🆕 专题一 产品新功能/新版本
1. SUSE Rancher 推出专为边缘和裸金属基础设施设计的 Rancher Elemental
边缘设备自动上线 + 集群自建,这才是 Kubernetes 的终极玩法!
Rancher Elemental 是什么
Rancher Elemental 是一个专为边缘和裸金属基础设施设计的 Kubernetes 部署方案,它基于 SUSE 的轻量级 Linux 发行版 – SLE Micro 与 Elemental,通过整合 Rancher 的集中管理能力,帮助用户快速、自动化地在任意硬件上部署 Kubernetes 节点。
简而言之,Elemental 提供了一套完整的云原生操作系统管理解决方案,不仅可将 Kubernetes 节点的系统镜像管理为 标准化的 OCI 镜像(如容器镜像那样便捷),还可以将其快速转换为 自安装 ISO 或磁盘镜像,极大简化大规模部署与自动化流程。
它不仅仅是一个安装工具,更是连接边缘设备与云原生管理平台的桥梁,使操作系统、集群注册、GitOps 配置到生命周期管理全部自动化完成。
典型适用场景
- 大规模边缘设备自动部署(零售、交通、制造等行业)
- 私有数据中心裸金属节点快速集群化
- 多站点集群的统一纳管与 GitOps 管理
- 安全可控的本地计算节点(支持 TPM、安全启动)
2. Istio 1.26 发布:增强 Gateway API 支持,拥抱 Kubernetes 未来 —— 同时告别 1.23 版本
Istio 1.26 发布:增强 Gateway API 支持,拥抱 Kubernetes 未来 —— 同时告别 1.23 版本
Istio 是什么
Istio 扩展了 Kubernetes 以建立可编程的应用程序感知网络。Istio 可同时处理 Kubernetes 和传统工作负载,为复杂的部署带来标准的通用流量管理、遥测和安全性。
选择所需的功能,Istio 会根据需要部署代理基础架构。使用零信任隧道实现第 4 层性能和安全性,或为第 7 层功能添加强大的 Envoy 服务代理。
使用 Istio 安全可靠地轻松构建云原生工作负载,无论有没有 sidecar。
新特性速览
- Gateway API 自动资源支持全面可配置
- Ambient 模式下支持 TCPRoute
- 支持 Kubernetes 新特性 ClusterTrustBundle
- istioctl 工具增强
- 安装与平台适配改进
- EnvoyFilter 和 Retry 策略增强
3. etcd v3.6.0 发布
etcd 是什么
etcd 是一个强一致的分布式键值存储,它提供了一种可靠的方法来存储需要由分布式系统或计算机集群。它优雅地处理领导者在网络分区期间进行选举,甚至可以容忍机器故障在领导节点中。
简介
etcd v3.6.0 是自 2021 年 6 月 15 日 etcd v3.5.0 以来的第一个次要版本。此版本引入了几个新功能,在长期的努力上取得了重大进展,如降级支持和迁移到 v3store,并解决了许多关键和主要问题。它还包括内存使用方面的重大优化,从而提高效率和性能。
除了 v3.6.0 的功能外,etcd 还以 SIG (sig-etcd) 的形式加入了 Kubernetes,使我们能够提高项目的可持续性。我们引入了系统的稳健性测试,以确保正确性和可靠性。通过 etcd-operator 工作组,我们也计划提高可用性。
安全
为了增强 v3.6.0 中的软件安全性,我们通过集成 govulncheck 来扫描源代码,并集成 trivy 来扫描容器镜像,从而改进了我们的工作流程检查。这些改进也已向后移植到受支持的稳定版本中。
新功能
- 迁移到 v3store
在 etcd v3.6.0 中,由于 --enable-v2 标志已被删除,因此无法再启用 v2store,并且 v3store 已成为成员数据的唯一事实来源。 - 支持降级
etcd v3.6.0 是第一个完全支持降级的版本。此降级任务的工作涵盖版本 3.5 和 3.6。该过程包括将数据架构迁移到目标版本(例如 v3.5),然后进行滚动降级。 - 功能门
在 etcd v3.6.0 中,我们引入了 Kubernetes 风格的特性门控来管理新功能。以前,我们通过功能标志名称中的 --experimental 前缀来表示不稳定的功能。一旦功能稳定,前缀就会被删除,从而导致中断性变更。现在,功能将从 Alpha 开始,进入 Beta 阶段,然后正式发布,或者被弃用。这确保了用户更流畅的升级和降级体验。 - Livez/readyz 检查
etcd 现在支持 /livez 和 /readyz 端点,与 Kubernetes 的 Liveness 和 Readiness 探针保持一致。 /livez 指示 etcd 实例是否处于活动状态,而 /readyz 指示它何时准备好为请求提供服务。此功能也已向后移植到版本 3.5(从 v3.5.11 开始)和版本 3.4(从 v3.4.29 开始)。 - v3 发现
在 etcd v3.6.0 中,引入了基于 clientv3 的新发现协议 v3discovery。它有助于在 bootstrap 阶段发现所有集群成员。
性能相关
- 内存
在此版本中,我们将平均内存消耗降低了至少 50%。 - 吞吐量
与 v3.5 相比,etcd v3.6 在读取和写入吞吐量方面平均性能提高了约 10%。
Breaking changes
- 旧二进制文件与新 Schema 版本不兼容
- 对等端点不再为客户端请求提供服务
- etcdctl 和 etcdutl 之间的明确界限
拓展阅读
The Kubernetes Surgeon’s Handbook: Precision Recovery from etcd Snapshots
核心步骤是:
- 准备快照: 将 etcd 快照文件解压并恢复到本地目录。
- 启动本地 etcd 实例: 使用恢复的数据启动一个本地 etcd 实例。
- 定位并提取资源: 使用 etcdctl 命令找到目标资源(例如 ConfigMap)的 key,并使用 etcdctl 获取其值。
- 解码并格式化: 使用 auger 工具将 etcd 的二进制数据解码成 YAML 格式。
- 应用到集群: 使用 kubectl 将 YAML 文件应用到 Kubernetes 集群。
📰 专题二 新闻与访谈
1. CNCF 与 Synadia 携手保障 NATS.io 项目的未来
CNCF and Synadia Reach an Agreement on NATS
CNCF and Synadia Align on Securing the Future of the NATS.io Project
背景
最新情况
2025 年 5 月 1 日 – 云原生计算基金会(CNCF®)致力于构建云原生软件的可持续生态系统,与领先创新者 Synadia 今日宣布,广泛采用的 NATS 项目将在 CNCF 的云原生开源生态系统中继续蓬勃发展,Synadia 将继续支持并参与该项目。
- Synadia 同意将其两项 NATS 商标注册转让给 Linux 基金会
- NATS 项目的基础设施和资产——包括 NATS.io 域名和 GitHub 仓库——将继续由 CNCF 持有,确保项目在 Apache-2.0 许可证下的长期稳定和持续开源发展
2. Redis 再次开源
Redis is now available under the AGPLv3 open source license
Navigating the Path From Redis to Valkey
也是承接上文,继续带来一份关于开源的新闻。
背景
Redis 是流行的内存数据存储,很多大型企业都在使用。考虑到像 AWS 和 Google 这样的超大规模企业的兴起,使得开源公司难以在云提供商在没有按比例回馈开源项目的情况下获取利润和控制基础设施时,继续创新和投资开源项目。所以去年 Redis 将其代码置于专有的 Redis Source Available License v2 (RSALv2) 和 Server Side Public License v1 (SSPLv1) 双重许可下。这种做法的初衷是为了阻止 AWS、Google 等大型云服务商在未获授权的情况下将其作为托管服务提供(微软是少数选择授权使用 Redis 的大型云服务商)。然而,这导致 AWS、Google、Oracle 等公司去支持了 Redis 的一个分支 —— Valkey。同时损害了与 Redis 社区的关系。
再次开源
由于该许可调整的效果未及预期、社区反响以及 Valkey 分支的出现,随着 Redis 联合创始人 Salvatore Sanfilippo 的回归,公司重新评估了策略,认为 AGPL v3 许可证能够提供所需的保护,所以 Redis 再次回归开源,其最新版本 Redis 8 将采用 AGPL v3 许可证。
相关讨论
在 Reddit 的帖子中有几条回复:
- I wonder how many times people will have to learn this lesson. Over and over and over and over again. Emby, OpenOffice, Redis, Elastic. The list somehow keeps growing, and it always ends up the same way. Every single time someone attempts this stunt.(我想知道人们必须学习多少次这一课。一遍又一遍。Emby、OpenOffice、Redis、Elastic。这个列表不知何故一直在增长,而且总是以同样的方式结束。每次有人尝试这种噱头。)
- Trust arrives on foot and leaves on horseback.(信任步行到达,马背离开。)
3. Grafana 将 Beyla 捐赠给 OpenTelemetry
Grafana’s eBPF Beyla Future Hinges on OpenTelemetry
大约六个月前,Grafana 意识到其 eBPF 开源项目 Beyla 更适合通过 OpenTelemetry 项目来推动自动检测。因此,Grafana 已决定将 Beyla 捐赠给 OpenTelemetry 项目,该项目于 2021 年获得了 CNCF 孵化(Incubating)状态。
Grafana Labs 希望,这项捐赠将扩展 Beyla(现在是 eBPF OpenTelemetry),使其成为推广 eBPF 覆盖范围的最佳方式,以获取只有它才能提供的那些类型的指标,同时通过更广泛的社区扩大其影响力。
类似于 Grafana 对 CNCF 第二个最老项目 Prometheus 的管理和捐赠,eBPF OpenTelemetry 被视为在遥测数据普及方面扮演着更广泛的角色,这些数据得益于 eBPF,能够一直延伸到内核,并遍布整个网络。
4. Nutanix 相关的新闻与访谈三则
Nutanix 通过新产品和服务从超融合基础设施 (HCI) 提供商向更广泛的平台提供商转型
Nutanix Unveils Major Platform Expansions at .NEXT 2025
Nutanix 在 .NEXT 2025 发布一系列新产品和服务,标志着其从单纯的超融合基础设施 (HCI) 提供商向更广泛的平台提供商转型,支持分布式、可扩展的 IT 运营。
主要更新包括:
-
扩展现代基础设施: Nutanix 正式支持外部存储系统(例如 Dell PowerFlex 和 Pure Storage),允许客户保留其现有的存储架构,同时通过 Nutanix 的 Prism 界面管理工作负载。此举旨在帮助企业减少对 VMware 的依赖。
-
云原生 AOS: 推出了 Cloud Native AOS,这是长期酝酿的 Project Beacon 的首个产品发布。这是一个容器化的 AOS 存储堆栈版本,可在 Kubernetes 环境中部署,无需虚拟机管理程序。支持 Amazon EKS、Google Cloud 和 Canonical 的裸机 Linux 部署。
-
与 NVIDIA 的 AI 赋能: Nutanix 与 NVIDIA 扩展合作,将高级 AI 代理模型集成到企业 IT 工作流程中,使用 NVIDIA 的 NeMo 框架部署生产级大型语言模型 (LLM),并增强隐私和控制。
Nutanix 和 Pure Storage 合作,为任务关键型工作负载提供新的集成解决方案,为客户提供更多选择
2025 年 5 月 7 日,混合多云计算领域的领导者 Nutanix 和提供全球最先进数据存储平台和服务的 IT 先驱 Pure Storage® 宣布建立合作伙伴关系,旨在提供深度集成的解决方案,使客户能够在可扩展的现代基础架构上无缝部署和管理虚拟工作负载。
优点:
- 可扩展的现代基础架构 - 此次合作将为客户提供高性能、灵活和高效的全栈基础架构,通过用于虚拟计算的 Nutanix 云基础架构的简单性和敏捷性,以及 Pure Storage 全闪存系统的一致性、可扩展性和性能密度,为客户提供高性能、灵活和高效的全栈基础架构,为其最关键的业务工作负载提供支持。
- 内置网络弹性 - 客户将能够利用原生 Nutanix 功能(如 Flow 微分段和灾难恢复编排)以及 Pure Storage FlashArray 功能(如静态数据加密和 SafeMode),加强其端到端网络弹性态势。
- 自由选择 - 客户希望获得敏捷性并控制其任务关键型环境。Nutanix 和 Pure Storage 的结合将为现有市场选择提供一种弹性和易于使用的替代方案。
该解决方案预计将于 2025 年夏季开始早期试用,年底正式上市,并支持 Cisco、Dell、HPE、Lenovo 和 Supermicro 等主要服务器硬件合作伙伴。
Nutanix 首席执行官 Rajiv Ramaswami 对云原生企业的看法
Q&A: Nutanix CEO Rajiv Ramaswami on the Cloud Native Enterprise
Nutanix 现在正在扩展到其 HCI 根源之外。现在,Nutanix 将自己定位为平台提供商,为需要使用同一套管理工具在任何地方(云、本地或边缘)运行其应用程序的公司提供服务。这种计划的关键是云原生计算。2023 年,该公司收购了专注于云原生的 D2iQ(前身为 Mesosphere),后者维护着自己的基于 Kubernetes 的云原生平台。
下面是根据访谈主题的摘要(推荐阅读原文):
Nutanix 如何定义云原生计算?
