及 TCP、UDP、SCTP、QUIC 等多种协议。其众多功能包括:使用 eBPF(Kubernetes 的完整集群网格)替换 kube-proxy、快速故障转移检测的高可用性、广泛且可扩展的端点活性探测,以及支持 IPsec/WireGuard 的状态防火墙。
要开始使用 LoxiLB,可以根据想要运行的模式从各种指南中进行选择:外部集群、集群内、服务代理、Kubernetes Ingress、Kubernetes Egress 或独立(完全没有 Kubernetes)。
云原生网络
8. OVN-Kubernetes:以 OVN 和 Open vSwitch 为核心的 CNI
原始所有者/创建者:Red Hat
OVN-Kubernetes 是一个用于 Kubernetes 集群的 CNI(容器网络接口)插件,实现了 OVN(开放虚拟网络),OVN 是基于 Open vSwitch(开放虚拟交换机)的抽象。它旨在通过为企业和电信用例提供高级功能来增强 Kubernetes 网络。
这些功能包括细粒度的集群出口流量控制、支持创建辅助网络和本地网络(例如,用于多宿主)、用于混合 Windows/Linux 集群的混合网络(使用 VXLAN 隧道)以及将网络任务从 CPU 卸载到 NIC。它还通过保持已建立的 TCP 连接处于活动状态,支持 KubeVirt 管理的虚拟机的实时迁移。具体见功能列表。
OVN-Kubernetes 支持两种架构各异的部署模式:默认模式(集中式控制平面)和互连模式(分布式控制平面)。后者通过 OVN 管理的 GENEVE 隧道连接多个 OVN 部署。
默认模式的架构包括:
- 控制平面:ovnkube-master Pod(它监视 Kubernetes 对象并将其转换为 OVN 逻辑实体)、OVN NBDB 数据库(存储这些逻辑实体)、northd(将实体转换为 OVN 逻辑流)和 sbdb(存储流);
- 数据平面:ovnkube-node Pod(运行 CNI 可执行文件)、ovn-controller(将逻辑流从 sdbd 转换为 OpenFlows)和 ovs-node Pod(OVS 守护进程和数据库、虚拟交换机)。
可观测性
9. Perses:开源的、云原生的可观测性仪表盘工具
原始所有者/创建者:Amadeus IT Group
Perses 首先是一个仪表板工具,可用于显示各种可观察性数据。它目前支持 Prometheus 指标和 Tempo 跟踪,并计划在未来扩展其功能,包括日志记录、性能分析、其他监控和跟踪技术等等。除了核心用途之外,Perses 还旨在实现几个更广泛的目标:
- 仪表板的开放规范。Perses 也是一项定义标准化仪表板规范的倡议,旨在促进跨可观察性工具的互操作性。
- 可集成性。Perses 提供了各种 npm 软件包,允许开发人员将面板和仪表板嵌入到自己的 UI 中,从而受益于 Perses 的开发成果。例如,这些软件包未来可用于增强 Prometheus UI 中的数据可视化。
- 可扩展性。Perses 即将支持插件,使用户能够扩展该工具的本机功能以满足特定需求。
- GitOps 友好型。SDK、CI/CD 库、静态验证、本机 CLI……Perses 为您提供出色的 Dashboard-as-Code 体验所需的一切。
- Kubernetes 原生模式。仪表板定义将可通过自定义资源定义 (CRD) 部署到各个应用程序命名空间,并可在各个应用程序命名空间中读取。
在线演示,网址为 https://demo.perses.dev。
应用程序定义和映像构建
10. Shipwright:用于在 Kubernetes 上构建容器镜像的可扩展框架
原始所有者/创建者:Red Hat
Shipwright 是一个利用现有工具在 Kubernetes 上构建容器镜像的框架。该项目使用简单的 YAML 配置(通过 CRD)来描述将使用哪些工具构建哪些应用程序。
特点:
- 灵活性和可扩展性
Shipwright.io 支持多种构建工具,包括 Kaniko。这种灵活性使您可以选择最符合项目需求的工具,从而确保您能够充分利用不同构建策略的优势。 - 简化配置
BuildStrategy 使开发人员能够使用最少的 YAML 配置来定义构建流程。这种方法为开发人员抽象了容器工具的知识,即使是容器技术新手也能轻松上手。 - 与 Kubernetes 集成
