🆕 专题一 产品新功能/新版本
1. Podman Desktop 1.25 发布
本次版本带来了许多新功能和改进:
- 导航历史控制:通过工具栏按钮、快捷键或命令面板,支持前进和后退浏览应用历史。
- 高级网络创建选项:新增网络驱动(bridge、macvlan、ipvlan)、双栈 IPv6、内网、自定义 IP 范围、网关和 DNS 设置,全部可通过 UI 配置。
- 全新升级的 Kubernetes 功能:增强的 Kubernetes 功能默认开启,带来更稳定、更完整的 Kubernetes API 支持。
- Kube play 可取消:新增取消按钮,可随时停止长时间运行的 Kube Play,避免部署卡住浪费时间。
- Windows Podman 安装程序更新:Windows 版安装程序改为 MSI 格式,安装时不再需要管理员权限。
2. KEDA 2.19.0 发布
主要亮点:
- 推出全新 Kubernetes 资源扩展器
- 为 ClusterTriggerAuthentication 添加基于文件的身份验证支持
简介:
KEDA 为事件驱动型 Kubernetes 工作负载提供细粒度的自动扩缩容(包括从零扩缩容/从零扩容)。KEDA 充当 Kubernetes 指标服务器,并允许用户使用专用的 Kubernetes 自定义资源定义来定义自动扩缩容规则。KEDA 既可以在云端运行,也可以在边缘运行,与 Kubernetes 组件(如 Horizontal Pod Autoscaler)原生集成,并且没有外部依赖项。KEDA 是云原生计算基金会(CNCF)的毕业项目。
3. HAMi v2.8 重磅发布详解:标准化与生态完整性的双重演进
HAMi v2.8 重磅发布详解:标准化与生态完整性的双重演进
进展概览
- 标准化能力建设:新增对 Kubernetes DRA(Dynamic Resource Allocation)的支持,提供独立实现项目 HAMi-DRA,推动 HAMi 从"自定义设备调度逻辑"向 Kubernetes 原生标准接口演进。
- DRA 是 Kubernetes 社区正在推进的下一代设备资源声明与分配机制,旨在为 GPU/AI 加速器等设备提供 更标准化、可组合、可扩展的资源管理模型。DRA 通过引入 ResourceClaim 和 DeviceClass 等新 API,将设备资源的声明、分配和管理标准化,使设备资源管理更加灵活和可扩展。
- HAMi-DRA 是 HAMi 社区提供的 DRA 独立实现项目,采用 Mutating Webhook架构,自动将传统 GPU 资源请求转换为 DRA ResourceClaim。核心特性:
- 自动资源转换:自动将 nvidia.com/gpu、nvidia.com/gpumem、nvidia.com/gpucores等资源请求转换为 DRA ResourceClaim
- 设备选择支持:通过 Pod Annotation 支持按 UUID、设备类型等选择特定设备
- 指标监控:可选的 Monitor 组件,通过 Prometheus 暴露 GPU 资源使用指标
- CDI 支持:与 Container Device Interface 集成,提供标准化的设备注入方式
- 异构 GPU 生态扩展:天数智芯、沐曦 GPU、华为昇腾等国产芯片支持更新与增强,vLLM 兼容性问题修复,Kueue 集成完善。高可用与可靠性提升:引入 Leader 选举机制支持 Scheduler 高可用部署;新增 CDI 模式支持提升设备管理标准化;对齐 NVIDIA k8s-device-plugin v0.18.0 保持生态兼容。
