🆕 专题一 产品新功能/新版本
1. OpenStack 最新版 Flamingo:减少技术债务,提升性能
OpenStack Flamingo Reduces Technical Debt, Boosts Performance
简介
OpenStack 最初于 2008 年由 NASA Ames 研究中心、Rackspace 和 Anso Labs 共同创建,旨在提供一个开源的 IaaS 云解决方案。
Flamingo 版本由来自 BBC R&D、爱立信、NVIDIA、Rackspace、Red Hat、三星 SDS、SAP 和沃尔玛等组织的 480 名贡献者完成,集成了近 8,000 项代码变更。
主要更新
- 大规模移除了 Eventlet(一个 Python 并发库,它已成为 OpenStack 近 18 年的基础),从 Nova 和 Neutron 中移除 Eventlet 方面也取得了进展。
- Nova 支持一次性直通设备和 AMD SEV-ES 安全区域支持。
- Magnum 支持 Kubernetes 集群的凭证轮换(云原生部署的一项关键安全功能)。
- Manila 支持文件服务器自带加密密钥。
- Horizon 引入二维码登录进行双因素身份验证,简化了安全的云操作。
- 通过 Flamingo 引入“非跨级升级发布流程 (SLURP)”,即每六个月发布一次。
SLURP
Release Cadence Adjustment: SLURP Model
很难通过任何一项发布节奏的调整来解决上述所有问题和顾虑。因此,技术委员会 (TC) 建议逐步调整发布升级预期,以改善部署缓慢的体验,同时又不牺牲“尽早发布,频繁发布”的目标。
根本性的变化在于,升级将不再仅支持相邻协兼容本之间的升级。技术委员会 (TC) 将以新的安排指定主要版本,以便每隔一个版本都被视为“SLURP(Skip Level Upgrade Release Process,跳级升级发布流程)”版本。除了相邻主要版本之间的升级(目前的做法),还将支持“SLURP”版本之间的升级。
希望保持六个月升级周期的部署,将像往常一样推出每一个 SLURP 和“非 SLURP”版本。希望转向一年升级周期的部署(SLURP 之间)。
2. 适用于 Karpenter 的 Headlamp 插件 - 缩放和可见性
Introducing Headlamp Plugin for Karpenter - Scaling and Visibility
简介
- Headlamp 是一个开源、可扩展的 Kubernetes SIG UI 项目,旨在让您探索、管理和调试集群资源。
- Karpenter 是一个 Kubernetes Autoscaling SIG 节点配置项目,可帮助集群快速高效地扩展。它可在几秒钟内启动新节点,为工作负载选择合适的实例类型,并管理完整的节点生命周期(包括缩容)。
全新 Headlamp Karpenter 插件可直接从 Headlamp UI 实时查看 Karpenter 的活动。它展示了 Karpenter 资源与 Kubernetes 对象的关系,显示实时指标,并实时呈现扩展事件。您可以在配置期间检查待处理的 Pod,查看扩展决策,并使用内置验证功能编辑 Karpenter 管理的资源。
Headlamp 的 Karpenter 插件旨在帮助 Kubernetes 用户和运维人员更轻松地理解、调试和微调其集群中的自动扩缩行为。
功能介绍
Karpenter 资源的地图视图及其与 Kubernetes 资源的关系
了解 Karpenter 资源(如 NodeClasses、NodePool 和 NodeClaims)如何与核心 Kubernetes 资源(如 Pods、Nodes 等)连接。

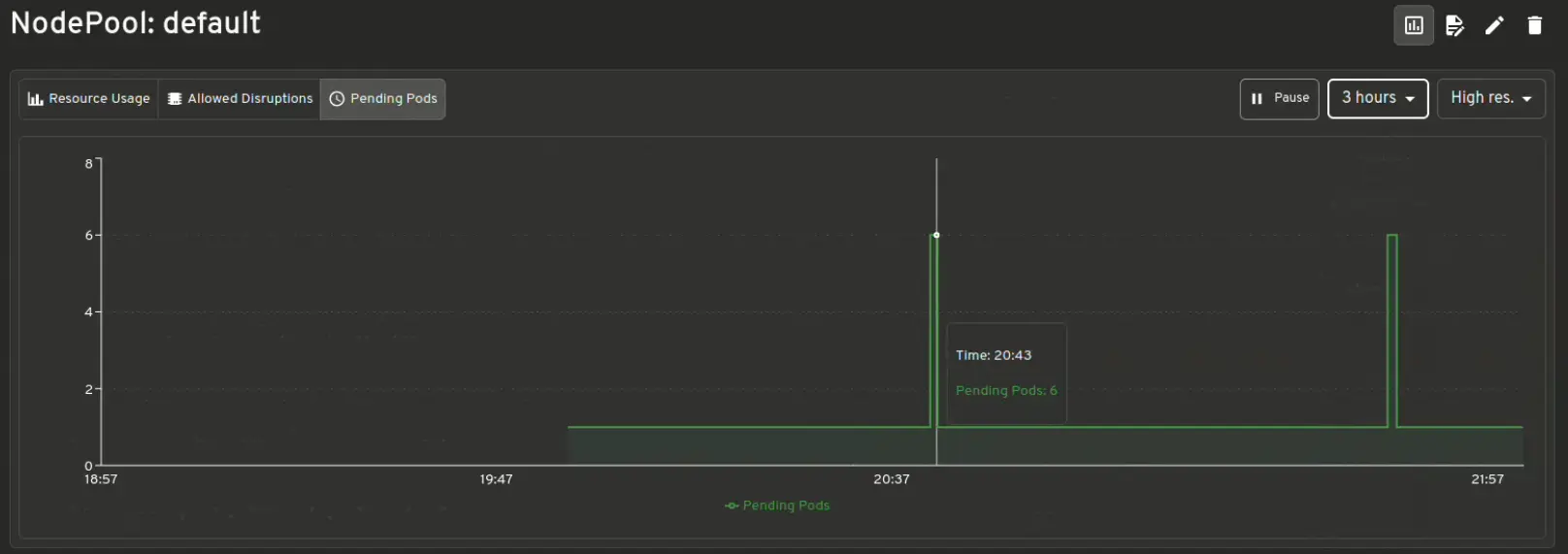
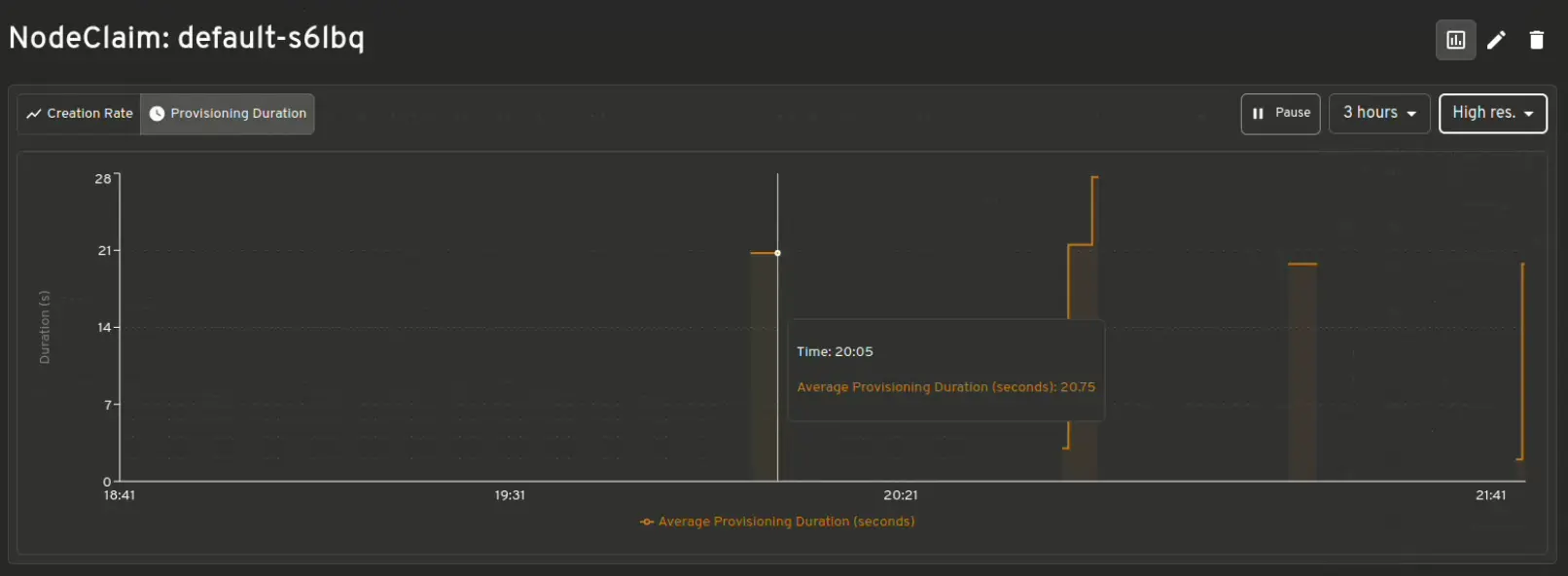
Karpenter 指标的可视化
即时了解资源使用情况与限制、允许中断、待处理 Pod、配置延迟等。
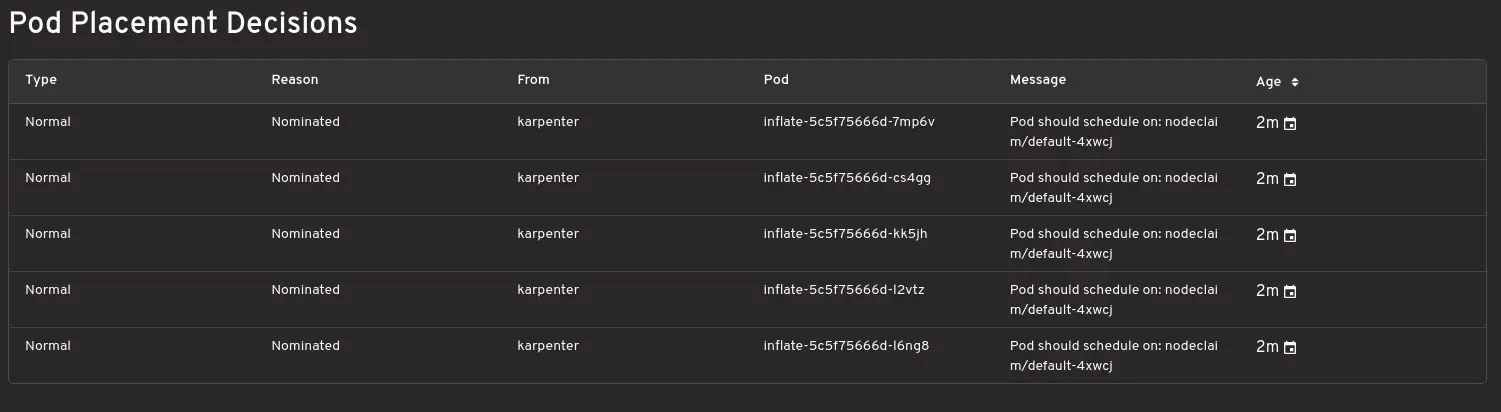
扩展决策
显示哪些实例正在为您的工作负载进行配置,并了解 Karpenter 做出这些选择的原因。这在调试时非常有用。

