🆕 专题一 产品新功能/新版本
1. Istio 1.27 增加了 Alpha 版 Ambient 多集群支持(Alpha 版)
文档:安装跨多个集群的 Istio Ambient 服务网格
背景
多集群架构可以提高故障恢复能力,缩小影响范围,并实现跨数据中心的扩展。然而,集成多个集群会带来连接性、安全性和运维方面的挑战。例如不同集群的 IP 地址空间可能会重叠, 即使没有重叠,底层基础架构也需要进行配置以路由跨集群流量。Pod 之间的流量会超出集群边界, Pod 也会接受来自集群外部的连接。如果没有集群边缘的身份验证和强加密, 外部攻击者可能会利用易受攻击的 Pod 或拦截未加密的流量。
关键组件
- 东西向网关
- 双倍 HBONE
- 服务发现和范围
Roadmap
希望改进以下领域:
- 所有集群的服务和 waypoint 配置必须统一。
- 不支持跨集群 L7 故障转移(L7 策略应用于目标集群)。
- 不支持直接 Pod 寻址或无头服务。
- 仅支持多主部署模型。
- 仅支持每集群单网络部署模型。
2. Karmada v1.15 版本发布!多模板工作负载资源感知能力增强
Karmada v1.15 版本发布!多模板工作负载资源感知能力增强
Karmada
Karmada 是开放的多云多集群容器编排引擎,旨在帮助用户在多云环境下部署和运维业务应用。凭借兼容 Kubernetes 原生 API 的能力,Karmada 可以平滑迁移单集群工作负载,并且仍可保持与 Kubernetes 周边生态工具链协同。
新增特性
- 多模板工作负载的资源精确感知(Alpha)
Karmada 利用资源解释器获取工作负载的副本数和资源请求,并据此计算工作负载所需资源总量,从而实现资源感知调度,联邦配额管理等高阶能力。这种机制在传统的单模板工作负载中表现良好。然而,许多 AI 大数据应用的工作负载 CRD(如 FlinkDeployments,PyTorchJob 和 RayJob 等)包含多个 Pod 模板或组件,每个组件都有独特的资源需求。
在这个版本中,Karmada 强化了对多模板工作负载的资源感知能力,通过扩展资源解释器,Karmada 现在可以获取同一工作负载不同模板的副本数和资源请求,确保数据的精确性。 - 集群级故障迁移功能增强(Alpha)
在之前的版本中,Karmada 提供了基本的集群级故障迁移能力,能够通过自定义的故障条件触发集群级别的应用迁移。
为了满足有状态应用在集群故障迁移过程中保留其运行状态的需求,Karmada 在 v1.15 版本支持了集群故障迁移的应用状态中继机制。对于大数据处理应用(例如 Flink),利用此能力可以从故障前的 checkpoint 重新启动,无缝恢复到重启前的数据处理状态,从而避免数据重复处理。 - 结构化日志
在先前版本中,Karmada 仅支持非结构化的文本日志,难以被高效解析与查询,限制了其在现代化观测体系中的集成能力。
Karmada 在 1.15 版本引入了结构化日志支持,可通过 --logging-format=json 启动参数配置 JSON 格式输出。可无缝对接 Elastic、Loki、Splunk 等主流日志系统,无需依赖复杂的正则表达式或日志解析器。支持结构化字段支持快速检索与分析、关键上下文信息(如集群名、日志级别)以结构化字段呈现。 - Karmada 控制器和调度器性能显著提升(Alpha)
在本次版本中,Karmada 性能优化团队继续致力于提升 Karmada 关键组件的性能,在控制器和调度器方面取得了显著进展。
控制器方面,通过引入优先级队列,控制器能够在重启或切主后优先响应用户触发的资源变更,从而显著缩短服务重启和故障切换过程中的停机时间。调度器方面,通过减少调度过程中的冗余计算,降低远程调用请求次数,Karmada 调度器的调度效率得到了显著提升。
3. Nelm 1.0 发布:Helm-chart 兼容的 Helm 3 替代方案
Nelm 1.0 发布:Helm-chart 兼容的 Helm 3 替代方案
简介
Nelm 是一个开源命令行工具,用于管理 Helm charts 并部署到 Kubernetes。它基于 Helm 3 代码,功能几乎和 Helm 一样,并且有所提升,还增加了额外功能。Nelm 与 Helm charts 和 Helm releases 向后兼容,Helm 用户可轻松迁移。熟悉 werf 的用户会发现,Nelm 就是去掉 giterminism 和容器构建/分发/清理的 werf(即 werf 的部署引擎)。
werf 是一个 CNCF Sandbox CLI 工具,用于构建容器并部署到 Kubernetes,基于 Helm 3 分支,增加了不少新功能和修复。
Nelm 与 Helm 3 相比的优势
- Nelm 的 Helm 部署子系统从零重写。部署时,Nelm 会构建一个有向无环图(DAG),表示所有要在集群中执行的操作,然后按图执行。DAG 让 Nelm 实现了高级资源排序。
- Nelm 用 Server-Side Apply(SSA) 替代了 Helm 里有问题的 3-Way Merge(3WM)。
- Nelm 从零构建了强大的资源追踪功能。
- 部署期间可定期打印相关 Pod 的容器日志,通过注解也可打印资源事件。
- 支持管理加密的 values 文件或任意加密文件,在模板渲染时内存解密,增强安全性。
- nelm release plan install 命令通过可靠的干运行 SSA,精确展示下一次发布将对集群资源造成的改动。
未来规划
未来 Nelm 计划包括:
- 实现 Helm 模板替代方案;
- 支持直接从 Git 拉取 charts;
- 提供公共 Go API,方便第三方集成 Nelm;
- 改进 CLI 体验,增强重实现命令与 Helm 原命令一致性;