通过与 Kubernetes 无缝集成,BuildStrategy 可确保您的构建流程可扩展且可靠 。这种集成使您能够充分利用 Kubernetes 的编排功能,确保高效且稳健的容器镜像构建。
自动化和配置
11. KusionStack:提供多种专注于构建内部开发者平台 (IDP) 的工具
原始所有者/创建者:蚂蚁集团
KusionStack 提供多种专注于构建内部开发者平台 (IDP) 的工具。其核心是名为 Kusion 的平台编排器。Kusion 采用声明式和意图驱动的方式,围绕单一规范运行,开发者只需定义工作负载以及应用程序部署所需的所有依赖项。Kusion 将负责其余工作,确保应用程序正常运行。
其他值得注意的 KusionStack 工具是 Karpor 和 Kuperator。Karpor 的 GitHub 星标数量甚至比 Kusion 主仓库还要多,它是 Kubernetes 的 Web UI,主要功能如下:
- 搜索:强大的 SQL 样式查询,可从多集群设置中快速选择所需的任何 Kubernetes 资源。
- Kubernetes 资源洞察:展示现有问题*的仪表板和交互式拓扑视图。
- AI:基于 GenAI 对现有问题的解释。
容器运行时
12. youki:Rust 实现的 OCI 运行时规范
拥有者/创作者:Toru Komatsu(小松彻,个人)
youki 是一个符合 OCI 标准的低级运行时,类似于 runc 和 crun。它可以直接用于创建、启动和运行容器。但是,将其与更高级的运行时(例如 Docker 或 Podman)结合使用会更加方便。关于 youki 的其他一些信息:
- 它可以在无根模式下工作。
- 目前,它仅适用于 Linux。在其他平台上(需要虚拟化)也可以使用它,并且 Vagrant 提供了现成的 Vagrantfiles 供您使用 Vagrant 设置虚拟机。
- 它支持 WebAssembly,这意味着您可以使用 WebAssembly 模块构建容器映像,然后使用 youki 运行该容器。
云原生存储
13. OpenEBS:开源容器原生持久化存储解决方案
原始所有者/创建者:MayaData(2021 年被 DataCore 收购)
OpenEBS 是一个开源容器原生存储解决方案,可为 Kubernetes 工作负载提供持久化存储。它支持使用容器化存储控制器动态配置存储资源,从而实现高度灵活且云原生的特性。OpenEBS 支持多种存储引擎,包括用于直接节点存储的 LocalPV 和用于高级数据复制和弹性的 Replicated PV。它旨在与 Kubernetes 无缝集成,提供存储策略、调整大小、精简配置、快照和恢复等功能,是状态型应用程序的理想之选。
OpenEBS 为 Kubernetes 工作负载提供了两种主要存储方法:本地存储和复制存储。以下是比较概述:
| 特性 | 本地存储 | 复制存储 |
|---|---|---|
| 数据可用性 | 限于卷配置所在的节点;不适用于高可用性要求。 | 数据在多个节点间同步复制,确保高可用性和持久性。 |
| 用例 | 适用于管理自身复制和可用性的应用程序,如 MongoDB 和 Cassandra 等分布式数据库。 | 适用于需要存储级别复制和高可用性的有状态工作负载,如 Percona/独立数据库和 GitLab 数据库。 |
| 性能 | 提供接近磁盘的性能,开销极小。 | 为实现低延迟访问而设计,利用 NVMe-oF 语义,实现高性能。 |
| 限制 | 不具备高可用性;节点故障会导致数据不可用。 | 需要足够的资源(CPU、RAM、NVMe)以获得最佳性能。 |
| 快照与克隆 | 当由 LVM 或 ZFS 等高级文件系统支持时,受支持。 | 受支持,提供企业级存储能力。 |
| 备份与恢复 | 通过 Velero 支持,对本地卷使用 Restic。 | 通过 Velero 支持,确保数据保护和恢复。 |
2. OpenYurt:简化云边一体化应用的部署和管理的边缘计算平台
简介
OpenYurt 是为满足典型边缘基础设施的各种 DevOps 需求而设计的。 通过 OpenYurt 来管理边缘应用程序,用户可以获得与中心式云计算应用管理一致的用户体验。 它解决了 Kubernetes 在云边一体化场景下的诸多挑战,如不可靠或断开的云边缘网络、边缘节点自治、边缘设备管理、跨地域业务部署等。 OpenYurt 保持了完整的 Kubernetes API 兼容性,无厂商绑定,更重要的是,它使用简单。