具有验证支持的配置编辑器
实时编辑 Karpenter 配置。编辑器包含差异预览和资源验证功能,以便更安全地进行调整。
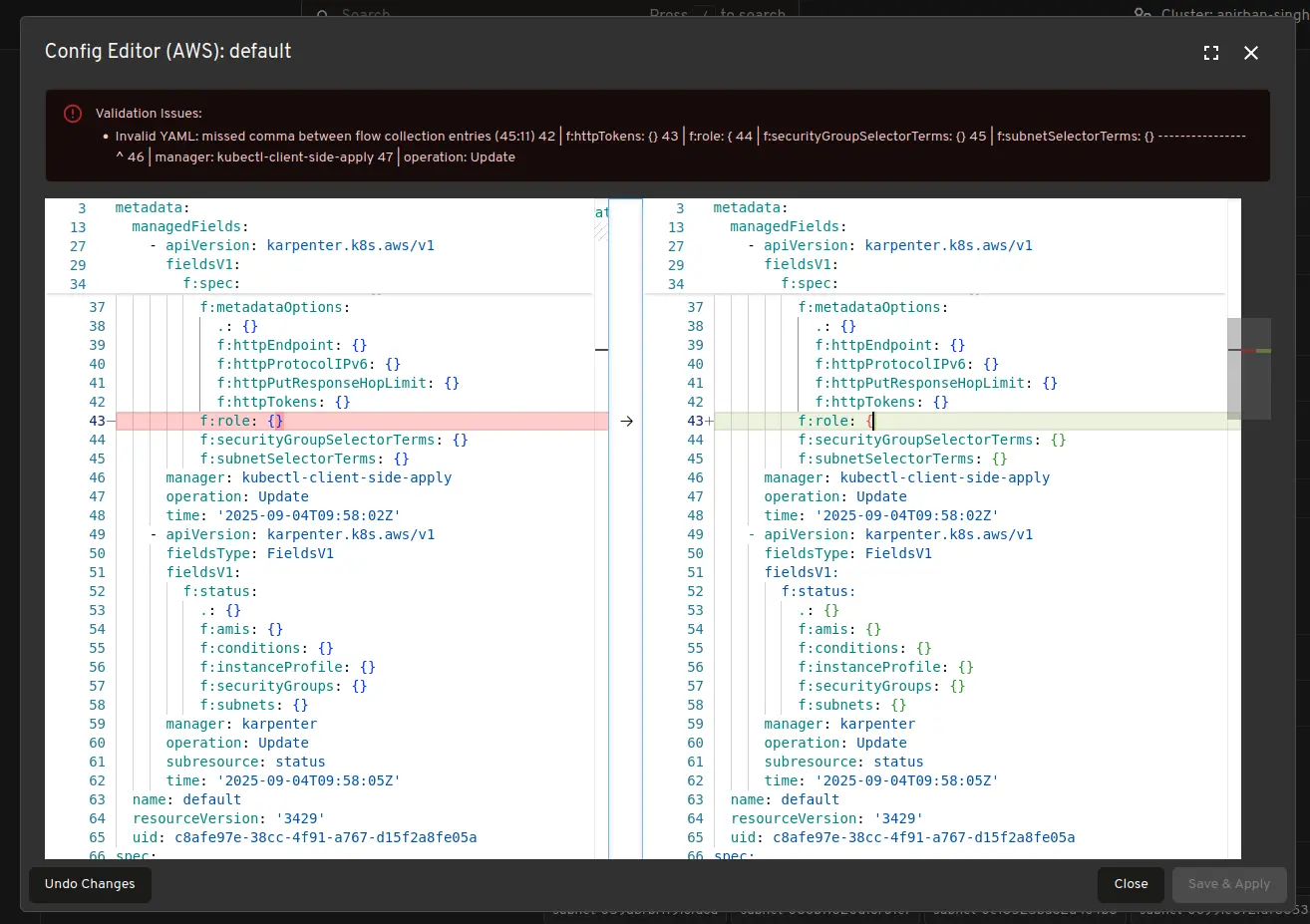
实时查看 Karpenter 资源
随着集群规模的扩大和缩小,实时查看和跟踪 Karpenter 特定资源,例如“NodeClaims”。



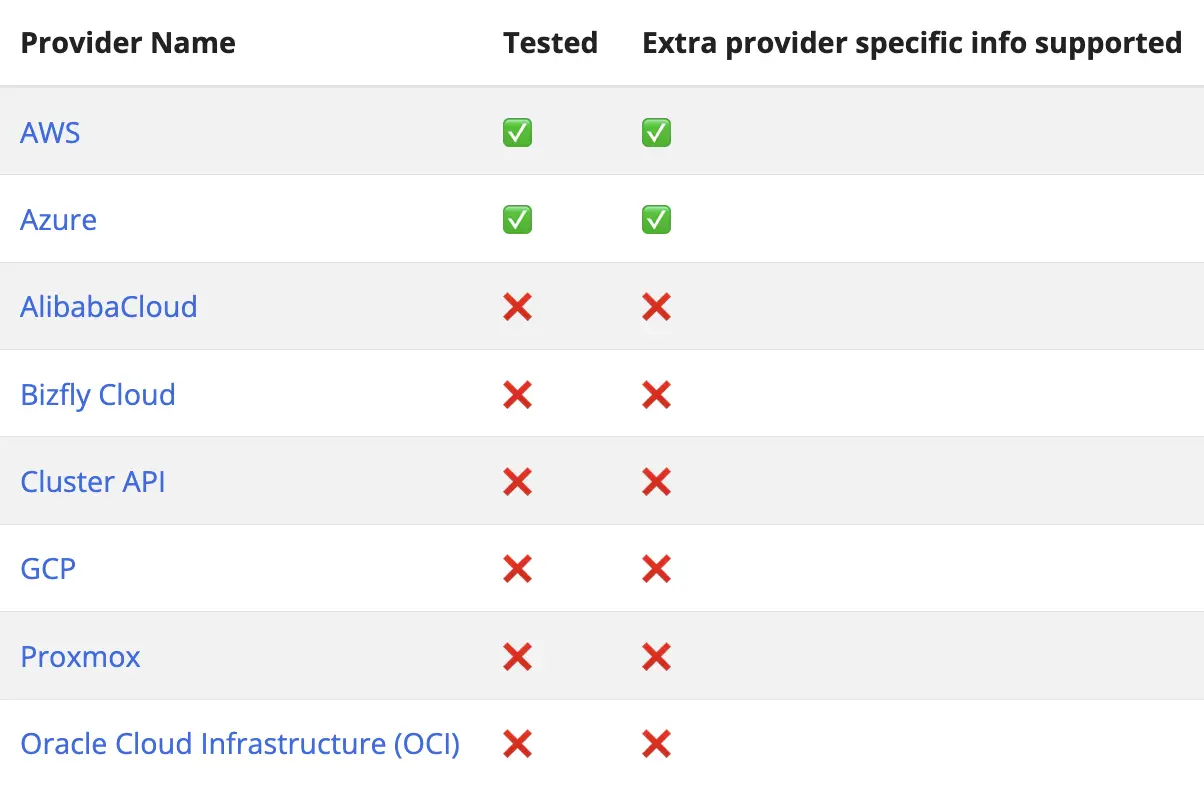
待处理 Pod 的仪表板
查看所有未满足调度要求/调度失败的待处理 pod,突出显示无法调度它们的原因。
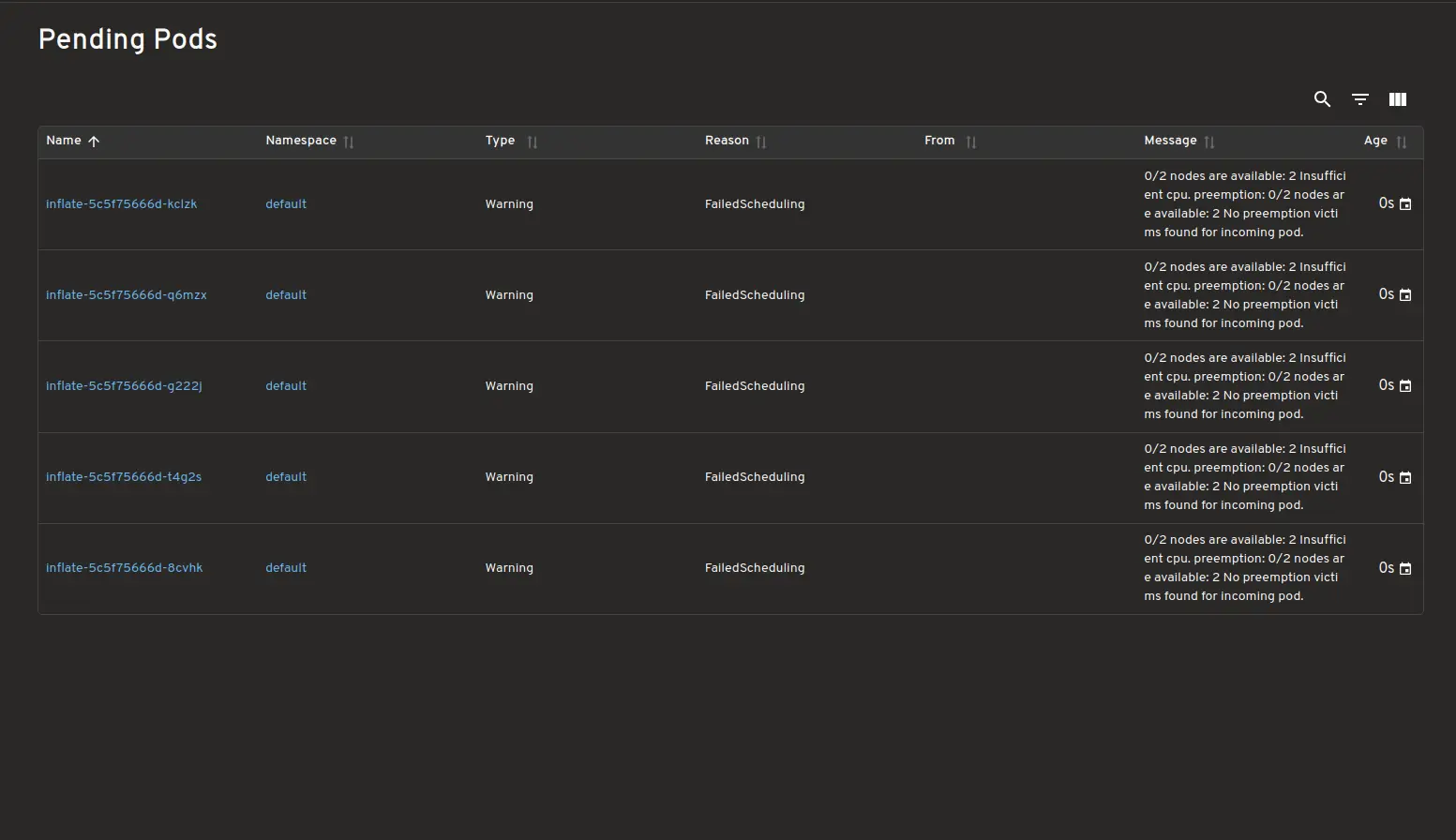
Karpenter 提供商
此插件应该适用于大多数 Karpenter 提供商,但目前仅在表格中列出的提供商上进行了测试。此外,每个提供商都会提供一些额外的信息,下表中的信息由插件显示。
拓展阅读
3. HAMi v2.7.0:芯片与调度 | 更强、更智能、更广泛
HAMi v2.7.0 — Of Silicon & Scheduling | Stronger, Smarter, Broader.
发布亮点
- 更广泛的硬件覆盖范围:新增了适用于全设备、虚拟化和拓扑感知模式的多个异构加速器的后端。NVIDIA 拓扑感知调度已升级; AWS Neuron 已从设备级共享集成到核心级共享,并具备拓扑感知功能。
- 调度程序核心:故障事件聚合、异常 NVIDIA 卡的隔离以及正确考虑多 GPU 内存/计算请求的扩展 ResourceQuota ,从而提高可观察性和稳健性。
- 应用生态系统:增强的 vLLM 兼容性、 Xinference Helm 与 HAMi vGPU 的集成以及 Volcano Dynamic MIG 。
- 社区:新的维护者/审阅者;CNCF 案例研究和生态系统讨论强调了现实世界的采用。
- WebUI:更清晰的异构 GPU 遥测,可实现更快的分类和容量洞察。
4. Volcano v1.13 发布,增强大模型训练与推理等调度能力
Volcano v1.13 重磅发布!大模型训练与推理等调度能力全面增强
发布亮点:
- 大模型推理场景支持 LeaderWorkerSet
- 新增 Cron Volcano Job
- 支持基于 Label 的 HyperNode 自动发现机制
- 原生支持 Ray 框架
- 新增 HCCL 插件支持
- 增强 NodeGroup 功能
- 新增 ResourceStrategyFit 插件
- 实现混部与 OS 解耦
- 支持自定义混部超卖资源名称
- 将网络拓扑感知调度能力扩展至 Kubernetes 标准工作负载
- 适配 Kubernetes 1.33
📰 专题二 新闻与访谈
1. Dell 从 GitHub 仓库中撤下了 CSI 驱动程序的源代码
戴尔似乎悄悄地从他们的 GitHub 仓库中撤下了 CSI 驱动程序(PowerStore、PowerFlex、PowerMax 等)的源代码。现在,他们只分发预编译的闭源容器镜像。
2. CNCF 宣布 Knative 毕业
毕业标志着 Knative 已准备好广泛投入生产使用,未来将推出新功能,旨在连接遗留系统,扩展 AI 和云原生集成。
主要亮点:
- 云原生计算基金会(CNCF)宣布 Knative 毕业,Knative 是一个 Kubernetes 原生的无服务器和事件驱动应用平台,标志着其已达到广泛生产使用的成熟阶段。
- Knative 简化了在 Kubernetes 上运行现代工作负载的复杂性,自动处理自动扩缩、路由和事件传递等基础设施任务,帮助组织降低成本、提升效率,加速创新。
- 开发者能更快上手 Kubernetes,平台团队简化运维,企业和初创公司都能更轻松地与 AI 和云原生技术集成。
- Knative 现已成为 CNCF 毕业项目,今天即可用于生产环境。
Knative 是一个基于 Kubernetes 的平台,提供一整套用于构建、部署和管理现代无服务器工作负载的中间件组件。Knative 扩展了 Kubernetes,提供了更高级别的抽象,从而简化了云原生应用程序的开发和运维。
3. KubeSphere 社区版发布
KubeSphere 社区版重磅发布:永久免费,秒享企业级容器管理!
KubeSphere 社区版包含了构建和管理云原生容器平台的核心能力:
- 统一管理:支持集群管理、细粒度 RBAC 访问控制、多租户隔离体系,满足企业级权限与资源治理需求。
- 强大可观测性:提供多维度的监控、告警、通知功能,集群与应用状态一目了然,故障排查效率显著提升。
- 高效运维:涵盖应用全生命周期管理、DevOps 流水线、灵活的存储与网络方案,让运维团队专注业务价值创造。
KubeSphere 社区版精心筛选并集成了 18 个扩展组件,覆盖可观测性、DevOps、安全治理、AI 推理、服务网关、数据库运维等关键领域:
- 可观测性体系
- WizTelemetry 平台服务
- WizTelemetry 监控
- WizTelemetry 告警
- WizTelemetry 通知
- WizTelemetry 数据流水线
- Grafana for WizTelemetry
- Grafana Loki for WizTelemetry
- Metrics Server
- 网关与流量管理
- KubeSphere 网关
- Higress(云原生 API 网关)
- DevOps 与持续交付
- DevOps(完整 CI/CD 流水线)
- 安全与合规
- Gatekeeper(策略引擎)
- cert-manager(证书管理)
- AI 与 GPU 支持
- NVIDIA GPU Operator
- DeepSeek(AI 推理)
- 数据管理与存储
- ob-operator(OceanBase Operator)
- oceanbase-dashboard(OceanBase 管理面板)
- Fluid(数据集编排与加速)
4. Helm 十周年
十年前,在 Kubernetes 1.1.0 发布不久的一次黑客松中,Helm 诞生了。
祝 Helm 十岁生日快乐!