D2iQ 构成了我们云原生工作的核心。我们拥有符合 Cloud Native Computing Foundation 的完整解决方案,其中包含 Nutanix Kubernetes 平台。
首先,我们得到了一个多云 Kubernetes 平台,它基于 D2iQ 解决方案,我们使用的一切都是开源的,并且符合 CNCF 标准。所以我们有一个用于运行时的 Kubernetes 平台。
我们还有一个 Kubernetes 管理平台,可与原生底层 Kubernetes 底层配合使用,无论是 [AWS] 的 Elastic Kubernetes Service、Azure Kubernetes Service 还是 Google Kubernetes Engine。您可以使用 Nutanix 管理跨多个云或本地云和公有云的集群。这是一个多云解决方案。
但云原生工作具有多种元素。它不仅仅是一个用于管理的 Kubernetes 解决方案。它还包括大约 30+ 附加组件:负载平衡、可观察性;我们引入的所有这些开源组件,我们将其编排并集成为解决方案的一部分。所以这就是基础。
然后,我们正在开发的最后一个组件就是我们所说的平台服务。这意味着通过 Nutanix 数据库服务实现数据库即服务。例如,我们支持 Postgres 和 Oracle。因此,可以将其视为本地可用的 Amazon RDS,我们正在公有云中提供它。
如果你把这三个组成部分放在一起考虑,最重要的是,它有一个 AI 元素。因此,Nutanix Enterprise AI 完全构建在 Kubernetes 之上。它本质上为代理 AI 应用程序提供了一个框架。所以我们有一组功能来下载模型、实例化模型、部署完整的 Nvidia AI 堆栈。
过去,我们认为 Nutanix 提供超融合基础架构 (HCI),拥有自己的虚拟机管理程序和强大的存储解决方案套件。这个平台如何(我不想称它为传统堆栈 ),但这个平台与云原生产品相融合?
我们认为 VM 提供了许多功能来有效管理基础架构。您可以使用虚拟机提高基础架构的利用率。您可以提高可管理性,并为基础设施提供安全弹性。
容器是开发人员关注的重点。它们提供敏捷性。它们为应用程序提供了扩展,并缩短了开发人员构建和运行这些东西的上市时间。
大多数客户将同时拥有两者,我们允许他们在同一平台上运行。我们可以将容器嵌入到 VM 中,实际上,这是人们运行大多数云原生应用程序的好方法。如果您查看公共云,在大多数情况下,Kubernetes 实际上运行在公共云中的 VM 之上。为什么?因为您可以获得更好的底层基础设施效率。
我们提供灵活性和选择。您可以在容器上运行 VM,可以在 VM 上运行容器,也可以在裸机上运行容器,具体取决于用户场景。
您是否看到人们对云提供商的成本和不灵活性越来越不满?
并非所有内容都将在公共云中构建。所以世界在很大程度上是一个混合环境。因此,一些应用程序将在公共云中运行。有些将在本地运行。有些人会成为边缘。
我们与云提供商合作。我们已经在 AWS 裸机和 Azure 裸机上运行了一段时间。现在,我们今天将宣布我们也在 Google 上运行。
今天的应用程序、明天的应用程序、AI 应用程序:在我看来,它们都将是混合的。因此,我们的观点是,我们提供这种灵活性和选择。
企业担心成本效益,这可能是他们从云提供商那里撤退的原因吗?
当然,成本和效率非常重要。我的意思是,他们意识到公共云的成本更高,通常是在大规模运行数据时。数据主权是另一个问题。许多国家/地区都希望数据本地化。安全性是另一个考虑因素。人们不一定会将所有内容都放在公共云中。
从数据的角度来看,延迟是另一个考虑因素。因此,如果您正在对边缘生成的数据运行 AI 推理,那么您实际上没有时间将这些数据发送到云中,以便您进行推理并返回。你必须在本地进行。所以换句话说,我认为 AI 计算必须去数据的地方,而不是相反。
今年的会议非常强调提供可在任何地方运行的应用程序。您能详细谈谈吗?
人们希望能够在任何地方运行他们的应用程序。有些将在本地运行。有些将在公共云上运行,有些将在边缘运行。因此,我们的理念是提供一个平台,让客户可以随时随地运行这些应用程序。那就是在任何地方运行:公共云、本地、虚拟机管理程序、裸机容器。
我们提出的价值主张之一是,无论您在哪里运营,平台都是相同的。您正在使用同一组工具来管理整个环境。
许多人仍然认为 Nutanix 是超融合基础架构 (HCI) 的提供商。现在还是这样吗?
这是我们今天之前的情况。您应该将我们视为一家多云平台软件公司。因此,我们转型为一个同时处理虚拟机和容器的云平台。
您如何看待使用 AI 的企业?
现在还为时过早。当然,传统的 AI 和机器学习计算机视觉已经使用了一段时间,用于企业中的许多用例。下一个尝试是生成式 AI。我想说我们正处于推理的早期阶段。
我们的重点是推理,而不是训练。训练模型将在公有云中的通用数据上进行训练,然后人们将采用这些模型,对其进行微调或排名,然后将它们用于特定的使用案例。这就是我们关注的一组应用程序。
另一个我们一直在密切关注的话题是 Broadcom(博通)引起的不满,特别是在虚拟机用的 VMware 平台定价方面,尽管许多客户似乎仍选择留用 Broadcom/VMware。您最近看到了什么情况,Nutanix 在这方面的价值主张是什么?
我们一直将其描述为一个多年的旅程。对于客户来说,您的基础设施软件往往具有粘性。你不能立即离开。原因有很多,因此我们描述了这些人将在未来三到五年内慢慢离开,甚至可能更长时间。因此,我们在上个季度大约增加了 700 个新客户,其中很多客户都是从 VMware 转移过来的。它正在发生,但它正在以有节制的速度发生,并将以这种速度持续数年。
5. ServiceNow 收购 Data.World 以扩展其 AI 数据战略
ServiceNow Acquires Data.World To Expand Its AI Data Strategy
ServiceNow、Data.World 是什么
ServiceNow 成立于 2004 年,涉足 ITSM(信息技术服务管理)领域,为 IBM 和惠普等老牌企业提供竞争。今天,它不仅仅局限于 ITSM,尽管它仍然是其收入的主要部分。 现在,it 已经多元化为五大服务,包括 IT、安全、人力资源服务交付、客户服务和业务应用。 ServiceNow 是一个集成的云解决方案,它将所有这些服务组合在一个记录系统中。
Data.World是一家数据分析和协作平台供应商,致力于帮助企业发现数据共享的优势。 公司的主要业务是利用公司软件设计帮助用户迅速、轻松地找到数据,进行准备和共享工作,然后利用数据来实时协作解决最复杂的学术、商业和社会问题。
为什么收购
ServiceNow 高级副总裁兼总经理 Gaurav Rewari 认为:仅仅拥有这个代理 AI 层和编排等是不够的。ServiceNow 必须帮助客户处理下面的管道。要实现这一点,ServiceNow —— 以及任何类似的平台——需要具备三个要素:
- 一个高性能且可扩展的数据库(对于 ServiceNow 来说,这就是其 Postgres 分支 RaptorDB),因为随着代理数量的激增,它们将使现有系统承受超出目前需求压力的负载。
- 代理能够访问单一公司内部数据孤岛之外的数据的能力。
- 确保数据质量的工具以及管理数据的治理工具。
收购 Data.World 为 ServiceNow 带来了一个基于知识图谱构建的数据目录和数据治理解决方案。最后一点至关重要,因为 ServiceNow 的核心架构原则,体现在配置管理数据库中,就是语义层或知识图谱的概念Data.World 从第一天起就通过其基于知识图谱的特性,使其在众多数据目录供应商中脱颖而出。
其他收购行为
ServiceNow 上个月宣布打算以 28.5 亿美元收购代理 AI 初创公司 Moveworks。
5. Docker 相关的新闻与访谈两则
Docker 推出强化镜像,强化安全容器市场
Docker Launches Hardened Images, Intensifying Secure Container Market
Docker 推出了 Docker Hardened Images (DHI),这是一个经过安全强化、面向企业的容器镜像目录,旨在应对日益严重的软件供应链威胁。DHI 的特点包括最小化、持续维护、内置安全功能(包括 SLSA Level 3 认证)、默认无根权限、符合法规要求(提供 SBOM、VEX 等),并支持多种发行版。这使得开发者能够更轻松地部署安全的容器,而无需改变既有的工作流程。
虽然 DHI 与 Chainguard 的安全容器镜像服务有竞争关系,但两者也存在合作,并共同致力于提供安全、最小化且持续更新的容器镜像。创建真正安全的镜像并非易事,许多现有镜像都存在大量漏洞。Docker 的优势在于其庞大的开发者基础和 Docker Hub 的普及性,而 Chainguard 则专注于消除所有常见漏洞和风险 (CVE),并快速修复漏洞。除了 Docker 和 Chainguard 之外,其他公司也提供类似的安全容器镜像服务,例如 Red Hat、Wiz 和 Canonical 等。
AI 时代的容器:与 Docker 新任总裁 Mark Cavage 的对话
Containers in the Age of AI: A Chat With New Docker President Mark Cavage
下面是根据访谈主题的摘要:
开发人员目前面临的最棘手的问题是什么,Docker 正在做些什么来提供帮助?