- HAMi 生态体系成型:HAMi 从单一 repo 发展为包含 HAMi-DRA、mock-device-plugin、ascend-device-plugin、HAMi-WebUI 等子项目的完整生态体系。
4. Headlamp 0.40.0 发布
关键改进:
- 为集群添加图标和颜色配置。
- 允许为每个集群保存选定的命名空间。
- 添加可配置的键盘快捷键。
- 通过新增值和模板,为 Gateway API 添加 HTTPRoute 支持。
- 在服务视图中显示 a8r.io 服务元数据。
- 使集群内上下文名称可配置。
- 必要时尽量减少遮挡主要内容的活动。
5. VMware vSphere Kubernetes Service 3.6:让企业级 Kubernetes 更安全、更灵活、更易于操作
概览:VKS 3.6 的新特性
- 开放、可扩展的网络生态系统 —— 合作伙伴网络插件的支持路径允许容器网络接口 (CNI) 插件与 VKS 原生集成,同时保持在生命周期和支持范围内。
- 针对数据密集型和延迟敏感型工作负载进行性能调优 —— 声明式 TuneD 配置文件能够安全地对数据库和高吞吐量应用程序进行内核和 sysctl 调优,而无需进行不受支持的主机自定义。
- 支持 RHEL – Red Hat Enterprise Linux (RHEL) 节点的企业操作系统选择 ,包括混合操作系统集群。
Kubernetes 1.35,专为企业运维而打造
VKS 3.6 增加了对 Kubernetes 版本 1.35 的支持。与之前的版本一样,博通为每个 Kubernetes 版本提供 24 个月的扩展支持,并且版本支持存在重叠。这使得大型组织能够根据自身进度推进团队发展,而无需强制进行全集群升级或缩短维护窗口。
更平稳的升级和更安全的第二天运营
Kubernetes 平台在升级过程中最容易承受压力。实际上,升级失败很少是由 Kubernetes 本身引起的,而是由配置和集成导致的。策略引擎、准入 Webhook 以及安全或管理工具可能会无意中阻塞生命周期操作。
VKS 3.6 在之前引入的 PodDisruptionBudget 预检查的基础上,扩展了升级准备检查功能,可在升级开始前发现常见的配置冲突。平台团队无需在升级过程中才发现障碍,即可在维护窗口之前识别并修复问题,从而减少升级失败和计划外中断。这些检查持续运行,通过 SystemCheckSucceeded 条件而非仅在升级执行期间暴露升级风险。
性能密集型和数据密集型工作负载
在 Kubernetes 上运行数据库和其他有状态平台通常需要进行内核和节点级别的调优,这超出了默认设置。
在许多环境中,团队依赖手动节点变更或定制镜像来满足这些需求。而在托管式 Kubernetes 模型中,这些变更通常需要以声明式的方式表达(例如通过已批准的配置机制、特权 DaemonSet 或标准化镜像),以确保在升级和节点替换后仍能保持持久性。
VKS 3.6 引入了对 TuneD 配置文件的支持,允许开发人员通过 Kubernetes 资源以声明方式调整 Linux 内核(包括 sysctl 和 sysfs 参数)。配置文件可以针对特定的节点池,从而在同一集群内实现针对特定工作负载的优化。
这使得常见场景变得简单易懂且易于支持,例如:
- 优化节点以实现高吞吐量网络
- 数据库和缓存系统的内存行为调优
- 针对延迟敏感型工作负载调整内核设置
安全、合规和治理
Kubernetes 组件的扩展配置功能使平台团队能够根据每个工作负载和环境定制合规性策略。团队可以根据需要应用更严格的控制措施,在适当情况下放宽控制,并随着时间的推移不断改进配置,而无需重建集群来更改策略。
