

# 郑成诗:低时延深度学习语音增强方法及应用 #

语音是人与人之间进行信息沟通最直接、最方便和最有效的方式。语音在空气中传播,在被麦克风拾取之前或者到达人耳之前,会受到各种环境噪声和风噪的影响,降低语音质量和可懂度,提升听者疲劳感和烦恼度。由此,语音增强成为语音信号处理的重要组成部分,目前已受到广泛的关注、研究和应用。

语音增强/重要性
噪声的种类繁多且动态范围大。根据《中华人民共和国环境噪声污染防治法》的分类,环境噪声包括交通噪声、工业噪声、机械噪声以及社会生活噪声等,这些噪声都会影响语音质量和语音可懂度。
值得一提的是,针对语音应用场景,即便是音乐也属于噪声;而在户外应用场景,风噪作为一类特殊的噪声,会对户外语音通话、助听器和人工耳蜗等产品产生严重的影响。
相比较而言,语音信号语谱图是结构化的。这是由于语音是由人的发声器官产生,语音信号的产生过程是可以进行数学建模的,其模型主要由三部分组成:
-
激励模型
-
声道模型
-
辐射模型
根据声带是否需要振动,把语音分为清音和浊音:清音能量主要集中在中高频,表现出随机性;浊音具有谐波结构,表现出一定的确定性。
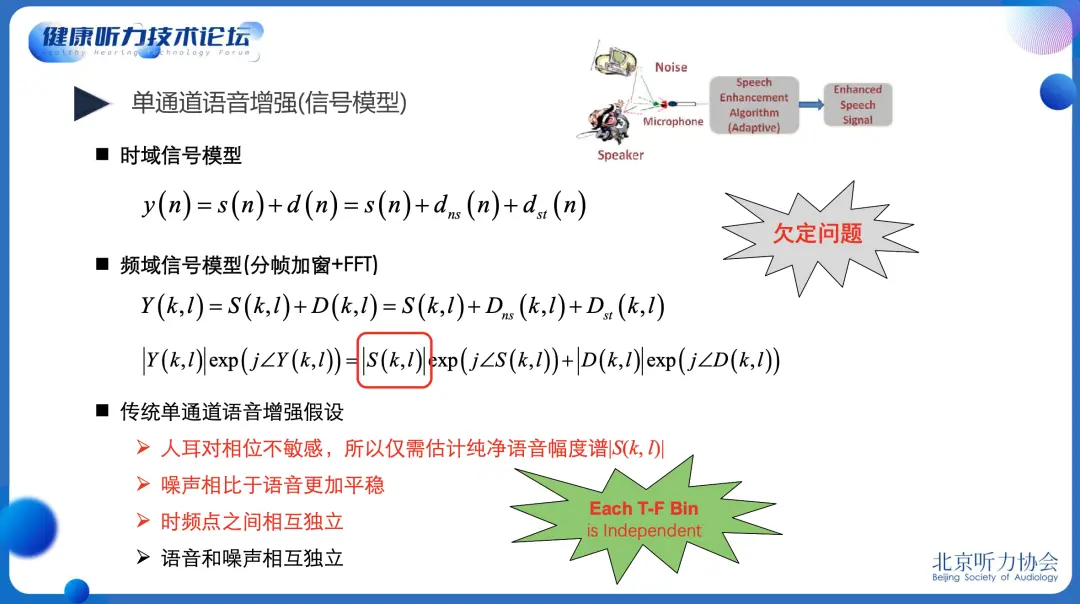
语音与噪声的差异,为从带噪语音中提取语音奠定了基础。传统语音增强方法通常有四个假设:
-
假设一、语音和噪声是统计独立的;
-
假设二、噪声相比于语音更加平稳;
-
假设三、时频点是统计独立的;
-
假设四、人耳对语音相位不敏感。
依据假设四,传统语音增强方法通常只估计纯净语音的幅度谱,并结合带噪信号的相位谱合成增强后语音时域信号;依据假设二,传统语音增强方法在纯噪声段估计噪声谱,或者采用最小统计特性的噪声谱估计方法及改进方法;依据假设三,传统语音增强方法通常采用各频点各自处理的方式。受限于硬件算力和当时人工智能技术水平,这四个假设在很长一段时间,起到了促进语音增强研究、发展和应用的积极作用。然而,随着人工智能技术的进步和芯片制程及其算力的不断提升,这些假设需要被打破才能实现语音增强性能的飞跃。
早期的深度学习语音增强方法率先打破了假设二和假设三的限制,但是依然保留了假设四,因而早期深度学习映射的目标依然是语音增强的增益因子、幅度谱或者对数谱。
随着深度学习语音增强网络建模能力的不断提升,假设四的限制也被打破,研究者发现深度学习映射纯净语音的实部和虚部,比映射幅度谱具有更优的性能,其本质是估计纯净语音幅度谱的同时也估计了纯净语音的相位谱。