- 重构 chart 依赖管理;
- 将内置密钥管理迁移到 Mozilla SOPS。
拓展阅读
计划在 2025 年 11 月中旬的 KubeCon + CloudNativeCon 北美大会上发布。
3. Rancher:新版本特性与改进一览
Rancher 社区双周报 | 聚焦 Rancher:新版本特性与改进一览
Rancher
近期,Rancher 发布了 v2.10.8、v2.11.4 和 v2.12.0 三个版本。其中,v2.10.8 与 v2.11.4 作为补丁版本,主要包含常规的维护更新和 Bug 修复;而 v2.12.0 则是一次重要的社区版小版本发布,带来了大量新特性与改进。
v2.12.0 亮点:
- Kubernetes 支持:新增对 Kubernetes v1.33 的支持;停止支持 v1.30,升级前需确保集群版本 ≥ v1.31。
- 架构支持:正式支持 ARM64 架构集群(混合集群依旧为实验性)。
- 性能提升:Rancher UI 默认开启 Server-Side Pagination(服务端分页缓存),显著提升大规模集群的界面响应速度。需要注意该特性依赖 SQLite 缓存机制,升级前需预留额外磁盘空间。
- UI 与体验优化:新增通知中心、改进 Helm 应用加载速度、支持在 Fleet 工作空间设置默认 OCI 存储,并更新了应用商店和资源详情页的设计。
- 身份与认证:Rancher 现可作为标准 OIDC Provider,支持 SSO,并新增对 Amazon Cognito 的身份认证集成。
- 安全与合规:引入全新的 Rancher Compliance App,替代原有的 CIS Benchmarks,扩展更多安全基线检查能力。
- Continuous Delivery (Fleet):HelmOps 功能脱离实验阶段,默认启用并支持语义化版本与轮询,带来更灵活的 GitOps/HelmOps 部署体验。
- CLI 与 API 增强:Rancher CLI 现已提供 Linux ARM64 二进制;同时引入新的 Rancher Kubernetes API 资源(如 tokens.ext.cattle.io 和 kubeconfigs.ext.cattle.io),便于与 kubectl 等工具集成。
- 日志与审计:API 审计日志(Audit Log)新增启用选项,默认记录请求与响应元数据,提升系统可观测性。
RKE 2
RKE2 发布了 v1.31.12+rke2r1、v1.32.8+rke2r1 和 v1.33.4+rke2r1 三个版本,对 Kubernetes 主版本进行了更新,并带来了一系列组件升级与问题修复。
主要更新内容:
- Kubernetes 与 Go 更新
- 升级至 Kubernetes v1.31.12、v1.32.8 和 v1.33.4。
- Go 版本同步更新至 1.23.11(v1.31 与 v1.32)以及 1.24.5(v1.33)。
- 网络与存储组件更新
- Cilium 升级至 v1.18.0。
- vSphere CSI 升级至 3.3.1-rancher10。
- ingress-nginx 升级至 v1.12.4-hardened7,增强安全性。
- CoreDNS 升级至 1.43.100,对应 Chart 与镜像均已更新。
- Kubernetes Metrics Server Chart 更新至 3.13.0。
- 功能与修复
- 改进静态 Pod 模板生成与清理机制,优化集群稳定性。
- 修复 ECM 配置缺失、上传认证问题。
- 修复 K3s 相关指标与事件问题,并合并证书启动检测修复。
- 新增 Prime Ribs index 上传与缓存失效逻辑,提升镜像索引处理能力。
Rancher Desktop
Rancher Desktop 发布了 v1.20.0,本次更新带来了更强的容器管理能力和系统适配改进。容器面板现在支持实时查看日志与自动刷新,容器按 Pod、docker-compose 或独立容器分组显示。同时新增 Volumes 页面 便于管理存储卷,并引入 rdctl reset命令,支持灵活清理 VM、Kubernetes 部署和缓存。
K3S
K3s 发布了 v1.30.14+k3s2、v1.31.12+k3s1、v1.32.8+k3s1 和 v1.33.4+k3s1 多个版本更新,涵盖 Kubernetes 升级、组件更新和功能增强。
NeuVector
NeuVector 发布 v5.4.6,本次版本重点优化安全策略与规则管理,同时修复若干漏洞与运行异常。
4. ORAS v1.3.0:提升制品和注册表管理流程
宣布 ORAS v1.3.0 —— 提升你的制品和注册表管理流程
简介
ORAS 是用于处理 OCI Artifacts 的事实标准工具。它将媒体类型视为该难题中至关重要的一环。它绝不会想当然地认为容器镜像是唯一的关注对象。ORAS 提供 CLI 和客户端库,用于在符合 OCI 标准的镜像仓库之间分发工件(artifacts)。
主要功能
- 工件引用
- 将供应链工件附加到容器镜像。
- 发现并展示工件引用关系。
- 扩展镜像仓库的功能,使其不仅用于存储容器镜像。
- 分布式软件工件
- 在 OCI 镜像仓库中管理工件。
- 在镜像仓库之间迁移工件。
- 通过 OCI 镜像布局在文件系统中管理工件。
- 探索和管理 OCI 镜像
- 在 OCI 镜像仓库中管理镜像清单(manifest)和层(layer)。
- 在 OCI 镜像仓库中操作标签(tag)和仓库(repository)。
- 探查 OCI 镜像的详细内容。
新特性
本次版本推出三大新特性,助力提升制品和注册表管理效率:
- 仓库和制品的便携式备份和恢复