此版本还简化了 AppArmor 配置文件的管理。管理员现在可以将 AppArmor 配置文件定义为自定义资源,并使其在集群的所有工作节点或特定节点池中自动加载和同步。这样,每个工作负载都可以配置所需的 AppArmor 配置文件,而无需进行复杂的节点级配置。
VKS 3.6 还提升了运维自主性。工作负载集群所有者现在无需 vCenter 凭据即可生成 VKS 支持包,从而无需在故障排除期间获得更高的基础架构访问权限。这减少了 Kubernetes 团队和基础架构团队之间的摩擦,同时保持了最小权限安全原则。
平台用户体验和生态系统赋能
- 网络:平台团队可以使用经合作伙伴验证的网络插件,同时仍能遵守正常的生命周期、升级和支持流程。
- 防火墙:VKS 3.6 引入了集中式、API 驱动的节点级防火墙规则管理,支持所有操作系统。平台团队现在可以通过集群配置为 HostPorts 和 NodePort 服务打开所需的端口,而无需依赖在每个节点上运行的特权初始化容器或 DaemonSet。通过将防火墙控制从单个工作负载转移到集群级别,团队可以简化配置、提高可审计性并降低与特权组件相关的安全风险。
- 操作系统:除 Photon OS 5、Ubuntu 22.04 和 24.04 以及 Windows Server 2022 之外,新增 Red Hat Enterprise Linux (RHEL) 9 的支持。
拓展阅读
Eliminating the OS Barrier: vSphere Kubernetes Service 3.6 Now Supports RHEL 9
6. Flux 2.8 正式发布
Flux v2.8 支持 Helm v4,引入了服务端应用(server-side apply)和增强的健康检查功能。
本次发布还带来了 Flux 控制器的多项新特性:
- 缩短 Flux 管理应用的平均恢复时间
- 基于 CEL 表达式对 Helm 管理对象进行就绪度评估
- ArtifactGenerator 支持提取并修改 Helm Chart
- 支持从 Flux 通知直接对 Pull Request 评论
- kustomize-controller 支持自定义 SSA 应用阶段,控制资源应用顺序
- 自动从仓库所有者获取 GitHub App 安装 ID
- 支持 Cosign v3 验证 OCI 制品和容器镜像
- 生态系统方面,Flux Operator 发布了新版本,带来专用的 Flux Web UI 和预览环境新供应商。
- Flux 是一款用于保持 Kubernetes 集群与配置源(如 Git 存储库和 OCI 工件)同步的工具,并在有新代码要部署时自动更新配置。
7. Volcano v1.14 重磅发布!迈向 AI 统一调度新纪元
Volcano v1.14 重磅发布!迈向 AI 统一调度新纪元
v1.14.0 版本带来以下重磅更新:
统一调度平台架构
- 多调度器架构升级:动态节点分片机制 (Alpha)
- AI Agent 工作负载极速调度能力 (Alpha)
网络拓扑感知调度增强
- HyperNode 级 Binpack 策略
- SubGroup 级精细化拓扑感知
- PodGroup 与 SubGroup 多层级 Gang Scheduling
- Volcano Job 分区支持
混部能力增强
- 全面支持通用操作系统(Ubuntu、CentOS 等)
- Cgroup V2 全面适配
- CPU 动态压制
