
DataGripでINSERT文の生成を制御する方法 ─ カラム名を大文字化し、スキーマ名を削除する
INSERT文で一部のデータをエクスポートする必要がある場合、クエリを使って以下の手順で操作できます。
- エディタでSELECT文を実行してクエリを行う
- データグリッド右上の「Data Extractors」が SQL-Insert-Statements (groovy) になっていることを確認します。もし違う場合はメニューから変更します
- データグリッドで複数のレコードを選択し、Ctrl+Cで対応するデータからINSERT文を生成し、システムクリップボードにコピーします
- エディタやテキストエディタでCtrl+Vを押し、生成された文が要件に合っているか確認します
1. 要件
- 元のデータベースは大小文字を区別しないが、出力先データベースは大小文字を区別する。そのため、生成されるINSERT文のテーブル名とカラム名をすべて大文字にする必要がある
- INSERT文にはデータベース名やスキーマ名を含めないこと
初期設定ではこれらの要件を満たさないため、追加の処理が必要です。
2. 識別子(Identifiers)を大文字化
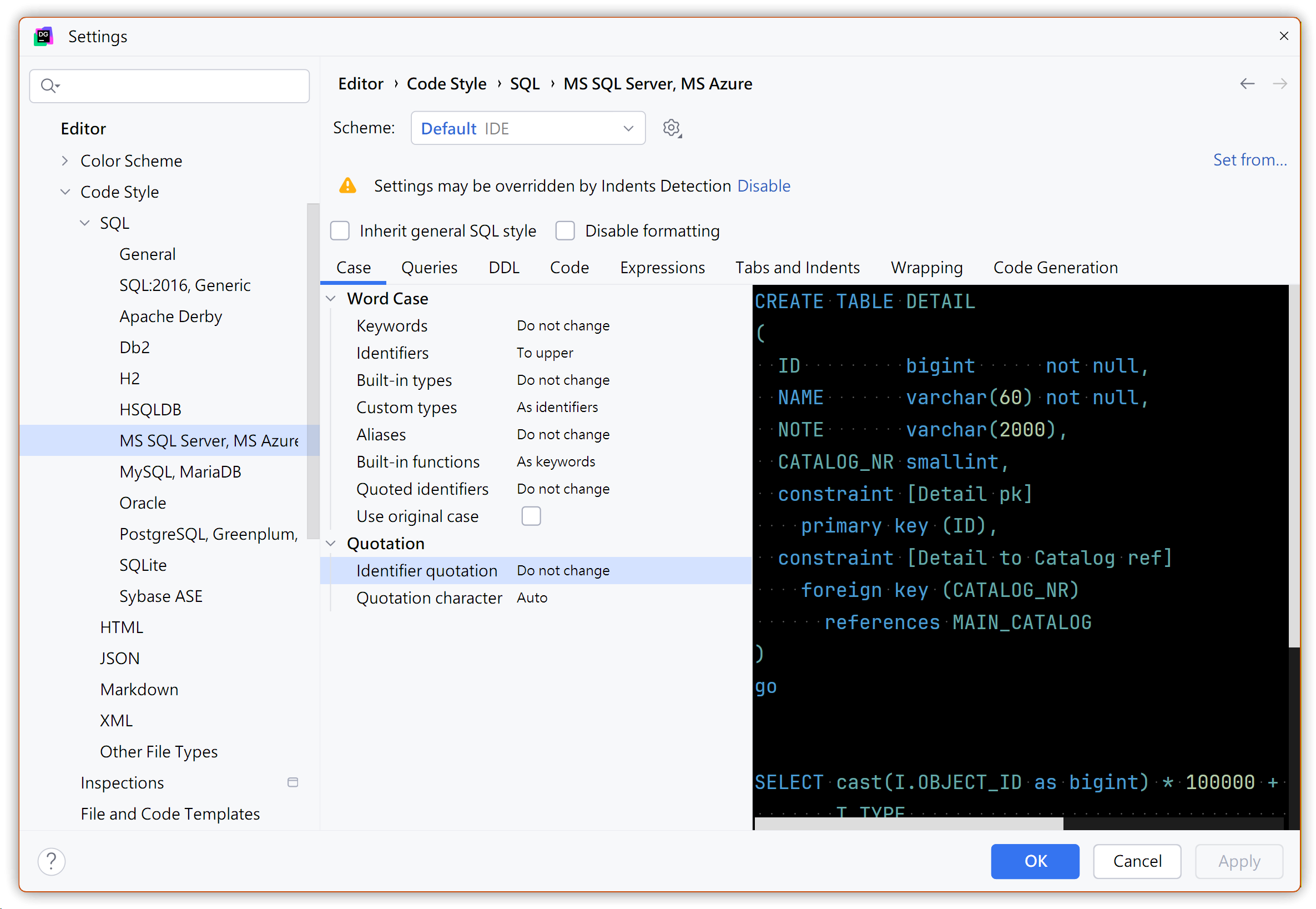
- 識別子の大文字設定:【Settings...】→【Editor】→【Code Style】→【SQL】→ 使用しているDBがMS SQL Serverのため、【MS SQL Server, MS Azure】を選択
- 【Case】タブを開き、【Word Case】内の【Identifiers】を【To upper】に設定
- 右側のプレビューでテーブル名とカラム名がすべて大文字になっていることを確認
3. データベース名とスキーマ名を削除
Data ExtractorsやSQL Generatorには、データベース名を出力しない設定はありません。しかし、INSERT文を生成するスクリプト SQL-Insert-Statements.sql.groovy を編集することで対応可能です。スクリプト言語はGroovyです。
3.1. 変更前にバックアップ
- データグリッド右上の「Data Extractors」メニュー → 最下部の【Go to Scripts Directory】