我将讨论三件事,即开发人员生产力、安全性和 AI。
- 在开发人员的工作效率方面,开发人员利用容器最佳实践中最前沿的部分来做他们能做的每一件事。他们已经自动化了所有事情,并且已经做了一切必要的工作,使他们的产品成为云原生、容器原生、低成本、超高扩展性等。
- 在安全方面,我们正在进行大量投资来帮助开发人员管理他们的环境,让他们不必处理安全漏洞,也不必处理 CVE,只需消除这些痛苦,帮助他们提高工作效率并帮助他们安全可靠地交付。
- 我们刚刚推出了 Docker Model Runner。我们坚信世界将由 LLM 花园组成。我认为开发人员需要选择,他们需要在笔记本电脑上访问这些东西。他们需要在生产环境中访问这些内容,无论是出于隐私、成本、延迟还是任何原因。因此,将开发人员喜欢的所有 Docker 工具、所有 Docker 友好性和所有 Docker 功能引入使用 LLM 的能力,以及将来的代理应用程序,这是一个绝佳的机会。
您是否正在与模型提供商合作?
我们正在与 Mistrals 和 Llama 以及 Gemma 等模型提供商合作。这些都打包为 Docker Hub 中的 OCI 标准容器 。您使用模型的方式就是您使用任何其他容器的方式。我认为,对于以前对此感到兴奋但又不敢进入它的开发人员来说,这要简单得多,也更容易获得,因为他们很难与之互动,也很难进入生态系统。我们将这一切自然而然地带到生态系统中。
Docker 还发布了其 MCP 目录和工具包。
💬 专题三 讨论与分享
1. 了解模型上下文协议(MCP,Model Context Protocol)
Introducing the Model Context Protocol
MCP 是什么
模型上下文协议 (MCP) 是由 Anthropic 开发的新兴开放标准,现在被主要行业参与者采用,它正在简化 AI 模型与外部工具和数据的交互方式。
Model Context Protocol 是一种开放标准,使开发人员能够在其数据源和 AI 驱动的工具之间构建安全的双向连接。架构很简单:开发人员可以通过 MCP 服务器公开他们的数据,也可以构建连接到这些服务器的 AI 应用程序(MCP 客户端)。
开发背景 & 解决问题
随着 AI 助手得到主流采用,该行业在模型功能方面投入了大量资金,实现了推理和质量的快速进步。然而,即使是最复杂的模型也受到与数据隔离的限制,它们被困在信息孤岛和遗留系统后面。每个新数据源都需要自己的自定义实施,这使得真正连接的系统难以扩展。
MCP 解决了这一挑战。它提供了一个通用的开放标准,用于将 AI 系统与数据源连接起来,用单一协议取代碎片化的集成。结果是一种更简单、更可靠的方法,使 AI 系统能够访问所需的数据。
拓展阅读
Model Context Protocol: Discover the missing link in AI integration
What Is MCP? Game Changer or Just More Hype?
KubeSphere MCP Server: 增强 AI 与 KubeSphere 的集成能力
Why APIs Are Essential and MCP Is Optional (for Now)
Remote MCP Servers: Inevitable, Not Easy
How MCP Enables Agentic AI Workflows
Why Canva Chose MCP Server Over AI Agent for App Developers
Model Context Protocol: A Primer for the Developers
Is Model Context Protocol the New API?
使用 Flux MCP 服务器实现 AI 辅助 GitOps
2. Kubernetes 1.33 部分新功能/优化解析
原地调整 Pod 资源特性升级为 Beta
Kubernetes v1.33:原地调整 Pod 资源特性升级为 Beta
传统上,更改分配给容器的 CPU 或内存资源需要重启 Pod。 虽然这对于许多无状态应用来说是可以接受的, 但这对于有状态服务、批处理作业或任何对重启敏感的工作负载可能会造成干扰。原地 Pod 调整大小允许你更改运行中的 Pod 内容器的 CPU 和内存请求及限制,通常无需重启容器。
防止无序删除时 PersistentVolume 泄漏
Kubernetes v1.33:防止无序删除时 PersistentVolume 泄漏特性进阶到 GA
通常,如果卷需要被删除,则预期是删除绑定的 PV-PVC 对的 PVC。但是, 删除 PVC 之前并没有限制不能删除 PV。对于一个“已绑定”的 PV-PVC 对,PV 和 PVC 的删除顺序决定了是否遵守 PV 回收策略。 如果先删除 PVC,则会遵守回收策略;然而,如果在删除 PVC 之前删除了 PV, 则不会执行回收策略。因此,外部基础设施中相关的存储资源不会被移除。
随着在 Kubernetes v1.33 中升级为 GA,这个问题现在得到了解决。 Kubernetes 现在可靠地遵循配置的 Delete 回收策略(即使在删除 PV 时,其绑定的 PVC 尚未被删除)。这是通过使用 Finalizer 来实现的, 确保存储后端如预期释放分配的存储资源。
允许将 OCI 镜像(或制品)作为只读卷挂载到 Kubernetes Pod 中
Kubernetes v1.33: Image Volumes Graduate to Beta
此功能与 AI/ML、DevSecOps 和构件分发空间中不断增长的 Kubernetes 用户集尤其相关。
DRA 的改进
Kubernetes v1.33 Brings Major Updates to Dynamic Resource Allocation (DRA)
在 DRA 之前,Kubernetes 严重依赖设备插件 API,这是一种允许节点级代理向调度程序公布可用硬件设备(如 GPU)的解决方案。虽然功能正常,但它也有局限性。DRA 通过在资源定义 、 声明和驱动程序之间引入明确的分离来解决这些问题。
Job 逐索引的回退限制进阶至 GA
Kubernetes v1.33:Job 逐索引的回退限制进阶至 GA
当你在 Kubernetes 上运行工作负载时,必须考虑 Pod 失效可能影响工作负载完成的场景。 理想情况下,你的工作负载应该能够容忍短暂的失效并继续运行。为了在 Kubernetes Job 中容忍失效,你可以设置 spec.backoffLimit 字段。 此字段指定容忍的失效总数。
