🆕 专题一 产品新功能/新版本
1. Dapr v1.17 重磅发布:工作流版本管理上线,性能飙升 41%,批量 Pub/Sub 正式稳定
简介
Dapr 是一套集成的 API,内置最佳实践和模式,用于构建分布式应用程序。Dapr 提供开箱即用的功能,例如工作流、发布/订阅、状态管理、密钥存储、外部配置、绑定、Actor、分布式锁和加密,可将开发人员的生产力提高 20-40%。您将受益于其内置的安全性、可靠性和可观测性功能,无需编写样板代码即可实现生产就绪的应用程序。
关键优化
- 工作流版本管理。提供了两种互补策略:命名版本(Named Versions)与补丁(Patching)。
- 工作流状态保留策略。精细控制工作流执行历史在状态存储中的保留时间。
- 工作流性能与追踪。大幅提升性能并支持端到端追踪。
2. Kubernetes 1.36 – 你需要了解的内容
Kubernetes 1.36 – What you need to know
关键更新
- DRA 中的污点和容忍
- DRA 对可分区设备的支持
- OCI VolumeSource
- 基于清单的准入控制配置
- Job 暂停时可变容器资源
- 向 StatefulSet 添加重新创建更新策略
- 将工作负载 API 与 Job controller 集成
- Deployment Pod 更换策略
- 更快的 SELinux 卷标签
- 外部签名 ServiceAccount 令牌
启用与废除
- Service 中已弃用 .spec.externalIPs
- 移除 gitRepo 卷驱动程序
3. Ingress2Gateway 1.0 正式发布:通往网关 API 的途径
Announcing Ingress2Gateway 1.0: Your Path to Gateway API
背景
随着 Ingress-NGINX 计划于 2026 年 3 月退役 ,Kubernetes 网络格局正处于一个转折点。对于大多数组织而言,问题不再是是否迁移到 Gateway API ,而是如何安全地进行迁移。
从 Ingress API 迁移到 Gateway API 是 API 设计的根本性转变。Gateway API 提供了一个模块化、可扩展的 API,并对 Kubernetes 原生的基于角色的访问控制 (RBAC) 提供了强大的支持。相反,Ingress API 较为简单,而像 Ingress-NGINX 这样的实现则通过晦涩难懂的注解、ConfigMap 和 CRD 来扩展 API。从 Ingress-NGINX 等 Ingress 控制器迁移到 Gateway API 面临着一项艰巨的任务:需要捕捉 Ingress 控制器的所有细微差别,并将这些行为映射到 Gateway API。
Ingress2Gateway 是一款辅助工具,可帮助团队自信地从 Ingress API 迁移到 Gateway API。它会将 Ingress 资源/清单以及特定于实现的注解转换为 Gateway API,同时对无法转换的配置发出警告并提供建议。
Ingress2Gateway 1.0
- Ingress-NGINX 注解支持:1.0 版本的主要改进在于更全面的 Ingress-NGINX 支持。在 1.0 版本之前,Ingress2Gateway 仅支持三种 Ingress-NGINX 注解。而 1.0 版本则支持超过 30 种常用注解(例如 CORS、后端 TLS、正则表达式匹配、路径重写等)。
- 全面集成测试:每个受支持的 Ingress-NGINX 注解以及常用注解的代表性组合,都由控制器级别的集成测试提供支持,这些测试验证 Ingress-NGINX 配置与生成的 Gateway API 的行为等效性。这些测试在实际集群中运行真实控制器,并比较运行时行为(路由、重定向、重写等),而不仅仅是 YAML 结构。
- 通知和错误处理:迁移并非“一键式”操作。揭示细微差别和难以翻译的行为与翻译受支持的配置同样重要。1.0 版本优化了通知的格式和内容,让您清楚地了解缺失的内容以及如何修复。
4. Amazon EKS Pod Identity 推出全新的会话策略功能
Session policies for Amazon EKS Pod Identity
借助这项新功能,您可以动态地缩小 Kubernetes Pod 的 AWS Identity and Access Management (IAM) 权限范围,而无需创建额外的 IAM 角色。会话策略提供了一种灵活的替代方案,无需为每种权限变体创建单独的 IAM 角色,只需在创建 Pod Identity 关联时指定内联 IAM 策略即可。这有助于您大规模管理权限,而无需增加角色数量。这意味着您的 Kubernetes 应用程序现在可以按照最小权限原则,以所需的精确权限运行,同时避免在大规模部署中达到 IAM 角色限制。
5. Kubescape 4.0 正式发布:企业级稳定性、高级威胁检测与 AI 安全能力全面升级
Kubescape 4.0 正式发布:企业级稳定性、高级威胁检测与 AI 安全能力全面升级
Kubescape 是一个开源的 Kubernetes 安全平台,旨在为 Kubernetes 环境提供实用、端到端的安全保障。它为工程师和运维人员在整个开发和部署生命周期中提供支持,提供配置扫描、漏洞评估、策略执行、网络策略和 seccomp 验证以及运行时威胁检测等工具。
发布亮点:
- 运行时威胁检测正式达到 GA
- Kubescape Storage 正式达到 GA
- 增强后的 Node-Agent 与 Host-Sensor 的弃用
- Kubescape 进入 AI 时代
- 为 AI 安全助手赋能
- 扫描 AI 的安全态势
📰 专题二 新闻与访谈
1. CNCF 宣布成立 AI 网关工作组
什么是 AI 网关
在 Kubernetes 环境中,AI 网关指的是网络网关基础设施(包括代理服务器、负载均衡器等), 它通常实现 Gateway API 规范,并针对 AI 工作负载提供增强功能。 AI 网关并非定义一个独立的产品类别,而是描述旨在对 AI 流量实施策略的基础设施,包括:
- 基于 token 的 AI API 速率限制。
- 推理 API 的细粒度访问控制。
- 有效负载检查,实现智能路由、缓存和防护机制。
- 支持 AI 特有的协议和路由模式。
工作组章程和使命