- 多平台镜像与制品管理
- 丰富格式化输出,支持脚本和流水线
📰 专题二 新闻与访谈
1. Chainguard 决定 fork Kaniko 并接管其维护工作
Fork Yeah: We’re Bringing Kaniko Back
Kaniko 最初由 Priya Wadhwa(@priyawadhwa)、Dan Lorenc(dlorenc) 和 Google 的其他人员创建,并发布于 GoogleContainerTools/kaniko。该项目于 2025 年 6 月存档,并由 Chainguard(包括 Priya 和 Dan)分叉,到 chainguard-dev/kaniko 继续维护安全补丁和项目维护。
没有计划进行任何重大功能开发,但欢迎修复错误和其他小贡献。
如果出现另一个活跃且社区支持的分支,将很乐意关闭这个分支并迁移到那个分支。
2. ESO 维护者更新 – 下一步
ESO Maintainer Update – Next Steps
书接上文:ESO 项目发布暂停,直至维护团队重建
目前情况
- 上个月的求助帖发布后,ESO 收到了全球 300 多人报名希望提供帮助。
- ESO 更新了治理模式,
- 引入贡献者阶梯:贡献者(Contributor)→ 成员(Member)→ 评审员(Reviewer)→ 维护者(Maintainer)。
- 设立专门的“赛道”(tracks),包括测试、CI/CD、核心代码和提供者相关代码,以满足不同技能的贡献者。
- 为了快速应对当前需求,ESO 任命了 2 名临时维护者。一位是项目创始成员,另一位在 CNCF 有维护其他项目的经验并与团队有联系。
未来计划
- 暂时仍不会恢复发布新版本。
- 建立一个“健康的贡献生命周期”,通过新的贡献者阶梯进行实践、测试和调整,以确保项目能够可持续发展。这一过程至少需要 6 个月。
如何帮助
- 协助 triage 问题/讨论。
- 贡献代码。
- 表达参与“倡议”的兴趣。
- Review PRs。
- 直接贡献到某个特定的“赛道”。
拓展阅读
External Secrets Operator Health update - Resuming Releases
ESO 将于 9 月 22 日继续发布。
3. CNCF 通过与 Docker 合作,扩展对项目维护者的基础设施支持
CNCF 通过与 Docker 合作,扩展对项目维护者的基础设施支持
2025 年 9 月 18 日,Cloud Native Computing Foundation®(CNCF®)宣布与 Docker, Inc.® 达成新合作,进一步扩展对 CNCF 托管项目的安全、可扩展支持。通过此次合作,所有 CNCF 项目将直接接入 Docker 的赞助开源计划(DSOS),该计划通过开放高端注册表、安保和支持服务,助力开源社区成长与成功。
通过 DSOS 计划,CNCF 项目将享受:
- Docker Hub 无限镜像拉取
- 赞助开源身份,提升信任和曝光度
- 使用 Docker Scout 进行漏洞分析和策略执行
- 从源码自动构建镜像
- 获取 Docker 使用数据和参与度洞察
- 通过开源渠道简化支持流程
总的来说,对于 CNCF,这项合作意味着为其托管项目提供了更坚实、更安全的基础设施支持;对于 Docker,则代表着将其核心服务和安全能力更深地融入到云原生生态系统的核心,扩大了其市场影响力和品牌认可度。
4. 重构 Nutanix Kubernetes 平台,实现与 Cilium 一致的体验
Refactoring Nutanix Kubernetes Platform for a Consistent Experience with Cilium
背景
Nutanix 需要为其托管 Kubernetes 平台 (NKP) 提供更现代、更高效且更易于管理的 CNI,尤其是在现有解决方案配置复杂且性能优化不足的情况下。客户还需要虚拟机和 Kubernetes Pod 之间实现无缝网络连接。
方案
Nutanix 已将 Cilium 用作 NKP 中的默认 CNI。选择 Cilium 的原因在于其简洁易用、文档完善,以及 DSR、Hubble 可观测性和基于身份的安全性等高级功能 —— 所有这些功能均由 eBPF 提供支持。
价值
- 简化操作
- 功能丰富
具有直接服务器返回 (DSR) 等功能,可以有效替代传统的覆盖网络,其基于身份的安全模型和可调的 eBPF 映射大小使其成为具有严格安全要求的高性能环境的理想选择。 - 实现 Kubernetes 集群和 VM 之间的无缝联网
仍然有一些工作负载在虚拟机上运行效果最佳。希望客户能够掌控在虚拟机或 Kubernetes 上部署,并能够无缝跨越这一界限。Cilium 让用户能够轻松查看流量,并定义在同一环境中运行的虚拟机和 Kubernetes 集群之间的网络策略。
Cilium 支持源 IP 保存,从而实现更精确的流量控制和跨环境策略实施。Hubble 还提供集群内部以及虚拟机、Kubernetes Pod 和服务之间的流量可见性,使统一网络控制变得简单直观。
5. KubeSphere 社区版即将发布:开启云原生新篇章
原因
技术门槛依然是很多团队面临的挑战,同时不同规模的团队有着不同的需求:
- 个人开发者需要轻量易用的容器管理工具
- 中小团队希望降低云原生技术的使用门槛
- 社区用户期待更灵活的部署选择
基于这些需求,推出了 KubeSphere 社区版,希望它成为连接技术与用户的桥梁。
功能范围
包含了构建和管理云原生应用的全部核心功能。提供集群管理、多租户管理、K8s 资源管理、应用管理等容器管理平台必备能力,涵盖从容器编排到微服务治理,从 CI/CD 到可观测性的完整技术栈。