💬 专题三 讨论与分享
1. Kubernetes 状态备份和恢复实用指南
A Practical Guide to Kubernetes Stateful Backup and Recovery(Andela 赞助)
背景
有状态应用程序中的数据丢失可能造成灾难性的后果。与无状态应用程序不同,无状态应用程序不需要持久存储,并且可以轻松扩展和随时替换,因此,为有状态应用程序制定经过测试且可靠的备份和恢复策略至关重要。有状态应用程序的示例包括:
- 数据库:MySQL、MongoDB 和 PostgreSQL
- 内存缓存:Redis、RabbitMQ
- 存储系统:Elasticsearch、Cassandra
Kubernetes 中的 StatefulSet 是用于管理有状态应用程序的工作负载 API 对象。StatefulSet 为 Pod 提供了维护粘性身份、唯一网络身份、持久卷 (PV) 和持久卷声明 (PVC) 的功能。StatefulSet 可以更轻松地获取每个 Pod 的身份,从而简化数据库备份和恢复。
有状态应用的备份策略
1. 卷快照
Kubernetes 内置支持通过容器存储接口 (CSI) 快照 API 管理卷快照,该 API 可与云环境中的存储无缝集成。
需要考虑的卷快照工具:
- Velero,一款流行的开源工具,用于执行 Kubernetes 资源(例如 PVC 和 PV)的备份、恢复和迁移。它还可以执行计划备份并与主流云提供商集成。
- Kubernetes Cron Job,创建一个 Kubernetes cron 作业资源,用于安排定期任务执行 rsync 命令。rsync 工具会将数据从 PV 同步或备份到备份位置,例如外部存储、云存储或其他 PV。
2. 应用程序级备份
有状态的应用程序(尤其是数据库)需要持续的日常备份。简单的复制数据可能会导致数据损坏,因此最好使用数据库的内置工具执行备份。
需要考虑的数据库备份工具:
- PostgreSQL:使用 pg_dump。
- MySQL:使用 mysqldump。
- 使用 Velero 进行定期备份。
3. 增量和差异备份
如果数据库非常庞大,执行增量备份和差异备份会非常方便。增量备份和差异备份只会备份更改的数据,从而节省时间、带宽和存储空间。
- 增量备份:捕获自上次备份以来的变化。
- 差异备份:捕获自上次完整备份以来的变化。
需要考虑的增量和差异备份工具:
- Restic 支持高效且加密的增量备份。
- BorgBackup 可用于备份节点上的 Kubernetes 卷。
4. 异地和多区域备份
为了防止数据库位置出现单点故障并防止数据库位置发生故障,请将备份存储在异地或多个区域。
有状态应用的恢复策略
1. 从卷快照还原
在尝试还原之前,需要验证卷快照的完整性。
2. 应用程序级恢复
使用数据库提供的内置工具执行数据库还原。只能使用这些工具来还原使用相同工具创建的备份。
3. 使用 Velero 进行完整的 Kubernetes 恢复
Velero 可以备份和恢复 Kubernetes 资源。可以使用 Velero 恢复 Kubernetes 资源,例如 StatefulSet、ConfigMap、Kubernetes Secret、PV 和 PVC。
一旦所有资源成功恢复,就可以重新连接 PV。
推荐的备份和恢复最佳实践
- 执行定期、预定的备份和保留策略。
- 定期组织备份测试(备份恢复),以验证其完整性和真实性。该测试可以自动化,并生成分析报告。
- 监控备份失败并发送警报。可以使用 Nagios 或 Datadog 等工具来执行备份监控。
- 记录恢复过程。
- 为了安全起见,对备份使用加密。
2. Kubernetes 1.34 带来的盲点
Kubernetes v1.34 Introduces Benefits but Also New Blind Spots
动态资源分配
它为 Kubernetes 集群在调度 GPU、TPU 和其他专用设备时提供了更大的灵活性。
但这种灵活性也增加了复杂性。更多的调度逻辑意味着更多地方容易出现错误配置。应用程序可能会请求无法满足的资源,从而导致调度延迟或回退场景与预期行为不同。从财务角度来看,过度分配 GPU 每月可能会浪费数万美元。
Linux 节点交换支持
Linux 节点交换支持可帮助节点在内存压力下保持稳定。节点可以将部分内存压力转移到磁盘,而不是在内存耗尽时导致 Pod 崩溃。
理论上,听起来像是防止内存不足事件的一种保障,但在实践中,交换机制会引入新的性能问题。过度依赖交换机制可能会掩盖内存行为不佳的工作负载,造成稳定的假象,而延迟峰值却不断增加。调整交换机制的行为需要格外小心,而内存问题的故障排除可能非常棘手,因为工程师现在必须区分物理内存压力和交换机制相关的性能下降。
Pod 级资源请求和限制
对于包含多个容器的工作负载,简化了配额管理,并降低了资源过度使用的风险。
此功能可能会掩盖每个容器的过度使用问题。如果一个容器独占资源,在 Pod 级别设置限制时,问题可能不明显。水平 Pod 自动扩缩器 (HPA) 也可能出现异常,因为它们的假设与容器级指标相关。
安全增强功能
短期令牌、外部签名和 Pod 级证书增强了合规性,并降低了长期凭证的风险。
与外部密钥管理或硬件安全模块集成会引入新的依赖项,这些依赖项必须始终可靠。如果外部签名系统出现故障,部署可能会失败。频繁的证书轮换需要自动化和警报机制,以避免凭证过期导致的中断。
存储和调度改进
卷扩展恢复和 VolumeAttributesClass 的引入使工作负载能够更动态地控制存储。更智能的 Job Pod 替换和非阻塞 API 调用减少了大型集群的瓶颈。
这些功能提供了灵活性和可扩展性,但也扩大了可能的故障模式范围。例如,当工作负载可以动态更改卷属性时,故障排除 I/O 速度变慢会变得更加困难。非阻塞 API 和流式响应虽然减轻了 API 服务器的压力,但增加了对缓存状态的依赖,这可能会造成微妙的一致性问题。
这对平台工程师意味着什么?
在部署每个新功能之前,平台工程师应该问自己三个问题:
- 必须捕捉哪些新指标?
- 引入了哪些新的故障模式?
- 当出现问题时谁负责补救?
拓展阅读
Kubernetes 1.34 Features Explained: Faster, Safer, and Cheaper Clusters
3. [Andela] 从 Cluster Autoscaler 迁移到 Karpenter v0.32
Migrating From Cluster Autoscaler to Karpenter v0.32
Cluster Autoscaler 和 Karpenter 都是开源 Kubernetes 自动伸缩器,为什么需要迁移?
最新的 Karpenter 架构解决了传统自动缩放带来的许多问题:
- 现在一切都变得合理了:NodePool 负责处理何时以及如何扩展,而 EC2NodeClass 负责处理 AWS 的具体细节。这意味着不再需要处理六个月后仍然无人理解的复杂配置。
- 一次编写,随处可用:创建一个 EC2NodeClass 模板,并在多个 NodePool 之间共享。当您不再需要复制粘贴配置时,您将来会感谢自己。
- 你的钱包会注意到:Karpenter 会在你需要的时候精准地启动你所需的资源,并且毫不犹豫地使用竞价实例来大幅降低成本。此外,扩展只需几秒钟。
更多具体操作等内容见原文。
4. [Datadog] 每个 DevOps 团队都应该跟踪的 15 个 Kubernetes 指标
15 Kubernetes Metrics Every DevOps Team Should Track
数据来源
Kubernetes 生态系统包含两个用于监控集群数据的插件:Metrics Server 和 kube-state-metrics。
- Metrics Server 公开有关 Kubernetes 对象资源使用情况的统计数据,报告各个节点、Pod 和集群对内存、磁盘、CPU 等的需求。
- kube-state-metrics 报告 Kubernetes 对象的更广泛状态,使集群状态信息更易于通过节点状态、节点容量、pod 状态等指标来使用。
可以通过命令行或 Kubernetes Dashboard(一个基于 Web 的 UI,可显示来自容器化环境的最近几分钟的数据)访问 Metrics Server 和 kube-state-metrics。
15 个关键指标
集群状态指标
集群状态指标提供集群状态的概览视图,包括各种 Kubernetes 对象的数量、运行状况和可用性。它们可以快速发现节点或 Pod 的问题,帮助 DevOps 团队确保应用程序的可靠性、支持故障排除并实现高效的扩展。
1 节点状态
节点状态指标提供有关集群内节点的运行状况和可用性的信息,指示调度程序是否可以将 Pod 放置在节点上。它会对以下节点状况运行检查,每个检查都会返回 true、false 或 unknown:
– OutOfDisk
– Ready(节点已准备好接受 Pod)
– MemoryPressure(节点内存过低)
– PIDPressure(正在运行的进程过多)
– DiskPressure(剩余磁盘容量过低)
– NetworkUnavailable

2 预期 vs. 当前的 Pod
Kubernetes 提供的指标反映了所需 Pod 数量和当前正在运行的 Pod 数量。通常情况下,这些数字应该匹配,因此建议设置警报来标记它们之间的任何差异。
如果差异较大,则表明配置存在问题,或者节点存在瓶颈,导致资源不足,无法调度新的 Pod。无论哪种情况,检查 Pod 日志都可以帮助找到根本原因。