AI 网关工作组遵循清晰的章程运作, 其使命是为 Kubernetes 特别兴趣小组(SIG)及其子项目制定提案。 其主要目标包括:
- 标准制定:为 Kubernetes 中的 AI 工作负载网络创建声明式 API、标准和指南。
- 社区协作:促进讨论并就 AI 基础设施的最佳实践达成共识。
- 可扩展架构:确保 AI 专用网关扩展的可组合性、可插拔性和有序处理。
- 基于标准的方法:基于已建立的网络基础,在成熟的标准之上构建 AI 专用功能。
2. 与 VKS 达成新的合作伙伴产品
Accelerating Customer Success with Expanded Partnerships across the Kubernetes Ecosystem
背景
在瞬息万变的云原生开发领域,Kubernetes 平台的强大程度取决于支撑它的生态系统。我们认为,由合作伙伴验证的产品组成的强大生态系统是提升客户体验和实现客户持续成功的关键引擎。
虽然 VMware Cloud Foundation (VCF) 提供安全的企业级私有云,但其全部潜力是通过 VMware vSphere Kubernetes Service (VKS) 释放出来的,VKS 是一个内置的、经 CNCF 认证的 Kubernetes 运行时。
我们正深化对 VKS 及其合作伙伴产品生态系统快速创新的承诺。通过与云原生领域的行业领导者合作,我们为客户提供了一个经过验证的基础架构,使他们能够自信地运行最关键的工作负载。今天,在 KubeCon Europe 大会上,我们很高兴地宣布与 VKS 达成新的合作伙伴产品验证。这些组织代表了云原生网络、安全和 API 管理领域的领先水平,为我们的客户提供更大的选择和灵活性。
合作伙伴产品
- F5 BIG-IP Container Ingress Services (CIS) 充当 Kubernetes 环境(例如 VKS)与 F5 BIG-IP 硬件/虚拟设备之间的桥梁。它通过将容器编排器事件转换为 BIG-IP 配置更改,实现对流量管理、负载均衡和安全等应用服务的自动化管理。
- Kong Konnect 是一个统一的 API 生命周期管理平台,提供高性能的运行时引擎来管理传统 API、AI 和微服务流量。在 VKS 等 Kubernetes 环境中,Kong API Gateway(Kong Konnect 的一部分)充当智能“控制塔”,将外部请求转换为安全且受控的内部流量,延迟低于毫秒级,同时提供统一的界面,用于配置、治理和深度分析。
- Tigera 的 Calico Enterprise 为平台工程团队提供了一个统一的管理平台,用于保护、监控和排查 Kubernetes 环境(例如 VKS)中所有集群的所有工作负载通信。它基于最值得信赖的开源技术构建,并通过企业级功能扩展了原生功能,包括高级网络安全控制和深度可观测性。
拓展阅读
Strengthening the Cloud-Native Ecosystem Through Upstream Collaboration
在博通,我们云原生创新的方法根植于参与社区建设,成为维护者、贡献者和协作者,共同推动现代平台所依赖的技术发展。
推动 Velero 向 CNCF 管理机构转型
与集群 API (CAPI) 社区合作开展 Kubernetes 生命周期管理
与 etcd 社区合作,提升 Kubernetes 核心可靠性
3. Broadcom 向 CNCF 捐赠 Velero
Broadcom VMware 宣布,将把 Velero 捐赠给 CNCF 沙箱项目。该公司称此举旨在将 VMware vSphere Kubernetes Service 扩展到私有云和公有云中的 Kubernetes 用户组织。
Velero 的前身是 Heptio,VMware 五年前收购了 Heptio。Heptio 是一个以 API 为中心的项目,由前 Google 和 Kubernetes 联合创始人 Joe Beda 和 Craig McLuckie 创立。根据 ESG 和 CNCF 的指标,Broadcom 也一直是 Kubernetes 的主要贡献者之一。在 CNCF 的指导下,企业可能会更有信心依靠 Velero 来实现有状态应用程序恢复和跨环境工作负载迁移。
拓展阅读:Why Broadcom gave Velero to the CNCF Sandbox — and what it means for Kubernetes data protection
4. IBM、Red Hat 和 Google 将 llm-d 捐赠给 CNCF
IBM, Red Hat, and Google just donated a Kubernetes blueprint for LLM inference to the CNCF
周二,在阿姆斯特丹举行的 KubeCon Europe 2026 大会上, IBM Research、Red Hat 和 Google Cloud 云宣布将他们的开源分布式推理框架 llm-d 捐赠给云原生计算基金会 (CNCF) 作为沙箱项目。
llm-d 于 2025 年发布,旨在使大规模基础模型服务变得可预测、可移植且云原生。它将推理从临时性的、逐个模型的挑战转变为可复制的、生产级的、基于 Kubernetes 的系统。llm-d 由 Neural Magic 创建,该公司于 2025 年被 Red Hat 收购。IBM 研究院杰出工程师 Carlos Costa 在 KubeCon 的主题演讲中表示,IBM 的目标是“打造一个能够服务于一流云原生工作负载的大规模模型”。Kubernetes 与 AI 的结合已在 llm-d 中实现,llm-d 是一个可复制的 Kubernetes 蓝图,用于在任何云上的任何加速器上为任何模型部署推理堆栈。
5. Fluid 晋升 CNCF 孵化项目:加速云原生 AI 与大数据应用创新
Fluid 晋升 CNCF 孵化项目:加速云原生 AI 与大数据应用创新
云原生计算基金会(CNCF)技术监督委员会(TOC)于 2026 年 1 月 8 日正式投票接受 Fluid 作为 CNCF 的孵化项目。这一重要里程碑标志着 Fluid 社区在技术成熟度、社区活跃度以及生态系统影响力方面均达到了新的高度,获得了云原生社区的广泛认可。