OpenYurt 由阿里云于 2020 年 5 月开源。它解决了以下常见问题:
- 云边网络断连或不稳定
- 边缘自治
- 区域感知部署
- 边缘设备管理
相关阅读
3. Dragonfly:基于 p2p 的文件分发和镜像加速系统
简介
Dragonfly 是一个基于 P2P 的开源文件分发和镜像加速系统。它由云原生计算基金会 ( CNCF ) 托管,目前处于孵化阶段。其目标是解决云原生架构中的所有分发问题。目前,Dragonfly 专注于:
- 简单:定义良好的面向用户的 API(HTTP),对所有容器引擎无侵入;
- 高效:种子对等体支持,基于 P2P 的文件分发,节省企业带宽;
- 智能:主机级限速,通过主机检测实现智能流控;
- 安全:块传输加密,HTTPS 连接支持。
相关阅读
- 持久化缓存任务
- 资源搜索(任务和持久化缓存任务)
- Vortex:基于 TLV 的 P2P 文件传输协议
- 增强的大文件分发
- 支持个人访问令牌(PAT)的作用域
- 增强的预热
- 实现用户操作的审计日志记录
- 垃圾回收
- 使用硬链接优化文件下载
- 分片哈希计算支持硬件加速
- 高级存储管理
- 支持 OpenTelemetry 追踪
4. Llama Stack:构建生成式 AI 应用的开源框架
Llama Stack 是一个开源框架,用于构建生成式 AI 应用。它目标是定义和标准化生成式 AI 应用的核心组件。提供统一的 API 和模块,包括:
- 统一的推理、RAG、Agent、工具、安全、评估和遥测 API 层
- 插件架构,支持本地开发、本地部署、云端和移动端多种环境下的多样实现
- 预打包的验证发行版,帮助开发者快速可靠地启动项目
- 多种开发接口,如 CLI 和 Python、Node、iOS、Android SDK
- 独立示例应用,演示如何用 Llama Stack 构建生产级 AI 应用
5. Tanzu Hub:Tanzu Platform 的统一界面和控制平面
Your Unified Interface for Application Delivery with Tanzu Hub
Tanzu Hub 整合了多个工具,如 Tanzu Apps Manager 和 Operations Manager 的功能,提供单一仪表盘来监控基础设施、应用部署、服务绑定以及性能等。Tanzu Hub 的主要优势包括:单一视图管理多个 Tanzu Platform 实例;应用到基础设施的全面可观测性;基于图形的数据存储,方便快速查询和故障排除;可定制的仪表盘和告警引擎;内置合规性工具。通过 Tanzu Operations Manager 的 tile 即可轻松安装和升级 Tanzu Hub,无需复杂的配置。
🤔 专题六 有意思的事与 Meme
1. ChatGPT 是否会鼓励危险的妄想?
Does ChatGPT Encourage Dangerous Delusions?
两个月前,一位患有精神分裂症的 Reddit 用户发表了一条关于 AI 的评论 :“我不喜欢 Chatgpt 的一点是,如果我陷入精神病,它仍然会继续肯定我。” The Cleveland Clinic 定义精神病为“无法区分真实与虚假”。
文章中列举了其他例子,具体见原文。
今年 4 月,OpenAI 在其公司博客上承认,GPT-4o “倾向于过度支持但不真诚的回应”,并承认其“存在意想不到的副作用”。该组织将 GPT-4o 回滚到早期版本,并表示 OpenAI“感谢所有为此发声的人”。
加州大学伯克利分校公共卫生学院精神病学家、生物伦理学教授、卡弗里伦理、科学与公众研究中心联合创始人兼联席主任乔迪·哈尔彭 (Jodi Halpern) 向《滚石》杂志描述了这种危险。她表示:“对于这种亲密、富有情感的聊天机器人来说,人类很容易成为攻击目标,它能够提供持续的验证,而无需处理他人的需求。”
麻省理工学院技术与社会研究教授雪莉·特克尔(Sherry Turkle ) 向 CNN 给出了更简洁的解释 :“ChatGPT 的建立是为了感知我们的弱点,并利用这一点让我们与之保持互动。”
为什么 ChatGPT 比我们生活中的真人“更引人注目”。“因为它总是说‘是’。”
🎤 回归自我,把握真实,锻炼心态。别人骂,得坚强,AI 夸,要冷静。总而言之,“面对平凡之物审慎地生活,从虚无中如上帝般创造”。
2. Kubernetes 之旅
How's your Kubernetes journey so far