- 基于 Cgroup V2 的内存 QoS
- 支持 CPU Burst
- 支持 systemd driver 自动检测
异构硬件支持
- 昇腾 vNPU 调度(支持 MindCluster 和 HAMi 模式)
Volcano Global 增强
- HyperJob 多集群作业自动拆分
- 数据感知多集群调度
Volcano Dashboard 增强
- PodGroup 全景可视化
- Job / Queue 全生命周期管理
- Volcano 是一个 Kubernetes 原生批处理调度系统,它扩展并增强了标准 kube-scheduler 的功能。它提供了一套全面的功能,专门用于管理和优化各种批处理和弹性工作负载,包括人工智能 (AI) / 机器学习 (ML) / 深度学习 (DL)、生物信息学 / 基因组学以及其他“大数据”应用。
📰 专题二 新闻与访谈
1. CNCF Project Velocity 在 2025 年揭示了云原生未来的哪些方面
What CNCF Project Velocity in 2025 Reveals About Cloud Native’s Future
1/1/2025 - 1/1/2026: CNCF Projects Velocity
*注:使用气泡图来显示三个数据轴:提交数、作者数和评论/拉取请求数,并在对数-对数图上绘制以显示大尺度数据。
- 气泡的面积与作者数量成正比。
- y 轴表示拉取请求和问题的总数。
- x 轴代表提交次数。
清晰图表见 CNCF Projects 1/1/2025 - 1/1/2026
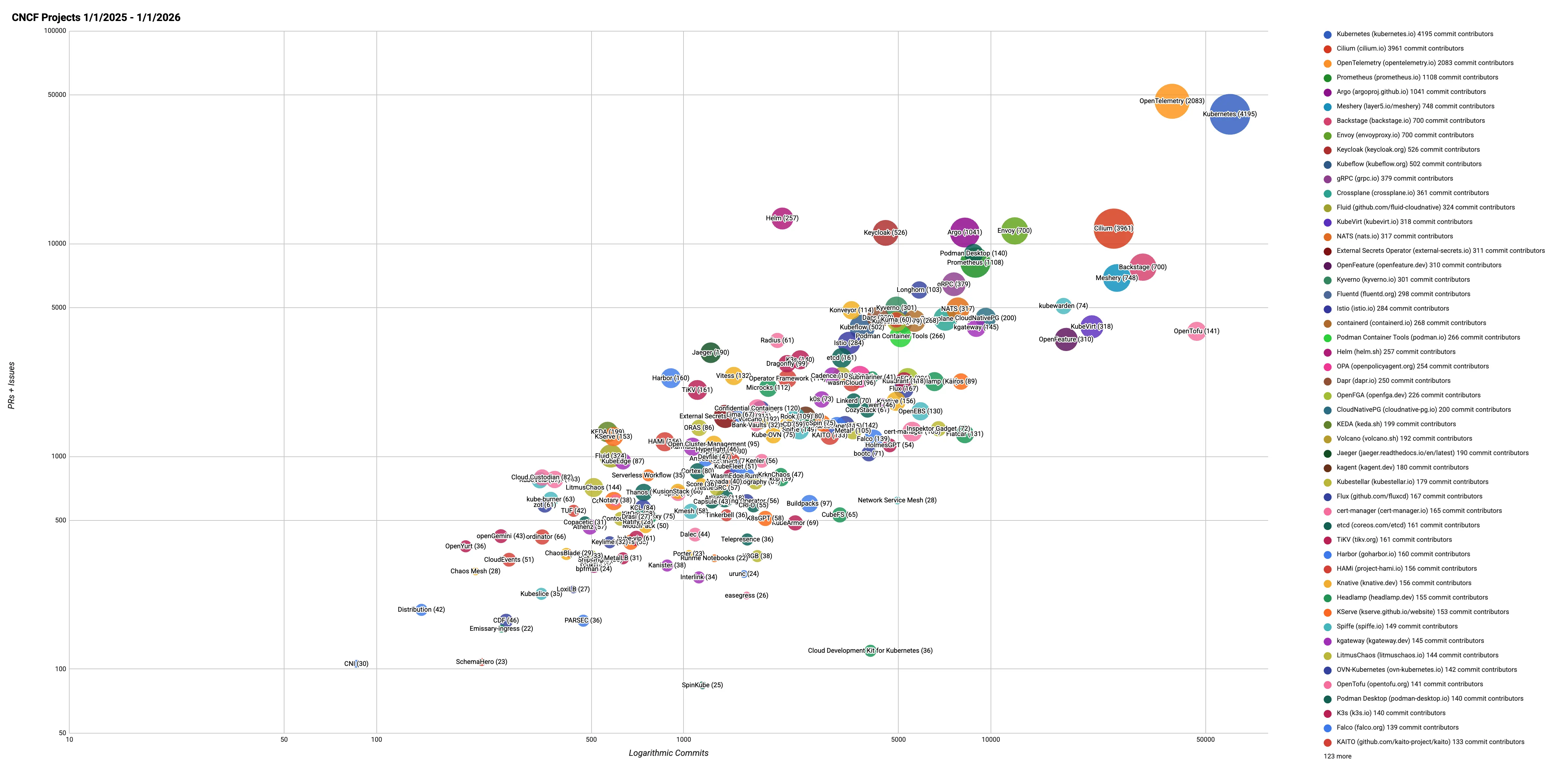
项目速度:关键要点
以下是 2025 年数据中一些突出的特点:
- Kubernetes 凭借其庞大的贡献者群体,继续引领着整个生态系统。这种持续增长的速度巩固了其作为企业现代基础设施基石的地位。随着 Kubernetes 发展成为人工智能背后的关键操作系统,它将继续巩固自身的成功。
- 自 2024 年以来, Backstage 的贡献量已增长了一倍以上。凭借其对开发者体验的专注,Backstage 已成为领先的开源身份提供商 (IDP),并在平台工程的兴起中发挥着基础性作用。随着越来越多的组织将内部平台作为提升开发者效率和一致性的优先考虑因素,Backstage 正逐渐成为首选解决方案。
- OpenTelemetry 发展势头强劲,提交次数增长了 39%,贡献者人数在短短一年内从 1301 人增长到 1756 人,增幅达 35%。如今,作为 CNCF 第二大项目,OpenTelemetry 显然已成为团队构建、运行和扩展系统不可或缺的关键要素。
2. MinIO 仓库已停止维护
该仓库于 2026.2.13 被归档,目前是只读状态。
其他选择:
- AIStor Free — 功能齐全的独立版本,供社区使用(免费许可)
- AIStor Enterprise — 分布式版本,提供商业支持
💬 专题三 讨论与分享
1. cgroup v1 CPU 份额到 v2 CPU 权重的新转换
New Conversion from cgroup v1 CPU Shares to v2 CPU Weight
背景与问题
cgroup v1 中 CPU 份额的定义很简单,只需以 millicpu 的形式分配容器的 CPU 请求即可。例如,请求 1 个 CPU (1024m) 的容器将获得 (cpu.shares = 1024)。