Fluid 是一个开源的 Kubernetes 原生分布式数据集编排器和加速器,专为大数据和人工智能等数据密集型应用而设计。它由云原生计算基金会 (CNCF) 托管,是一个沙箱项目。Fluid 可以将分布式缓存系统(例如 Alluxio 和 JuiceFS)转换为具有自我管理、弹性伸缩和自我修复能力的可观测缓存服务,其实现方式是支持数据集操作。同时,Fluid 还利用数据缓存位置信息,为使用数据集的应用提供数据亲和性调度。
6. Bitnami 镜像现已由 Anchore Tools 全面扫描
Bitnami 镜像现已由 Anchore Tools 全面扫描
VMware Tanzu 宣布,Bitnami 所有镜像的安全报告功能已得到增强:Bitnami 安全镜像现在可由 Anchore 的开源项目 Grype 分析工具进行正确且全面的扫描。
这一关键集成意味着,当您在任何官方 Bitnami 容器或 VM 镜像上使用 Anchore 的安全分析工具套件时,所报告的通用漏洞和披露 (CVE) 数据将最准确地反映我们致力于提供强化、可用于生产的镜像的承诺。
Anchore Enterprise 是一款基于软件物料清单 (SBOM) 的软件供应链管理解决方案,专为云原生环境而设计。它能够持续监控供应链安全风险。Anchore Enterprise 采用对开发者友好的方式,通过将自动化功能嵌入开发工具链,生成 SBOM 并准确识别漏洞、恶意软件、错误配置和敏感信息,从而最大限度地减少开发摩擦,加快修复速度。
💬 专题三 讨论与分享
1. 字节跳动的超大规模 Kubernetes 集群解决方案
ByteDance's Solution for Ultra-Large-Scale Kubernetes Clusters
单集群扩展:KubeBrain
KubeBrain 是字节跳动的元数据存储系统,旨在取代 Kubernetes 集群中的 etcd。它基于分布式 KV 存储引擎构建,支持生产环境中超过 2 万个节点的超大规模 Kubernetes 集群的稳定运行。
KubeBrain 采用分层架构,其存储引擎接口支持多个分布式 KV 存储后端:
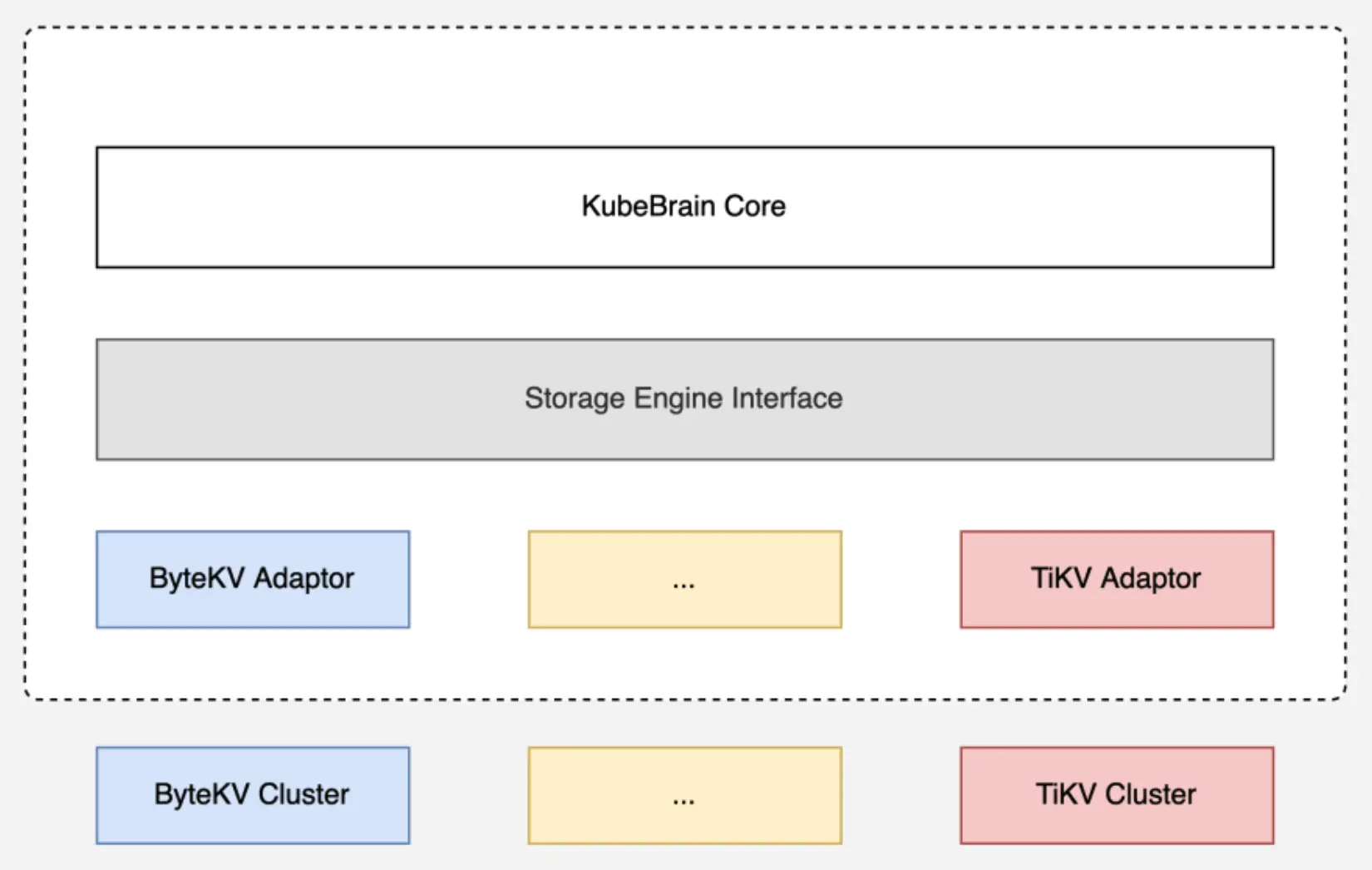
- KubeBrain 现已基于 TiKV 开源(https://github.com/kubewharf/kubebrain)
- 兼容性:支持 Kubernetes 1.25
- 性能优势:读写吞吐量显著高于 etcd
多集群编排:KubeAdmiral
随着业务规模的扩大,单个集群往往无法满足所有需求。字节跳动开源了 KubeAdmiral,这是一款基于 Kubernetes 的新一代多集群编排和调度引擎。
核心功能:
- 多集群应用管理:跨多个 Kubernetes 集群统一管理应用
- 智能调度:基于资源、拓扑、亲和性和其他策略的智能调度
- 故障转移:自动检测集群故障并迁移工作负载
- 灵活的联邦策略:支持多种资源分配和调度策略
调度器优化:Gödel
在大规模 Kubernetes 集群中,默认调度器往往会成为性能瓶颈。字节跳动开发了 Gödel 调度器,旨在优化大型集群的调度性能。
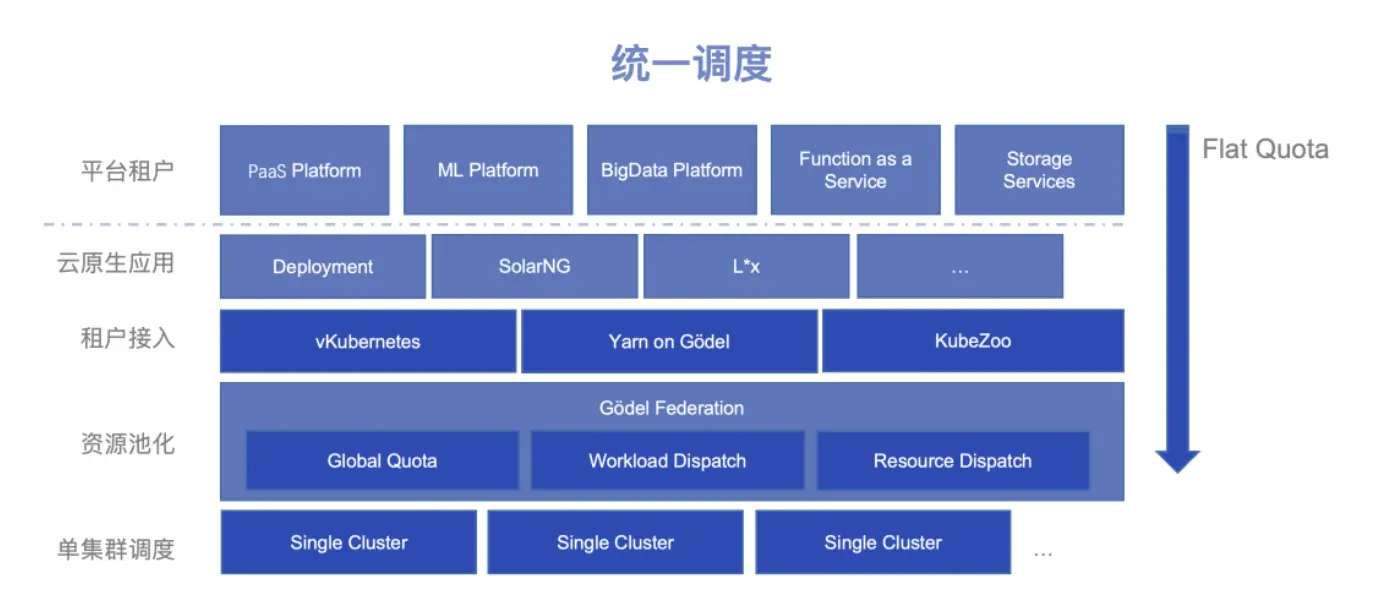
关键优化:
- 高吞吐量:支持大规模 pod 调度
- 资源池化:统一管理多集群资源
- 多租户支持:隔离不同类型的工作负载
- 灵活的配额管理:全球和集群配额的协调
资源管理:Katalyst
Katalyst 是字节跳动的开源 Kubernetes 资源管理系统,专注于提高大规模集群中的资源利用率和应用程序服务质量。
核心能力:
- QoS 感知调度:基于服务质量的智能调度
- 资源超额分配:安全的资源超额分配策略
- 动态资源调整:根据实际工作负载进行动态资源调整
- 托管优化:在线服务和离线任务托管的优化
架构优势:
- 调度层:Gödel 负责全局工作负载调度
- 节点层:Katalyst 管理节点级资源管理和 QoS 保证
- 反馈回路:将节点资源状态实时反馈给调度器
2. 为什么 Kubernetes 集群在仪表盘显示正常的情况下仍在添加节点?
Why is your Kubernetes cluster adding nodes when the dashboards look fine?
Kubernetes 一直以来都对错误输入非常敏感。如今的变化在于团队遇到错误输入的频率。随着更多突发性工作负载(尤其是推理)迁移到 Kubernetes,一种熟悉的模式也越来越频繁地出现:即使集群利用率看起来正常,集群仍然会添加节点。
如果你曾经查看过集群,却发现仪表盘显示还有充足空间,但集群仍在添加节点,你并不孤单。这种情况通常会在集群自动扩缩器或 Karpenter 部署完毕,并且一些明显的容量问题(例如节点大小不合适、约束过于严格或合并设置不当)都已解决之后出现。
大多数情况下,问题并非出在 Cluster Autoscaler 或 Karpenter 配置上,而是输入参数。请求值通常带有一定程度的猜测性,并预留一定的安全余量,而且这些请求值并非总能随着工作负载的变化而重新评估。
你眼前的这些图表看起来可能很平静,但当你观察很多数据点时,你会发现这些迹象呈现出一种熟悉的顺序:
集群范围内的 CPU 和内存图表显示存在以下情况:
- 调度器仍然无法放置新的 pod。
- Pods 处于待处理状态。
- 增加容量是为了让这些 Pod 能够着陆。
从表面上看, 集群似乎在不应该扩展的时候进行了扩展。但实际上,它正在执行其设计目标:根据已声明的预留资源保守地放置 Pod。
当感觉规模有问题时,首先要问的问题是:我们的请求是否仍然类似于这些工作负载目前的运行方式?
如果请求量过大,调度器会阻止原本应该合适的节点部署(如果按照实际使用情况分配)。集群的拥塞情况看起来比实际情况更糟,因此自动扩缩器会添加节点来满足预留请求,而不是应对实际压力。即使进行资源整合也无法解决问题,因为集群理论上已经满了。
如何在不将其变成一个项目的情况下确认漂移?
- 将请求量与一段时间内观察到的使用量进行比较,而不是仅查看单个快照。寻找每天都会重复出现的差距。
- 要观察工作负载横向扩展时的情况。当副本数量增加时,预留容量不会一直保持较小。如果部署在负载下从 5 个副本增加到 50 个副本,那么少量额外的请求很快就会转化为大量的预留容量。
- 一旦请求数量激增,副本数量攀升,出现额外的节点就是预期结果。
将问题进行分类:
- 哪些命名空间或服务是最大的违规者?
- 造成这种差距的原因是少数稳定的工作负载,还是规模远超负荷的突发性工作负载?
- 共享服务/闲置资源与直接工作负载占用之间,差距分别有多大?