相比于传统语音增强方法,深度学习语音增强方法在性能上具有绝对优势,不仅可有效抑制强非稳态噪声,而且可以显著降低语音失真,从而显著提升语音质量和可懂度。
低时延语音增强
绝大多数语音增强方法都采用分帧模式,且采用重叠相加法(OLA, OverLap-Add)重建增强后语音时域信号,其时延由帧长决定。过大的帧长,将导致处理时延过大;而过短的帧长,会导致频率分辨率过低,从而影响语音增强性能。
现有的语音增强方法为了保证性能,其时延大多在20ms以上,这限制了其诸多应用场景。例如,具有通透模式的TWS耳机、助听器产品以及扩声系统,都对 时延 提出了极高的要求,如果能将时延控制在10ms、5ms之内甚至实现无时延(Delayless),将可极大提升用户体验,拓宽语音增强的应用场景。
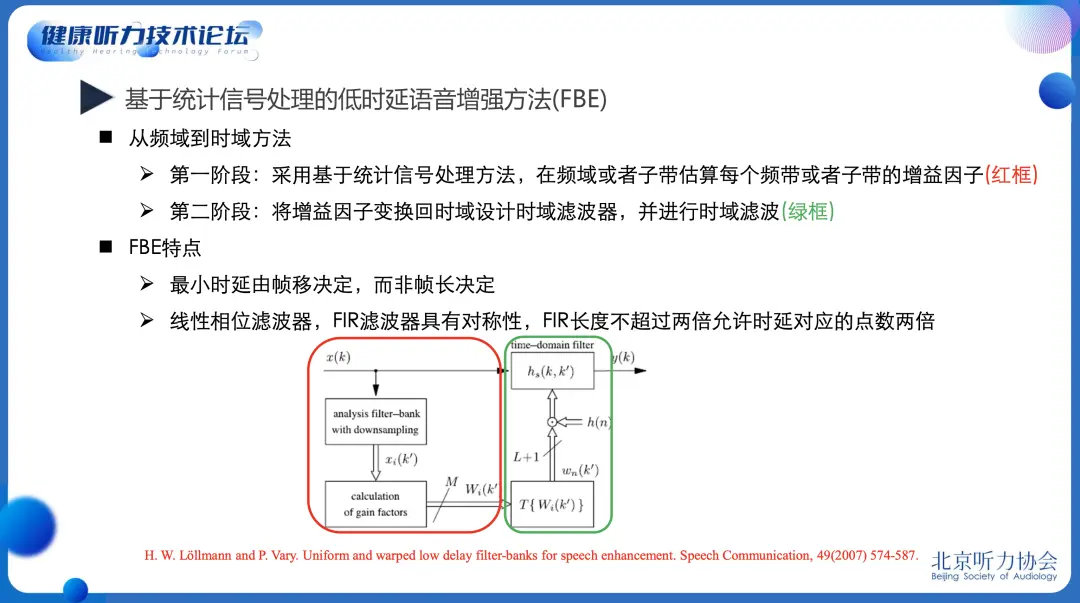
低时延语音增强研究甚少,仅有少量学者关注了这个问题,并进行了一些方法上的尝试。德国学者提出了一种称之为 滤波器组均衡 (FBE, Filter-Bank Equalizer)的方法,通过两步法实现低时延目标:
-
第一步先将带噪语音时域信号经过滤波器组,并采用传统语音增强方法估计每个子带的增益因子;
-
第二步根据增益因子设计时域滤波器,并根据时延要求对时域滤波器进行截断等处理,最后进行时域滤波实现语音增强。
FBE方法存在 两个问题:
-
首先是第一步采用了传统语音增强方法估算增益因子,因而该方法依然无法有效抑制非平稳态噪声,而且在低信噪比场景下语音失真较大;
-
其次是第二步通过频域增益因子设计时域滤波器的过程,在时频域上逼近频域特性,与优化语音增强性能不能直接画等号。
尽管研究表明,相比于时延较大的传统语音增强方法,FBE方法性能与之相当,并没有明显的退化;但是,和现有的深度学习语音增强方法相比,其性能相去甚远。
近期,我们提出了一种 基于深度学习的滤波器组均衡方法,即 Deep FBE,沿袭了FBE方法的两步法思想,并采用深度学习方法解决了FBE方法存在的问题。
Deep FBE方法第一步采用深度学习方法映射每个子带的增益因子,第二步采用深度学习方法隐式映射时域滤波器,并采用重叠保留法(OLS, OverLap-Save)重建增强后语音时域信号。
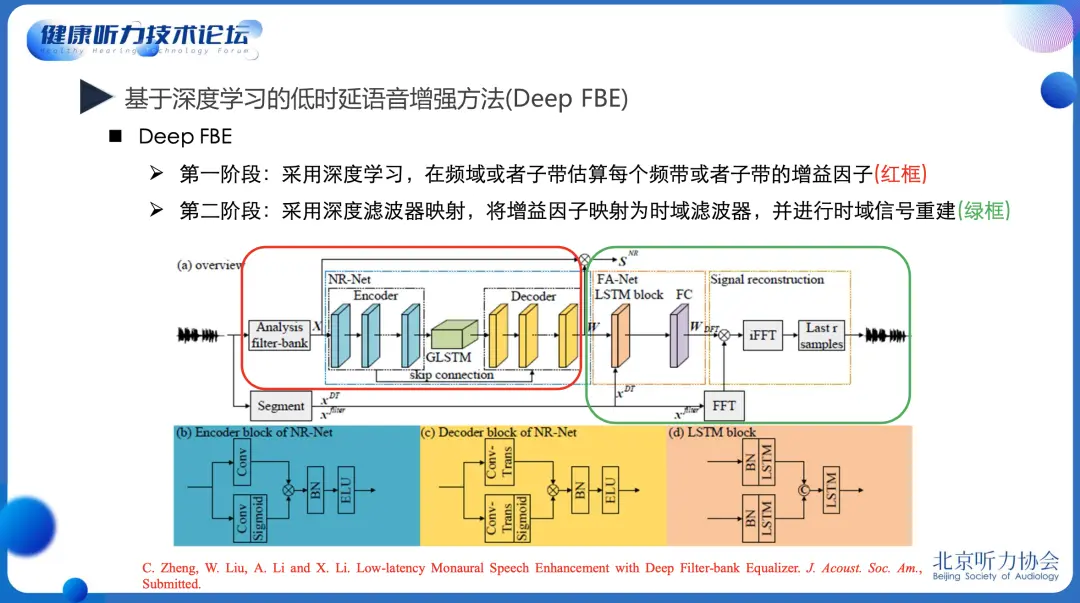
相比于FBE方法,我们提出的Deep FBE方法既能抑制非稳态噪声,也能显著降低信噪比较低的时频点的语音失真,有效地解决了FBE方法的两个问题,实现了 深度学习低时延语音增强 的目标。