将复杂的 Kubernetes 操作转化为可视化界面。创建 K8s 资源,都可通过图形化界面快速完成。同时保留原生能力:支持 YAML 编辑模式,内置终端随时切换命令行模式,可以在简便操作与精细控制之间自由切换。
社区版与企业版
-
社区版
- 目标用户:个人开发者、中小型团队、小规模生产业务的团队。
- 费用:免费。
- 功能范围:功能完整的容器管理平台。
- 技术支持服务:无。
- 使用场景:小规模生产环境。
-
企业版
- 目标用户:较大的企业级用户。
- 费用:需购买许可。
- 功能范围:在社区版基础上提供更强的性能保障、更丰富的企业级特性。
- 技术支持服务:有。
- 使用场景:大规模生产环境。
6. OpenSearch 宣布成立 Observability TAG:共塑开源观测未来
OpenSearch 宣布成立 Observability TAG:共塑开源观测未来
背景
OpenSearch 项目累计下载超过 10 亿次,来自 30 多家机构的 1000 多名开发者参与贡献,GitHub 上仓库数量超 140 个。随着 OpenSearch 组件不断丰富,涵盖观测、搜索、安全、AI/ML 工作流等多种场景,对跨堆栈的端到端观测技术视角需求日益增长。这样可以推动统一、经济高效的观测解决方案,原生结合生态系统,并遵循如 OpenTelemetry 等演进中的标准。
基于这种势头和社区需求,OpenSearch 项目宣布成立 Observability 技术咨询组(TAG)。该组隶属于技术指导委员会,负责为 OpenSearch 生态内的观测方案提供战略和技术指导。Observability TAG 于 2025 年 9 月 2 日召开首次会议,参与者包括 AWS、SAP、Apple 和 Hilti。成员还来自 Uber、Paessler 等多家机构,代表了观测社区的广泛声音。
Observability TAG 简介
Observability TAG 的宗旨是定义、倡导并推广最佳实践,帮助用户高效利用 OpenSearch 实现各种遥测数据的采集、存储和可视化。该组将向技术指导委员会提供建议,确保 OpenSearch 与开放标准、互操作性、行业趋势及社区需求保持一致。
Observability TAG 重点关注以下领域:
- 为基于 OpenSearch 的观测应用提供技术指导,包括指标、日志、追踪、性能分析的存储,数据采集流水线,数据可视化、仪表盘及告警、异常检测等插件。
- 结合行业趋势及 CNCF 观测指南,与 OpenTelemetry、Prometheus、Jaeger、Fluent Bit 等外部项目协作,推动 OpenSearch 观测方案的标准化和互操作性。
- 制定 OpenSearch 观测部署的最佳实践,覆盖采集流水线、告警、可视化及运维监控,同时促进社区成长与采用。
7. VMware vSphere 版本 7 产品支持终止通知
提醒:VMware vSphere 版本 7 产品支持终止通知
VMware vSphere 7.x 和 VMware vSAN 7.x 产品的通用支持将于 2025 年 10 月 2 日终止。届时,仍在运行 vSphere 7.x 和/或 vSAN 7.x 的客户将不再能获得产品支持、安全补丁及更新。
此外,自 2025 年 10 月 2 日起,博通技术支持团队将不再为这些版本提供服务。
也可以为满足一定条件的客户提供官方延长支持服务,如需更多信息,请联系您的博通销售代表、合作伙伴或博通支持团队。
8. Rancher 创始人从 Kubernetes 转向 Agentic AI
Why Rancher’s Founders Pivoted From Kubernetes to Agentic AI
梁胜曾创立 Cloud.com(后来被 Citrix 收购)和 Rancher Labs(后来被 SUSE 收购)。现在创立了 Obot.ai。
Acorn Labs 最初专注于简化 Kubernetes 上的应用程序部署。后正式更名为 Obot.ai,并获得了 3500 万美元的种子轮融资。团队认为 Agentic AI 是一种全新的计算范式,不仅仅是又一个需要容器化的工作负载。AI 开发者更倾向于使用自然语言提示和源代码,而不是二进制容器,这使得他们之前的 Kubernetes 运行时不再完全适用。
Obot.ai 的目标是成为企业 AI 堆栈的基础组件,其中 Obot MCP Gateway 扮演“企业工具应用商店”的角色,提供安全和治理;而 Nanobot 则提供构建和运行这些代理的“SDK 和运行时”。
💬 专题三 讨论与分享
1. 用户反馈调查:构建多集群管理和监控工具
User feedback Survey: Building Multi cluster Management and Monitoring tool.
Kubernetes SIG 多集群用户体验工作组正在收集用户、运维人员和开发者对多集群环境实际使用情况的反馈。
预计需要 10-15 分钟,详细答案将仅与多集群 SIG 领导层和进行用户访谈的团队共享。匿名汇总数据可能会通过多集群 SIG 公开分享。
2. HAMi 的产品营销
「全球共建:vLLM 社区原生支持 HAMi,推理效率飞跃」— 来自西班牙开发者的贡献
Virtualizing Any GPU on AWS with HAMi: Free Memory Isolation
🎤 相较于其他国内产品,算是目前看到的营销文章质量很高的产品了。
3. OCI 制品如何推动未来的 AI 应用场景
背景
随着 AI 的发展,目前虽然已有像大型语言模型(LLMs)这样的通用高级工具,但许多领域专用解决方案仍缺乏,或者开发成本和风险较高,尤其是针对小众问题时。这带来了一个重要挑战:如何避免形成分散、实际应用有限的 AI 工具生态?