3. 现代基础架构层级:掌握 VMware Cloud Foundation、vSphere Kubernetes Service 和 VCF Automation 中的命名空间
层级
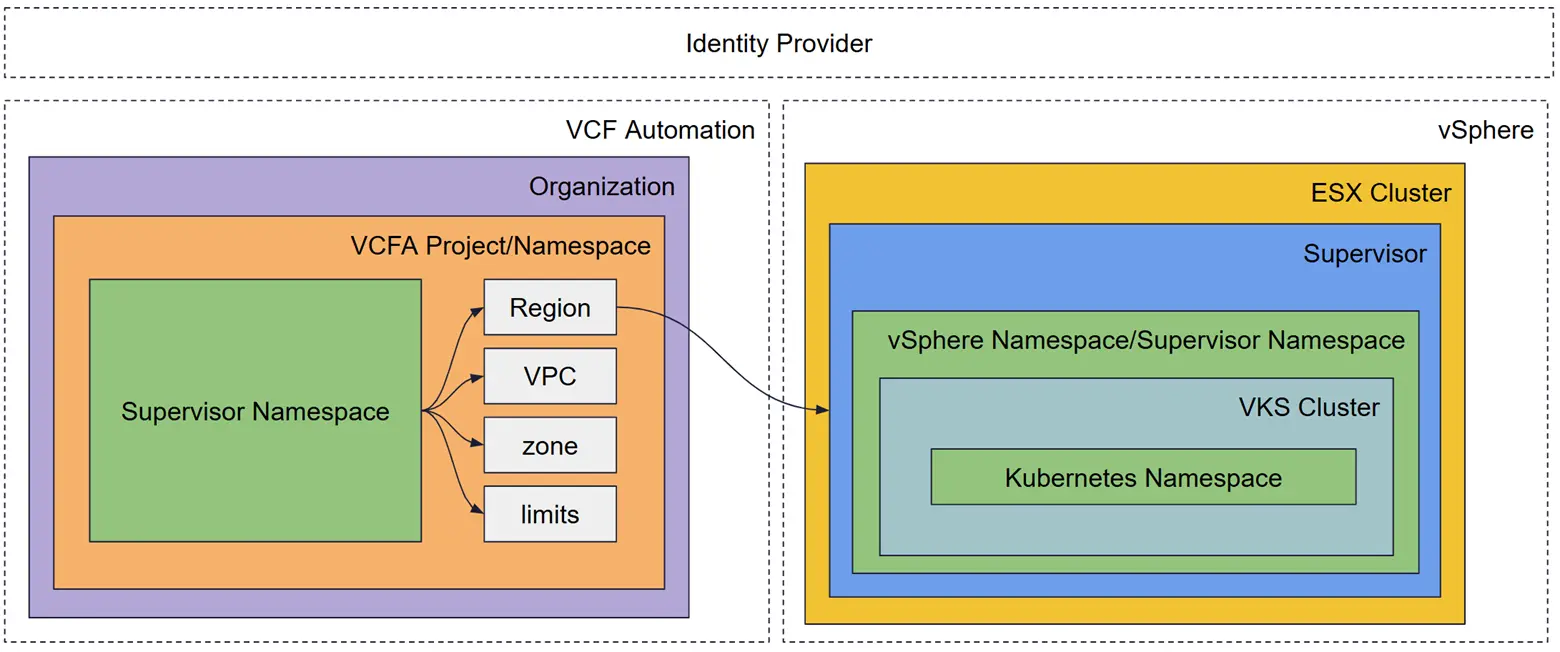
- 第一层:VCF Automation Project(治理层):VCF Automation 位于堆栈的顶层。在这一层,“命名空间”被抽象成一个项目。VCF Automation 充当主要租户边界。
- 第二层:vSphere Namespace(资源层):在 VCF Automation 中定义项目后,它会在 Supervisor 集群上配置一个 vSphere Namespace(也称为 Supervisor 命名空间)。这是 VCF 的“连接组织”。VKS Supervisor 本质上是一个运行在 ESXi 上的专用 Kubernetes 集群。vSphere Namespace 是一个管理结构,而不是直接部署应用程序代码的地方。
- 第三层:VKS Namespace(工作负载层):一旦 Supervisor 命名空间准备就绪,开发人员就可以使用它来启动自己的专用 Kubernetes 集群。
优势
通过将 VCF Automation Project、vSphere Namespace 和 VKS Namespace 分离,VCF 提供了以下优势:
- 管理员可以完全了解和控制物理资源消耗和安全加固情况。
- DevOps 团队可以获得所需的自助服务速度,无需提交工单即可在几分钟内启动 Kubernetes 集群。
- 企业获得了一个可靠、可扩展的平台,弥合了传统虚拟机和现代容器之间的差距。
实例
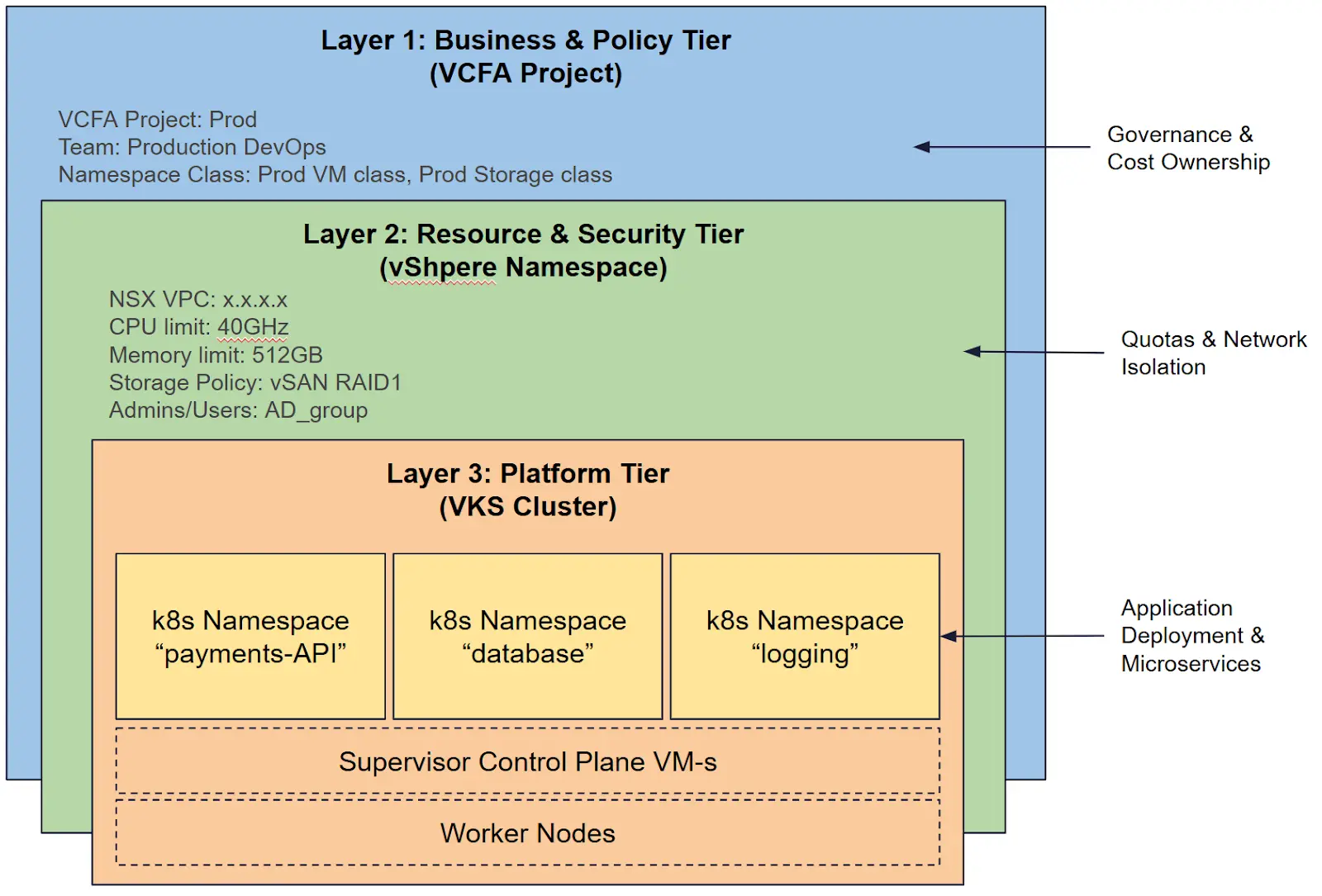
- 治理层 —— 业务和策略层(VCF Automation):云管理员在 VCF Automation 中创建两个项目: 开发项目和生产项目。 开发项目允许使用“尽力而为”的存储和较小的虚拟机规模。生产项目则强制要求使用“RAID-1 镜像”和“超大型”虚拟机规模。我们已定义了业务边界 。开发人员登录 VCF Automation 门户后,只能看到他们负责的特定项目。
- 基础架构层 —— 资源层和安全层(vSphere Namespace):生产项目的开发人员创建了命名空间——VCF Automation 与 Supervisor 通信并自动配置 vSphere 命名空间。配额已应用——限制为 512GB 内存和 2TB vSAN 存储。此外,NSX VPC 也已从 IP 空间中自动划分出来,并分配了一个专用的 CIDR 块。仅将生产 DevOps AD 组添加为“所有者”。
- 工作负载层 —— 平台层(VKS 集群):DevOps 工程师使用 kubectl 将 VKS 集群部署到 vSphere 命名空间中,用于运行其微服务。Supervisor 配置了三个控制平面虚拟机和五个工作虚拟机。这就是操作边界。
- 应用层(Kubernetes Namespace):开发人员登录到新的 VKS 集群,并为应用程序组件创建标准的 Kubernetes 命名空间。他们运行 kubectl 命令来创建命名空间。
4. 生产环境中的 Helm:经验教训和陷阱
Helm in production: lessons and gotchas
自行管理 CRD
Helm 只在初始图表安装时安装 CRD,从不更新、回滚或删除 CRD。 如果您不自行管理 CRD,则永远不会收到 CRD 更新。
这也意味着,带有 CRD 的图表对于版本而言不是幂等的:从 1.0.0 升级到 1.1.0 产生的结果与直接安装 1.1.0 产生的结果不同。
等待并不总是意味着等待
在 Helm 4 之前, --wait 标志仅用于等待 Pod 和 hooks。从 Helm 4 开始 ,该标志使用 kstatus 进行等待 。 用于检查资源健康状况,但即使是 kstatus 也不能保证对自定义资源有效。
如果你的 Helm Chart 部署了自定义资源, --wait 标志可能无法按预期工作。Helm 可能会成功返回,但不会提示应用程序尚未准备就绪。
试运行(Dry run)并不像它名字暗示的那样‘干’
当使用 --dry-run 运行 helm upgrade 时,如果现有版本未能通过 Helm 的健康检查,则 dry-run 升级也会失败。
避免在 PR/MR 管道中使用 --dry-run 因为如果现有安装不正常,它会阻止合并。
验证你的值
图表可以包含一个 values.schema.json 文件,其中包含用于图表值验证的 JSON 模式。该模式允许指定字符串值长度、枚举类型、属性名称等方面的附加限制。可以将模式加载到 yaml-language-server 中,以便在编辑值文件时提供模式验证。
OCI 注册表涵盖一切
Helm 已经从传统的 Helm 仓库格式转向 OCI 注册表。
图表可以上传到任何与 OCI 兼容的注册表,从而使您可以使用同一个注册表提供商来管理图表和容器镜像。
使用 OCI 镜像仓库时,安装时必须指定完整的镜像 URL。这样就无需运行 repo add ,也不用担心因为忘记运行 repo update 而导致镜像版本过旧。尽可能优先选择 OCI 而非传统的 Helm 镜像仓库。
5. 迁移之前:你需要了解的 Ingress-NGINX 的五个令人惊讶的行为
Before You Migrate: Five Surprising Ingress-NGINX Behaviors You Need to Know
- 正则表达式匹配基于前缀,且不区分大小写
- nginx.ingress.kubernetes.io/use-regex 适用于主机在所有 (Ingress-NGINX) Ingress 中的所有路径
- 重写目标意味着正则表达式