修复了一个存在了 10 年的镜像拉取漏洞
Kubernetes silently carried this issue for 10 years, v1.33 finally fixes it
容器生命周期更新
容器生命周期回调的 Sleep 动作现在支持零睡眠时长(特性默认启用)。 同时还为定制发送给终止中的容器的停止信号提供了 Alpha 级别支持。
3. Service Mesh 是什么?
简介
服务网格(service mesh)的架构相当直观。它不过是一堆用户空间代理,紧挨着你的服务(我们稍后会讨论“紧挨着”意味着什么),再加上一套管理进程。
这些代理被称为服务网格的数据平面(data plane),而管理进程则被称为其控制平面(control plane)。数据平面拦截服务间的调用并对这些调用“进行处理”;控制平面协调代理的行为,并为你——操作者——提供一个 API,以便你能够整体上操作和衡量该网格。
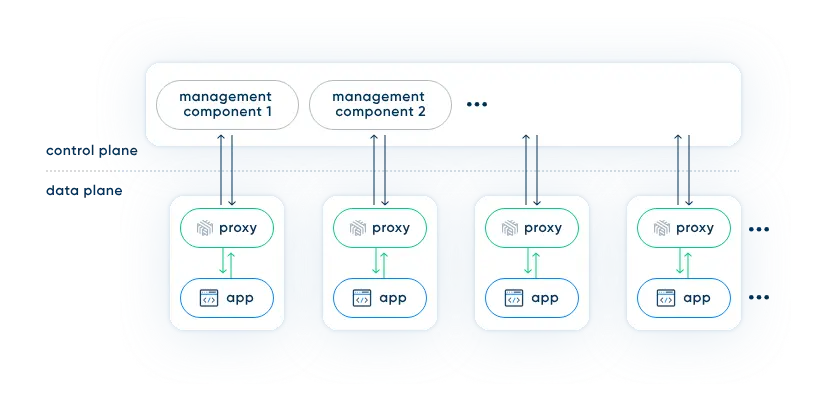
为什么需要
- 由于生态系统中正在发生的一些其他变化,部署这些代理的运营成本可以大大降低。
- 这种设计实际上是向系统中引入额外逻辑的绝佳方式。这不仅是因为你可以在那里(指服务旁边的代理位置)添加大量功能,而且还因为你无需改变现有生态系统即可添加这些功能。
受众
如果大致将团队分为服务负责人(service owners)和平台负责人(platform owners)。服务负责人负责构建业务逻辑,而平台负责人则负责构建这些服务运行的内部平台。在小型组织中,这些角色可能由同一个人承担,但随着组织规模的扩大,这些角色通常会变得更加明确,甚至进一步细分。(关于 DevOps 性质的变化、微服务的组织影响等等,还有很多内容可以讨论。但目前,让我们姑且接受这些描述。)
从这个角度来看,服务网格的直接受益者是平台负责人。毕竟,平台团队的目标是构建一个内部平台,让服务负责人可以在其上运行业务逻辑,并且要以一种让服务负责人尽可能独立于操作的“血腥细节”的方式来完成。服务网格不仅提供了实现这一目标至关重要的功能,而且它这样做的方式反过来也不会给服务负责人带来依赖。
服务负责人也受益,尽管是以一种更间接的方式。服务负责人的目标是在构建业务逻辑方面尽可能提高生产力,他们需要担心的操作机制越少,工作就越容易。他们无需负责实现例如重试策略或 TLS,而是可以纯粹专注于业务逻辑方面的问题,并相信平台会处理其余的一切。这对他们来说也是一个巨大的优势。
可以根据自己的角色具体来看:
- 业务逻辑开发者:无需关心,服务网格应是透明的,让他们专注于业务逻辑。
- 使用 Kubernetes 的平台团队:强烈建议关心。因为 Kubernetes 倾向于微服务架构,服务网格是管理大量微服务间复杂运行时依赖的必要工具。应了解并选择适合自身的服务网格方案。
- 未使用 Kubernetes 但使用微服务的平台团队:需要关心,但会很复杂。 虽然服务网格的价值仍在,但缺乏 Kubernetes 提供的部署模型,手动管理大量代理会显著增加运维成本,降低投资回报率。
- 正在使用单体应用的平台团队:无需关心。 对于通信模式明确且稳定的单体应用(或单体应用集合),服务网格带来的额外价值很小。
4. VMware 的 Kubernetes 演进:降低复杂性
VMware’s Kubernetes Evolution: Quashing Complexity
观点摘要
VMware Cloud Foundation 部门产品副总裁 Paul Turner 和节目主持人 Alex Williams(TNS 创始人兼发行商)探讨了 VMware 如何解决 Kubernetes 复杂性问题,同时支持容器化工作负载和虚拟机。下面是一些观点摘要。
- “要使 Kubernetes 可用,您实际上需要的不仅仅是 Kubernetes 运行时。您实际上需要一个 Kubernetes 平台,即一组刚刚运行的服务,否则,开发人员 — 最昂贵的资源之一 — 必须花费大量时间运行基础设施服务,而这些服务本应存在。”
- 人们似乎有一种有趣的信念,即虚拟化会产生很大的开销。它没有,他通过引用性能指标来支持他的说法:VMware 最近发布了 ML Perf 基准测试 ,显示基于容器的虚拟化 AI 应用程序以 98.3% 的裸机性能运行,同时提供跨集群动态应用程序移动等优势。(报告:Broadcom Delivers Near Bare-Metal Performance for Virtualized AI/ML)
- 关于 VMware 的 GPU 虚拟化功能:“我们可以对运行 PyTorch 前端的 AI 应用程序进行完全无中断的 V 形运动。我们可以在服务器之间移动它们而不会造成任何中断。一切都有效,而且 700 亿个参数的 Llama 模型同时运行推理服务。”
VMware 的做法
VMware 的解决方案是他们的 VCF (VMware Cloud Foundation) 平台 ,Turner 称之为“新 vSphere”。VCF 提供完整的 Kubernetes 环境,其中包含预配置的组件,包括控制器运行时、Harbor 注册表、Valero 备份、网络、存储和 Istio,所有这些组件都是开箱即用的,并由 VMware 管理。
拓展阅读
Learn KubeVirt: Deep Dive for VMware vSphere Admins
该文章的写作背景:作为 vSphere 管理员,您的职业生涯建立在对基础架构、数据存储、DRS 集群、vSwitch 和 HA 配置的理解之上。您习惯于大规模管理 VM。随着行业发生的所有变化,作者现在发现自己更多地使用 Kubernetes,并帮助 VMware 客户为其平台探索其他选项。KubeVirt 便是其中之一。
虽然 KubeVirt 承诺 Kubernetes 原生 VM 编排,但它也有一个警告:需要 Kubernetes 的流畅性。本文旨在弥合这一差距,不仅解释了 KubeVirt 是什么,还将其架构、作和概念直接映射到 vSphere 术语和经验。希望读者阅读完可以拥有一个与现有知识相关的 KubeVirt 心智模型。
主要的映射关系:
- vCenter/ESXi ↔ Kubernetes/KubeVirt: KubeVirt 如同 vCenter 的插件,在 Kubernetes 集群中管理虚拟机。每个节点上的 libvirt 类似于 ESXi 的 hostd。
- 虚拟机 ↔ VirtualMachine (CRD) & VirtualMachineInstance (VMI): VirtualMachine 是声明式的 YAML 定义,VMI 是运行中的实例。
- 数据存储/VMDK ↔ PersistentVolume/PersistentVolumeClaim: PVC 代表虚拟机磁盘,通过 CSI 驱动程序连接到各种存储系统。ReadWriteMany(RWX) 或块模式卷对于实时迁移至关重要。
- 虚拟交换机/端口组 ↔ Multus + CNI: Multus 允许每个虚拟机拥有多个网络接口,CNI 映射到网络配置。
- DRS ↔ Kubernetes调度器: 将 VMI 调度到各个节点,但缺乏精细的虚拟机感知资源平衡功能。
- vMotion ↔ 实时迁移API: 需要共享存储(RWX 或块模式 PVC)。
主要操作差异:
- 声明式 vs. 命令式: KubeVirt 使用 YAML 清单进行虚拟机定义和管理,取代了 GUI 驱动的工作流程。
- 自动化优先: GitOps 和自动化对于大规模高效管理至关重要。
- 工具: kubectl 和 virtctl 是主要的工具,取代了 vCenter 和 PowerCLI。
- 可观察性: 需要集成 Prometheus、Grafana 和集中式日志系统等多种工具。
- 日常运维: 与 vSphere 相比,监控、故障排除、补丁和安全管理方面存在显著差异。
5. vGPU 是伪命题?NVIDIA 官方为什么不自己出细粒度共享呢?
vGPU 是伪命题?NVIDIA 官方为什么不自己出细粒度共享呢?
虽然是 HAMi 的研发写的,但写的还是蛮坦诚蛮好的,推荐阅读原文。
背景
关于 HAMi 的讨论中会包含两种类型:
- CUDA 都是 NVIDIA 自家的,为什么官方不直接提供像 HAMi 这样的细粒度 GPU 共享能力?
- vGPU 是个伪需求,实际场景里大家都是巴不得整块 GPU 满载跑好几天。
围绕这些问题,可以从这几个角度聊聊。
HAMi 是什么,与 NVIDIA 的方案有何本质不同?
关于 Time-Slicing、MPS、MIG、vGPU 这四类方案的边界与局限:
- Time-Slicing:软件层轮转共享,兼容性好但无隔离,性能不可控,适合开发测试。
- MPS(Multi-Process Service):多个进程共享 GPU 上下文并发执行,提升吞吐,但无显存隔离,不适合多租户。
- MIG(Multi-Instance GPU):硬件级固定切分,强隔离、性能可预测,仅限高端卡,切分不够灵活。
- vGPU:基于 Hypervisor 的商业方案,通过预设 Profile 分配资源,隔离性强但粒度固定,需许可证。主要用于 VMware/Citrix/OpenStack 等平台,K8s 场景需借助 KubeVirt 引入 VM,部署复杂,原生支持度低。
NVIDIA 为何“不为”?是技术不能,还是商业不愿?
NVIDIA 掌握完整技术栈,如果战略需要,历史包袱也好,维护成本也好,技术层面必定攻克。显然,技术并非决定性障碍,真正的考量在商业与生态上。
首要的商业考量在于保护其精心构建的高利润护城河。MIG 技术是 Ampere 及后续数据中心级 GPU 的核心卖点,支撑着高端卡的溢价;若让中低端卡通过官方软件就能实现类似的细粒度切分,共享效率固然提升,但 MIG 的独特性和高端市场利润将可能被稀释。同时,vGPU 业务与 VMware、Citrix 等伙伴绑定了多年的商业许可模式,一个免费、容器原生且功能部分重合的官方方案,无异于自家产品的“打折清仓”,会直接冲击现有 vGPU 收入并扰乱合作关系。
维持清晰的产品线定位与市场区隔也至关重要。过于灵活通用的软件共享能力,可能模糊消费级 GeForce 与专业卡/数据中心卡之间的界限,让前者在部分服务器场景变得“够用”,从而影响后者的销售和定价策略。
此外,维护庞大的生态系统与合作伙伴关系同样是战略重心。损害与合作伙伴基于 vGPU 建立的深厚联盟,对 NVIDIA 而言损失更大。NVIDIA 近期收购 Run:ai 后选择开源其调度组件 KAI‑Scheduler,并且暂时未计划开源 Runtime 层的显存隔离代码,这一策略选择可见一斑。看起来在 K8s 生态中,NVIDIA 更倾向于提供“用得上,但不过度”的能力,通过上层调度优化来提升资源利用率,以此避免颠覆现有的商业产品(vGPU、NVIDIA AI Enterprise 等)和伙伴生态,为它们保留足够的市场空间。
2025.04 云原生相关信息简报 - NVIDIA 收购 Run:ai 并将其核心调度组件 KAI Scheduler 开源
HAMi 的核心竞争力与长期护城河到底在哪里?