展望
深度学习语音增强方法取得了卓越的性能,在一些较高功耗的高性能芯片上逐渐替代了传统语音增强方法。然而,深度学习语音增强方法的运算复杂度依然较高,所需的存储资源也更大。
将深度学习语音增强方法直接应用于要求极低功耗的产品,如助听器,还需要解决其运算复杂度和模型存储所需的资源问题。实现一种低时延低复杂度的深度学习语音增强方法,具有重要意义。
现场互动Q&A
Q:
请问深度学习降噪方法是否已经商业化,市面上有助听器使用深度学习的技术?
目前有商业应用了,不管是耳机这种低功耗产品,还是在PC上都有应用了。
Q:
辅听或助听设备的降噪如何平衡环境变化带来的目标改变的问题,例如在街道上鸣笛声就是需要被佩戴人员听到的,对人具有警示作用,但是在交谈或者室内鸣笛声就需要被降噪将掉?
警示音可以作为目标信号,不作为噪声抑制。
Q:
相位的非结构化特征,如何进行深度学习,有什么好办法或者注意点吗?
估计纯净语音的实部和虚部,隐含估计相位。
Q:
在增强后对原人声有损伤情况下,怎样优先保证可懂度允许一定噪声残留情况下进行降噪呢?有相关技巧吗?
语音增强采用MMSE的话,每个频带失真的权重是一样的,可根据听力损失情况,采用Frequency-weighted的MMSE。
Q:
实部+虚部与幅值+相位的训练形式会有区别吗?
没有采用幅度相位做输入的模式。我们修正相位,其实估计的是实部和虚部的残差,也就是补充第一步幅度估计的不足。
Q:
请问降噪后导致噪声不平稳,语音段会有残留噪声,这种情况有什么好的解决方法吗?
深度降噪残留噪声不平稳的问题较小,传统方法一般只能抑制稳态的部分,会导致残留噪声更不平稳。


扫码查看回放
健康听力技术论坛
往期回顾
第一季图文总结


随着TWS耳机的飞速发展、辅听产品技术的日新月异,以及美国FDA发布OTC助听器草案的政策驱动下,未来五年,助听产品和辅听产品的跨界与整合将成为主流趋势。
在行业变革时代背景下,北京听力协会主办了「健康听力技术论坛」,长期为大家提供发声的平台。论坛持续以每期两位嘉宾、不固定更新上线的形式长期举办。
期待声学领域、TWS领域、辅听及助听领域的专家、学者,以及产业供应链上中下游多方代表积极参与论坛并发表演讲。我们希望通过论坛的举办,搭建行业平台,促进产品变革,推动技术发展,为轻中度听损人士及健听人士提供更合适的听力保护及听力辅助方案,实现「全民健康听力」这一终极目标。

作者:郑成诗
编辑:Elan
排版:Elan