3 可用和不可用的 Pod
如果发现不可用 Pod 的数量激增,这可能会影响应用程序的性能和正常运行时间,并可能表明出现崩溃、调度问题或资源短缺,因此密切监控此指标非常重要。
大量 Pod 持续不可用可能意味着它们的配置存在问题,例如它们的就绪性探测。检查 Pod 的日志可以找到它卡在不可用状态的原因。

资源指标
集群状态指标报告的是 Kubernetes 对象的状态,而资源指标则能洞察其资源使用情况。监控集群不同层的内存、CPU 和磁盘使用情况,可以帮助检测和排查应用程序和系统级别的问题。通过了解环境的资源使用效率,可以更好地规划容量,并防止 Pod 崩溃、瓶颈和停机。
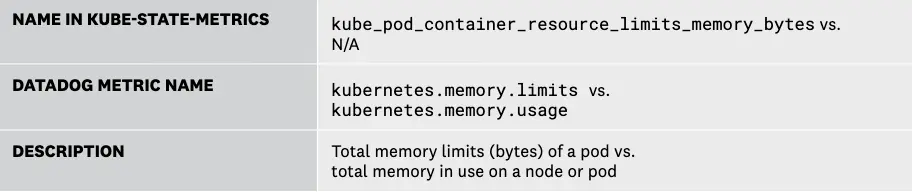
4 每个 Pod 的内存限制与每个 Pod 的内存利用率
对于 Pod 上运行的每个容器,可以声明内存使用请求和限制。务必主动将配置的内存限制与 Pod 的实际内存使用情况进行比较。如果 Pod 使用的内存超过其定义的限制,它将被 OOMKilled,导致容器重启时出现停机;如果内存累积速度过快,甚至可能触发 CrashLoop 状态。
另一方面,将 Pod 的限制设置得太高可能会导致糟糕的调度决策。例如,一个内存请求为 1GiB、限制为 4GiB 的 Pod 可以调度到具有 2GiB 可分配内存的节点上。这足以满足其请求。但是,如果 Pod 突然需要 3GiB 内存,即使它远低于内存限制,它也会被终止。
5 内存利用率
除了关注实际内存使用情况与配置限制的对比情况外,在 Pod 和节点级别监控内存使用情况也很重要。超出内存限制的 Pod 将被 OOMKilled,而那些内存使用量明显超过设置的请求量的 Pod 也面临被终止的风险 —— 即使它们保持在分配的限制范围内。
例如,如果某个节点的可用内存不足,kubelet 会将其标记为内存压力并开始回收资源,优先驱逐超出其定义内存请求的 Pod。

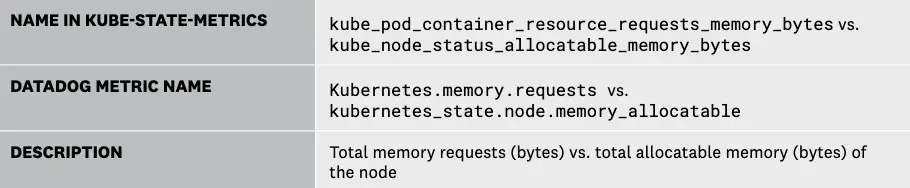
6 每个节点的内存请求 vs. 每个节点的可分配内存
可分配内存反映了节点上可供 Pod 使用的内存量。具体来说,它会从总容量中减去操作系统和 Kubernetes 系统进程的内存需求,以确保它们不会与用户 Pod 争夺资源。
虽然内存容量是一个静态值,但监控 Pod 内存请求与节点可分配内存之间的关系对于容量规划至关重要。生成的指标可以告知节点内存是否足以满足当前 Pod 的需求,以及控制平面是否能够调度新的 Pod。例如,如果运行的 Pod 数量少于预期,那么查看此指标可能是故障排除工作的良好开端。
7 磁盘利用率
磁盘空间与内存一样,在 Kubernetes 中是一种不可压缩的资源。如果节点的根卷磁盘空间不足,则可能会触发调度问题。当磁盘空间低于阈值时,该节点会被标记为磁盘压力过大,从而促使 kubelet 运行垃圾回收,移除未使用的镜像或死容器。如果空间仍然有限,kubelet 将开始驱逐 Pod —— 因此,主动监控磁盘利用率至关重要。
除了节点级别的磁盘使用情况外,跟踪 Pod 的卷级别磁盘使用情况也很重要。如果卷空间不足,应用程序在写入数据时可能会遇到错误。因此,明智的做法是设置当卷使用率达到 80% 时发出警报,以便通过添加更多存储空间或调整请求来预防问题。

8 每个节点的 CPU 请求 vs. 每个节点的可分配 CPU
与内存一样,跟踪每个节点的总体 CPU 请求并将其与每个节点的可分配 CPU 容量进行比较对于容量规划非常有价值,可以帮助了解集群是否可以支持更多 Pod。

9 每个 Pod 的内存限制与每个 Pod 的内存利用率
与内存不同,CPU 是可压缩的,这意味着如果 Pod 超出设置的 CPU 限制,节点将限制其 CPU 使用率,而不会终止该 Pod。然而,限制仍然可能导致性能问题。通过密切关注这些指标,您可以确保 CPU 限制配置合理,以满足 Pod 的实际需求,并降低速度变慢的风险。

10 CPU 利用率
与内存一样,在 Pod 和节点级别监控 CPU 利用率也很重要。了解 CPU 使用率有助于减少节流并确保最佳集群性能。同时,如果 CPU 使用率持续高于预期,则可能表明 Pod 存在问题,需要识别并解决。

控制平面指标
虽然集群状态和资源指标报告了 Kubernetes 对象的一般状态、性能和效率,但控制平面指标以集群管理为中心,揭示了集群中枢神经系统的健康状况。
11 etcd 集群是否有 leader
为了使集群正常运行,etcd 需要一个稳定的 leader。如果大多数节点无法识别 leader(即它们的指标值为 0),etcd 集群可能会变得不可用,这会影响整个 Kubernetes 集群调度工作负载、存储配置以及维持其所需状态的能力。

12 集群内 leader 转换的次数
etcd_server_leader_changes_seen_total 指标跟踪集群内 leader 变更的次数。突然或频繁的 leader 变更虽然本身并不一定造成损害,但可以提醒 etcd 集群中的连接或资源限制问题,因此值得密切关注该计数。如果注意到计数逐渐增加,则可能表示资源耗尽,需要您扩展或优化 etcd 基础架构。

13 每个资源向 API 服务器发出的请求数量和持续时间
通过监控特定类型 API 服务器请求的数量和延迟,可以了解集群在执行任何用户发起的创建、删除或查询资源的命令时是否出现延迟。还可以跟踪这些指标随时间的变化,并将它们的增量相除,从而计算出实时平均值,这将提供一个基准来进行故障排除,能够快速识别 API 服务器是否被请求淹没。

14 Controller manager 延迟
这些延迟指标为深入了解 Controller manager 的性能提供了重要的参考。Controller manager 会在执行每个可操作项(例如 Pod 的复制)之前将其排队,因此 DevOps 团队应该密切监控它们。如果发现控制器的自动操作延迟增加,可以查看 Controller manager 的日志,以收集有关原因的更多详细信息。