后来,cgroup v1 开始被其继任者 cgroup v2 所取代。在 cgroup v2 中,CPU 份额(范围从 2 到 262144,或从 2¹ 到 2¹⁸)的概念被 CPU 权重(范围从 [1, 10000],或从 10⁰ 到 10⁴)所取代。
随着向 cgroup v2 的过渡,KEP-2254 引入了一个转换公式,用于将 cgroup v1 的 CPU 份额映射到 cgroup v2 的 CPU 权重。该转换公式定义为: cpu.weight = (1 + ((cpu.shares - 2) * 9999) / 262142)。该公式将 [2¹, 2¹⁸] 到 [10⁰, 10⁴] 的值线性映射。线性映射简单,但是会带来一些重大问题,并影响性能和配置粒度:
- 降低对非 Kubernetes 工作负载的优先级
- 粒度过大,难以管理
新转换公式
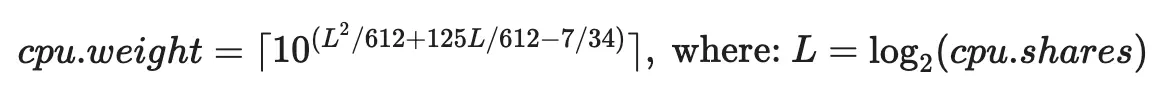
- 更好的优先级排序:请求 1 个 CPU (1024m) 的容器现在将获得 cpu.weight = 102 。该值接近 cgroup v2 的默认值 100。这恢复了 Kubernetes 工作负载和系统进程之间预期的优先级关系。
- 粒度提高:请求 100m CPU 的容器将获得 cpu.weight = 17 (参见此处)。这可以实现容器内更细粒度的资源分配。
2. OpenClaw 在严肃场景下的实践:迁移 Ingress NGINX
OpenClaw 在严肃场景下的实践:迁移 Ingress NGINX
具体见原文。
Sealos API 网关选型:为何最终选择 Higress (基于 Envoy) 支撑数千租户与海量路由
3. 节点就绪控制器简介
Introducing Node Readiness Controller
背景
对于具有复杂引导要求的集群而言,Kubernetes 核心节点的“就绪”状态通常不足以满足需求。运维人员经常需要确保特定的 DaemonSet 或本地服务运行正常,才能将节点加入调度池。
节点就绪控制器弥补了这一不足,它允许运维人员定义针对特定节点组的自定义调度门控。这使得您可以跨异构集群强制执行不同的就绪要求,例如,确保配备 GPU 的节点只有在专用驱动程序经过验证后才能接受 Pod,而通用节点则遵循标准路径。
优势如下:
- 自定义就绪状态定义:定义您的特定平台的就绪状态意味着什么。
- 自动化污点管理:控制器根据条件状态自动应用或移除节点污点,防止 Pod 部署在未就绪的基础设施上。
- 声明式节点引导:可靠地管理多步骤节点初始化,并清晰地观察引导过程。
执行模式
- 持续执行:在节点的整个生命周期内主动维护就绪保证。如果关键依赖项(例如设备驱动程序)之后发生故障,则立即对节点进行标记,以防止新的调度。
- 仅 Bootstrap 强制执行:适用于一次性初始化步骤,例如预拉取大型镜像或硬件配置。一旦满足条件,控制器就会将引导过程标记为完成,并停止监控该节点的该特定规则。
状况报告
- 节点问题检测器 (NPD):使用现有的 NPD 设置和自定义脚本来报告节点健康状况。
- 就绪状态报告器:项目提供的一个轻量级代理,可以部署以定期检查本地 HTTP 端点并相应地修补节点状态。
4. 案例研究:VKS 升级指南——平衡基础设施限制与应用实际情况
Case Study: Navigating VKS Upgrades – Balancing Infrastructure Constraints and Application Reality
升级复杂性
在现代企业平台中,升级远不止 Kubernetes 版本号的变更那么简单。它涉及以下方面的复杂相互作用:
- 管理平面(主管/平台服务)