- 缺少尾部斜杠的请求将被重定向到带有尾部斜杠的同一路径
- Ingress-NGINX 对 URL 进行规范化
6. Cluster API、不可变性和 Kubernetes 基础设施的未来
Cluster API, Immutability, and the Future of Kubernetes Infrastructure
不可变性的好处
- 速度
- 大规模管理
- 安全
- 稳定
示例
- 滚动升级:这种方法源于不可变性原则,不仅允许您执行 Kubernetes 升级,而且通过支持创建和删除机器这两个简单的原语,允许您对机器(基础架构、操作系统和 Kubernetes 组件)执行任何类型的更改。该过程本质上是可重复和可预测的;更换每台机器可确保每个节点都达到预期状态,而不会出现配置漂移经常导致的意外情况。
- 修复不健康的机器:快速创建一个全新的、纯净的替代机器,并删除旧机器——同样利用了创建和删除机器这两个简单的原语。
- 避免不必要的滚动更新:机器是复杂的组件,有时你想进行一些不需要节点排空或 pod 重启的更改;例如,更改镜像仓库证书。如果出于任何原因,您希望在不进行全面机器部署的情况下执行此类更改,集群 API 提供了扩展点,允许以安全且全自动的方式执行一组经过严格验证的就地更新操作,从而实现这一目标。即使在这种情况下,通过在所有机器上一致地应用相同的更改,也能避免配置漂移。
7. 隐形重写:Kubernetes 镜像推广器的现代化
The Invisible Rewrite: Modernizing the Kubernetes Image Promoter
背景
从 registry.k8s.io 拉取的每个容器镜像都是通过以下方式获得的: kpromo ,Kubernetes 镜像推广工具。它将镜像从暂存镜像仓库复制到生产环境,使用 cosign 对其进行签名,并进行复制。 在超过 20 个区域镜像站点上收集签名,并生成 SLSA 出处认证。如果这个工具出问题,Kubernetes 的任何版本都无法发布。
解决的问题
Kubernetes 核心镜像的生产环境部署任务通常耗时超过 30 分钟。并且经常因速率限制错误而失败。核心分发逻辑已经发展成一块巨大的岩石,难以扩展而且难以测试,这使得溯源或漏洞等新功能难以实现。扫描功能很麻烦。
新的 pipeline

- Setup:验证选项,预热 TUF 缓存。
- Plan:解析清单,读取注册表,计算哪些镜像需要升级。
- Provenance:核实暂存图像上的 SLSA 认证。
- Validate:检查共同签署人的签名,从这里退出进行演练。
- Promote:在服务器端复制图像,保留摘要。
- Sign:使用无钥匙联署功能推广图片。
- Attest:使用专用的整体谓词类型生成促销来源证明。
对用户的影响
用户端无任何变更。但是相关性能会提高,代码库也进行了精简。
8. 抽样:分布式追踪的点金石
Sampling: the philosopher’s stone of distributed tracing
背景
在现代可观测性领域,分布式追踪通常被认为是最具表现力的信号。它不仅能够捕获日志提供的大部分信息,还能提供丰富的执行上下文。如果没有 OpenTelemetry,这种转变在实践中是无法实现的。OpenTelemetry 支持跨各种框架、库和技术进行跨度收集。
然而,分布式追踪也可能代价高昂。在如今(有时甚至是毫无必要地)分布式系统盛行的时代,即使是中等规模的环境也能产生海量的跨度数据。虽然存储大量数据的成本总体上有所降低,但我们大规模查询跨度数据的能力却未能跟上生成跨度数据的能力。
解决方案:采样
如果我们无法有效地查询所有收集到的追踪数据,一个直观的正确解决方法是缩小数据量。 采样 ,即选择性地保留一部分生成的追踪数据,与分布式追踪本身一样古老。
分布式追踪的抽样方法通常分为两类:
- 头部采样预先决定是否为给定请求创建 span,通常是在请求到达第一个跟踪组件时。
- 尾部采样会记录所有请求的跟踪数据,但选择性地仅存储其中的一部分。
头部采样
当一个新的波形即将开始时,你立即决定是否要采集它。
头部采样决策可以基于请求属性,但在实践中,它通常是随机的,通过确定性规则(例如模运算)从跟踪标识符中得出。
随机采样通常被称为一致概率采样或确定性采样 。它假设从统计学角度来看,所有轨迹都有相同的价值概率。或者至少,在采样率足够高且轨迹数量足够多的情况下,诸如错误和延迟峰值之类的重要信号仍然能够被充分识别,并在统计学上得到很好的体现。
实际上,尤其是在个位数采样率下,这种假设并不成立。一致性概率采样往往会遗漏或低估局部问题,即一小部分请求的行为与其他请求截然不同。
尾部采样
尾部采样基于一个所有可观测性实践者都明白的道理:并非所有轨迹都具有相同的价值。理论上,其思路很简单:收集轨迹的所有跨度,然后判断该轨迹是否值得保留。如果实现得当,尾部采样可以非常有效。然而,遗憾的是,它也很难完美实现。
总结
在观测大型分布式系统时,采样是不可避免的必要步骤。虽然概念很简单,但实际操作起来却很复杂。这种复杂性会向外扩散,尤其体现在 RED 指标的生成和保存方式上。
好消息是,进展仍在继续。针对尾采样处理器提出的基于磁盘的缓冲方案旨在降低尾采样的操作难度。诸如 SignalTometricsConnector 之类的新型连接器使得即使在高采样率的流水线中也能更有效地生成精确的指标。
遗憾的是,并没有万全之策。前进的方向在于融合更完善的工具、更智能的默认设置,以及对采样是一系列权衡取舍的清醒认识——采样并非一劳永逸,不能一劳永逸地解决。目前也有一些有趣的想法,例如“ 基于示例的存储尾部采样 ”,虽然名称略显冗长,但其原理却很简单:将所有数据“热”保存一段时间,稍后再进行采样。这可以通过 OpenTelemetry Collector 相对容易地实现,它将传入的数据复制到一个生命周期短、精度全高的数据流中,并使用本文中介绍的其他技术生成一个采样数据流。