OCI 制品是什么
OCI 是一个开放的治理结构,其明确目的是围绕容器格式和运行时创建开放的行业标准。OCI 由 Docker 和其他容器行业领导者于 2015 年 6 月创立,目前包含三个规范:运行时规范 (runtime-spec)、镜像规范 (image-spec) 和分发规范 (distribution-spec)。
简单来说,OCI 就像是容器世界的 “ISO 标准组织”。它不创建具体的容器产品(例如 Docker 或 Podman),而是制定一套规范,让所有容器工具和平台都遵循相同的规则。
CNCF ModelPack 是什么
云原生计算基金会 (CNCF) 的 ModelPack 项目是一个供应商中立的开源规范标准,用于在云原生环境中打包、分发和运行 AI 模型。该项目的目标是创建符合标准的实现,将 AI/ML 项目工件从供应商控制的专有格式转变为与云原生生态系统兼容的标准化、可互换的格式。
总结
容器运行时(如 CRI-O)必须作为低层 OCI 标准和高层 Kubernetes 功能之间的桥梁。
CRI-O 最新版本已原生支持 OCI 制品,专门存储在独立目录,避免与传统容器镜像文件混淆。这带来多项 AI 相关功能:
- 在 Kubernetes 中将 OCI 制品挂载为 Image Volume
- 附加模型、配置文件,甚至通过多个 OCI 制品组装完整容器文件系统
其中一个显著优势是架构无关性。OCI 制品可跨平台,适合存储配置文件或其他跨平台资源。需要架构特定二进制时,CRI-O 也支持多架构清单(v1.33 起),如 ghcr.io/cri-o/bundle:v1.33.3 可自动选择合适架构版本。
CRI-O 还在探索支持以 OCI 制品形式存储的 WebAssembly(Wasm)二进制文件,目前通过 crun 运行时支持。这有望扩展基于制品的轻量级便携计算平台应用。
尽管已有进展,OCI 制品在功能上仍未完全赶上传统容器镜像,比如:
- sigstore 签名验证尚未完全支持,但已列入计划
- 计划支持针对大文件(如数据集、日志)压缩的制品层
- 读写 Image Volume 挂载的更灵活支持,既简化分发又保证运行时安全
- 随着这些能力成熟,OCI 制品将在构建可扩展、安全、便携的 AI 系统中变得更加关键。
4. AI Agents vs. Agentic AI
AI Agents vs. Agentic AI: A Kubernetes Developer’s Guide
什么是 AI Agent
AI Agent 是独立的自主软件实体,通过工具集成和快速工程执行特定任务。可以将它们视为具有 AI 功能的单一用途微服务。每个代理负责一项明确定义的职责,例如处理客户查询、重置密码或分析日志。它们采用请求-响应模式运行,并且通常在交互之间保持最低限度的状态。
一个简单的 AI 代理通常包含一个 AI 模型和一些运行时逻辑。它还可以与内存存储或工具集成以扩展其功能。