- 平台层(VMware Kubernetes 服务 – VKS)
- 工作负载集群
- 具有不同程度弹性和状态的应用程序
方案一:顺序就地升级
就地升级模型逐层升级现有组件,修改运行中的基础架构。
流程:
- 主管集群:1.29 → 1.30
- VKS 服务:已更新以支持更新的 Kubernetes 版本(例如,v3.1 → v3.5)
- 工作负载集群:1.30 → 1.31 → 1.32 → 1.33
优势:
- 利用现有基础设施:无需大量备用容量。
- 熟悉的操作模式:它符合标准的补丁工作流程。
- 降低资源占用:在整个过程中保持精简的资源利用率。
挑战:
- 缺乏适当的 PodDisruptionBudgets (PDB) 的有状态工作负载。
- 启动时间长或需要手动初始化步骤的传统应用程序。
- API 对已弃用的 Kubernetes 功能存在硬编码依赖。
当应用程序不具备完全的滚动安全性时,每一次版本升级都会变成高风险事件。即使博通支持平台升级,应用层也可能会强制执行更慢的升级速度、更长的冻结窗口期或需要人工干预。
方案二:并行/蓝绿升级
并行(蓝绿)升级涉及在现有环境(蓝色)旁边创建一个目标版本的新环境(绿色),迁移流量,然后停用旧环境。
流程:
- 部署目标版本的新版 Supervisor 和 VKS。
- 创建目标 Kubernetes 版本的新工作负载集群。
- 通过 CI/CD 逐步迁移应用程序。
- 拆除旧环境。
使用要求:
- 高级流量管理(负载均衡器):需要一个功能强大的负载均衡器 (LB) 来处理蓝绿集群之间的流量切换。这样你就可以精细地分配流量(例如,先分配 5%,再分配 50%,最后分配 100%),并在检测到问题时立即切换或回滚。
- 弹性可扩展性(自动扩缩器):将流量转移到新的绿色集群后,负载几乎会立即飙升。手动扩展速度太慢。需要支持:
- 水平 Pod 自动扩缩容 (HPA):根据 CPU/内存/自定义指标快速增加 Pod 数量。
- 集群自动扩缩容:随着 HPA 调度更多 Pod,动态地配置底层工作节点。
- 强大的 CI/CD 工具:需要一个现代化的持续交付工具链(例如 ArgoCD、Flux、Harness)来定位新的集群端点并同步配置。尝试在两个动态环境中手动执行
kubectl apply manifests命令很容易导致配置漂移和系统宕机。 - 有状态应用程序的策略:无状态应用易于迁移;有状态应用则更具挑战性。您必须规划好:
- 复制:该应用是否支持 active-active 数据库复制?
- 备份/恢复:您会使用 Velero 等工具来迁移持久卷 (PV) 吗?
- 停机时间:您是否需要短暂的维护窗口期,将存储设备从蓝色存储设备拆卸下来并安装到绿色存储设备上?
优势:
- 压缩日历时间:一次性从版本 A 跳转到版本 Z。
- 避免链式跳转:消除中间版本错误的风险。
- 简化回滚:回滚只需将流量转移回“蓝色”集群即可。
- 稳定生产:“蓝色”环境保持不变,同时验证“绿色”环境。
决策清单
- 平台与规模
- 是否需要跨越两个以上的 Kubernetes 小版本?
- 是否管理着庞大的集群,而顺序升级需要数年时间?
- 如果答案是肯定的 → 倾向于蓝绿政策
- 应用程序准备情况
- 所有关键应用程序都能容忍滚动重启吗?
- 应用程序是否具有定义明确的 PDB 和健康探针?
- 已弃用的 API 是否已得到修复?
- 如果没有 → 蓝绿平衡策略(隔离风险)
- 运营与治理
- 维护窗口期是否不频繁?
- 变更审批流程繁琐吗?
- 如果答案是肯定的 → 倾向于蓝绿策略(减少变更窗口)
- 基础设施限制
- 是否有临时增加的产能?