9. 确保 Kubernetes 生产环境中的调试安全
Securing Production Debugging in Kubernetes
背景
在生产环境调试期间,最快的方法通常是使用广泛的访问权限,例如 cluster-admin (一种授予管理员级别访问权限的集群角色)、共享堡垒机/跳转服务器或长期有效的 SSH 密钥。这种方法虽然短期有效,但存在两个常见问题:审计变得困难,而且临时异常很容易变成常规问题。
适用于现有 Kubernetes 环境的最佳实践建议
- 在 Kubernetes RBAC 之上使用访问代理
- 短期、与身份绑定的凭证
- 使用即时访问网关运行调试命令
10. Prometheus 中的未缓存 I/O
Prometheus 会向磁盘写入大量数据。毕竟,它是一个数据库。但并非每次写入都适合缓存到页面缓存中。压缩写入就是一个最明显的例子:一旦写入一个数据块,只有一小部分数据可能很快会被再次查询,而且由于无法预测具体是哪一部分,因此全部缓存意义不大。use -uncached-io 特性标志正是为了解决这个问题而设计的。
绕过缓存进行这些写入操作可以减少 Prometheus 的页面缓存占用,使其内存使用情况更可预测,也更容易理解。此外,它还能减轻共享缓存的压力,降低查询和其他读取操作所依赖的热数据被驱逐的风险。另一个潜在的好处是减少了缓存分配和驱逐带来的 CPU 开销。整个过程中的硬性限制是避免 CPU 或磁盘 I/O 出现任何可衡量的下降。
该标志是在 Prometheus v3.5.0 中引入的,目前仅支持 Linux。其底层使用直接 I/O,这需要适当的文件系统支持以及内核版本 v2.4.10 或更高版本,不过应该没问题,因为该版本发布至今已有近 25 年了。
11. 为什么扁平化的 Kubernetes 网络在大规模部署时会失败
Why flat Kubernetes networks fail at scale
背景
Kubernetes 网络功能强大。它的灵活性使团队能够跨命名空间、集群和环境连接数百个微服务。但随着平台的发展,这种灵活性也可能将原本简洁的架构变成错综复杂、脆弱不堪的系统。
Kubernetes NetworkPolicy 为团队提供了一种控制工作负载之间流量的方法。默认情况下,所有策略都处于同一级别,没有内置的可管理优先级。这种方法在小型单团队集群中行之有效。但在大型多团队环境中,很快就会变得风险重重。
在扁平化模型中,安全管理是通过例外情况而非强制执行来实现的。保护关键服务通常意味着列出所有允许的连接,并祈祷不会有其他连接意外地覆盖这些连接。随着策略的增多,越来越难以预测更改后会发生什么。
解决方案
解决方案的原则很简单:引入层级结构。安全层级结构为网络策略赋予了明确的顺序和职责分离。策略不再是在同一层级上相互竞争,而是根据优先级和用途进行分组和评估。
常见模式包括:
- 平台层级 —— 集群服务所需的连接
- 安全层级 —— 强制性控制措施,例如出口限制或拒绝规则
- 应用层 —— 开发者管理的用于服务通信的规则
- 数据或基础设施层 —— 保护数据库等高价值工作负载
层级结构使策略意图清晰明确,并减少了意外覆盖。全局规则得到一致执行,同时团队在既定边界内保持自主权。这种方法也符合零信任原则 ,即访问权限被明确授予并持续评估,即使在集群内部也是如此。
仅仅依靠层级结构是不够的。团队还需要安全的方式来测试新策略。在传统网络中,验证通常是在流量中断后才进行的。但在云原生环境中,这种方法已不再适用。策略模拟或试运行模式正逐渐成为一种最佳实践。在这种模式下,策略会被部署,但不会实际执行。系统会观察流量并报告哪些流量会被允许或拒绝。
12. 别再把“Pod 重启”说错了:Kubernetes 重启机制全解析
别再把“Pod 重启”说错了:Kubernetes 重启机制全解析
术语问题
“Pod 重启了”往往指的是四种完全不同的情况。
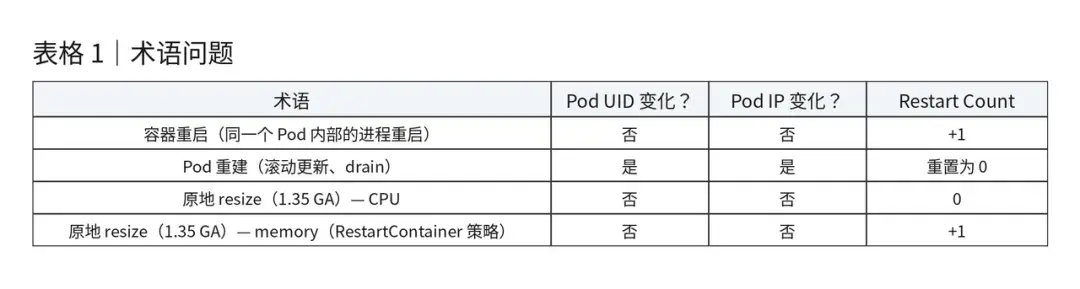
核心洞察:kubelet 实际上在看什么
kubelet 观察的是 Pod Spec——不是 ConfigMap,不是 Secret,也不是 Istio 的 CRD。如果 Pod Spec 没有变化,kubelet 就不会触发任何动作。这一个事实,解释了生产环境里绝大多数“为什么我的配置没有更新?”的排查问题。
可变更的准入 Webhook 可以在创建时修改 Pod Spec,但在准入完成之后就不行了——它们无法在 Pod 创建后触发容器重启。
决策矩阵
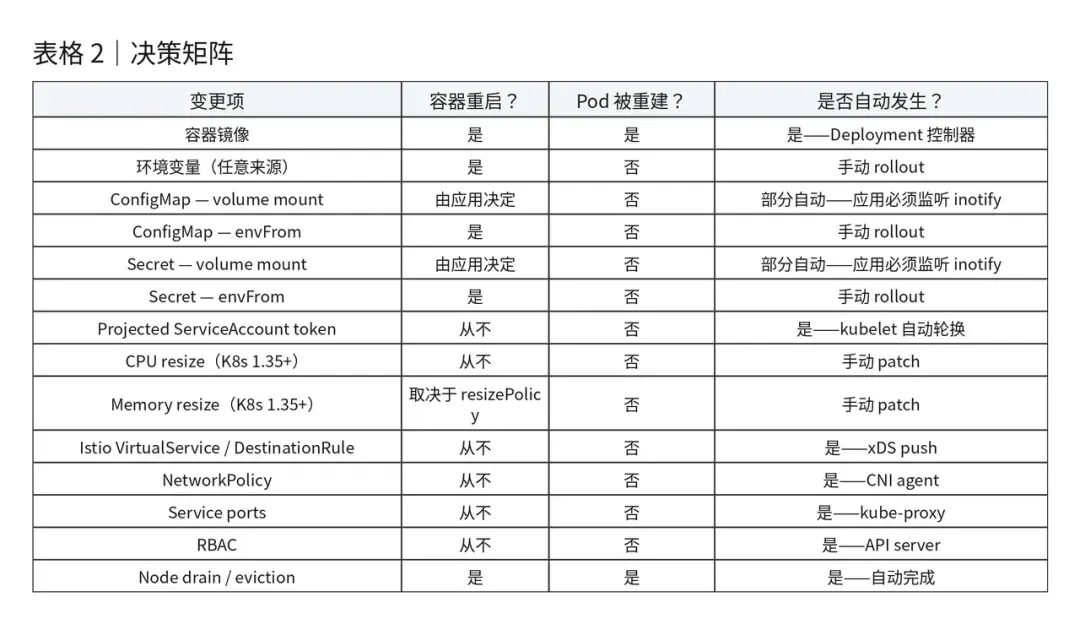
场景介绍
见原文。
13. 理解 Kubernetes 指标:实现高效监控的最佳实践
什么是 Kubernetes 指标(Metrics)?
Kubernetes 指标,是用来反映 Kubernetes 环境中各类对象运行情况的数据。它们能够帮助你了解集群是否健康、资源是否充足、控制面是否正常工作,以及 Pod 和应用是否处于稳定状态。
对于生产环境来说,指标的价值主要体现在几个方面:
- 发现性能瓶颈
- 提前识别异常和故障征兆
- 判断是否需要扩容或优化资源配置
- 为排障提供依据
- 帮助团队持续优化系统稳定性和运行效率
Kubernetes 指标的常见类型
集群指标(Cluster Metrics)
- 节点 CPU 资源使用率
- 节点内存使用情况
- 节点磁盘使用情况
节点指标(Node Metrics)
- 磁盘 I/O 与可用磁盘空间
- 网络带宽使用情况
控制面指标(Control Plane Metrics)
- API Server 请求延迟
- Scheduler 队列长度
Pod 指标(Pod Metrics)
- Pod 重启次数(Pod Restart Count)
- Pending Pod 数量
- Pod 状态(Pod Status)
如何在 Kubernetes 中采集指标?