15 Kubernetes scheduler 尝试在节点上调度 Pod 的次数和延迟
跟踪 Kubernetes scheduler 的性能非常重要。通过监控其在节点上调度 Pod 的尝试,以及执行这些尝试的端到端延迟,可以识别 Pod 与工作节点匹配过程中的任何问题。
5. [GKE] GKE 网络接口的 10 年:从核心连接到 AI 主干
2015-2017:通过 kubenet 奠定 CNI 基础
GKE 采用了扁平的 IP 寻址模型,以便 Pod 和节点可以与虚拟私有云 (VPC) 中的其他资源自由通信,而无需经过隧道和网关。在 GKE 的形成期,其早期网络模型通常使用 kubenet (一个基本的网络插件)。Kubenet 提供了一种启动和运行集群的简单方法,即在每个节点上创建网桥,并从专用于该节点的 CIDR 范围中为 Pod 分配 IP 地址。Google Cloud 的网络负责处理节点之间的路由,而 Kubenet 负责将 Pod 连接到节点的网络,并在节点内实现基本的 Pod 间通信。
2018-2019:拥抱 VPC 原生网络
为了满足不断变化的需求并与 Google Cloud 强大的网络功能集成,为 GKE 引入了 VPC 原生网络。这标志着 CNI 在 GKE 中的运行方式取得了重大飞跃,别名 IP 范围(Pod 在节点中使用的 IP 范围)成为该解决方案的基石。VPC 原生网络已成为默认和推荐的方法,有助于将 GKE 集群的规模扩展到 15,000 个节点。借助 VPC 原生集群 ,GKE CNI 插件可确保 Pod 直接从 VPC 网络接收 IP 地址——它们成为网络上的“一等公民”。
这种转变的好处在于:
- 简化的 IP 管理:GKE CNI 插件与 GKE 配合使用,直接从 VPC 分配 pod IP,使它们可直接路由,并且更易于与其他云资源一起管理。
- 通过 VPC 集成增强安全性:由于 pod IP 是 VPC 原生的,因此可以将 VPC 防火墙规则直接应用于 pod。
- 改进的性能和可扩展性:GKE CNI 插件有助于在 VPC 内进行直接路由,从而减少开销并提高 pod 流量的网络吞吐量。
- 高级 CNI 功能的基础:VPC 原生网络为随后更复杂的 CNI 功能奠定了基础。
2020 年及以后:eBPF 革命
GKE CNI 策略的下一个重大发展是 eBPF 的强大功能 ,它允许您在特权上下文中运行沙盒程序。eBPF 使得动态编程 Linux 内核变得安全,为 CNI 级别的网络、安全性和可观察性开辟了新的可能性,而无需重新编译内核。Google Cloud 采用了 Cilium (一个基于 eBPF 构建的领先开源 CNI 项目),打造了 GKE Dataplane V2 (DPv2)。GKE Dataplane V2 于 2021 年 5 月正式发布,标志着 GKE CNI 功能的重大飞跃:
- 增强的性能和可扩展性:通过利用 eBPF,CNI 可以绕过传统的内核网络路径(如 kube-proxy 的基于 iptables 的服务路由),从而实现服务和网络策略的高效数据包处理。
- 内置网络策略实施:GKE Dataplane V2 配备开箱即用的 Kubernetes 网络策略实施,这意味着在使用 DPv2 时,您无需仅为了策略实施而安装或管理单独的 CNI(如 Calico)。
- 增强数据平面的可观察性:eBPF 支持直接从内核深入了解网络流量。GKE Dataplane V2 为网络策略日志记录等功能奠定了基础 ,从而提供对 CNI 级别决策的可见性。
- 数据平面中的集成安全性:eBPF 直接在 CNI 的数据平面内高效地执行网络策略并具有上下文感知能力。
- 简化操作:由于它是 Google 管理的 CNI 组件,GKE Dataplane V2 简化了客户工作负载的操作。
- 高级网络功能:Dataplane V2 解锁了 Data Plane V1 所不具备或难以实现的一系列强大功能。这些功能包括:
- IPv6 和双 栈支持:使 pod 和服务能够同时使用 IPv4 和 IPv6 地址运行。
- 多网络:允许 pod 拥有多个网络接口,连接到不同的 VPC 网络或专用网络附件,这对于云原生网络功能 (CNF) 和流量隔离等用例至关重要。
- 服务转向:通过集群内的一系列服务功能(如虚拟防火墙或检查点)引导特定流量,提供对流量的细粒度控制。
- pod 的持久 IP 地址:与 Gateway API 结合使用,GKE Dataplane V2 允许 pod 在重新启动或重新安排时保留相同的 IP 地址,这对于某些有状态的应用程序或网络功能至关重要。
2024年:人工智能训练和推理迈向新高度
2024 年,宣布 GKE 支持高达 65,000 个节点的集群,标志着 GKE 可扩展性取得了里程碑式的成就。
对于当今的 AI/ML 工作负载,网络起着至关重要的作用:AI 和机器学习工作负载正在突破计算和网络的界限,为 GKE 网络接口带来了独特的挑战:
- 极高的吞吐量:训练大型模型需要处理海量数据集,这需要由 GKE 网络接口协调的 TB 级以上的网络。
- 超低延迟:分布式训练依赖于处理单元之间的近乎即时的通信。
- 多 NIC 功能:为 pod 提供多个网络接口 ,由 GKE Dataplane V2 的多网络功能管理,可以显著提高带宽并允许网络分段。
2025 - 以后:应对下一代 Pod 网络挑战
在 GKE 中,DRA(从 GKE 版本 1.32.1-gke.1489001+ 开始提供预览版)为更高效、更定制的网络资源管理开辟了可能性,帮助要求苛刻的应用程序使用 Kubernetes 网络驱动程序 (KND) 获得所需的网络性能。
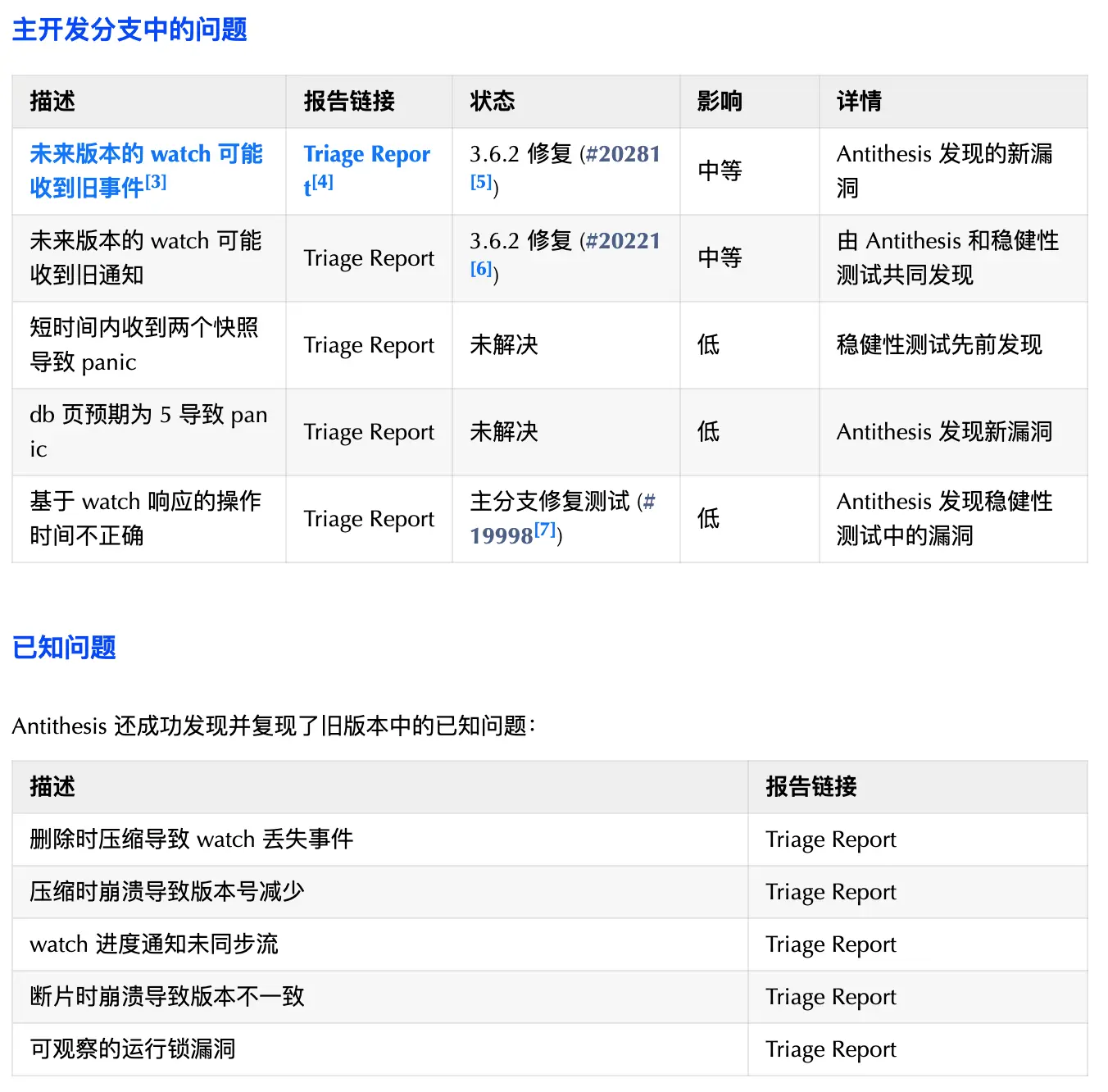
6. etcd 稳健性自主测试
作为许多生产系统(包括 Kubernetes)的关键组件,etcd 项目的首要任务是确保可靠性。保证一致性和数据安全,要求项目贡献者不断改进测试方法。
测试方式
本次测试目标包括:
- 验证 etcd v3.6 的稳健性
- 通过发现和修复漏洞提升 etcd 软件质量
- 以自主测试增强现有测试框架
在 Antithesis 模拟平台上运行现有稳健性测试,测试了 3 节点和 1 节点 etcd 集群,涵盖多种故障,包括:
- 网络故障:延迟、拥堵和分区
- 容器级故障:线程暂停、进程终止、时钟抖动和 CPU 限速
测试了含已知漏洞的旧版本,以及 3.4、3.5、3.6 稳定版本和主开发分支。总测试时长达 830 小时,模拟了 4.5 年的使用。
发现的主要问题
7. [CNCF] 统一管理虚拟机和容器
Finding the Path for Integrating Kubernetes With Existing VMs
The Challenges of Uniting VMs and Containers on a Single Platform
背景
虽然云原生计算如今占据了主导地位,但它有时与包括虚拟机在内的现有范式存在冲突。过去20年,企业已投入数千亿美元在虚拟机中构建和部署企业应用程序,他们并不倾向于将其彻底淘汰,并用更现代的云原生计算架构取而代之。
新的开发通常采用云原生的方式,但大多数现有应用程序都在虚拟机中运行。因此,在可预见的未来,虚拟机和容器将需要共存。然而,说起来容易做起来难。因此,IT 决策者面临的挑战是,找到一条既能同时使用虚拟化应用程序,又能避免额外成本的路径。
可行的机制
Kubernetes 和虚拟机可以共存。只要选择正确的平台,Kubernetes 和虚拟机实际上可以运行在同一台符合行业标准的 x86 机器上。尽管许多企业在不同的物理机器上运行虚拟机和 Kubernetes,但在同一硬件上同时运行它们会带来诸多好处,包括更高的硬件利用率、更佳的可管理性、更精简的集成、更强大的安全性以及更简单的故障排除。
在同一硬件上结合虚拟化和容器化工作负载主要有两种方式:
- 在虚拟机内运行 Kubernetes