HAMi 的竞争力并非单一技术突破,而是来自几个方面的结合。首先,我们成功地将 CUDA API 拦截的核心技术与 K8s 生态紧密整合,提供了一套实际可用、配置灵活的 GPU 虚拟化与调度增强方案,这本身就是一项复杂的、面向生产可用性的工程实践。
更关键的是 HAMi 非常独特的一个优势——对异构硬件的广泛兼容。除了 NVIDIA GPU,HAMi 从设计之初就考虑并已支持了多种国产 AI 芯片(比如寒武纪、海光、天数智芯、摩尔线程、昇腾、壁仞等等)。在国内强调供应链安全、信创适配的大背景下,这种统一纳管异构算力、降低单一供应商依赖的需求,是一个真实且日益强烈的痛点,也是 NVIDIA 这类单一硬件厂商难以全面覆盖的市场。
长期来看,什么能构成 HAMi 的“护城河”呢?坦白说,现在各种 AI 工具确实降低了不少技术的 learn & build 的门槛,单纯强调“技术壁垒有多高”或许不那么牢靠。
我认为,真正的壁垒更多在于那些难以快速复制的要素。HAMi 作为 CNCF 的 Sandbox 项目,已经在云原生社区积累了一定的认知和影响力,我们与 Volcano、Koordinator 等项目的集成、以及正在和 KAI-Scheduler 的协同工作,连同不断增长的社区用户和贡献者,正在逐步形成一个生态圈,赢得这个圈子的信任需要时间。
同时,对多种异构硬件特别是国产芯片的支持,为 HAMi 在特定市场(尤其是国内)构建了战略纵深和独特的价值定位,只要这种需求存在,HAMi 就有其不可替代性。
但这其中,我认为最重要的护城河,还是通过大规模实战检验所积累的客户信任与产品稳定性。企业选择基础设施软件,最终看的还是稳定可靠和良好支持。像华为、顺丰科技、科大讯飞等领先企业的实践与评估,这个逐步积累信任、打磨成熟度、沉淀运维经验的过程,才是最难被快速复制的。即使有了类似技术,要让企业客户放心用到生产环境,依然需要跨越很高的信任门槛。
所以,对于“NVIDIA 会不会自己下场”的担忧,结合他们收购 Run:ai 后的策略来看,我个人判断短期内可能性不大。即使未来出现变化,HAMi 凭借其异构支持和已有的市场基础,也并非没有一战之力。真正的挑战,其实在于我们自己能否持续打磨产品,赢得更多客户的深度信任,并创造更多成功的标杆案例。
拓展阅读
Developers Can Now ‘Uber’ GPUs With NVIDIA’s Lepton Platform
NVIDIA 宣布推出名为 DGX Cloud Lepton 的一站式商店,允许开发人员租用分散在全球各地的主机提供商的 NVIDIA GPU。
6. 在 Go 中从头开始构建 Kubernetes(精简版)
Building Kubernetes (a lite version) from scratch in Go
一篇写得蛮好的技术文档,具体见原文。
7. 技术世界的民主与权力
平台民主:重新思考谁来构建和使用您的内部平台
Platform Democracy: Rethinking Who Builds and Consumes Your Internal Platform
平台工程的演变,从最初的开发与运维分离,到 DevOps,再到平台团队,最后提出了一种新的模式:平台民主化。传统的模式常常导致瓶颈和效率低下。平台民主化则主张打破平台构建者和使用者之间的严格界限,让开发者、安全团队、SRE 甚至外部服务提供商都能参与平台的构建和维护。
要实现平台民主化,需要重新定义生产者和消费者的角色。生产者不局限于中央平台团队,可以包括外部服务提供商和内部团队;消费者则需要平台提供快速、安全、高效的服务。
实现平台民主化的关键在于:契约驱动的方法(Promises)、插件机制(Plugins)以及持续改进的机制(Fleet Upgrades)。
云、代码和控制:新的开源权力斗争
Clouds, Code, and Control: The New Open Source Power Struggle
在开源项目中权力动态的转变,类比于中世纪的封建制度。大型云提供商占据主导地位,类似于国王,拥有最大的权力;小型公司拥有部分权力,类似于贵族;而个人贡献者和用户则权力最小,类似于农民。
小型公司为了应对大型云提供商的竞争和投资者的压力,可能会重新许可开源项目,以此来限制云提供商的获利能力,从而改变权力平衡。但这又会进一步削弱贡献者和用户的权力。
为了应对这种权力失衡,贡献者和用户可以通过创建分支项目(fork)来重新获得控制权。然而,创建成功的分支项目需要大量的资源和人力。
8. 2025 年及以后,您的基础设施会是什么样子?
What does your infrastructure look like in 2025 and beyond?
作者的个人见解。具体见原文。
9. 了解和优化 Prometheus 中的资源消耗
Understanding and optimizing resource consumption in Prometheus
作者探讨了 Prometheus 监控系统资源消耗高的问题,并分析了其原因和优化方法。具体见原文。
📄 专题四 报告查看与分析
本月暂无。
✍️ 专题五 产品/方案介绍
1. OVHcloud 的 MKS:托管 Kubernetes 服务
简介
MKS 全称为 Managed Kubernetes Service,是 OVHcloud 提供的一项托管式 Kubernetes 服务。MKS 旨在简化 Kubernetes 集群的部署、管理和运维,让用户能够专注于应用程序的开发和部署,而无需过多地关注底层基础设施的复杂性。
OVHcloud 是一家全球性的云计算提供商,提供各种解决方案,包括专用服务器、托管数据库和云基础设施,总部位于法国。
价值
-
由 OVHcloud 完全托管
我们在自主管理的云基础架构上,管理 Kubernetes 集群正常运行所需的所有组件的配置、部署和维护。专注于创新和开发您的数字产品。
-
可扩展性和弹性
您的基础设施会根据负载自动调整,因此您只需消耗所需的资源,同时提高应用程序的弹性。
-
互操作性
获取经过认证的 Kubernetes 的所有功能。我们的解决方案已通过云原生计算基金会(CNCF)的认证,可确保高水平的互作性。您的基础设施保持灵活,并与您现有的所有工具和系统兼容。
-
服务生态系统
托管 Kubernetes Service (MKS) 原生集成了 OVHcloud 基础设施服务,例如用于密集计算的以 CPU 为中心的实例、用于人工智能的 GPU、存储类和负载均衡器。使用我们的附加服务更高效地创建和部署容器化和基于微服务的应用程序:Managed Private Registry、Managed Databases 和 Object Storage。
特点
-
自动扩展您的集群
通过自动扩展,您的基础设施可以适应应用程序的需求,无论是向上还是向下。
-
与您的访问管理工具集成
通过使用 OpenID Connect(OIDC)集成来管理访问权限,从而控制对 MKS 群集资源的访问。
-
简化的生命周期管理
一键或通过 API 调用触发 Kubernetes 更新,并定义集群的安全策略以自动应用新的安全补丁。
其他阅读
Open Source bringing Managed Kubernetes Service to the next level
OVHcloud 与 Kamaji 社区紧密合作,Kamaji 是一个托管控制平面管理器,提供纯净且上游的 Kubernetes 控制平面:这项进一步的验证,除了 NVIDIA 随 DOCA 平台框架发布带来的验证之外,标志着在可靠性和采用率方面又一个重要的里程碑。
Kamaji 是利用托管控制平面概念的 Kubernetes Control Plane Manager。Kamaji 的方法基于在 Pod 中运行 Kubernetes Control Plane 组件,而不是专用机器。这允许大规模作 Kubernetes 集群,而作负担只是其中的一小部分。由于这种方法,运行多个 Control Plane 可以更便宜,并且更易于部署和作。
2. Popeye:实时集群检查工具
简介
Popeye 是一个实用工具,它扫描实时 Kubernetes 集群并报告已部署资源和配置中存在的潜在问题。随着 Kubernetes 环境的不断发展,对于人类而言,跟踪协调集群的大量清单(manifests)和策略正变得越来越具有挑战性。Popeye 根据集群中已部署的内容而非磁盘上的内容进行扫描。通过对集群进行“代码检查”(linting),它能检测出配置错误、过期资源,并协助您确保最佳实践得到落实,从而避免未来的麻烦。它旨在减少在实际操作 Kubernetes 集群时所面临的认知过载。此外,如果您的集群部署了指标服务器(metric-server),它还会报告潜在的资源过量/不足分配,并试图在您的集群容量不足时发出警告。
Popeye 是一个只读工具,它不会以任何方式改变你的任何 Kubernetes 资源。