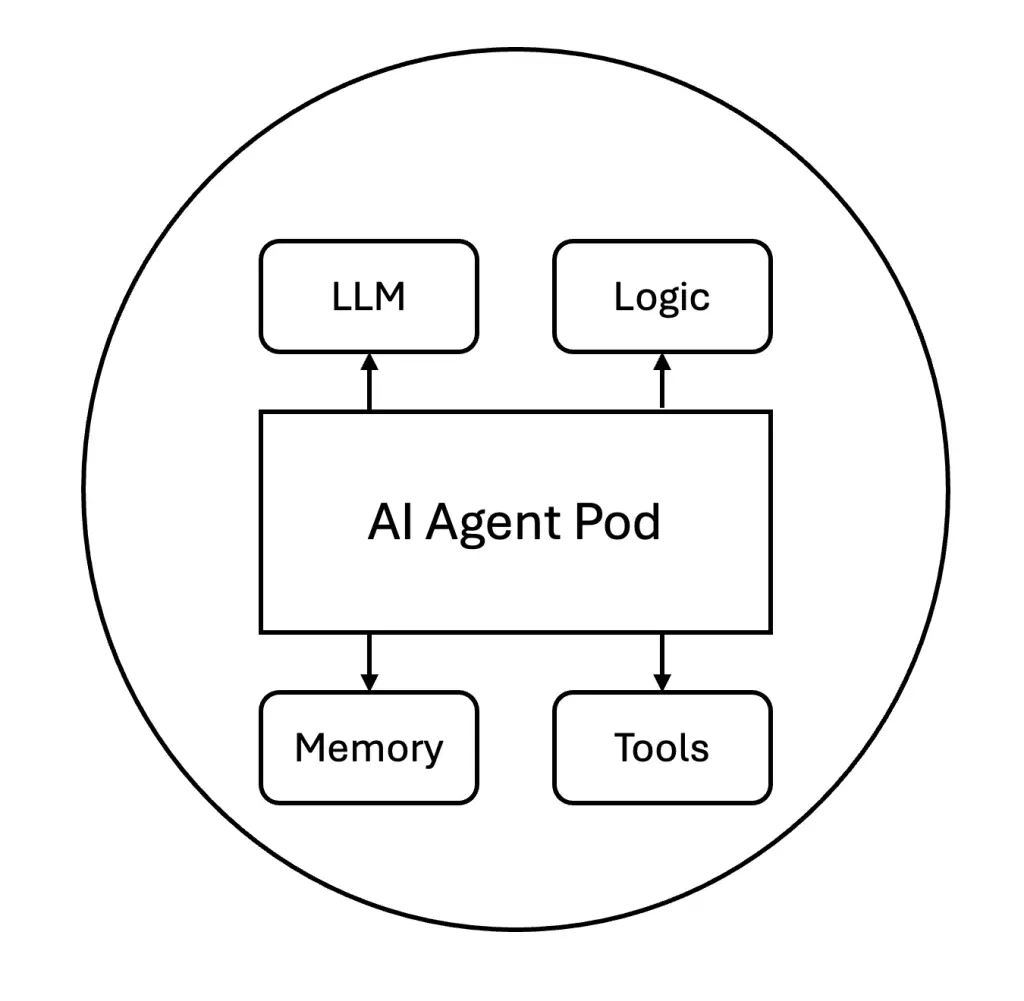
在此图中,代理(在 Pod 中运行)连接到向量数据库(充当其内存),并在需要时通过 API 调用外部工具服务。向量数据库(内存)类似于 Sidecar 数据库,允许代理存储或检索上下文,就像微服务可能使用缓存或数据库一样。
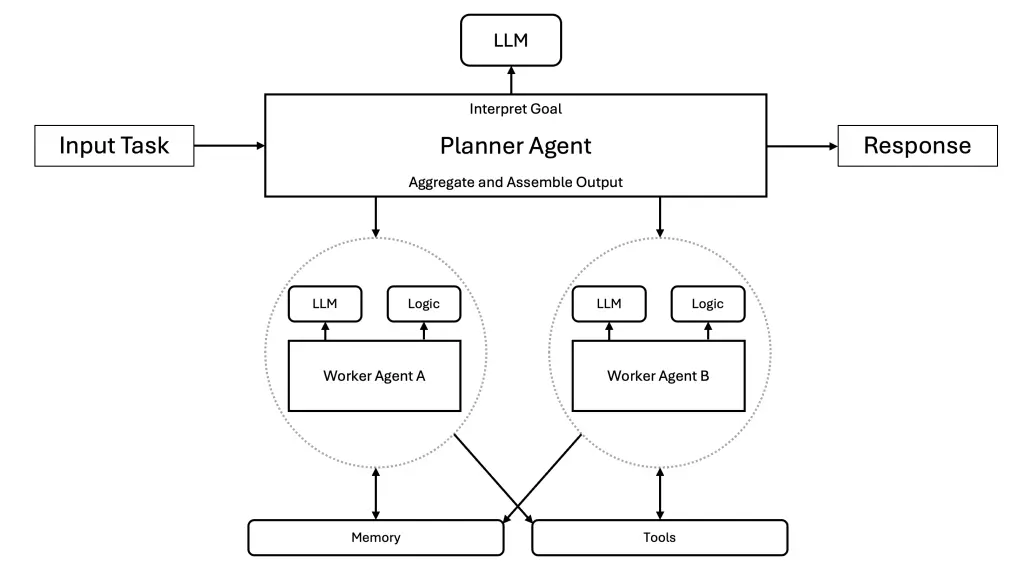
什么是 Agentic AI
Agentic AI 代表着更为复杂的事物。这类系统由多个 AI 代理组成,它们通过编排、持久内存和自主决策功能协同工作。如果说 AI 代理是微服务,那么 Agentic AI 则涵盖您的整个部署,包括服务网格和事件驱动架构。该系统可以将复杂问题分解为子任务,在专用代理之间进行协调,并根据经验调整策略。
代理可以通过多个步骤自我修正和优化其方法。正因如此,代理型人工智能通常被描述为由多个自主代理协同工作,以处理单个代理无法完成的相互依赖的任务。这在概念上类似于在 Kubernetes 上运行分布式工作流,其中每个步骤由不同的服务处理。然而,在这种情况下,每个步骤/代理都拥有自主权,可以自行决定如何完成其部分任务。
5. 优雅关机:一份优雅关闭指南
Terminating elegantly: a guide to graceful shutdowns
优雅关机简介
优雅关机是一种礼貌地停止程序的方式,让程序有时间干净利落地完成任务。
良好的正常关机具有以下特点:
- 完成正在进行的请求(任务)
- 释放关键资源
- 可能将状态信息保存到磁盘或数据库(以便您稍后可以恢复)
- 停止接受连接
Pod 关闭流程
当一个 pod 终止时,它会涉及一个明确定义的生命周期。Kubernetes 还会给 pod 时间来完成正在进行的请求,并在删除它们之前干净地关闭它们。
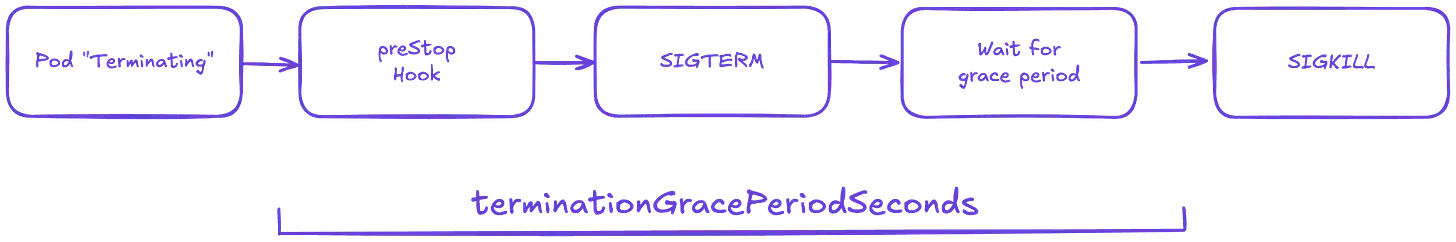
- Pod 被设置为“Terminating”状态,并从所有服务的 Endpoints 列表中移除。此时,Pod 将停止接收新的流量。Pod 中运行的容器不会受到影响。
- 如果定义了 preStop Hook,则会执行该 Hook。preStop Hook 是一个特殊的命令或 http 请求,它会发送到 Pod 中的容器。如果您使用第三方代码或管理一个您无法控制的系统,那么 preStop Hook 非常有用,它是一种无需修改应用程序即可触发正常关闭的好方法。
- SIGTERM 信号会发送到每个容器内的进程 1。您的代码应该监听此事件,并在此时开始干净地关闭进程。这可能包括停止任何长连接(例如数据库连接或 WebSocket 流)、保存当前状态或类似操作。即使您使用了 preStop 钩子,也务必测试发送 SIGTERM 信号后应用程序会发生什么情况,以免在生产环境中出现意外!