- 云或硬件扩展能否获得批准?
- 如果没有 → 顺序方式可能更合适
VMware 会提供专业服务加速升级
- 评估和依赖关系图
- 战略选择和路线图设计
- 自动化和工具
- 运营赋能
拓展阅读
Mastering Application Migration to VKS: Patterns and Best Practices
📄 专题四报告查看与分析
1. [CNCF] Annual Cloud Native Survey:The infrastructure of AI’s future
The CNCF Annual Cloud Native Survey: The Infrastructure of AI’s Future
Kubernetes 作为 AI 平台
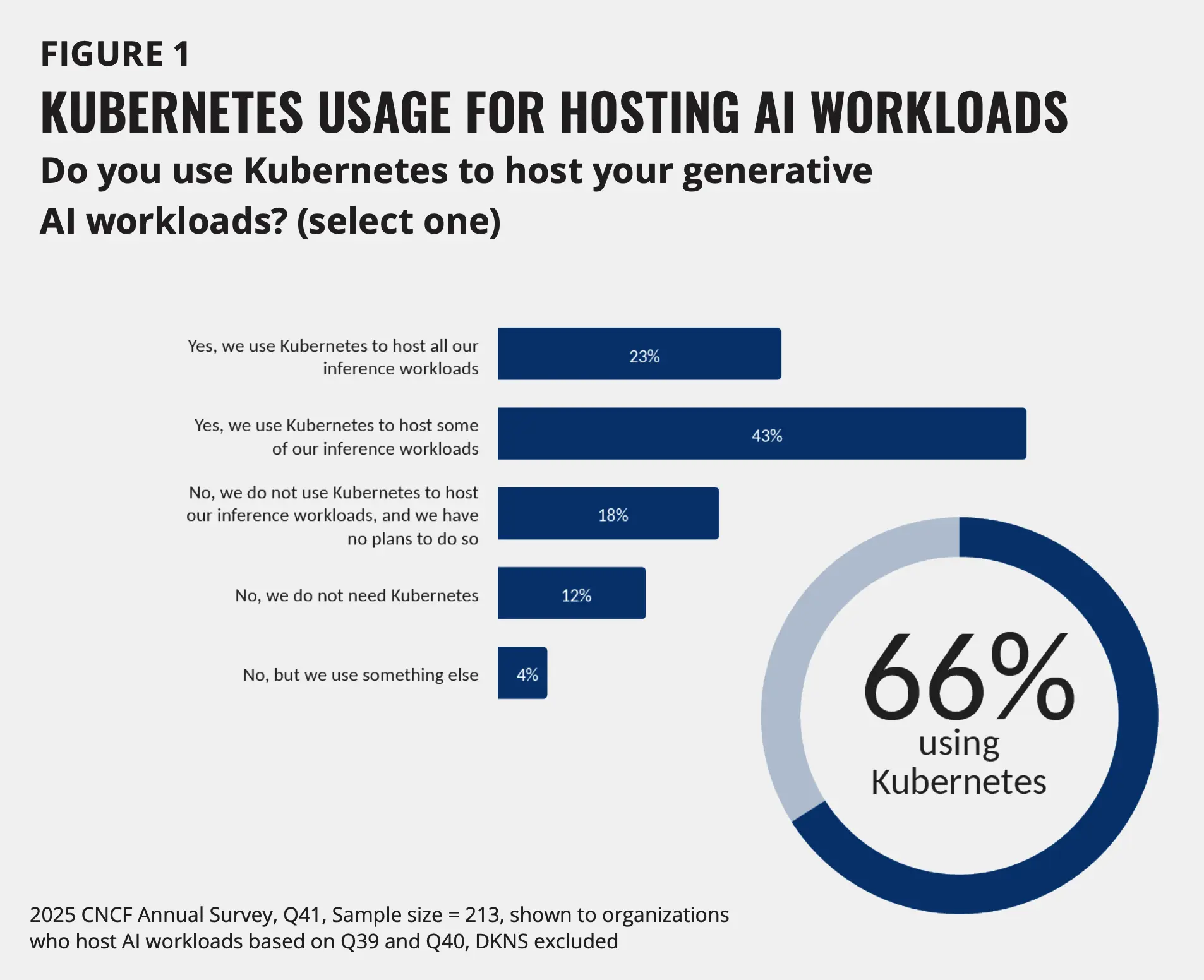
Kubernetes 已成为生产级 AI 的事实标准编排层。然而,“完全采用”(23%)与“部分采用”(43%)之间的差距表明,各机构正采取一种审慎的、基础设施优先的策略。将 AI 工作负载迁移到 Kubernetes 不仅仅是容器化那么简单。机构必须解决一系列独特的需求。
云原生基础设施的成熟度
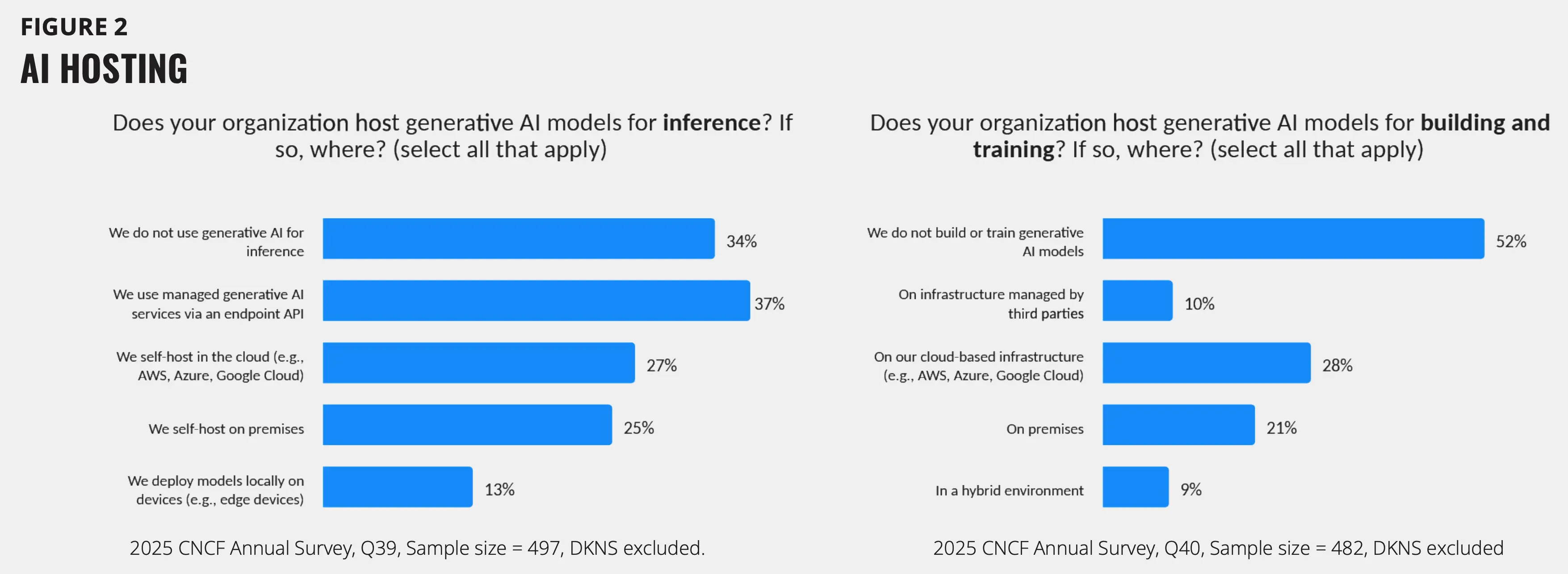
大多数机构是 AI 模型的消费者,而非生产者。52% 的受访机构并不构建或训练 AI 模型;即使是那些进行训练的机构,通常也不是从零开始,而是基于自有数据进行微调。机构可能会对低负载任务使用基于 CPU 的推理,而将 GPU 资源留给对延迟敏感的应用。
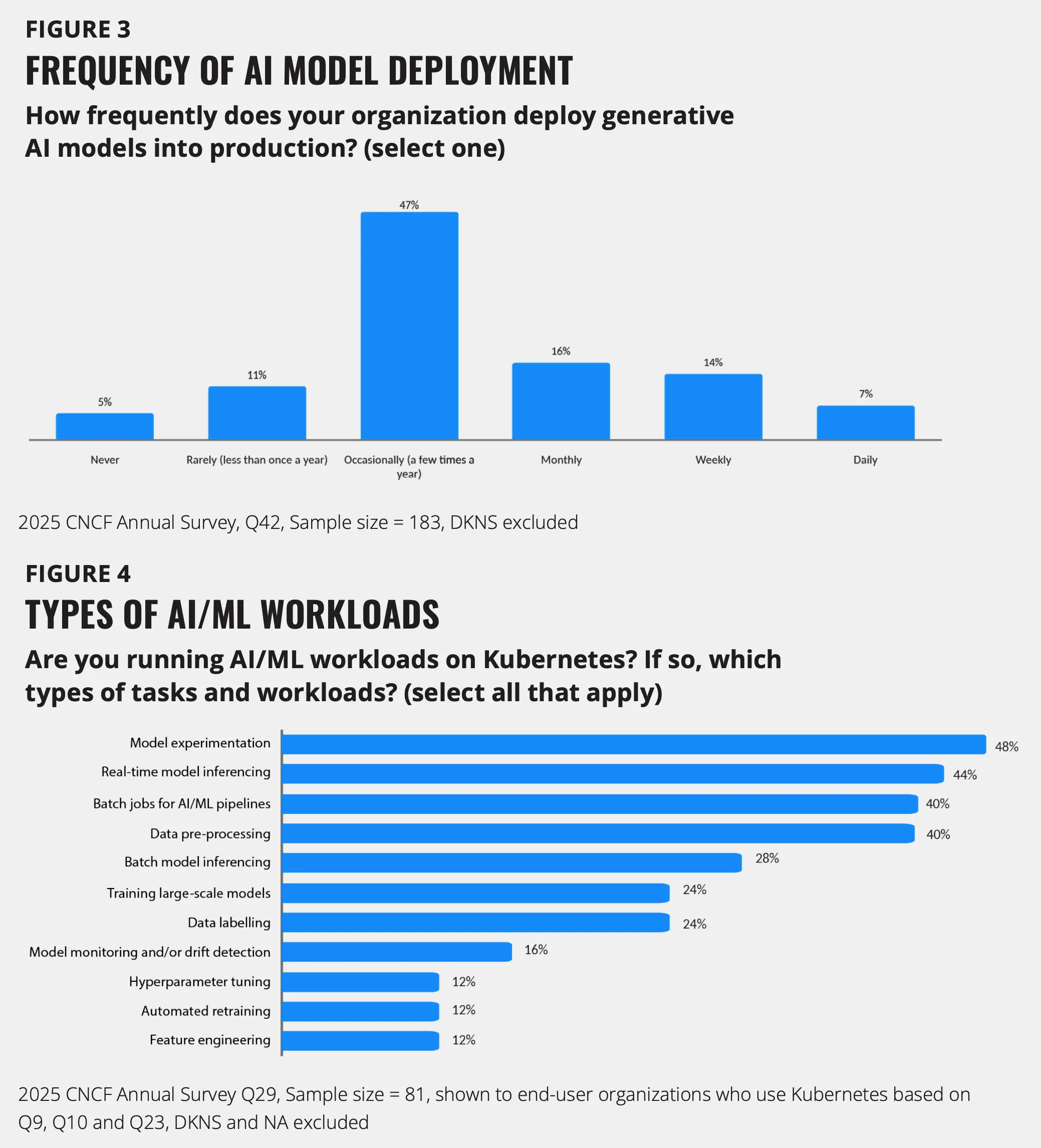
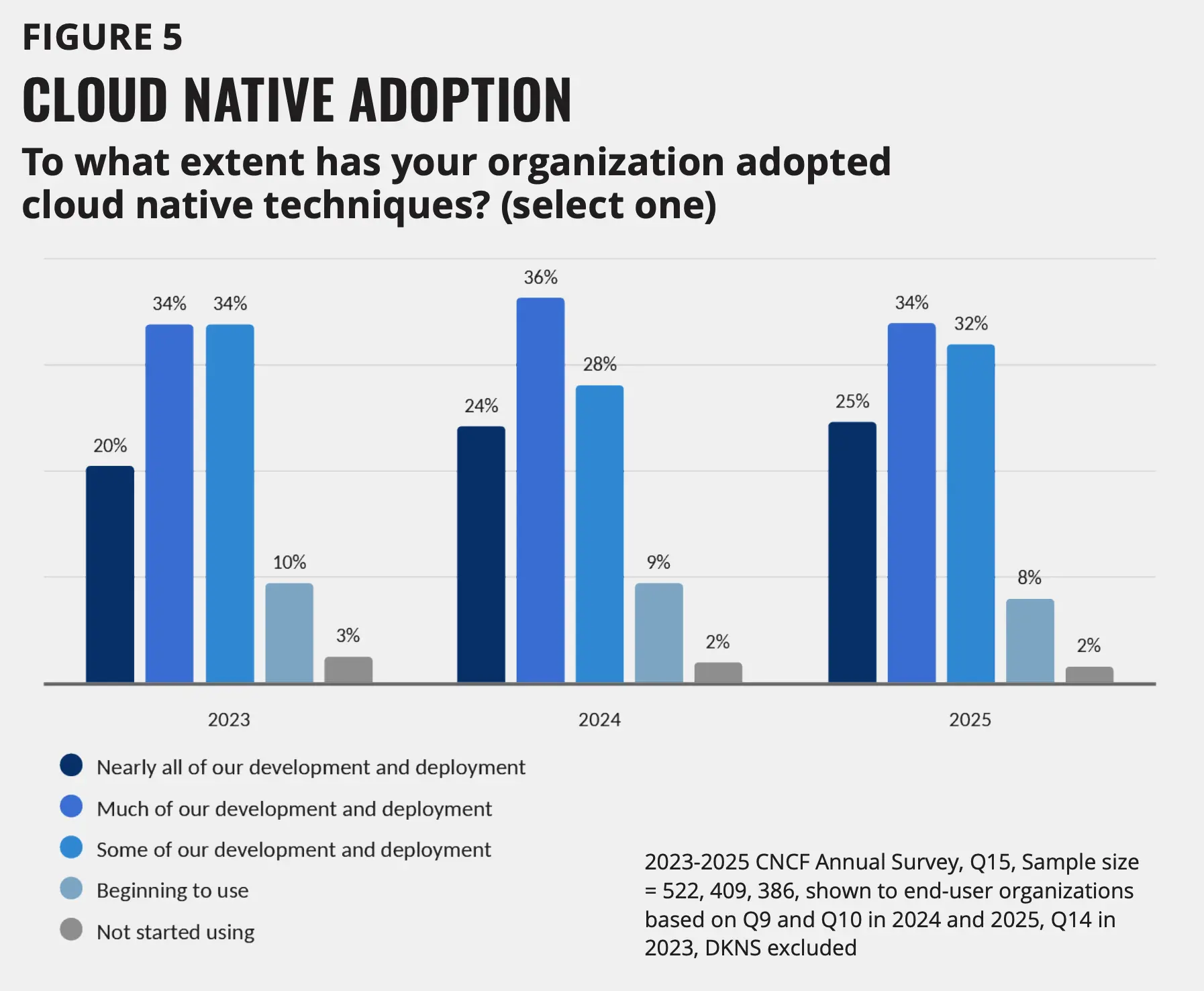
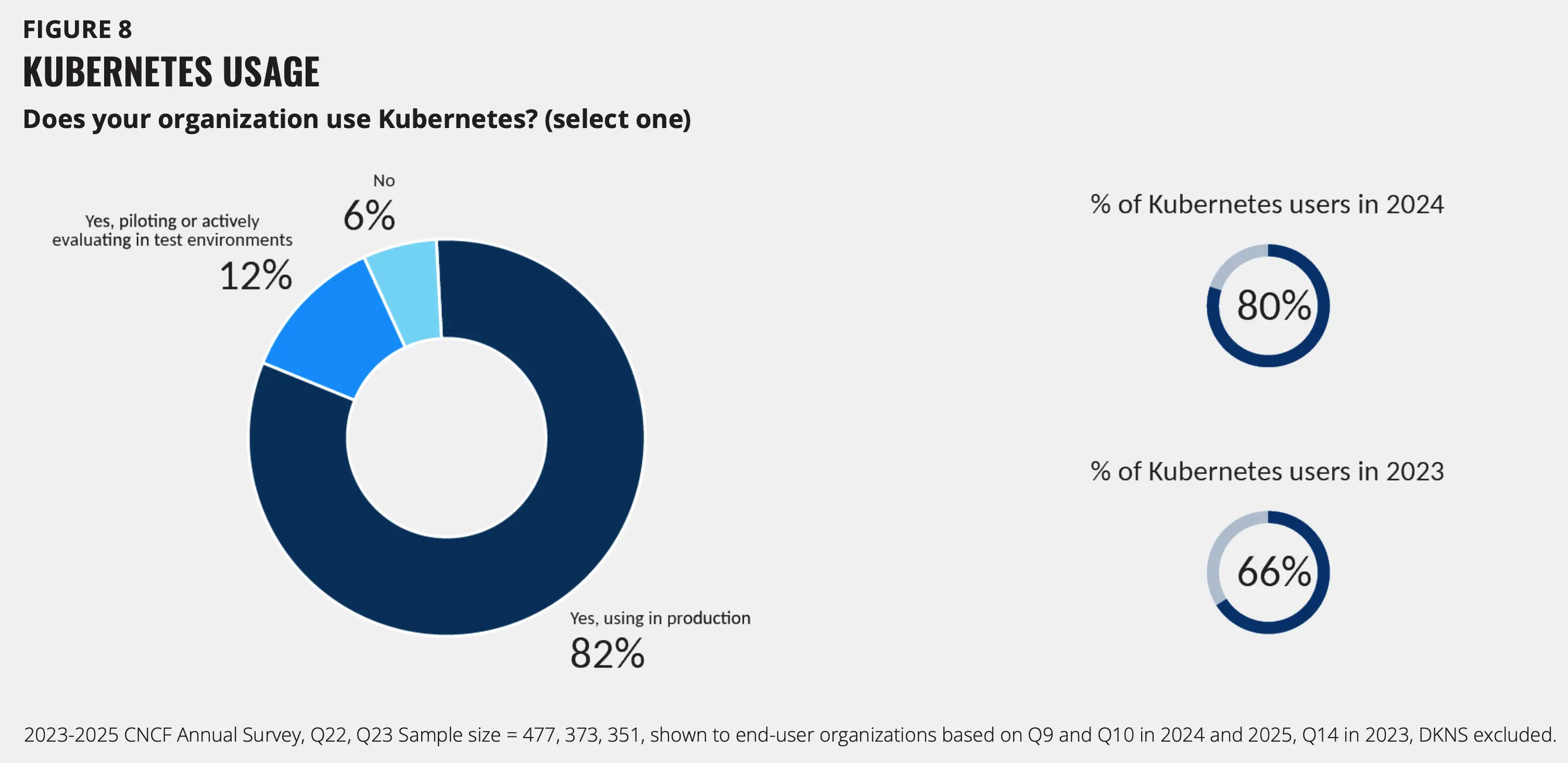
98% 的机构现在至少在某些能力上使用云原生技术,早期采用阶段的机构降至仅 8%。生产环境中的容器使用率从 41% 增加到 56%,而 Kubernetes 巩固了其作为事实标准编排平台的地位,在 82% 的容器化运行环境中运行。
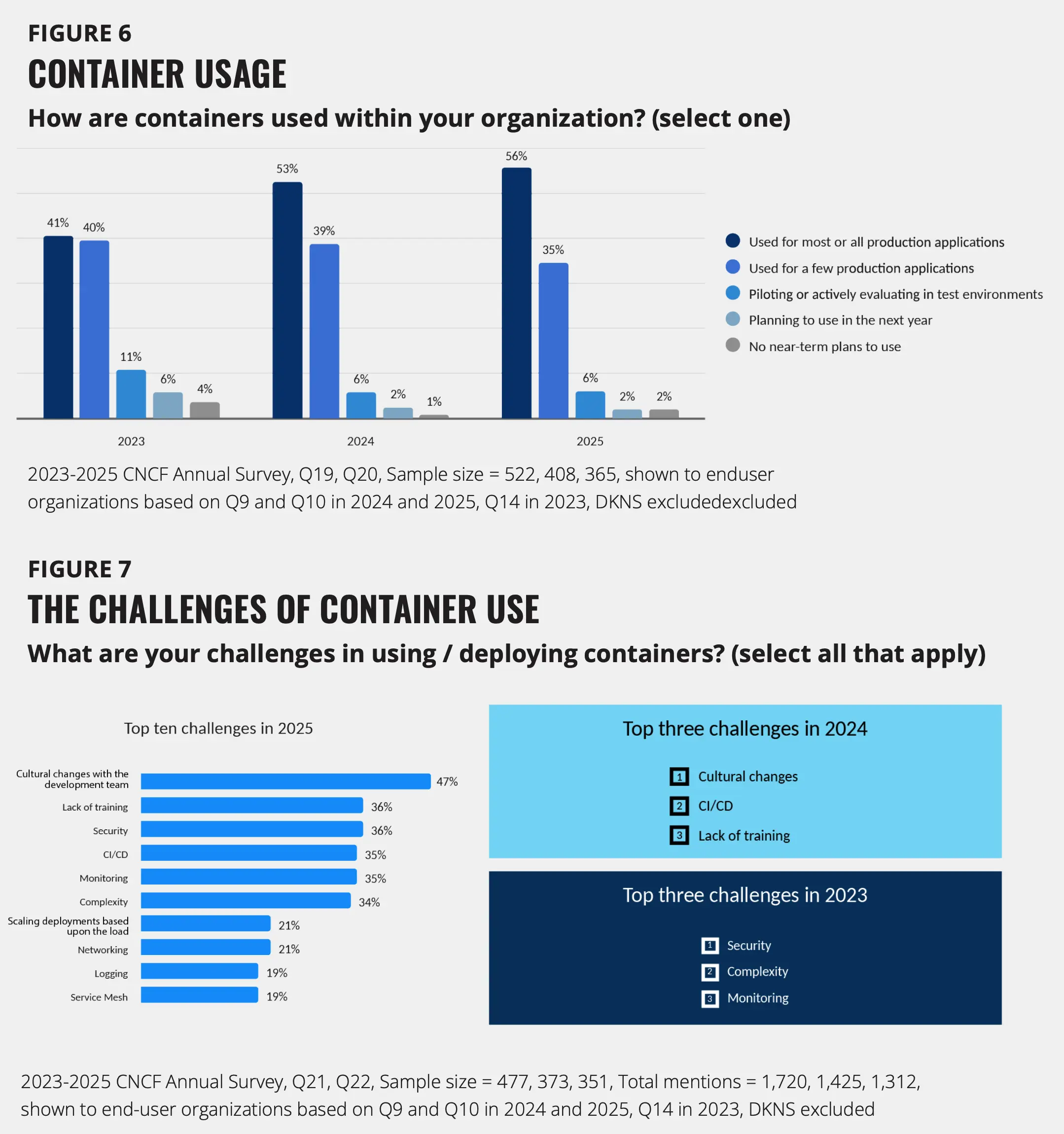
在大多数或全部生产应用中使用容器的比例从 2023 年的 41% 增长到了 2025 年的 56%。仍在试点容器的机构比例从 11% 下降至仅 6%。2025 年面临的首要挑战是“开发团队的文化变革”(47%),其次是缺乏培训(36%)和安全性(36%)。
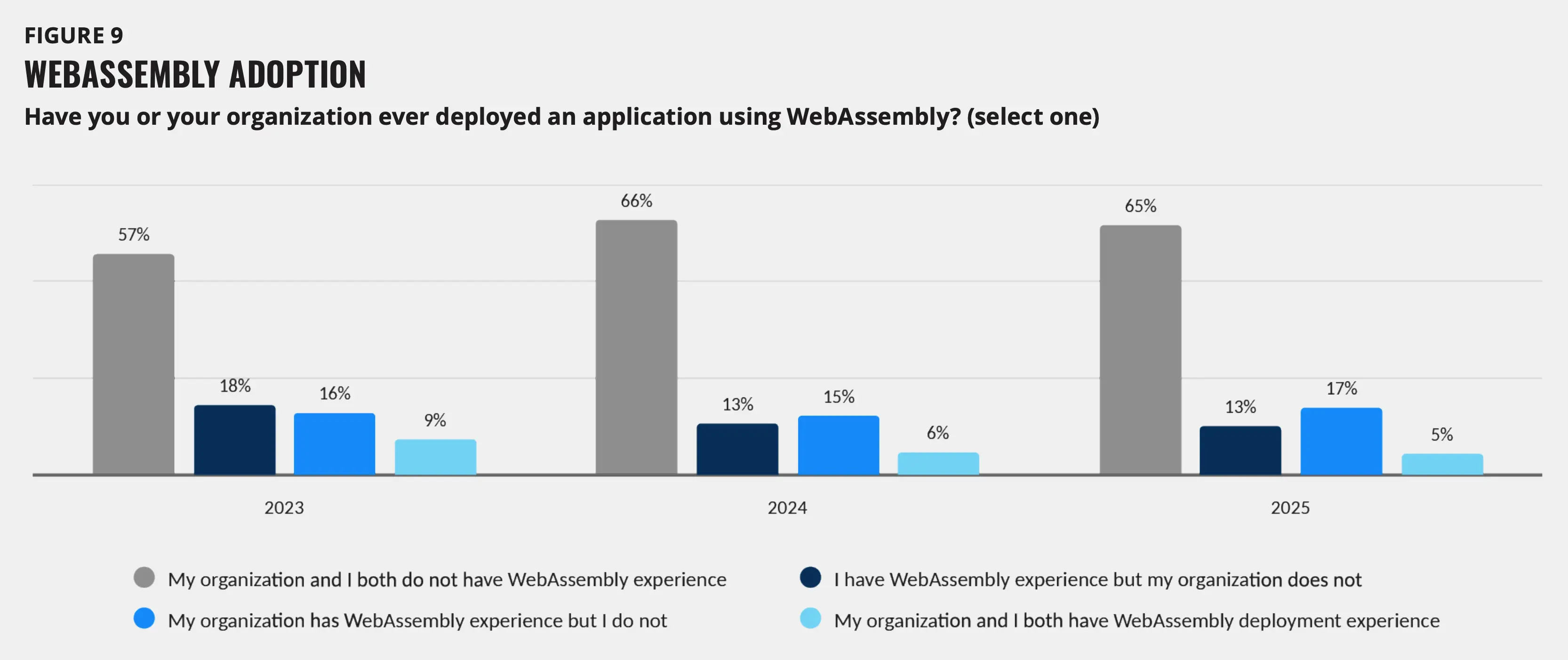
约 65% 的组织表示没有 WebAssembly 使用经验。连续三年,仅有 5% 的人在 2025 年拥有完整的部署经验。WebAssembly 在云原生领域尚未迎来转折点。
云原生成熟度概况
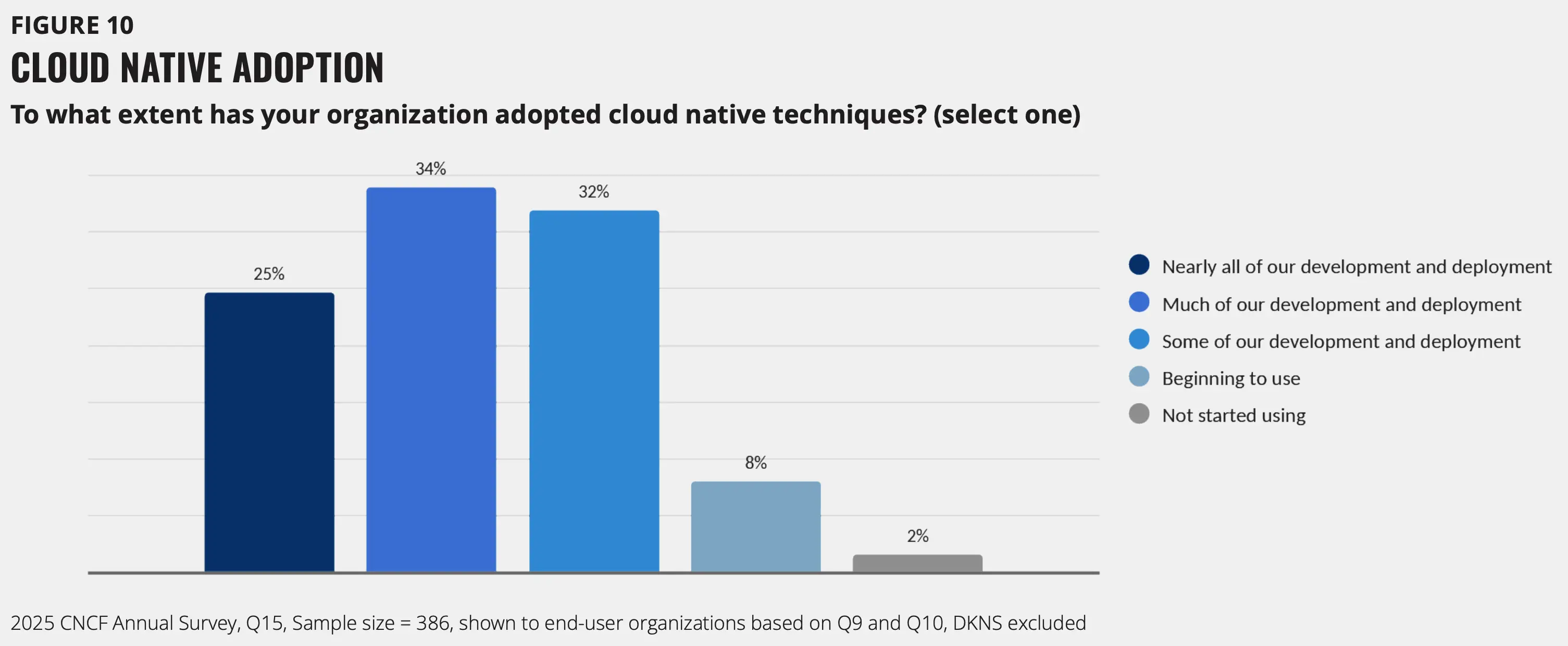
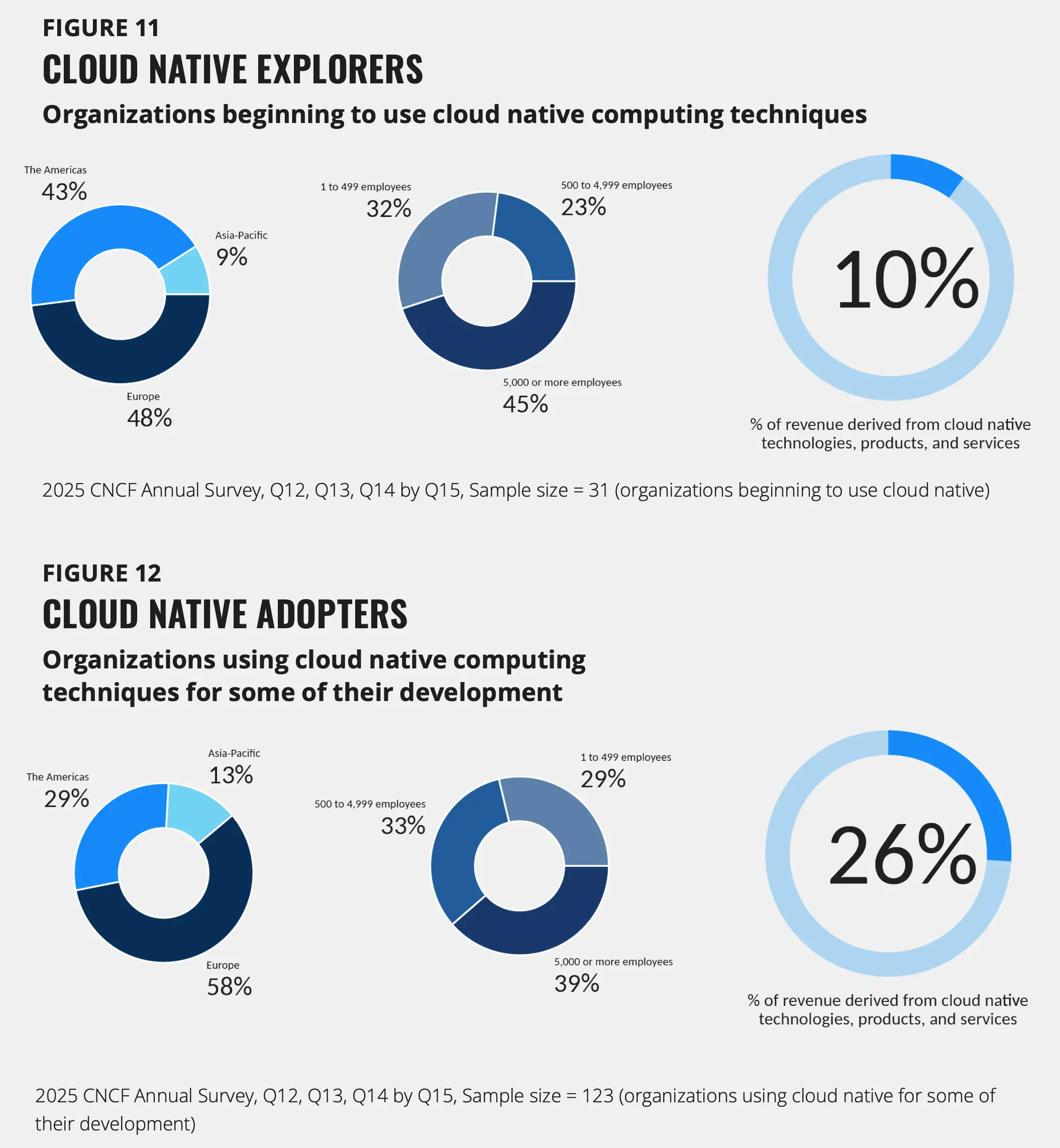
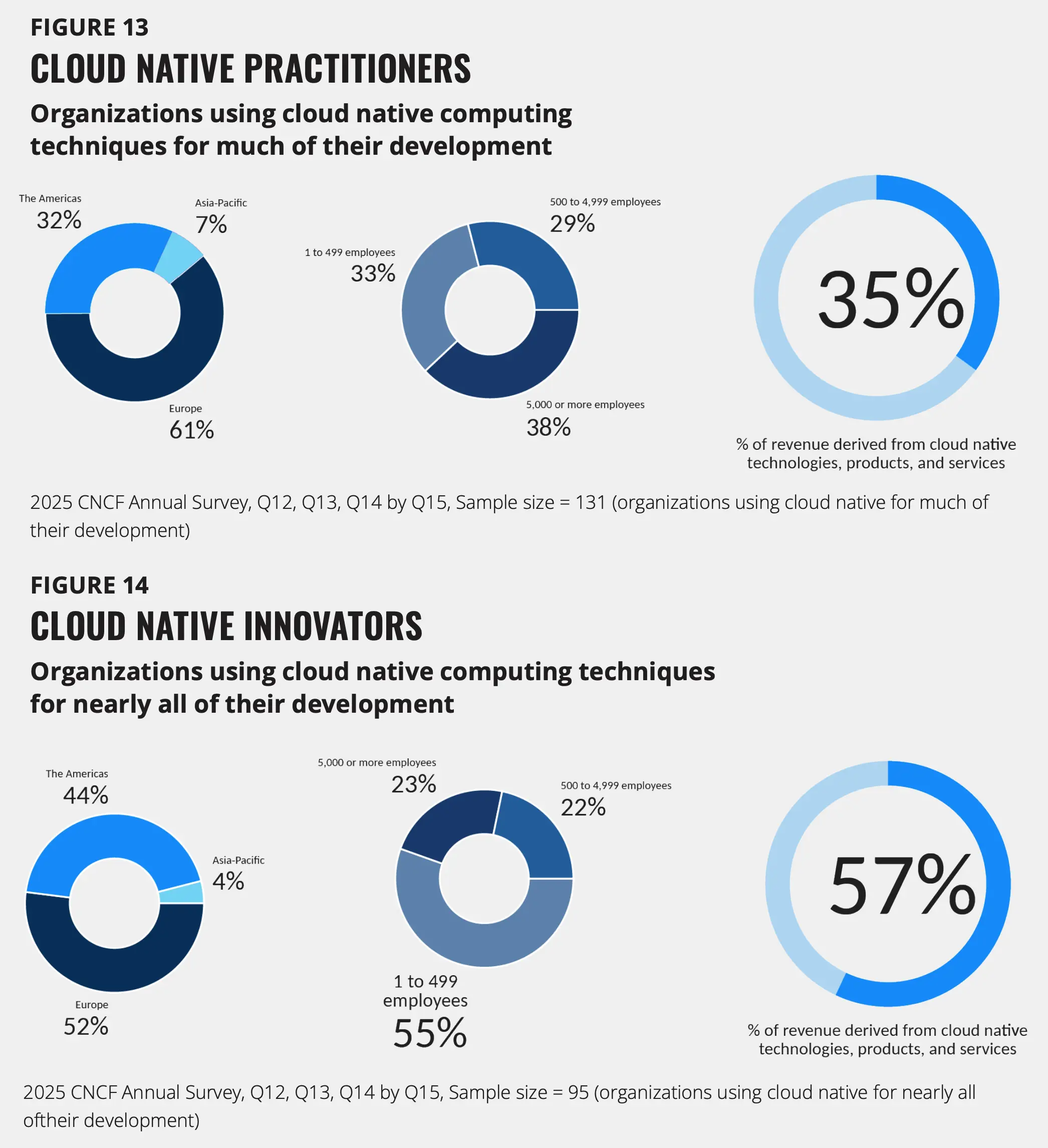
为了更好地了解各组织在云原生转型过程中所处的阶段,我们根据其原生采用情况对其进行了分类。不同阶段会产生四种不同的成熟度特征:
- 云原生探索者(占组织总数的 8%):开始使用云原生技术。这些组织正在进行试验使用容器和基本部署。
- 云原生采用者(32%):使用云原生技术它们的开发和部署。这些组织可选择性地应用于特定项目或团队。