功能
- 集群扫描:Popeye 扫描实时 Kubernetes 集群,检测集群中存在的错误配置和潜在问题。
- 多种报告格式:支持多种输出格式,包括控制台、JSON、HTML、Grafana 仪表板等,方便用户查看和分析报告。
- 灵活的安装方式:支持 Linux、macOS 和 Windows 平台,可以通过二进制文件、Homebrew、go install 或从源代码构建安装。
- 可配置的 Linters:Popeye 提供了多种 Linters,用于检查不同类型的 Kubernetes 资源,例如 Pod、Service、Deployment 等。用户可以通过 Spinach YAML 配置文件自定义 Linters 的行为。
- 问题检测:检测常见问题,如端口不匹配、未使用的资源、资源利用率、探针、容器镜像、RBAC 规则等。
- 资源优化建议:如果集群启用了 metric-server,Popeye 还可以报告潜在的资源过度分配或不足的情况。
- 无修改操作:Popeye 是一个只读工具,不会更改任何 Kubernetes 资源。
- 报告保存:可以将扫描报告保存到本地文件或 S3 对象存储。
- Docker 支持:可以在 Docker 容器中运行 Popeye。
- Prometheus 集成:可以将扫描结果以 Prometheus 指标的形式发布,并提供 Grafana 仪表板示例。
- Spinach YAML 配置:通过 Spinach YAML 配置文件,用户可以排除特定资源或 Linter 代码,并配置资源利用率阈值。
- 集群内部运行:Popeye 可以作为 CronJob 在 Kubernetes 集群内部运行。
- RBAC 支持:需要适当的 RBAC 权限才能访问和扫描 Kubernetes 资源。
- 评分系统:根据扫描结果提供 Popeye Score,评估集群的健康状况。
🎤:有点可爱
3. Rook:云原生存储方案
4 月的简报曾介绍过 Rook 1.17 的更新内容,这次整体来看一下这款产品。
简介
Rook 是一个开源的云原生存储解决方案,专为 Kubernetes 设计。它通过 Kubernetes Operator 来管理分布式存储系统,如 Ceph,使其具备自我管理、自我扩展和自我修复的能力。Rook 简化了存储管理员的任务,如部署、配置、扩展、升级、迁移、灾难恢复和监控。它支持文件、块和对象存储,并能高效地在 Kubernetes 上运行 Ceph,实现弹性存储,优化工作负载,并充分利用通用硬件。
-
适用于 Kubernetes 的 Storage Operators
Rook 将分布式存储系统转变为自我管理、自我扩展、自我修复的存储服务。它自动执行存储管理员的任务:部署、引导、配置、预置、扩展、升级、迁移、灾难恢复、监控和资源管理。
Rook 利用 Kubernetes 平台的强大功能,通过适用于 Ceph 的 Kubernetes Operator 交付其服务。 -
Ceph Storage Provider
Rook 使用专门的 Kubernetes Operator 编排 Ceph 存储解决方案,以实现自动化管理。Rook 确保 Ceph 在 Kubernetes 上运行良好,并简化部署和管理体验。
特点
- 简单可靠的自动化存储管理
- 超大规模或超融合您的存储集群
- 高效分发和复制数据以最大限度地减少损失
- 提供文件、块和对象存储
- 管理开源 Ceph 存储
- 在您的数据中心轻松启用 Elastic Storage
- 在 Apache 2.0 许可下发布的开源软件
- 优化商用硬件上的工作负载
4. ORAS:处理 OCI Artifacts 的工具
简介
ORAS 是处理 OCI Artifacts(开放容器倡议制品)的事实标准工具。它将媒体类型视为关键组成部分。容器镜像从未被假定为唯一涉及的制品。ORAS 提供命令行工具(CLI)和客户端库,用于在符合 OCI 规范的注册表之间分发制品。
特点
- 制品引用
- 将供应链制品附加到容器镜像。
- 发现并展示制品引用关系。
- 扩展注册表,使其不仅仅用于存储容器镜像。
- 分布式软件制品
- 在 OCI 注册表中管理制品。
- 在注册表之间迁移制品。
- 通过 OCI 镜像布局在文件系统中管理制品。
- 探索和管理 OCI 镜像
- 在 OCI 注册表中管理镜像清单和层。
- 在 OCI 注册表中操作标签和仓库。
- 探索 OCI 镜像的详细内容。
拓展阅读
宣布 ORAS v1.3.0-beta.3 - 丰富 oras discover 的格式化输出
5. Kairos:Linux 边缘操作系统
简介
Kairos 是一个开源项目,可简化边缘、云和裸机作系统生命周期管理。借助统一的云原生 API,Kairos 是社区驱动的、开源的和与发行版无关的。Kairos 可将 Linux 和 Kubernetes 发行版转换为边缘设备的安全可启动映像
特点
- 可根据需求定制
使用 Kairos,您将掌握主导权。您可以根据自己选择的操作系统和 Kubernetes 发行版,为边缘设备构建自定义的可引导操作系统镜像。这些镜像以容器镜像的形式交付,并可根据您的需求进行定制和扩展。Kairos 能完美融入您的 CI/CD 流水线,并允许您选择自己喜欢的容器引擎。 - 一致性与安全性
告别集群间的不一致性,因为每个节点都从相同的不可变镜像启动,确保了统一性。它还降低了恶意攻击的风险,通过数据加密,您的存储数据也受到保护,从而增强了集群的安全性。 - 易于安装
我们致力于让事情变得简单。使用 Kairos,您可以通过二维码、手动、通过 SSH 远程、交互式或使用 Kubernetes 来设置节点。 - 针对 Kubernetes 进行了优化
Kairos 经过优化,可用于运行 Kubernetes 工作负载,并且升级也可以通过 Kubernetes 完成。然而,它也可以作为标准的 Linux 发行版使用。配置管理通过 cloud-init 完成。
拓展阅读
6. Rekor:为软件项目供应链中生成的元数据提供一个不可变、防篡改的账本
简介
Rekór - 希腊语,意为“记录”。
Rekor 的目标是为软件项目供应链中生成的元数据提供一个不可变、防篡改的账本。Rekor 将使软件维护者和构建系统能够将签名的元数据记录到不可变的记录中。其他各方随后可以查询这些元数据,从而能够就一个对象的生命周期的信任度和不可否认性做出明智的决定。
Rekor 项目提供了一个基于 restful API 的服务器用于验证,并提供了一个用于存储的透明日志。CLI 应用程序可用于制作和验证条目、查询透明度日志以获取包含证明、透明度日志的完整性验证或通过公钥或构件检索条目。
Rekor 履行了 sigstore 软件签名基础设施的签名透明度角色。但是,Rekor 可以独立运行,并且设计为可扩展以使用不同的清单架构和 PKI 工具。
拓展阅读
7. Vitess:围绕 MySQL 构建的云原生、可水平扩展的分布式数据库系统
简介
Vitess 是一个围绕 MySQL 构建的云原生、水平可扩展的分布式数据库系统。Vitess 能够通过通用分片实现无限扩展。
Vitess 允许应用程序代码和数据库查询对数据在多个数据库服务器上的分布保持无感知。使用 Vitess,您甚至可以根据需求增长来拆分和合并分片,只需几秒钟的原子切换步骤即可完成。
特点
- 可扩展性
Vitess 与 MySQL 兼容,同时扩展了其可扩展性。其内置的分片功能让您无需向应用程序添加分片逻辑即可扩展数据库。 - 高可用性
Vitess 自动检测并修复主要故障。将数据迁移到 Vitess 以及在 Vitess 中重新分片作都是在接近零停机时间的情况下完成的。 - 分片管理
MySQL 本身不支持分片,但随着数据库的增长,您可能需要它。Vitess 提供了灵活的分片方案,这些方案对应用程序完全透明。它还支持实时重新分片,同时将只读停机时间降至最低。 - 性能提升
Vitess 通过查询重写、缓存和连接池提高了 MySQL 的性能。这允许并发客户端连接的数量扩展到比传统 MySQL 高几个数量级。通过夜间基准测试来监控性能。 - 特征
Vitess 通过提供跨分片工作的具体化视图和消息传递功能来改进 MySQL。 - 架构管理
Vitess 允许您轻松管理架构,同时保持分片之间的一致性。架构更改在后台进行,而不会中断正在运行的工作负载。此功能附带一组丰富的监控和精细控制。
拓展阅读
8. Knative:基于 Kubernetes,用于构建、部署和管理现代无服务器工作负载的平台
简介
Knative 是一个用于构建无服务器和事件驱动应用程序的开源企业级解决方案。
为什么选择无服务器(serverless)容器
无服务器是指在云中运行后端程序和流程。无服务器按使用量工作,这意味着公司只需为他们使用的内容付费。Knative 是一种与平台无关的解决方案,用于运行无服务器部署。