- 使用 Kubevirt 等技术在裸机上运行带有 Kubernetes 的虚拟机
机制对比
| 特征 | 方案一:在 VM 内运行 K8s | 方案二:使用 Kubevirt (K8s-Native VM) |
|---|---|---|
| VM 的角色 | K8s 的节点 (Node) | K8s 的工作负载 (Pod) |
| 管理 API | 双重管理:管理 VM 用 vSphere API,管理容器用 K8s API。 | 单一 K8s API:所有资源(Pod, VM, 网络)都通过 K8s API 管理。 |
| 隔离性 | 硬隔离:VM 级别隔离,安全性高,但开销大。 | 软隔离:Pod 级别隔离,VM 依赖 K8s 网络,隔离性略低于硬 VM。 |
| 资源效率 | 较低:VM 内的 OS 占用资源,K8s 组件也占用资源。 | 较高:VM 直接运行在 Pod 内,减少了底层 OS 层的资源浪费。 |
| 灵活性 | 较低:VM 配置更改需要传统运维流程。 | 极高:VM 的创建、迁移、伸缩都可像 Pod 一样通过 YAML 声明式管理。 |
| 技术成熟度 | 非常成熟,公有云和私有云的标准做法。 | 相对较新,依赖 Kubevirt 等开源项目,仍在快速发展中。 |
| 典型的例子 | 所有公有云的 K8s 服务(如 EKS/AKS/GKE);使用 Kubespray 部署在 vSphere 上的集群;SmartX 的 SKS,部署在超融合集群上的集群。 | 使用 Kubevirt 在裸机集群上运行。 |
在虚拟机内运行 Kubernetes
- 简介
- 将 Kubernetes 部署在传统的虚拟机基础设施之上。
- 工作原理
- 虚拟机承担了 Kubernetes 节点的角色。所有 Kubernetes 的核心组件和工作负载(Pod)都运行在这些虚拟机内部。虚拟机提供了硬件隔离、操作系统管理、网络和存储的抽象。
- 适用场景
- 企业已经有大量的虚拟机基础设施,希望利用现有投资。
- 需要严格的硬隔离(Hard Multi-tenancy),即每个 Kubernetes 节点(虚拟机)之间需要完全隔离。
- 需要运行传统的、操作系统级别的服务,然后在其上层部署 Kubernetes。
- 相关产品/方案
- 公有云 Kubernetes 服务,例如 Amazon EKS、Azure AKS、Google GKE
- 私有云 Kubernetes 服务,例如 VMware Tanzu、SmartX SKS、Nutanix NKE、Rancher
Kubevirt
- 简介
- 将虚拟化技术作为 Kubernetes 的工作负载来管理。
- 工作原理
- Kubevirt 利用 Kubernetes 的调度、存储和网络功能,通过 KVM/QEMU 等技术在 Pod 内部运行一个虚拟机实例。虚拟机不再是 Kubernetes 的节点,而是一个受 Kubernetes 管理的 Pod 内的特殊工作负载。
- 适用场景
- 希望用统一的 Kubernetes API 管理所有类型的负载(容器和虚拟机)。
- 需要将遗留的、无法容器化的应用(如特殊内核要求的应用)迁移到 Kubernetes 平台。
- 追求更高的资源密度和更少的虚拟化开销。
- 相关产品/方案
- KubeVirt
- OpenShift
面临的困境
- 运维人员的技术差异
- 那些在 VMware 、Hyper-V 或 Nutanix 上积累了职业生涯的运维人员本能地理解数据存储、端口组和快照等概念。这些概念与物理服务器和传统 IT 实践紧密相关。相比之下,Kubernetes 则需要一种全新的思维方式。
- Pod 是短暂的。Deployment 和 Service 定义了期望状态。网络由策略驱动,存储是抽象的。管理通常通过 YAML 文件和 API 进行,而不是图形控制台。例如一名 VMware 管理员习惯于在 vCenter 中拖放虚拟机;平台工程师则不会考虑在他们的 Pod 上这样做。对于习惯于稳定虚拟机状态的团队来说,这种转变可能会让人感到困惑。
- 对 Kubernetes 平台的不同期望
- 在 Kubernetes 上运行虚拟机也改变了企业对平台本身的期望。容器通常设计为无状态且瞬时,而虚拟机通常是有状态的、长寿命的,并且与持久存储绑定。连接这两种模型需要在调度、存储处理和生命周期管理方面具有灵活性。
- 网络最能体现这一挑战。虚拟机工作负载通常依赖于静态 IP、VLAN 和防火墙结构。Kubernetes 假设网络是一个具有动态寻址和网络策略的扁平网络。协调这些因素并非易事。
- 迁移困境
- 即使 Kubernetes 能够满足虚拟机的运营需求,迁移问题仍然存在。将工作负载迁移到基于 Kubernetes 的平台远不止复制磁盘文件那么简单。
- 虚拟机与虚拟机管理程序特定的设置紧密相关。它们的磁盘通常驻留在专有存储系统上。它们的网络依赖于 Kubernetes 环境中可能不存在的结构。将所有这些映射到一组新的抽象中是一项艰巨的任务。
- 同样重要的是,我们不太可能看到虚拟机资源的大规模迁移。大多数企业最近才完成虚拟化项目。将所有工作负载迁移到容器可能需要数十年时间,就像大型机和物理服务器工作负载目前仍在运行一样。更现实的做法是选择性迁移。组织可以从较简单的工作负载开始:CI 和构建系统、批处理作业、Web 前端或某些值得迁移的数据库。
拓展阅读
Learn KubeVirt: Deep Dive for VMware vSphere Admins
8. 每提供一个选项,就要求用户做出一次决定
下面是部分节选:
- 让用户做决定本身并非坏事。选择自由本身就很棒。但当你要求他们做出他们并不关心的选择时,问题就来了。用户关心的事情比你想象的要少得多。他们使用你的软件是为了完成一项任务。他们关心的是这项任务本身。如果它是一个图形程序,他们可能希望能够控制每个像素到最精细的程度。如果它是一个网站构建工具,你可以肯定,他们执着于让网站看起来完全符合他们的期望。
- 有人说,设计就是一门取舍的艺术。当你为街角设计一个垃圾桶时,你必须在相互冲突的需求之间做出取舍。它需要足够重,这样才不会被风吹走。它需要足够轻,这样垃圾收集员才能把它倒掉。它需要足够大,这样才能装下大量的垃圾。它需要足够小,这样才不会妨碍人行道上的行人。当你在设计时,试图推卸责任,强迫用户做决定,那么你可能没有做好自己的工作。别人会开发一个更简单的程序,以更少的干扰完成同样的任务,而且大多数用户都会喜欢它。
- 很多电脑用户都无法摆脱这种困境;顾名思义,当你不小心重新配置了程序中的某个选项时,你不知道如何重新配置它。令人惊讶的是,当软件出现问题时,很多人会卸载软件,然后再重新安装,因为他们至少知道该怎么做。(他们学会了先卸载,否则所有损坏的自定义设置很可能会再次出现)。
- “为想要调整环境的高级用户提供选项很重要!”实际上,它并不像你想象的那么重要。
- 每次你提供一个选项,你就是在要求用户做出决定。这意味着他们必须思考并做出决定。这未必是坏事,但总的来说,你应该尽量减少用户需要做的决定数量。
9. 使用 Prometheus 控制 Fluent Bit 背压
Control Fluent Bit Backpressure With Prometheus
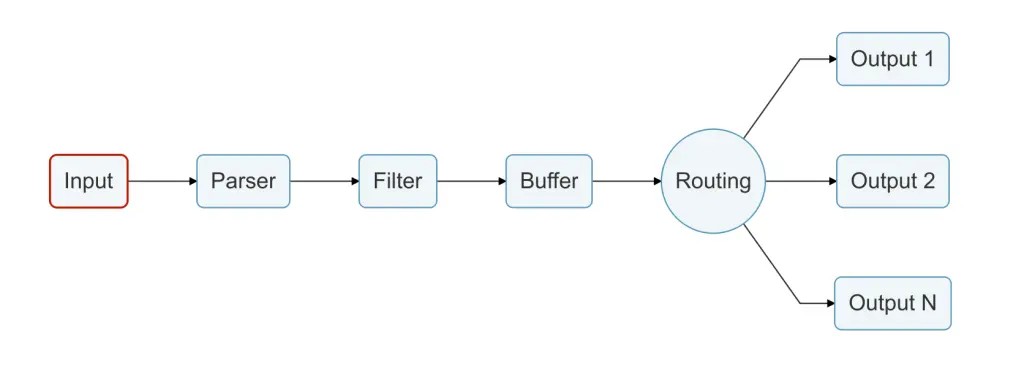
Fluent Bit 简介
Fluent Bit 是用于日志、指标和跟踪的最广泛使用的开源数据收集代理之一。它轻量级、高性能且易于扩展,是现代可观测性管道的理想选择。Fluent Bit 的核心是一个包含各个阶段的简单数据管道,如下图所示。
什么是背压
即使是最高效的管道也会遇到被称为背压的瓶颈。当数据提取的速度超过系统处理和刷新数据的能力时,就会出现背压。背压会导致内存占用高、服务停机和数据丢失等问题。
在高吞吐量日志记录管道中,Fluent Bit 的数据提取速度超过了下游输出(HTTP 端点、数据库、存储后端)的接收速度。输入速率和输出速率之间的这种不匹配会导致背压,即缓冲区增大、内存消耗增加,并且必须限制或暂停输入。