または、Side Panelの【File】→【Scratchers and Consoles】→【Extensions】→【Database Tools and SQL】→【data】→【extractors】 - SQL-Insert-Statements.sql.groovy を右クリック → Copy (Ctrl+C)、続けてCtrl+Vで貼り付け、新しいスクリプトファイルとして保存
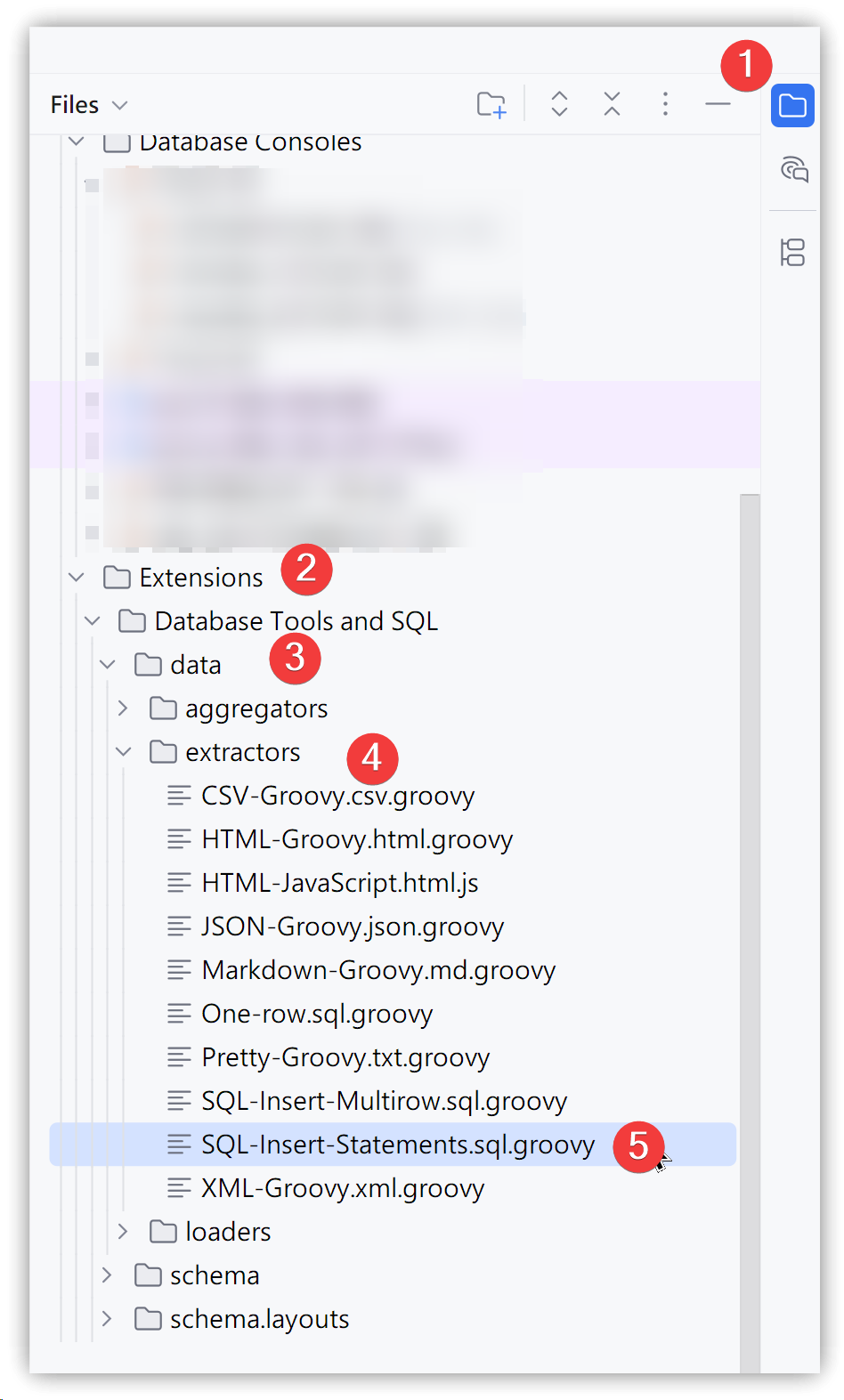
デフォルトスクリプトの場所
C:\Users\ユーザー名\AppData\Roaming\JetBrains\DataGrip2025.2\extensions\com.intellij.database\data\extractors\SQL-Insert-Statements.sql.groovy
3.2. スクリプト内容の修正
対象のスクリプトファイルを開き、データベース名やスキーマ名を出力するコードにコメントを追加します。
def record(columns, dataRow) {
OUT.append(KW_INSERT_INTO)
def table_name = TABLE.getName().toUpperCase()
if (TABLE == null) OUT.append("MY_TABLE")
else OUT/*.append(TABLE.getParent().getName()).append(".")*/.append(table_name)
OUT.append(" (")
columns.eachWithIndex { column, idx ->
def name = column.name().toUpperCase()
OUT.append(name).append(idx != columns.size() - 1 ? SEP : "")
}
修正後、DataGripを再起動し、Data Extractorsメニューで変更後の .groovy スクリプトを選択します。データグリッドでレコードを選択しCtrl+Cを押すと、修正後の仕様に沿ったINSERT文が生成されます。
4. 💡 関連リンク
✅ 解説記事 (繁体中文): https://jdev.tw/blog/8985/
✅ Explanation article (English)
✅ 解説記事 (日本語)