- 更简单的抽象
使用我们的自定义 CRD 简化您的 YAML - 自动缩放
缩小到 0 和从 0 向上扩展 - 逐步推出
根据您的需求选择您的推出策略 - 事件集成
处理来自多个来源的事件 - 处理事件
来自事件代理的触发器处理程序 - 可插拔
Kubernetes 原生可集成和扩展
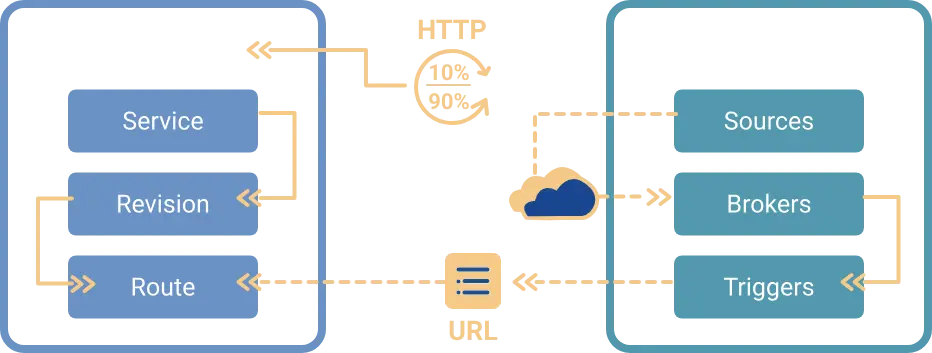
组件
Knative 有两个主要组件,可以为使用 Kubernetes 的团队提供支持。Serving 和 Eventing 协同工作以自动化和管理任务和应用程序。
- Serving:在 Kubernetes 中轻松运行无服务器容器。Knative 负责联网、自动扩展(甚至为零)和修订跟踪的详细信息。团队可以使用任何编程语言专注于核心逻辑。
- Eventing:事件的通用订阅、交付和管理。通过声明式事件连接和开发人员友好的对象模型将计算连接到数据流,构建现代应用程序。
拓展阅读
9. Kyverno:提供一套全面的工具来管理 Kubernetes 和其他云原生环境的策略即代码(PaC)生命周期
简介
Kyverno 是专为云原生平台工程团队设计的策略引擎。它使用策略即代码实现安全性、自动化、合规性和监管。Kyverno 可以使用 Kubernetes 准入控制、后台扫描和源代码存储库扫描来验证、更改、生成和清理配置。Kyverno 策略还可用于验证 OCI 映像,以确保软件供应链安全。Kyverno 策略可以作为 Kubernetes 资源进行管理,不需要学习新语言。Kyverno 旨在与您已经使用的工具(如 kubectl、kustomize 和 Git)完美配合。
Kyverno 策略是声明性 YAML 资源, 不需要新语言 。Kyverno 支持使用熟悉的工具(如 kubectl、git 和 kustomize)来管理策略。Kyverno 支持 JMESPath 和通用表达式语言 (CEL),以高效处理复杂逻辑。
适用场景
-
安全与合规性
- 强制执行 Pod 安全标准
- 要求特定的安全上下文
- 验证镜像来源和签名
- 确保资源限制和请求
-
卓越运营
- 自动添加标签和注解
- 强制执行命名规范
- 生成默认网络策略
- 验证资源配置
-
成本优化
- 强制执行资源配额
- 要求成本分配标签
- 清理未使用的资源
- 验证实例类型
-
开发者护栏
- 强制执行入口/出口规则
- 要求存活/就绪探针
- 验证容器镜像
- 自动挂载配置
拓展阅读
10. Kubewarden:Kubernetes 的策略引擎,有助于保持 Kubernetes 集群的安全性和合规性
简介
Kubewarden 是 Kubernetes 的策略引擎。它的目标是成为 Kubernetes 的通用策略引擎。Kubewarden 有助于保持 Kubernetes 集群的安全性和合规性。Kubewarden 策略可以使用常规编程语言或域特定语言 (DSL) 编写。策略被编译成 WebAssembly 模块,然后使用传统的容器注册表进行分发。
特点
- 使用任何能够生成 WebAssembly 二进制文件的编程语言来编写您的策略。
- WebAssembly 支持跨处理器和操作系统的策略兼容性。
- 无需重写即可重用其他策略引擎的策略。
- 使用标准且安全的机制(例如符合 OCI 标准的注册表)分发策略。
- 准入时的策略执行确保仅运行合规的工作负载。
- Kubewarden 审计扫描器会持续主动地检查策略执行情况。
- 使用 SLSA(软件工件供应链级别)工具和实践来验证策略。
- Kubewarden 提供了全面的准入策略管理方法。
- CNCF 成员资格以及不断发展的开源社区和生态系统有助于 Kubewarden 提高透明度、增强协作能力并不断改进。
适用场景
- 安全强化。例如,强制执行限制容器权限的策略、强制执行网络策略或阻止不安全的镜像仓库。
- 合规性审计。确保工作负载遵循组织或监管标准和最佳实践。
- 资源优化。强制执行资源限制和配额。
拓展阅读
11. kubectl-klock:一个 kubectl 插件,用于以更具可读性的方式呈现 kubectl get pods --watch 输出
简介
kubectl-klock 是一个 kubectl 插件,用于以更具可读性的方式呈现 kubectl get pods --watch 输出。可以将其视为运行 watch kubectl get pods,但它不是轮询,而是使用常规的 watch 功能在更新发生时立即流式传输更新。
由于创作者不喜欢 "fullscreen terminal apps",所以不喜欢使用 K9s,所以开发了这款产品。
12. Kmesh:高性能 Service Mesh 数据平面
简介
Kmesh 是基于 eBPF 和可编程内核的高性能、低开销服务网状数据平面。Kmesh 为服务通信提供流量管理、安全和监控功能,而无需更改应用程序代码。它原生无 sidecar、零入侵,并且不会给应用程序容器增加任何资源成本。
目前,业务网格数据面的时延和噪底开销已成为业务网格技术发展中的关键问题,且数据面技术多种多样。我们致力于为客户提供更轻量级、更高效的服务治理能力,满足客户对安全性、敏捷性和效率的要求。
特点
- 流畅兼容
- 应用透明的流量管理
- 高性能
- 转发延迟 60%↓
- 工作负载启动性能 40%↑
- 低资源开销
- ServiceMesh 数据平面开销 70%↓
- 零信任
- 通过默认双向 TLS 提供零信任安全
- 在 eBPF 和 Waypoint 中均支持策略执行
- 安全隔离
- eBPF 虚拟机安全
- Cgroup 级别编排隔离
- 开放生态
- 支持 XDS 协议标准
- 支持网关 API
13. OpenReports:提供统一的 API 和工具集,以标准化、供应商中立的格式生成和消费报告
宣布 OpenReports:标准化 Kubernetes 报告
简介
OpenReports 提供了用于在 Kubernetes 中管理报告的 API 和工具。
OpenReports 允许任何 Kubernetes 控制器、策略引擎或扫描器将报告作为 Kubernetes 自定义资源生成。然后,可以通过 kubectl、OpenReports 仪表板或任何其他 Kubernetes 客户端使用报告。为了在大型集群中实现高性能,可以使用 API 聚合服务将报表从 etcd 卸载到报表数据库。
特点
- 供应商中立性:OpenReports 旨在保持供应商中立,确保不同策略引擎和报告工具之间的互操作性。
- 社区驱动:作为一个 CNCF 沙箱项目(希望 – 在所有工具集成后计划提交!),OpenReports 将受益于社区的贡献与合作。
- 可扩展性与性能:该项目旨在处理大规模 Kubernetes 部署和大量政策报告。
- 简化集成:标准化格式和集成简化了将政策报告集成到现有监控和日志工作流中的过程。
功能
- OpenReports API:集群范围和命名空间的报告资源。
- Web 控制台:查看报告的 web 界面。
- 报告路由服务:将报告路由到各种通知目标的服务,如 Slack、Teams、Elasticsearch 等。
- API 聚合服务:通过将报告存储在单独的数据库中,减轻 etcd 的负担。这对于生成大量报告的大型或繁忙集群是必要的。
14. k0rdent:一个 Kubernetes 原生分布式容器管理环境(DCME)
简介
k0rdent 扩展了 Kubernetes,以帮助您在任何云或基础设施上轻松设计、部署和管理任何规模的基于 Kubernetes 的 IDP。
关于 IDP,见 2025.02 云原生相关信息简报 - 如何通过自助服务方法构建多租户平台
特点
- Kubernetes 原生平台管理
IDP/平台作为 Kubernetes 原生抽象进行管理,具有自我修复、自动升级和持续对账功能。 - 声明式和可组合性
使用集群、服务和基础设施的模块化模板定义 IDP/平台。完全兼容 GitOps 和 CI/CD。 - 多云、混合和边缘就绪
跨公共云、私有数据中心、裸机和边缘设备无缝管理集群和 IDP/平台。 - 安全性和扩展的黄金路径
配置工作流程和护栏以执行标准、确保合规性并大规模增强自助服务。 - 针对现代工作负载进行了优化
设计 IDP/平台以支持任何用例,从传统应用程序到 AI/ML、无服务器等。 - 开源和可扩展
基于开放标准构建,并与您已经使用的工具兼容。
为什么选择 k0rdent?
平台工程团队面临的挑战是交付内部开发人员平台 (IDP):
- 使开发人员能够在明确的防护机制内进行自助服务。
- 跨环境实施合规性和安全性。
- 满足业务对可用性、性能和成本效益的需求。
拓展阅读
Introducing k0rdent v0.3.0: Smarter observability, smoother operations