- 云原生从业者(34%):使用云原生在其大部分开发和部署过程中。这些组织在大多数举措中都得到了主流采纳。
- 云原生创新者(25%):使用云原生技术几乎所有开发和部署工作都已完成。这些组织实现了全面的、全组织范围的转型。
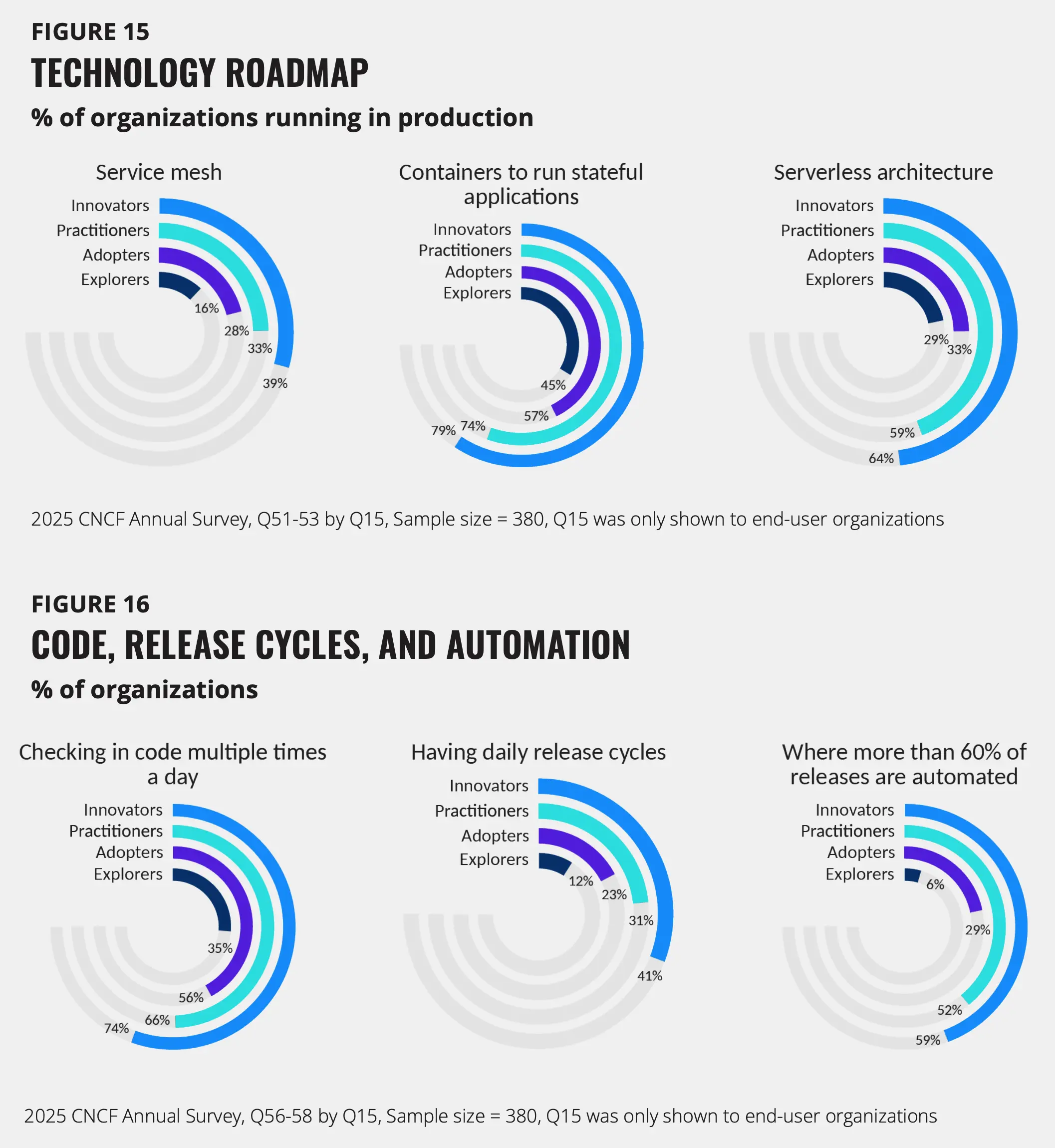
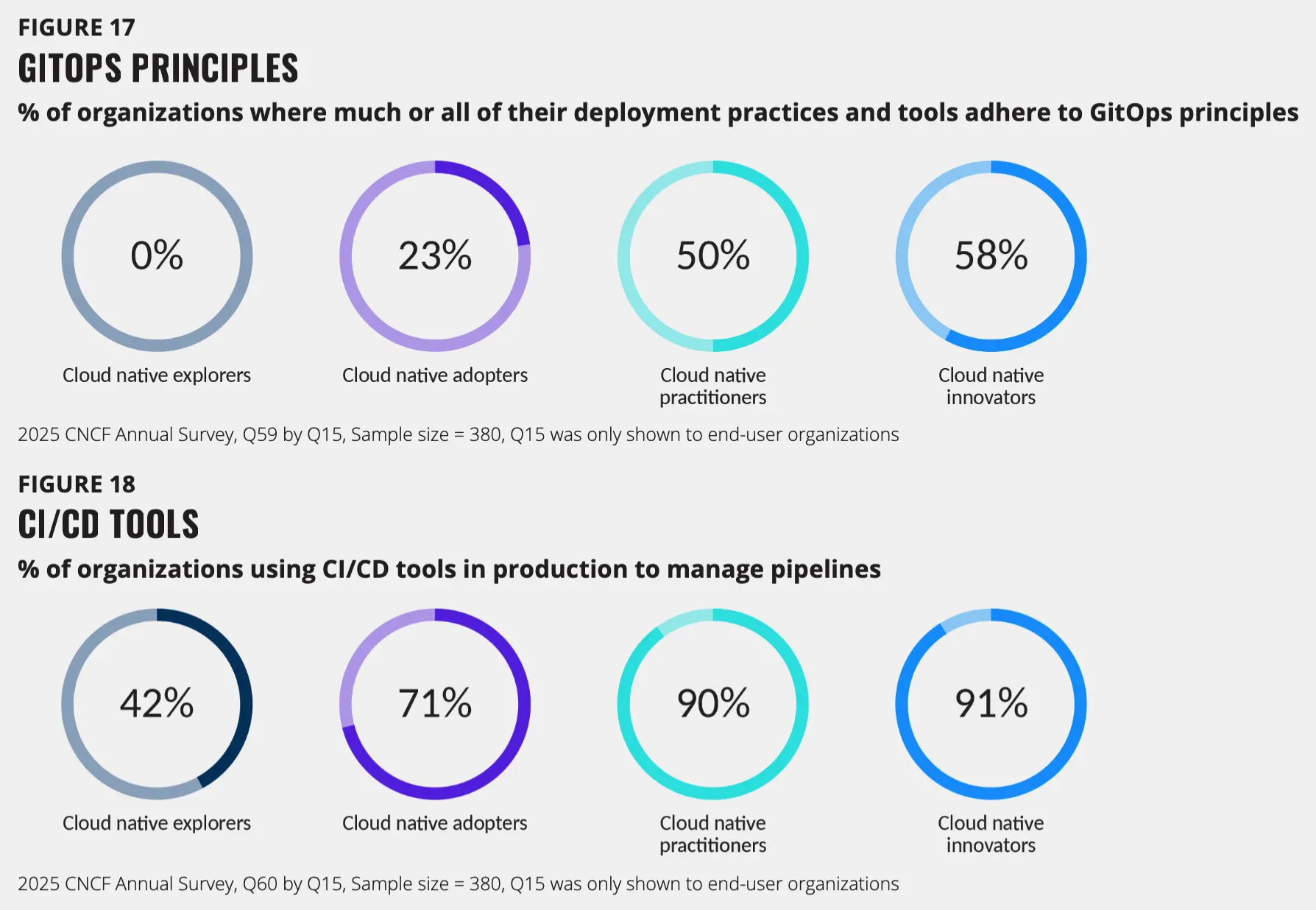
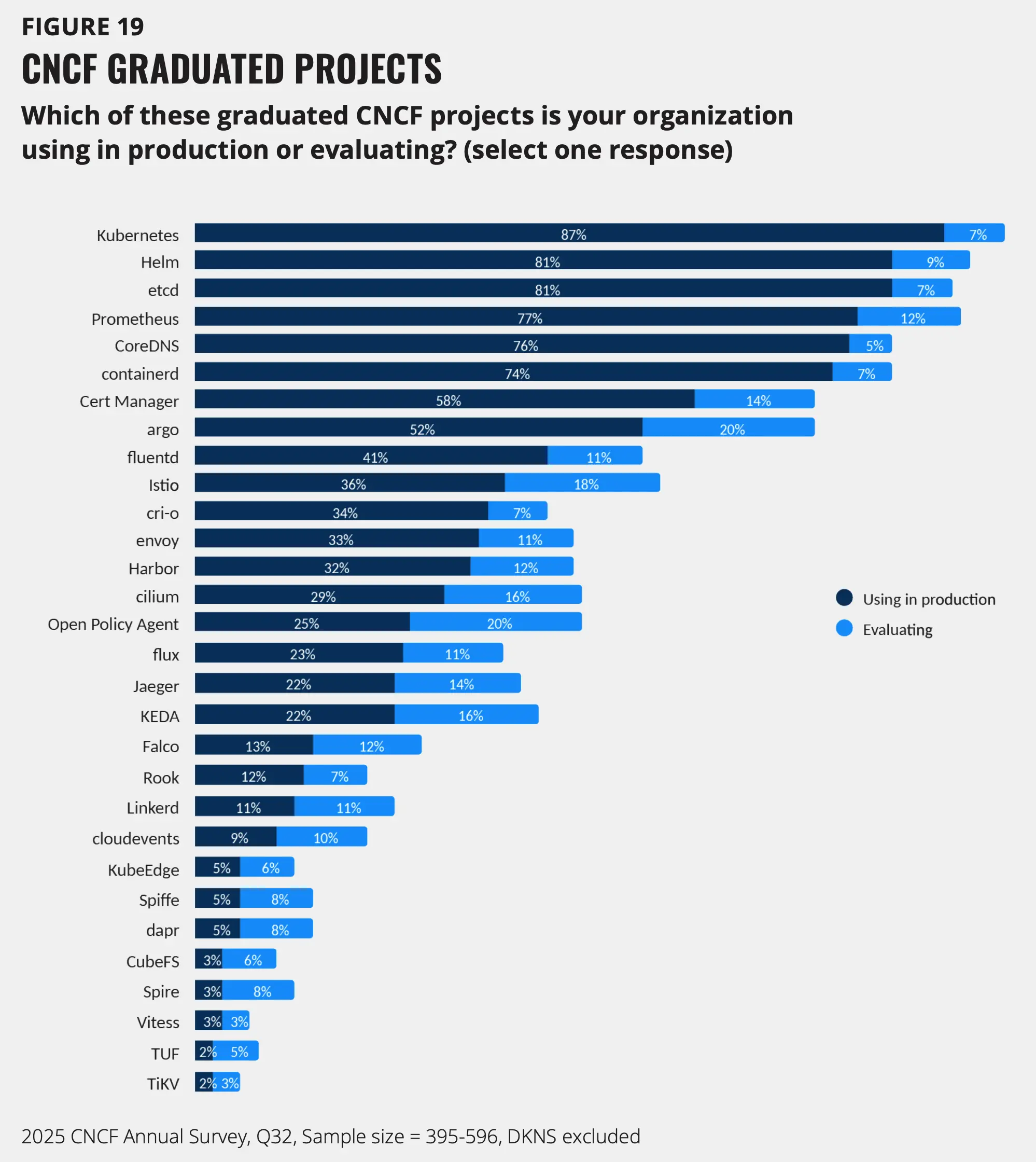
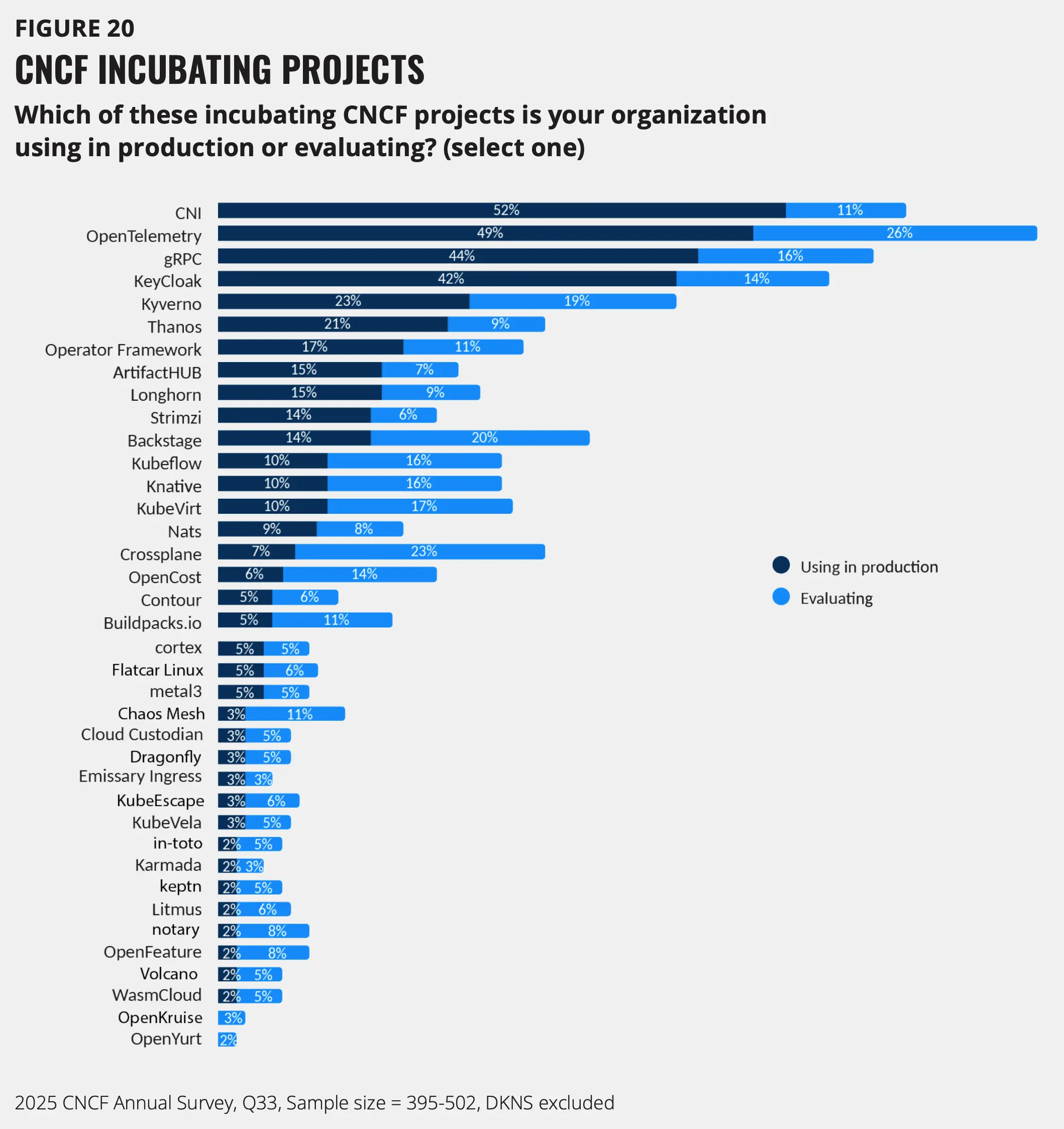
CNCF 项目
💁♀️ 专题五 产品/方案介绍
1. werf:Kubernetes 全周期 CI/CD 的 CLI 工具
简介
werf 是一个 CNCF Sandbox CLI 工具,可轻松实现 Kubernetes 的全周期 CI/CD。werf 可集成到您的 CI 系统中,并利用 Git、Dockerfile、Helm 和 Buildah 等熟悉且可靠的技术。
特点
- 完整的应用程序生命周期管理:构建和发布容器镜像、测试、将应用程序部署到 Kubernetes、分发发布工件并清理容器镜像仓库。
- 易于使用:使用 Dockerfiles 和 Helm 图表进行配置,然后让 werf 处理其余所有事情。
- 高级功能:自动构建缓存和基于内容的标记、增强的资源跟踪和 Helm 中的额外功能、独特的容器注册表清理方法等等。
- 粘合常见技术:Git、Buildah、Helm、Kubernetes 和您选择的 CI 系统。
- 生产就绪:werf 自 2017 年起就已投入生产;成千上万的项目依靠它来构建和部署各种应用程序。
拓展阅读
2. NVSentinel:Kubernetes GPU 节点弹性系统
简介
NVSentinel 由 NVIDIA 开发的一套全面的 Kubernetes 服务,能够自动检测、分类和修复 GPU 节点中的硬件和软件故障。它专为 GPU 集群设计,可确保高性能计算环境中的最大正常运行时间和无缝故障恢复。
主要特点
- 全面监控:实时检测 GPU、NVSwitch 和系统级故障
- 自动化修复:采用警戒、排空和故障修复工作流程进行智能故障处理
- 模块化架构:可插拔的健康监测器,采用标准化的 gRPC 接口
- 高可用性:Kubernetes 原生设计,支持副本和领导者选举
- 实时处理:事件驱动架构,可立即响应故障
- 持久化存储:基于 MongoDB 的事件存储,带有用于实时更新的变更流
- 优雅处理:协调工作负载移除,并可配置超时时间
- 元数据增强:利用云提供商和节点元数据信息自动增强健康事件
🤔 专题六 有意思的事与 Meme
1. kubectl 和 yaml 打字练习
Typing practice - but it's kubectl and sample yaml snippets
2. AI Fundamentals
这是 GitHub 上的一个仓库,该仓库是一个全面的人工智能基础设施(AI Infrastructure)学习资源集合,涵盖从硬件基础到高级应用的完整技术栈。内容包括 GPU 架构与编程、CUDA 开发、大语言模型、AI 系统设计、性能优化、企业级部署等核心领域,旨在为 AI 工程师、研究人员和技术爱好者提供系统性的学习路径和实践指导。
适用人群:AI 工程师、系统架构师、GPU 编程开发者、大模型应用开发者、技术研究人员。 技术栈:CUDA、GPU 架构、LLM、AI 系统、分布式计算、容器化部署、性能优化。
3. CNCF Releases
汇总了 CNCF 项目的最新版本说明。