一个典型的例子是读取大型日志文件(或有大量积压数据),并尝试通过网络将事件分发到后端。如果后端速度慢或不可用,缓冲数据就会在 Fluent Bit 中累积。
如果不加以控制,背压可能会导致内存使用过多、性能下降甚至数据丢失。
背压的控制机制
- Mem_Buf_Limit
- 仅当 storage.type 为 memory 时(默认)
- 设置可排队的内存数据量的上限。当内存使用量超过此限制时,Fluent Bit 会在输入时触发暂停回调,从而阻止新数据的提取,直到缓冲区耗尽为止。
- storage.max_chunks_up
- 使用 storage.type filesystem 或混合(内存 + 文件系统)模式时
- 控制在强制执行转换或限制之前可以容纳多少个内存“块”。一旦达到限制,Fluent Bit 可能会停止在内存中缓冲新数据,并切换到仅文件系统缓冲(如果已启用)。
更多细节内容见原文。
10. 高效自动扩缩容:用开源项目兼顾性能、可靠性与成本
背景
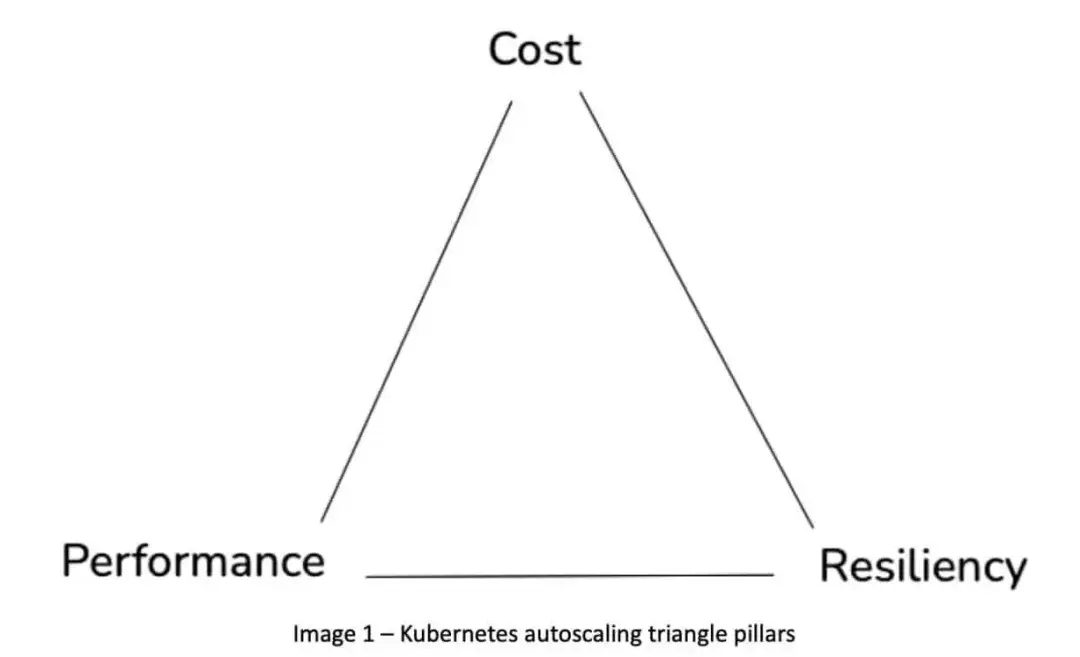
Kubernetes 自动扩缩容,不只是简单地在需求增长时增加副本或节点,需求减少时缩减资源。你必须在性能、可靠性和成本三者之间找到平衡,这三者往往相互制约。把这三大支柱想象成一个三角形,如下图所示。
这三者之间自然存在张力。在应用性能下降之前,你需要增加资源,这会推高成本。为了节省成本,你会缩减资源,这可能影响可靠性。
性能
首先要清楚哪些因素真正影响应用性能——用户和利益相关者关心什么。大多数情况下,他们并不直接关注 CPU 或内存使用率,这些只是指标,并不能完全反映情况。
成功的团队通常会追踪每秒请求数、延迟、队列长度、首个令牌时间、每秒令牌数,甚至来自云服务商等外部源的事件驱动指标。没有一种“万能”指标适用于所有工作负载,通常需要多指标结合。
明确了关键指标后,你可以设计更智能的扩缩容策略和阈值,确保不会为了节省资源而牺牲用户体验。
一种实用方法是测试你的工作负载:
- 用 k6 等负载测试工具模拟流量
- 使用 VPA、krr、Goldilocks 了解资源效率
- 找出单个 Pod、多 Pod 或实际运行场景的临界点
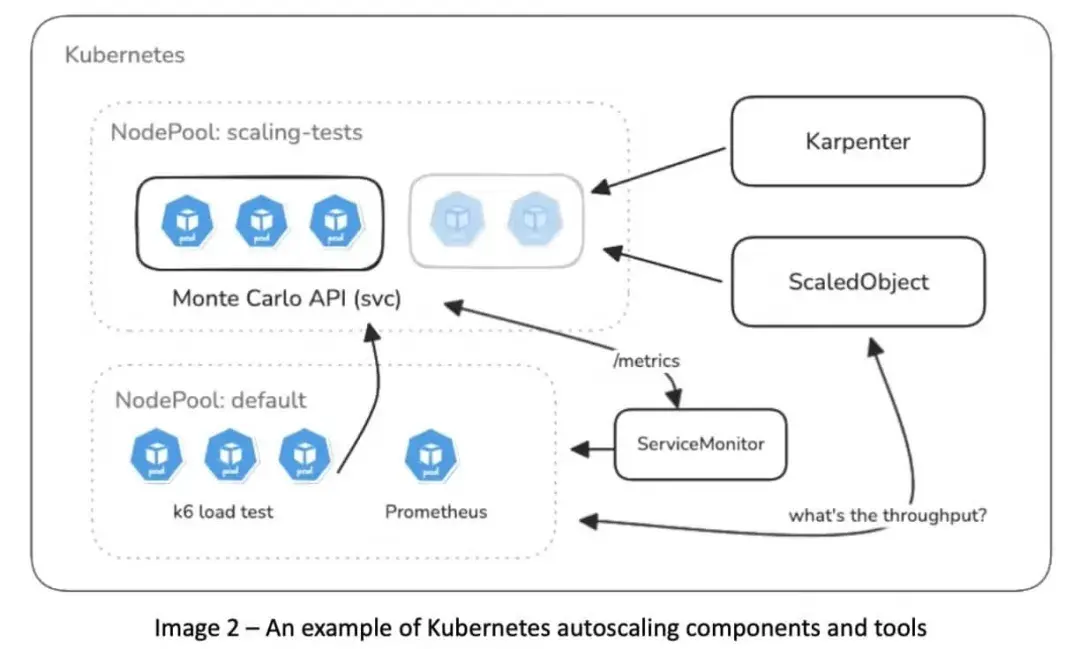
成本
自动扩缩容的最大驱动力之一是效率——用多少资源,正好够用。KEDA 通过智能扩缩容来精准调整 Pod 数量,Karpenter 则负责按需快速创建节点,优化成本。
它们协同工作机制如下:
- 需求增加时,KEDA 扩容更多 Pod。
- 当 Pod 因资源不足无法调度,Karpenter 会增加节点。
- Karpenter 确保只创建必要的容量,不多不少。
- 需求下降时,KEDA 缩容 Pod,Karpenter 则合并或释放闲置节点,甚至模拟节点驱逐,尽可能把负载压缩到更少更便宜的节点上。
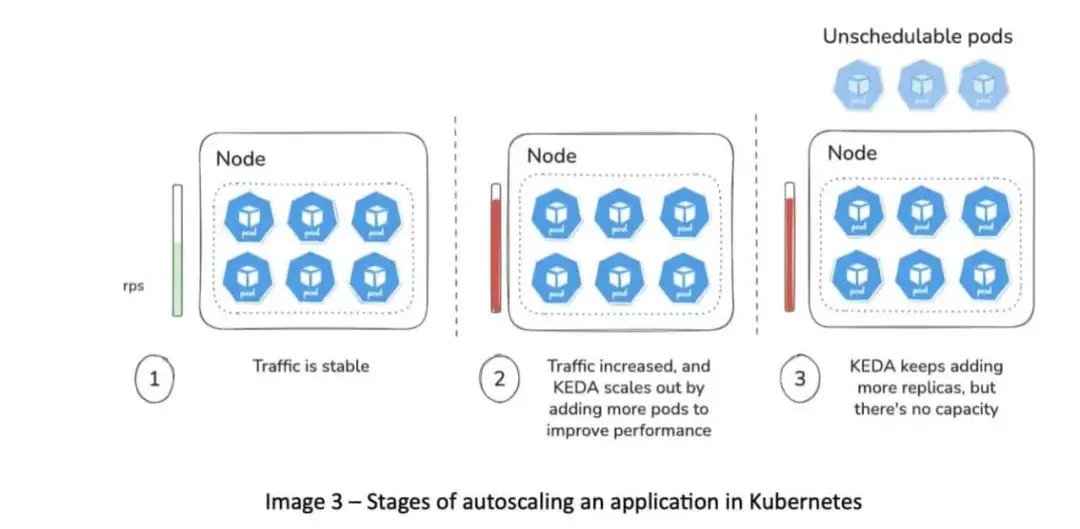
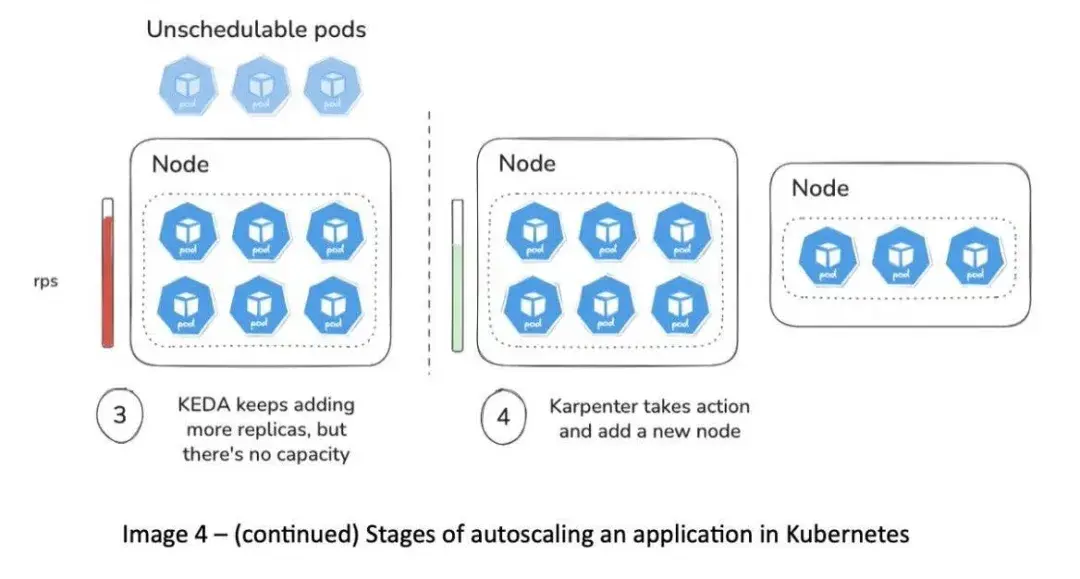
可靠性
自动扩缩容动态增删 Pod 和节点,如果应用没做好优雅终止和应对突发变化的准备,会影响稳定性。解决可靠性问题前,先明确 SLA 和 SLO。不要过度设计或投入超过服务水平要求。
保障可靠性的实用方法:
- Pod 跨多个可用区分布
- 用 pod 拓扑分布约束(topology spread constraints)配合 whenUnsatisfiable: ScheduleAnyway,保证高可用而不至于过度扩容。注意这可能稍微增加成本,因为可能会启动新节点以均匀分布。
- 使用 Pod Disruption Budgets (PDBs) 和 NodePool Disruption Budgets (NDBs)(使用 Karpenter 时)
- 这些帮助管理节点合并或升级时的自愿中断,但对抢占式节点终止无效,务必测试应用对意外终止的容忍度。
- 优雅处理终止事件
- 配置 terminationGracePeriodSeconds(默认 30 秒,可考虑延长到 90 秒),添加 preStop 钩子做清理,设置 readinessProbe 避免流量打到即将终止的 Pod,尽量在代码中处理 SIGTERM 信号。
- 主动监控节点健康
- 使用 Node Problem Detector 及 Karpenter 的 Node Auto Repair 自动替换异常节点。
做到这些,能让扩缩容既高效又可靠。
11. Kubernetes 向 cgroups v2 的转变:你需要知道什么
The Shift to cgroups v2 in Kubernetes: What You Need to Know
简介
cgroups (control groups) 是一种用于管理系统资源的 Linux 内核功能。Kubernetes 利用 cgroups 来为容器分配 CPU 和内存等资源,确保应用程序平稳运行且互不干扰。随着 Kubernetes v1.31 版本的发布,cgroups v1 已被转入维护模式。至于 cgroups v2,它已于两年前在 v1.25 版本中正式升级(毕业)。
cgroups v1 的问题与 cgroups v2 的解决方案
active_file 内存不被视为可用内存
- 在 cgroups v1 中,没有原生的解决方案。解决方法是为 Pod 设置更大的内存限制,或者使用一些外部项目来删除缓存,或者在内存超过阈值时限制内存分配。
- 在 cgroups v2 中,可以使用 memory.high 来限制。
容器感知的 OOM Killer 和更好的 OOM 处理策略
- 在 cgroups v1 中,多进程 Pod 中的一个进程可能会被 OOM 终止程序终止。在这种情况下,Pod 必须使用 runit 或 supervisord 来管理多进程的生命周期。
- cgroups v2 使用 cgroup.kill 文件。向该文件写入“1”会导致 cgroup 及其所有后代 cgroup 被终止。这意味着受影响的 cgroup 树中的所有进程都将通过 SIGKILL 被终止。Pod 可以运行多个进程,并且所有进程可以同时被终止。
无根支持
在 cgroups v1 中,将 cgroups v1 控制器委托给权限较低的容器可能会很危险。
cgroups v2 正式支持委托。大多数 Rootless 容器实现依赖 systemd 将 v2 控制器委托给非 root 用户。
使用 cgroups v2 的要求
- OS 发行版启用 cgroups v2
- Linux 内核版本为 5.8 或更高版本
- 容器运行时支持 cgroups v2。例如:
- containerd v1.4 或更高版本(在撰写本文时,containerd 版本 v1.6 及更高版本在该项目的支持期内)
- CRI-O v1.20 或更高版本
- kubelet 和容器运行时配置为使用 systemd cgroup 驱动程序
12. 7 个常见的 Kubernetes 陷阱(以及如何避免它们)
7 Common Kubernetes Pitfalls (and How I Learned to Avoid Them)
1. 跳过资源请求和限制
未在 Pod 规范中指定 CPU 和内存需求。这种情况通常是因为 Kubernetes 不需要这些字段,而工作负载通常可以在没有这些字段的情况下启动和运行——这使得在早期配置或快速部署周期中很容易忽略这一遗漏。
在 Kubernetes 中,资源请求和限制对于高效的集群管理至关重要。资源请求确保调度程序为每个 Pod 预留适量的 CPU 和内存,从而保证其拥有运行所需的资源。资源限制限制了 Pod 可以使用的 CPU 和内存量,防止任何单个 Pod 消耗过多资源,从而避免其他 Pod 出现资源匮乏的情况。未设置资源请求和限制时:
- 资源匮乏:Pod 可能获取到的资源不足,从而导致性能下降或出现故障。这是因为 Kubernetes 根据这些请求来调度 Pod。如果没有这些请求,调度程序可能会在单个节点上放置过多的 Pod,从而导致资源争用和性能瓶颈。
- 资源囤积:相反,如果没有限制,Pod 可能会消耗超过其合理份额的资源,从而影响同一节点上其他 Pod 的性能和稳定性。这可能会导致其他 Pod 因可用内存不足而被驱逐或被内存不足 (OOM) 终止程序终止等问题。
如何避免:
- 从适度的 requests 开始(例如 100m CPU、 128Mi 内存),看看您的应用程序如何表现。
- 监控实际使用情况并优化您的配置数值; HorizontalPodAutoscaler 可以帮助根据指标自动进行扩展。
- 密切关注 kubectl top pods 或您的日志记录/监控工具,以确认您没有过度或不足地配置。
2. 低估活性探测和就绪探测
部署容器时没有明确定义 Kubernetes 应如何检查其健康状况或就绪状态。这种情况经常发生,因为只要容器中的进程尚未退出,Kubernetes 就会认为容器“正在运行”。如果没有额外的信号,Kubernetes 会假设工作负载正在运行——即使容器中的应用程序无响应、正在初始化或卡住。
活跃度、就绪度和启动探测是 Kubernetes 用来监控容器健康和可用性的机制
- 存活探测用于确定应用程序是否仍然处于活动状态。如果存活检测失败,则重新启动容器。
- 就绪探测控制容器是否已准备好处理流量。在就绪探测通过之前,容器将从服务端点中移除。
- 启动探测有助于区分长时间启动和实际故障。
如何避免:
- 添加一个简单的 HTTP livenessProbe 来检查健康端点(例如 /healthz),以便 Kubernetes 可以重新启动挂起的容器。
- 使用 readinessProbe 来确保流量在应用程序预热之前不会到达您的应用程序。
- 保持探测简单。过于复杂的检查可能会导致误报和不必要的重启。
3. “我们只查看容器日志”(著名的临终遗言)
仅依赖通过 kubectl logs 检索的容器日志。这种情况经常发生,因为该命令快捷方便,并且在许多设置中,日志在开发或早期故障排除期间似乎可以访问。然而,kubectl logs 仅检索当前正在运行或最近终止的容器的日志,并且这些日志存储在节点的本地磁盘上。一旦容器被删除、驱逐或节点重启,日志文件可能会被轮换或永久丢失。
如何避免:
- 使用 CNCF 工具(如 Fluentd 或 Fluent Bit) 集中日志以汇总所有 Pod 的输出。
- 采用 OpenTelemetry 统一查看日志、指标和(如果需要)跟踪记录。这可让您发现基础架构事件与应用级行为之间的关联。
- 将日志与 Prometheus 指标配对,以便跟踪集群级数据和应用程序日志。如果您需要分布式追踪,可以考虑使用 CNCF 项目,例如 Jaeger。
4. 以完全相同的方式对待开发和生产
在开发、预发布和生产环境中部署相同的 Kubernetes 清单,其设置可能完全相同。这种情况通常发生在团队追求一致性和可重用性,却忽略了特定环境的因素(例如流量模式、资源可用性、扩展需求或访问控制)可能存在显著差异的情况下。如果不进行定制,针对一个环境优化的配置可能会导致另一个环境出现不稳定、性能低下或安全漏洞。
如何避免:
- 使用环境覆盖或 kustomize 来维护共享基础,同时为每个环境定制资源请求、副本或配置。
- 将特定于环境的配置提取到 ConfigMap 和/或 Secrets 中。您可以使用 Sealed Secrets 等专用工具来管理机密数据。
- 规划生产环境的规模。你的开发集群可能只需要极少的 CPU/内存,但生产环境可能需要更多。
5. 让旧东西四处乱放
集群中残留未使用或过期的资源(例如 Deployment、Service、ConfigMap 或 PersistentVolumeClaims)。这种情况经常发生,因为 Kubernetes 不会自动移除资源,除非明确指示,而且没有内置机制来跟踪所有权或过期时间。随着时间的推移,这些被遗忘的对象会累积起来,消耗集群资源,增加云成本,并造成运维混乱,尤其是在陈旧的 Service 或 LoadBalancer 继续路由流量的情况下。
如何避免:
- 为所有内容添加用途或所有者标签。这样,您就可以轻松查找不再需要的资源。
- 定期审核您的集群:运行 kubectl get all -n <namespace> 来查看实际运行的内容,并确认它们都是合法的。
- 采用 Kubernetes 的垃圾收集:K8s 文档展示了如何自动删除依赖对象。
- 利用策略自动化:像 Kyverno 这样的工具可以在一定时间后自动删除或阻止陈旧的资源,或者执行生命周期策略,这样您就不必记住每一个清理步骤。