15. kubesolo:一个生产就绪的单节点 Kubernetes 发行版
简介
专为受限环境构建的超轻量级、符合 OCI 标准的单节点 Kubernetes。无聚类。没有 etcd。正是您在真实硬件上运行真实工作负载所需要的。
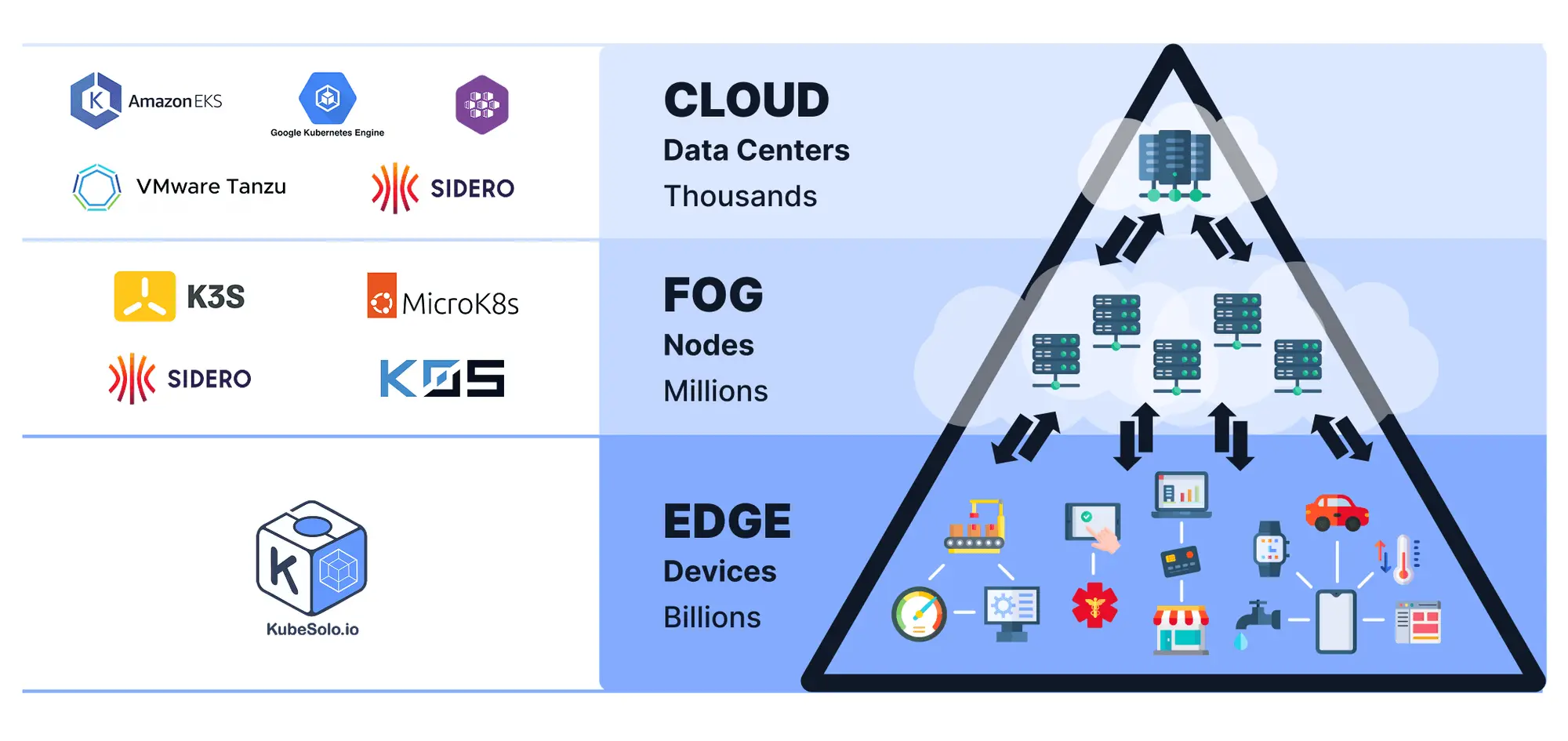
KubeSolo 专为网络最远层的设备而设计,例如 IoT、IIoT 和嵌入式系统。该图说明了现代分布式基础设施的三个主要层:
- 云(数据中心)规模:数千个节点 示例:Amazon EKS、Google Kubernetes Engine、VMware Tanzu、Sidero 用途:集中式大规模计算和存储
- FOG(分布式节点)规模:数百万个节点 示例:K3s、MicroK8s、Sidero、K0S 用途:更靠近边缘的分布式计算,通常用于延迟敏感型或区域性工作负载
- 边缘(设备)规模:数十亿台设备 示例:KubeSolo 用途:适用于资源受限环境(物联网网关、工业控制器、智能设备等)的超轻量级 KubernetesKubeSolo 位于此堆栈的最底部,为边缘提供简单的单节点 Kubernetes 体验,其中最少的资源和离线作至关重要。
特点
KubeSolo 比上游 Kubernetes 更轻量:
- 要运行的内存占用较小
- 二进制文件(包含运行集群所需的所有非容器化组件)更小
- Kubernetes Scheduler 不存在,相反,它被一个名为 NodeSetter 的自定义 Webhook 所取代
拓展阅读
KubeSolo FAQ: Clearing up Common Questions and Confusions
16. KubeVirt:是 Kubernetes 的虚拟机管理插件,目的是为 Kubernetes 之上的虚拟化解决方案提供一个共同的基础
简介
KubeVirt 的核心是通过添加额外的虚拟化资源类型(尤其是 VM 类型)来扩展 Kubernetes Kubernetes 的自定义资源定义 API。通过使用这种机制,Kubernetes API 可用于管理这些 VM 资源以及 Kubernetes 提供的所有其他资源。
为什么选择 KubeVirt
KubeVirt 技术满足了已经采用或希望采用 Kubernetes 但 拥有无法轻松容器化的现有基于虚拟机的工作负载。更具体地说, 技术提供了一个统一的开发平台,开发人员可以在其中构建、修改和部署应用程序 驻留在通用共享环境中的应用程序容器和虚拟机中。
好处是广泛而显著的。依赖基于虚拟机的现有工作负载的团队能够快速容器化应用程序。通过将虚拟化工作负载直接放置在开发工作流中,团队可以随着时间的推移分解它们,同时仍能根据需要利用剩余的虚拟化组件。
可以用 KubeVirt 做什么
- 利用 KubeVirt 和 Kubernetes 管理无法容器化的应用程序的虚拟机。
- 在一个平台上将现有虚拟化工作负载与新的容器工作负载相结合。
- 支持在与现有虚拟化应用程序交互的容器中开发新的微服务应用程序。
拓展阅读
Open Source KubeVirt: VM Management With Kubernetes Is a Work in Progress
核心观点:
- KubeVirt 的功能相对有限,主要支持创建、调度、启动、停止和删除预定义的 VM,缺乏成熟的虚拟机管理平台所具备的诸多高级功能,例如存储管理集成、快照、扩容等。其对存储系统的依赖也受限于 Container Storage Interface (CSI) 驱动的支持程度,而许多 CSI 驱动程序并不支持常用的存储功能。
- KubeVirt 的 Kubernetes 原生设计增加了迁移和管理的复杂性,需要组织机构对现有 IT 基础设施进行重大变更,并对团队进行大规模的技能再培训。对于拥有大量VM的企业来说,这种转变成本高昂且风险巨大。
- Gartner 预测,至少到 2028 年,KubeVirt 在企业生产环境中的采用率将低于 10%。文章建议,除非是针对少量 VM 的非生产环境(例如开发和测试环境),否则不建议企业采用 KubeVirt 进行大规模生产环境的虚拟机管理。成熟的虚拟机管理平台仍然是更安全可靠的选择。
🤣 专题六 相关趣事与 Meme
1. Kubernetes 升级

K8s has help me with the character development 😅
2. 关于开源

This reminds me of the CNCF tools
3. 全世界如何庆祝开源维护者月
How the World Is Celebrating Open Source Maintainer Month
2025 年 5 月是第五个年度维护者月。自 2021 年起,GitHub 每年都会举办此活动,通过折扣、活动、教育资源等方式,普遍庆祝和表彰所有致力于开源项目运行的维护者们。
4. Traefik Labs 的拉踩营销
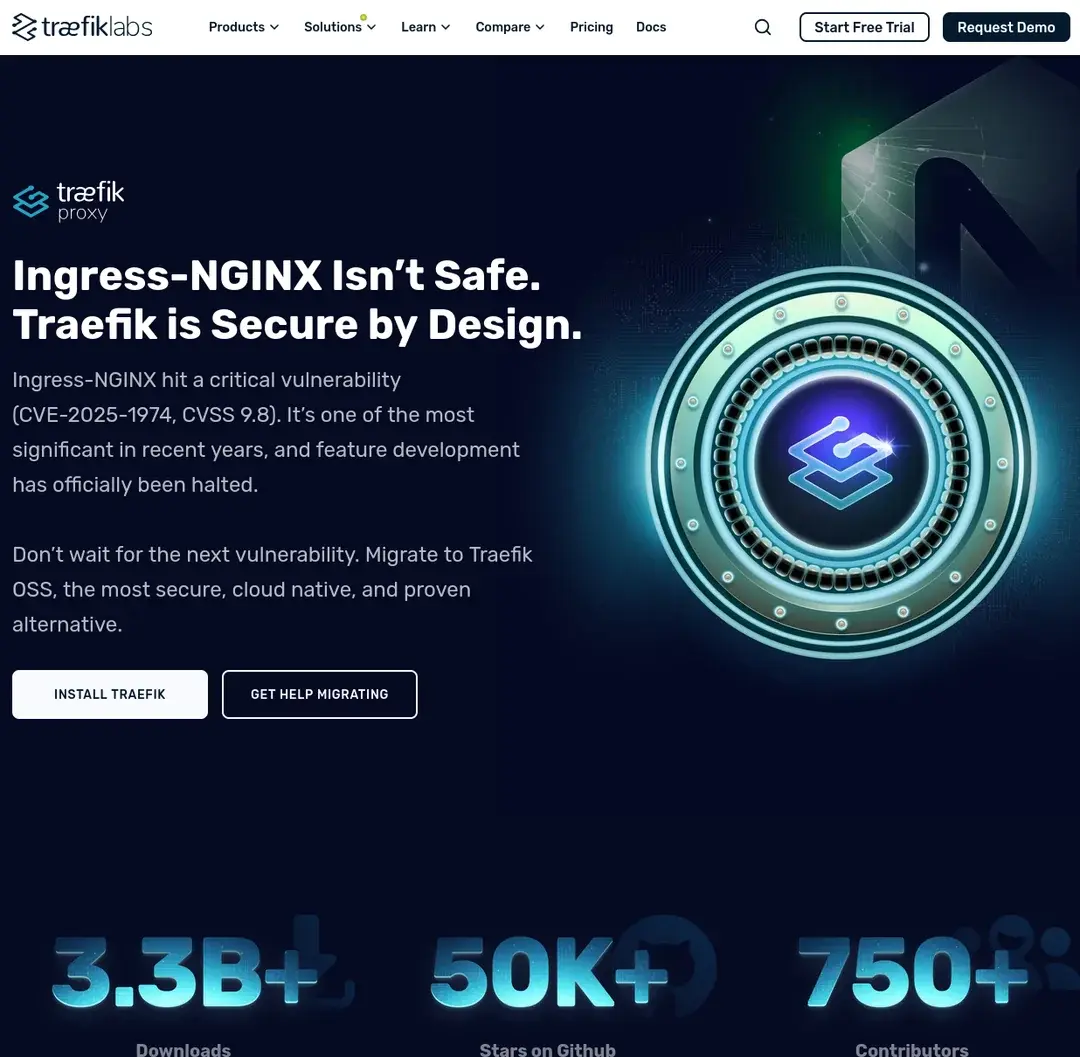
Calling out Traefik Labs for FUD
5. HAMi 到 Reddit 寻求建议
背景
与 2025.04 云原生相关信息简报 - 5.2k 星的 Rainbond 在海外为何无人问津类似。同样是在大陆(并未明说)有一定数量的用户,但是在海外受众有限。
帖主想了解:
- 项目/文档/社区的哪些部分感觉像是阻塞者?
- 什么会让您(或其他人)更有可能尝试 HAMi?
- 有没有我们完全忽略了什么?
⚠️ 关于 HAMi,本文前面也有介绍,在此不做赘述。
回复摘要
- 告诉我为什么想在现实生活中使用 HAMi,然后告诉我它如何帮助我。
- 想想最成功的 CNCF 项目,它归结为曝光度和易于消化的信息大小。
🎤 想到了经典 4 P:产品(Product)、价格(Price)、渠道(Place)和促销(Promotion)。以及太多重点就是没有重点。以及读者的注意力是很有限的。 - HAMi 的安装和运行真的简单吗?还是需要专门的工程学位?
- 才来没有没听说过。仅仅加入 CNCF 并不能带来太多的知名度。你仍然需要进行市场营销和社区参与。
6. 不要以我之名:Brian Eno 致 Microsoft 的一封公开信
Not in My Name: An Open Letter to Microsoft from Brian Eno
Brian Eno 是谁
Brian Eno 生于 1948 年 5 月 15 日,也被称为 Eno,是一位英国音乐家、词曲作者、唱片制作人、视觉艺术家和活动家。他最出名的是他对环境音乐和电子乐的开创性贡献,以及摇滚和流行音乐的制作、录音和创作作品。
可以试试这张专辑以了解他的音乐风格:Before and After Science。
中文全文
在 1990 年代中期,我受邀为微软的 Windows 95 操作系统创作一小段音乐。数百万——甚至可能是数十亿——的人们此后都听过那段简短的开机提示音——它代表着通往一个充满希望的科技未来的门户。我欣然接受了这个项目,将其视为一项创意挑战,并享受与微软公司相关人员的合作互动。我从未想过,同一家公司有朝一日会与压迫和战争的机器产生牵连。
今日我不得不发声,这次不是以作曲者身份,而是以公民身份——针对微软正在参与的另一种“谱曲”(composition):一种导向对巴勒斯坦的监控、暴力与毁灭的“谱写”。
在 2025 年 5 月 15 日的一篇博文中,微软承认它向以色列国防部提供了“软件、专业服务、Azure 云服务和 Azure AI 服务,包括语言翻译”。它接着声明“重要的是要承认,微软无法了解客户如何在自己的服务器或其他设备上使用我们的软件”。这些所谓的“服务”,实则为某个政权提供支持——该政权所推行的行径,已被顶尖法律学者、人权组织、联合国专家以及全球越来越多国家的政府认定为种族灭绝。微软与以色列政府和军队之间的合作并非秘密,其中包括该公司的软件被用于具有“滑稽”名称的致命技术,例如“爸爸在哪里?”(——用于追踪巴勒斯坦人以便在家中将其炸死的制导系统)。
向一个从事系统性种族清洗的政府出售和提供先进的 AI 和云服务,这可不是什么“常规业务”。这是共谋。如果你明知故犯地构建能够导致战争罪的系统,你将不可避免地成为这些罪行的同谋。
我们现在生活在一个像微软这样的公司通常比政府拥有更大影响力的时代。我相信,拥有如此权力,就伴随着绝对的道德责任。因此,我呼吁微软立即暂停所有支持违反国际法行为的服务运营。
我的新开机提示音是:与那些真正具有颠覆性并拒绝保持沉默的勇敢的微软员工站在一起。他们为了那些已经失去并将继续失去生命的人们,冒着生计的风险。
我邀请艺术家、技术人员、音乐家以及所有有良知的人响应这份呼吁,与我同在。
我还承诺,我最初为创作 Windows 95 提示音收到的报酬,现在将用于帮助加沙遇袭的受害者。如果一个声音能够预示真正的改变,那就让它成为这样的声音。