- Metrics Server
- cAdvisor
- Kube-State-Metrics
📄 专题四报告查看与分析
1. Kubernetes 日志收集器基准测试:vlagent、Vector、Fluent Bit、OpenTelemetry Collector 等
基准(Benchmark)
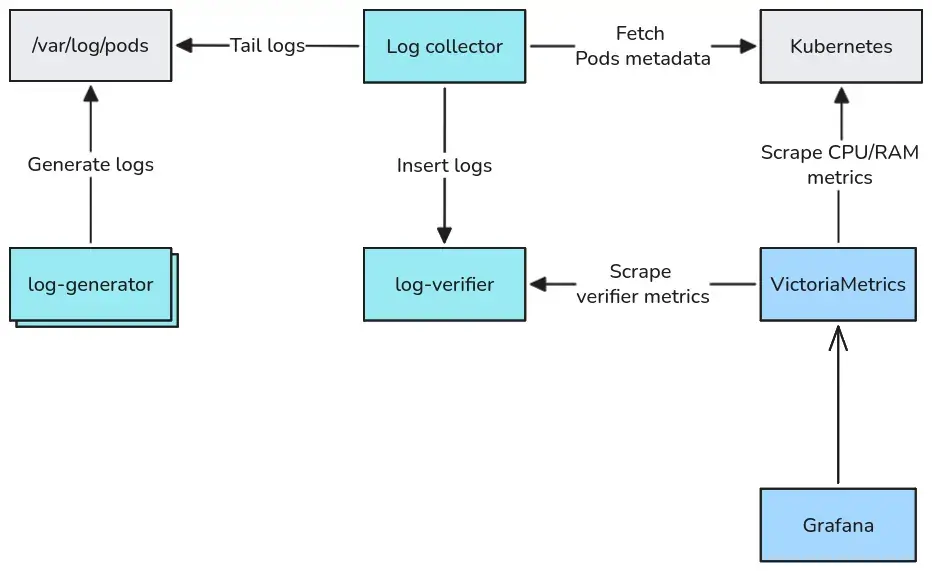
该基准测试由四个部分组成:
- log-generator:是一个部署为多个 Pod 的程序,每个 Pod 以可配置的速率向标准输出 (stdout) 写入 JSON 日志记录。每条记录包含一个 sequence_id (单调递增的整数)、时间戳以及 Kubernetes 应用中结构化日志中常见的随机字段子集,例如:日志级别、组件名称、HTTP 方法、状态等。平均记录大小约为 216 字节。
- Log collector:日志采集器。Tails 会从 /var/log/pods 或 /var/log/containers 中获取 Pod 日志。解析由日志生成器 Pod 生成的 JSON 编码的日志条目内容,并将记录发送给日志验证器。 使用收集器特定的协议: JSON 行 (vlagent, Vector, Fluent Bit, Fluentd), Loki (Alloy, Grafana Agent, Promtail), Elasticsearch (Filebeat), OpenTelemetry (OpenTelemetry Collector)。