- 此时,Kubernetes 会等待一段指定的时间,称为终止宽限期。默认情况下,该时间是 30 秒。需要注意的是,preStop 钩子必须执行完毕后才能发送 TERM 信号。
- 当宽限期到期时,如果 Pod 中仍有容器在运行,kubelet 将触发强制关闭。容器运行时会向 Pod 中任何容器中仍在运行的进程发送 SIGKILL 信号。此时,所有 Kubernetes 对象也会被清理。
🎤 更多细节以及验证介绍见原文。
6. Kubernetes 部署十大错误:原因、修复方法以及技巧
Top Kubernetes (K8s) Troubleshooting Techniques – Part 1
Top Kubernetes (K8s) Troubleshooting Techniques – Part 2
Top 10 Kubernetes Deployment Errors: Causes and Fixes (And Tips)
三个关键原因
- 声明式配置出错
- 声明式配置文件中哪怕出现一个小错误(例如拼写错误、缩进错误或缺少字段),应用程序都将无法正确部署。
- 此外,有时文件是有效的 YAML,但对 Kubernetes 无效。例如,您可能忘记设置副本数量,或者指向尚不存在的服务。这些小错误可能很难发现,但一旦发现就很容易修复。
- 镜像和资源限制
- 容器镜像是 Kubernetes 运行的应用程序。如果镜像名称错误或未推送到镜像仓库,Kubernetes 就无法拉取镜像,应用程序也无法启动。
- 未为 Pod 设置足够的 CPU 或内存。如果 Pod 请求的资源超过可用资源,Kubernetes 可能会延迟它或将其保持在“待处理”状态。
- 节点和集群级别
- 如果节点已满、离线或出现问题,应用可能无处可运行。
- 集群的网络或存储设置也可能存在问题。例如,Pod 可能无法连接到其他服务,或者由于存储不可用而崩溃。
十种常见错误及排除方法
- CrashLoopBackOff
- 说明:此错误意味着 Pod 启动后崩溃,然后反复尝试重启。通常情况下,容器内的应用程序启动后立即失败时就会发生这种情况。
- 排除方法:
- 运行 kubectl logs < pod-name > 来查看应用程序崩溃的原因。
- 检查启动命令或环境变量。
- 确保所有必需的文件、服务或依赖项均可用。
- ImagePullBackOff / ErrImagePull
- 说明:当 Kubernetes 无法下载容器镜像时,就会出现这些错误。这可能是因为镜像名称错误、镜像仓库需要登录或镜像不存在。
- 排除方法:
- 检查 YAML 文件中的镜像名称和标签。
- 确保镜像已推送到容器镜像仓库。
- 如果是私人镜像仓库,请添加有效的镜像拉取密钥。
- OOMKilled
- 说明:OOM 代表内存不足。此错误表示容器使用的内存超出了允许的上限,因此已被系统关闭。
- 排除方法:
- 增加部署文件中的内存限制。
- 优化应用程序以使用更少的内存。
- 使用 kubectl describe pod < pod-name > 检查内存限制和使用情况。
- CreateContainerConfigError
- 说明:此错误表示 Pod 设置存在错误。可能是 Secret、配置映射或卷设置错误。
- 排除方法:
- 使用 kubectl describe pod < pod-name > 查看详细的错误消息。
- 检查 YAML 中是否引用了机密、配置映射或卷。
- 确保路径和键正确。
- NodeNotReady
- 说明:此错误表示集群中的某个节点无法运行 Pod。该节点可能已关闭或断开连接。
- 排除方法:
- 使用 kubectl get nodes 检查节点状态。
- 查看 kubectl describe node < pod-name > 了解更多信息。
- 根据问题重新启动或修复节点。
- Pod 卡在 Pending 状态
- 说明:处于“Pending”状态的 Pod 尚未启动。这通常意味着资源(CPU 或内存)不足,或者卷不可用。
- 排除方法:
- 运行 kubectl describe pod < pod-name > 来找出其待处理的原因。
- 检查集群是否有足够的可用资源。
- 确保存储卷或节点选择器正确。
- FailedScheduling
- 说明:此错误表示 Kubernetes 找不到符合 Pod 要求的节点。它通常与资源限制或调度规则有关。
- 排除方法:
- 使用 kubectl describe pod < pod-name > 查看调度详情。
- 减少 pod spec 中的 CPU 或内存请求。
- 检查是否正在使用任何可能阻止调度的节点选择器或污点。
- ContainerCannotRun
- 说明:这意味着容器根本启动失败。可能是因为入口点命令错误,或者容器没有所需的权限。
- 排除方法:
- 使用 kubectl logs < pod-name > 或者 describe pod 查看错误。
- 确保 YAML 中的命令和参数正确。