6. 过早地投入社交
在完全理解 Kubernetes 原生网络原语之前,就引入高级网络解决方案(例如服务网格、自定义 CNI 插件或多集群通信)。这种情况通常发生在团队使用外部工具实现流量路由、可观察性或 mTLS 等功能时,而没有首先掌握 Kubernetes 核心网络的工作原理:包括 Pod 间通信、ClusterIP 服务、DNS 解析和基本的入口流量处理。因此,网络相关问题会变得更加难以排查,尤其是在覆盖层引入额外的抽象和故障点时。
如何避免:
- 从小处开始:部署、服务和基本入口控制器,例如基于 NGINX 的控制器(例如,Ingress-NGINX)。
- 确保您了解流量在集群内如何流动、服务发现如何工作以及 DNS 如何配置。
- 仅当您真正需要时才转向全面的网格或高级 CNI 功能,复杂的网络会增加开销。
7. 安全性和 RABC 方面过于薄弱
使用不安全的配置部署工作负载,例如以 root 用户身份运行容器、使用 latest 镜像标签、禁用安全上下文或分配过于宽泛的 RBAC 角色(例如 cluster-admin 。这些做法之所以持续存在,是因为 Kubernetes 不会强制执行开箱即用的严格安全默认设置,而且该平台的设计初衷是灵活而非固执己见。如果没有明确的安全策略,集群仍然可能面临风险,例如容器逃逸、未经授权的权限提升,或由于镜像未固定而导致的意外生产环境变更。
如何避免:
- 使用 RBAC 在 Kubernetes 中定义角色和权限。虽然 RBAC 是默认且最广泛支持的授权机制,但 Kubernetes 也允许使用其他授权器。对于更高级或外部策略需求,可以考虑 OPA Gatekeeper (基于 Rego)、 Kyverno 等解决方案,或使用 CEL 或 Cedar 等策略语言的自定义 Webhook。
- 将镜像固定到特定版本(不再使用 :latest !)。这有助于您了解实际部署的内容。
- 研究 Pod Security Admission (或其他解决方案,如 Kyverno)来强制执行非根容器、只读文件系统等。
13. 超越命名空间:为什么 Kubernetes 需要真正的工作负载隔离
Beyond Namespaces: Why Kubernetes Needs Real Workload Isolation
命名空间提供了逻辑上的隔离,但它们并没有强制执行那种在运行时阻止工作负载相互干扰的强化边界。
命名空间分区,但并不隔离
命名空间为开发人员和运维人员提供了一种优雅的抽象:它们允许多个团队或租户共享集群,而无需占用彼此的资源。它们可以强制执行配额,启用基于角色的访问控制 (RBAC),并允许更清晰地限定策略范围。这对于减少管理混乱至关重要。但是命名空间并不能改变所有运行在同一节点上的容器共享同一内核这一基本事实。由于内核本身就是共享界面,因此命名空间中受感染的容器仍然有可能攻击内核、利用共享设备或窥探 GPU 内存。即使租户管理员被赋予了完整的命名空间控制权,他们通常仍然保留着影响整个集群的途径。红队的经验表明,命名空间边界在压力之下难以维持。它们是策略构造,而非安全屏障。
这种区别很重要,因为我们经常谈论命名空间和隔离,好像它们是可以互换的。但事实并非如此。命名空间提供分区。隔离是对工作负载进行严格限制,即使其中一个工作负载受到损害,也无法跨越边界。
仅靠命名空间不足以实现多租户安全
命名空间的局限性在现代攻击模式中凸显出来。容器逃逸和内核级漏洞就说明了这个问题:
- GPU 逃逸 Wiz 记录了 NVIDIA 漏洞,这些漏洞允许攻击者利用钩子和环境变量处理来逃离容器边界。命名空间无法阻止这种攻击,因为攻击针对的是共享内核状态。
- 权限提升:一旦进入内核,攻击者就可以提升权限、危害邻近的工作负载并在节点之间横向移动。
- 爆炸半径:在仅限命名空间的模型中,单个受损的 Pod 可能触发级联故障,影响节点上的所有工作负载。在受监管的行业或 SaaS 多租户环境中,这是不可接受的。
将命名空间视为强化边界的安全模型依赖于一个危险的误解:逻辑隔离等于运行时隔离。一旦容器闯入内核,一切就都完了。
历史的对比:虚拟机与容器
虚拟化几十年前就解决了这个问题。虚拟机 (VM) 通过为每个工作负载赋予其自己的内核来强制执行严格的边界。一个虚拟机不能轻易地干扰另一个虚拟机。容器则为了速度、密度和灵活性而牺牲了这一点——而这些权衡在当时是合理的。
但时代变了。轻量级虚拟化和虚拟机管理程序支持的运行时已经缩小了曾经让虚拟机失去吸引力的性能差距。半虚拟化和 Type-1 虚拟机管理程序现在提供了接近原生的性能,同时恢复了命名空间所缺乏的强大隔离属性。
为什么命名空间不能作为安全边界
要了解为什么命名空间不等同于隔离,我们需要深入研究 Linux 内核本身:
- 命名空间隐藏了进程 ID、文件系统和网络接口等资源。它们改变了容器所看到的内容。
- Cgroups 控制容器可以消耗多少 CPU 或内存。它们可以调节容器的使用量。
- Seccomp 和 AppArmor 限制系统调用或强制执行配置文件,但它们仍在共享内核内运行。
这些机制都无法阻止受感染容器攻击内核或利用漏洞影响其他租户。它们最多只能限制可见性和资源使用。它们无法提供现代工作负载所需的加密或硬件支持保障。
与虚拟机管理程序级别的隔离进行对比:
- 每个容器(或 pod)都在具有自己内核的轻量级虚拟机中运行。
- 没有共享内核状态意味着一个虚拟机中的逃逸漏洞不会暴露主机或其他租户。
- GPU 和设备访问可以虚拟化,从而消除工作负载之间的侧通道泄漏。
这就是分区和保护之间的区别。
📄 专题四 报告查看与分析
本月无。
💁♀️ 专题五 产品/方案介绍
1. 灾难恢复自动化工具:Velero、Stash、Ark
- Velero
- Stash
- Ark
2. Numaflow:事件驱动的 Kubernetes 流处理引擎
简介
Numaflow 是一个 Kubernetes 原生的无服务器平台,用于运行可扩展且可靠的事件驱动应用程序。Numaflow 将事件源和接收器与处理逻辑解耦,允许每个组件根据需求独立地自动扩展。凭借开箱即用的源和接收器以及内置的可观察性,开发者可以专注于处理逻辑,而无需担心事件消费、编写样板代码或操作复杂性。管道的每个步骤都可以使用任何编程语言编写,从而提供了无与伦比的灵活性,可为每个步骤选择最合适的编程语言,并且可以轻松地使用您最熟悉的语言。
Numaflow 专为高吞吐量工作负载而构建,可连接到 Kafka、Pulsar 和 SQS,并可在将数据流发送到目的地之前对其进行分析、过滤或处理。它易于扩展,可根据您的需求快速运行。
特点
- Kubernetes 原生:如果您了解 Kubernetes,那么您已经知道如何使用 Numaflow。
- 无服务器:专注于您的代码并让系统根据需求进行扩展和缩减。
- 与语言无关:使用您最喜欢的编程语言。
- 恰好一次语义:即使重新安排或重新启动 Pod,也不会重复或丢失输入元素。
- 具有背压的自动缩放:每个顶点自动从零缩放到所需的任何值。
使用场景
- 事件驱动应用程序:处理发生的事件,例如,在电子商务中更新库存和发送客户通知。
- 实时分析:即时分析数据,例如社交媒体分析、可观察性数据处理。
- 流数据推理:执行实时预测,例如异常检测。
- 工作流以流式方式运行。
拓展阅读
Intuit’s Numaflow Abstracts Away Infrastructure for ML Engineers
3. OrbStack:功能强大的 WSL 和 Docker Desktop 替代方案
简介
OrbStack 是运行 Docker 容器和 Linux 机器的快速、轻量且简单的方法。它是一个功能强大的 WSL 和 Docker Desktop 替代方案,所有功能都包含在一个易于使用的应用程序中。
特点
- 闪电般快速。2 秒启动,优化的网络和文件系统,Rosetta 仿真。
- 轻量级。低 CPU 和磁盘占用,电池友好,占用更少内存,原生 Swift 应用。
- 轻松便捷。自动域名和迁移、CLI 和文件系统集成、VPN 和 SSH 支持。
- 功能强大。运行 Docker 容器、Kubernetes 和 Linux 发行版。从菜单栏快速管理容器。浏览卷和镜像文件。
收费
个人使用免费,商业用途则需支付每月 8 美元 / 用户的费用,企业版需联系报价。
4. cosign:提升软件供应链安全性的开源项目
简介
Sigstore 是一个旨在提升软件供应链安全性的开源项目。Sigstore 框架和工具使软件开发者和用户能够安全地对软件构件(例如发布文件、容器镜像、二进制文件、软件物料清单 (SBOM) 等)进行签名和验证。签名由临时签名密钥生成,因此无需管理密钥。签名事件记录在防篡改的公共日志中,以便软件开发者可以审核签名事件。
该项目由 Linux 基金会旗下的开源安全基金会 (OpenSSF) 支持,并得到了谷歌、红帽、Chainguard、GitHub 和普渡大学的贡献。它完全开源,所有开发者和软件提供商均可免费使用。Sigstore 社区开发并维护用于简化代码签名和验证的工具,同时还运营一项公益性非营利服务,以改善开源软件供应链。
目标
Cosign 的目标是使签名成为隐形的基础设施。
使用场景
在软件供应链漏洞日益增多的形势下,未签名的软件面临多种攻击风险,例如:
- 抢注具有相似名称的软件包
- 托管软件包的站点被攻陷
- 发布后篡改
特点
- 便利性:用户可以利用便捷的工具、轻松的容器签名,甚至可以绕过密钥管理和轮换的难题。
- 自动化:用户还可以使用我们的 CI 工具自动签名。
- 安全性:使用 Sigstore,工件不仅仅是签名;它使用临时密钥签名,与已知身份相关联,并且可以公开审计。
工作原理
- Sigstore 客户端(例如 Cosign)会创建公钥/私钥对,并使用公钥向我们的代码签名证书颁发机构 (Fulcio) 发出证书签名请求。请求中还会提供一个可验证的 OpenID Connect (OIDC) 身份令牌。OIDC 令牌包含用户的电子邮件地址或服务帐户,如果是 CI 签名,则包含工作流信息。证书颁发机构会验证此令牌,并颁发与提供的身份和公钥绑定的短期证书。
- 您无需管理签名密钥,Sigstore 服务也永远不会获取您的私钥。Sigstore 客户端创建的公钥会与颁发的证书绑定,而私钥在单次签名后会被丢弃。
- 客户端对工件进行签名后,其摘要、签名和证书将保存在一个透明日志中:一个不可篡改、仅可追加的账本,名为 Rekor。通过此日志,签名事件可以被公开审计。身份所有者可以监控该日志,以验证其身份是否被正确使用,而下载工件的用户则可以确认证书在签名时是否有效。
- 为了验证工件,Sigstore 客户端将使用证书中的公钥验证工件上的签名,验证证书中的身份是否与预期身份匹配,使用 Sigstore 的信任根验证证书的签名,并验证其在 Rekor 中的包含证明。这些信息的验证可以告知用户该工件来自预期来源,并且在创建后未被篡改。
拓展阅读
5. Kata Containers:构建可无缝插入容器生态的轻量虚拟机的开源容器运行时
简介
Kata Containers 是一个开源社区,致力于使用轻量级虚拟机构建安全的容器运行时,这些虚拟机的感觉和性能类似于容器,但使用硬件虚拟化技术作为第二层防御提供更强大的工作负载隔离。
自 2017 年 12 月启动以来,社区成功地将英特尔 Clear Containers 的精华与 Hyper.sh RunV 融合,并扩展至支持 AMD64、ARM、IBM p 系列和 IBM z 系列以及 x86_64 等主流架构。Kata Containers 还支持多种虚拟机管理程序,包括 QEMU、Cloud-Hypervisor 和 Firecracker,并与 containerd 项目等集成。
Kata Containers 社区由开放基础设施基金会 (Open Infrastructure Foundation) 管理,该基金会支持全球开放基础设施的开发和应用。代码托管在 GitHub 上,遵循 Apache 2 许可证。
特点
- 安全
- 在专用内核中运行,提供网络、I/O 和内存的隔离,并可以利用虚拟化 VT 扩展实现硬件强制隔离。
- 兼容性
- 支持行业标准,包括 OCI 容器格式、Kubernetes CRI 接口以及传统虚拟化技术。
- 性能
- 提供与标准 Linux 容器一致的性能;增强隔离性,而不会对标准虚拟机造成性能负担。
- 简单
- 消除了在成熟虚拟机内嵌套容器的要求;标准接口使其易于插入和启动。
拓展阅读
How To Get Bare-Metal GPU Performance in Confidential VMs
🤔 专题六 有意思的事与 Meme
本月无。