- log-verifier:日志验证器接收来自收集器的日志,支持上述所有协议。对于每个收集器和 Pod 对,它会跟踪观察到的最大 sequence_id 和接收到的日志总数。由于 sequence_id 从 1 开始并严格递增 1,因此这两个值之间的任何差距都表示日志丢失。它还会以直方图的形式跟踪日志传递延迟(即日志记录生成到到达日志验证器之间的时间)。所有指标均通过 Prometheus 公开。
- VictoriaMetrics + Grafana:收集和可视化容器 CPU/内存指标和日志验证器输出。
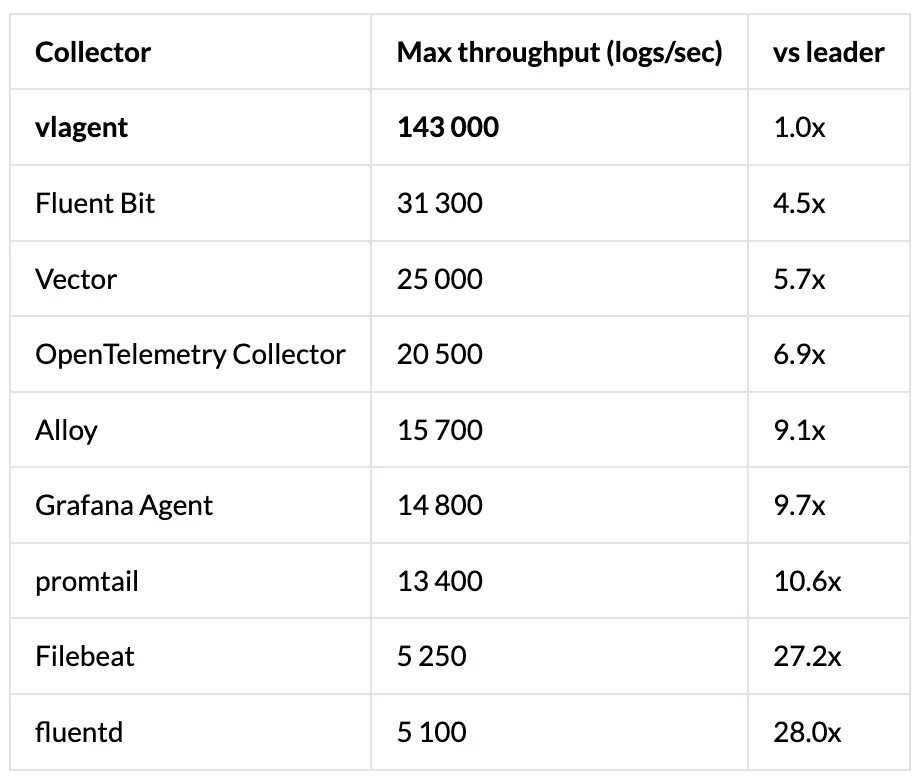
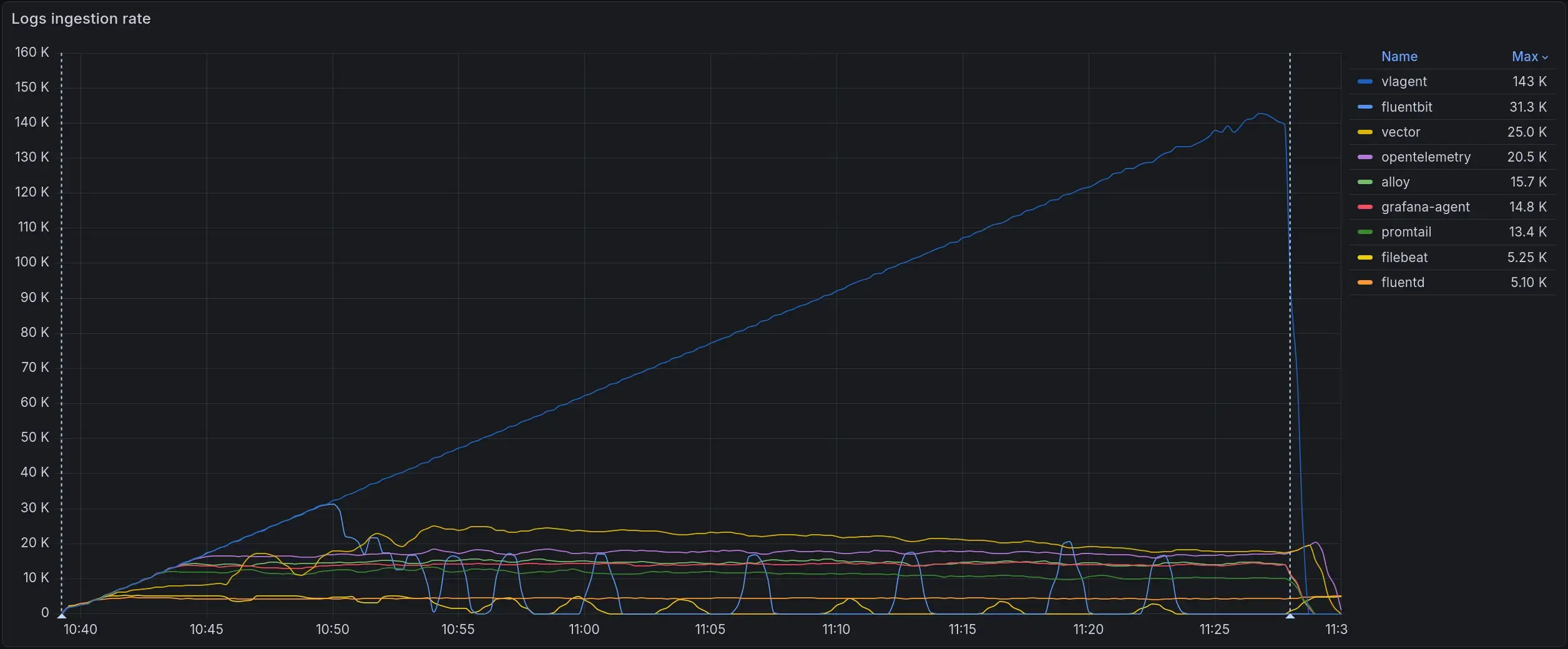
吞吐量结果
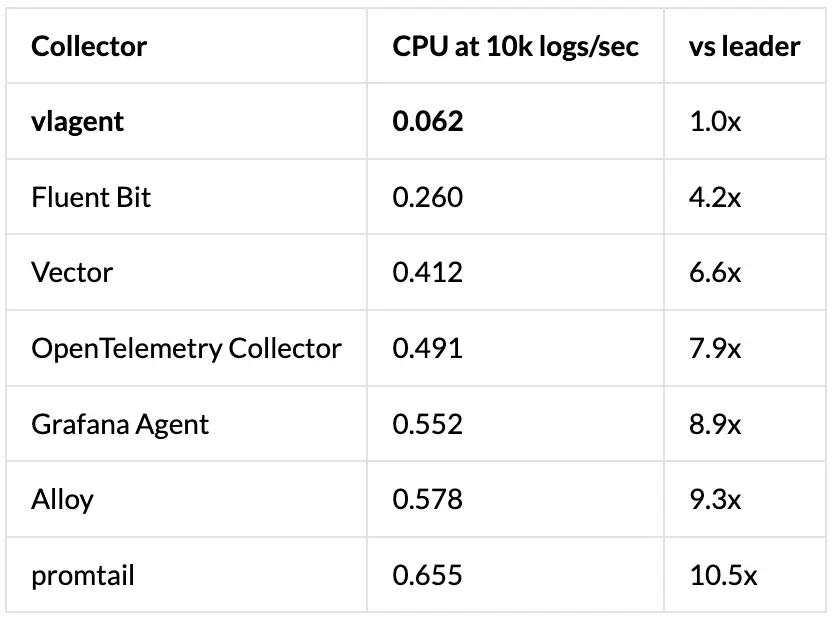
CPU 使用率
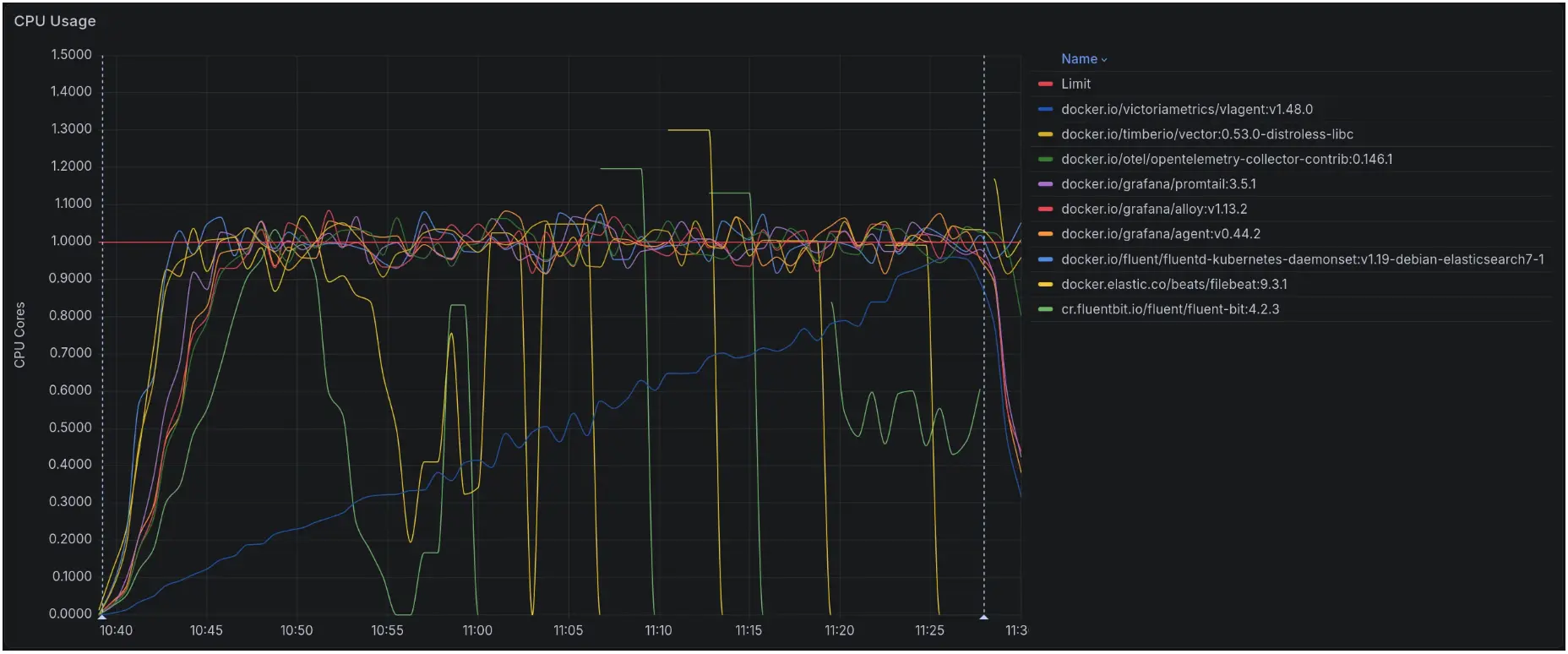
内存使用情况
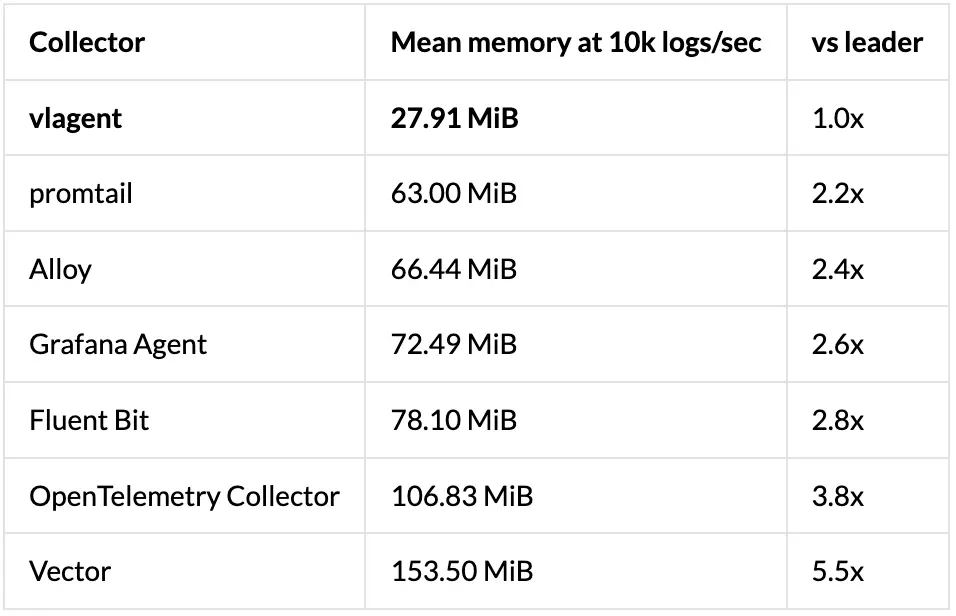
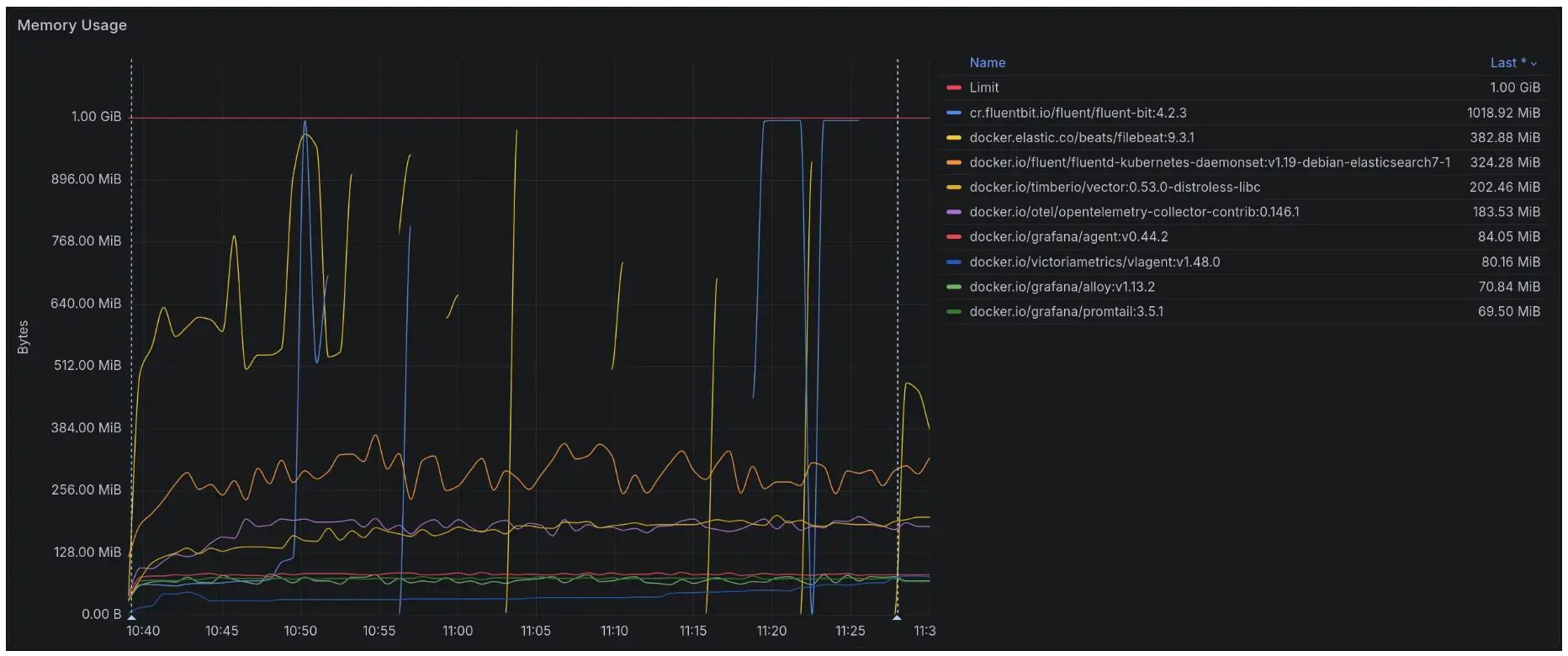
更多细节见原文。