- 检查是否有丢失的文件、损坏的权限或所需的访问权限。
- Exit Code 1 / 125
- 说明:这些退出代码表示应用启动后立即失败。代码 1 通常表示一般错误。代码 125 可能表示容器命令在应用运行之前就失败了。
- 排除方法:
- 使用 kubectl logs < pod-name > 查看错误输出。
- 仔细检查您的输入命令、环境变量和依赖项。
- 尝试使用 docker run 在本地运行该镜像来测试它。
- 处于初始化/等待循环的 Pod
- 说明:有时,Pod 会停留在“Init”或“Waiting”状态太久。这是因为 Init 容器或主容器无法正常启动。
- 排除方法:
- 使用 kubectl describe pod < pod-name > 来检查是什么阻碍了事情的发生。
- 确保初始化容器成功完成。
- 检查镜像名称、卷挂载和启动脚本。
通用故障排除框架
- kubectl describe pod < pod-name >
- kubectl get events, kubectl logs
- kubectl apply –dry-run=client
- kubectl top pod 或者仪表盘工具
- YAML 中的 Liveness 和 readiness 探针
预防错误的技巧
- 自动化验证 YAML 文件中的错误
- 为容器设置 CPU 和内存请求及限制
- 监控资源使用情况
7. 在 Harvester 上安装 Rancher 的三种方法
手把手教你在 Harvester 上安装 Rancher 的三种方法
Harvester 是什么
简介
Harvester 是一款基于 Kubernetes 构建的现代、开放、可互操作的超融合基础设施 (HCI) 解决方案。它是一款开源替代方案,专为寻求云原生 HCI 解决方案的运营商而设计。Harvester 可在裸机服务器上运行,并提供集成的虚拟化和分布式存储功能。除了传统的虚拟机 (VM) 之外,Harvester 还通过与 Rancher 集成自动支持容器化环境。它提供了一种解决方案,可以统一传统的虚拟化基础设施,同时支持从核心到边缘位置的容器化应用。
主要功能
- 易于安装:由于 Harvester 作为可启动设备映像提供,因此可以使用 ISO 映像将其直接安装在裸机服务器上,或者使用 iPXE 脚本自动安装它。
- VM 生命周期管理:轻松创建、编辑、克隆和删除 VM,包括 SSH-Key 注入、cloud-init 以及图形和串行端口控制台。
- VM 实时迁移支持:将 VM 移动到不同的主机或节点,且零停机时间。
- 虚拟机备份、快照和还原:从 NFS、S3 服务器或 NAS 设备备份虚拟机。使用备份还原故障的虚拟机或在其他集群上创建新的虚拟机。
- 存储管理:Harvester 支持分布式块存储和分层。卷代表存储;可以轻松创建、编辑、克隆或导出卷。
- 网络管理:支持使用虚拟 IP (VIP) 和多个网络接口卡 (NIC)。如果您的虚拟机需要连接到外部网络,请创建 VLAN 或未标记网络。
- 与 Rancher 集成:通过 Rancher 的虚拟化管理页面直接在 Rancher 内访问 Harvester,并与 Kubernetes 集群一起管理 VM 工作负载。
架构
- Longhorn 是 Kubernetes 的一个轻量级、可靠且易于使用的分布式块存储系统。
- KubeVirt 是 Kubernetes 的虚拟机管理插件。
- Elemental for SLE-Micro 5.3 是一个不可变的 Linux 发行版,旨在尽可能地消除 Kubernetes 集群中的操作系统维护。
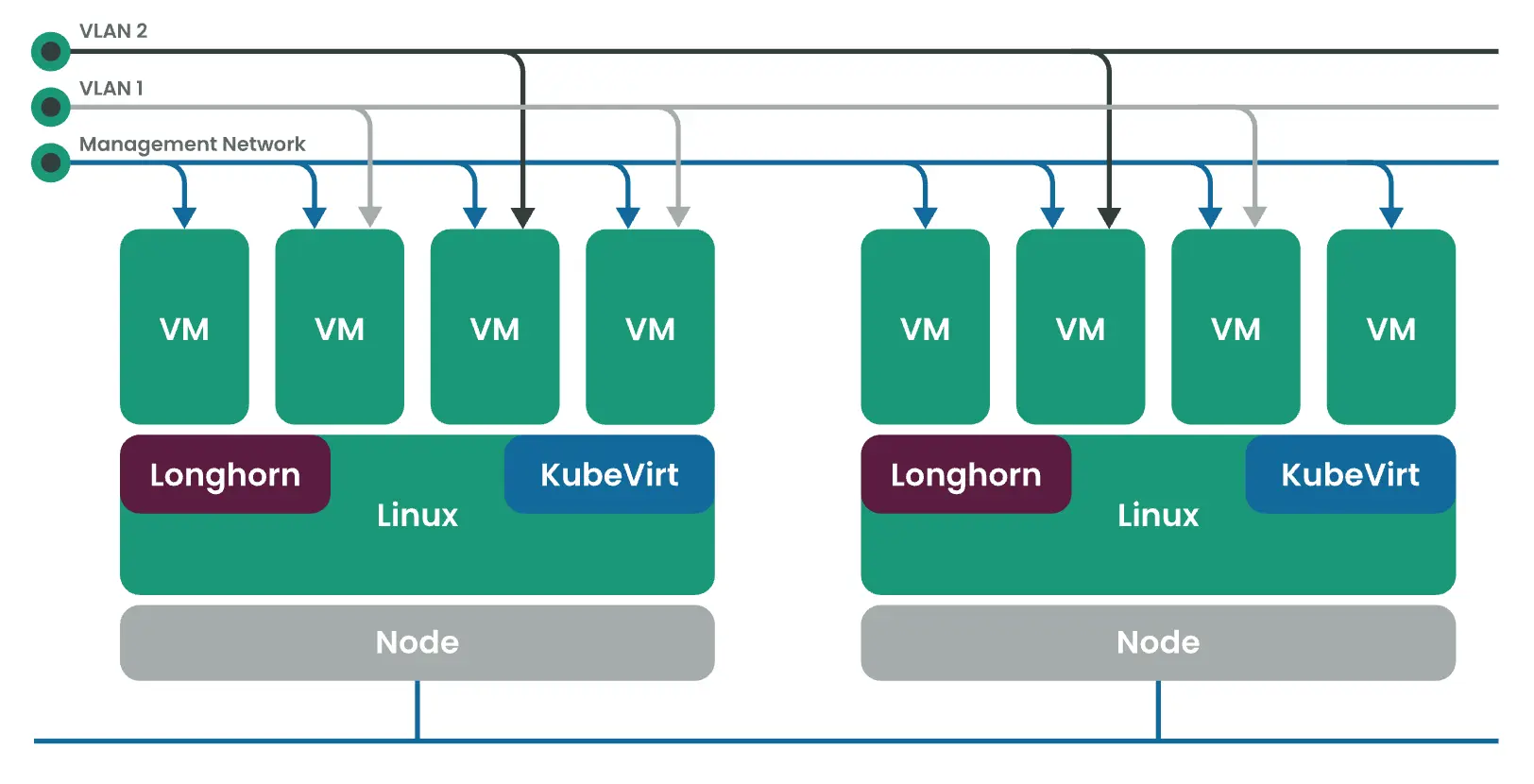
三种方法
- Helm
- Fleet
- CAPI
具体内容见原文。
8. 继续学习 Kubernetes v1.34 新特性
🎤 9 月还是陆续有很多文章、博客在分析和介绍 1.34 的新特性。这场宣传绵延数月,正好也结合人的学习曲线,需要多多重复保证消化。所以会继续收集和总结这些内容,加深理解。
a. 压力失速信息 (PSI) 指标升级到 Beta 版本
Kubernetes v1.34: PSI Metrics for Kubernetes Graduates to Beta
PSI 是什么
压力失速信息,Pressure Stall Information (PSI) 是 Linux 内核(4.20 及更高版本)的一项功能,它提供了一种规范的方法来量化基础设施资源的压力,即资源需求是否超过当前供应。它超越了简单的资源利用率指标,而是测量由于资源争用而导致任务停滞的时间。这是一种识别和诊断可能影响应用程序性能的资源瓶颈的有效方法。
PSI 公开 CPU、内存和 I/O 的指标,分为 some 压力或 full 压力:
- some
至少有一项任务在资源上停滞的时间百分比。这表明存在一定程度的资源争用。 - full
所有非空闲任务同时在资源上停滞的时间百分比。这表明资源瓶颈较为严重。
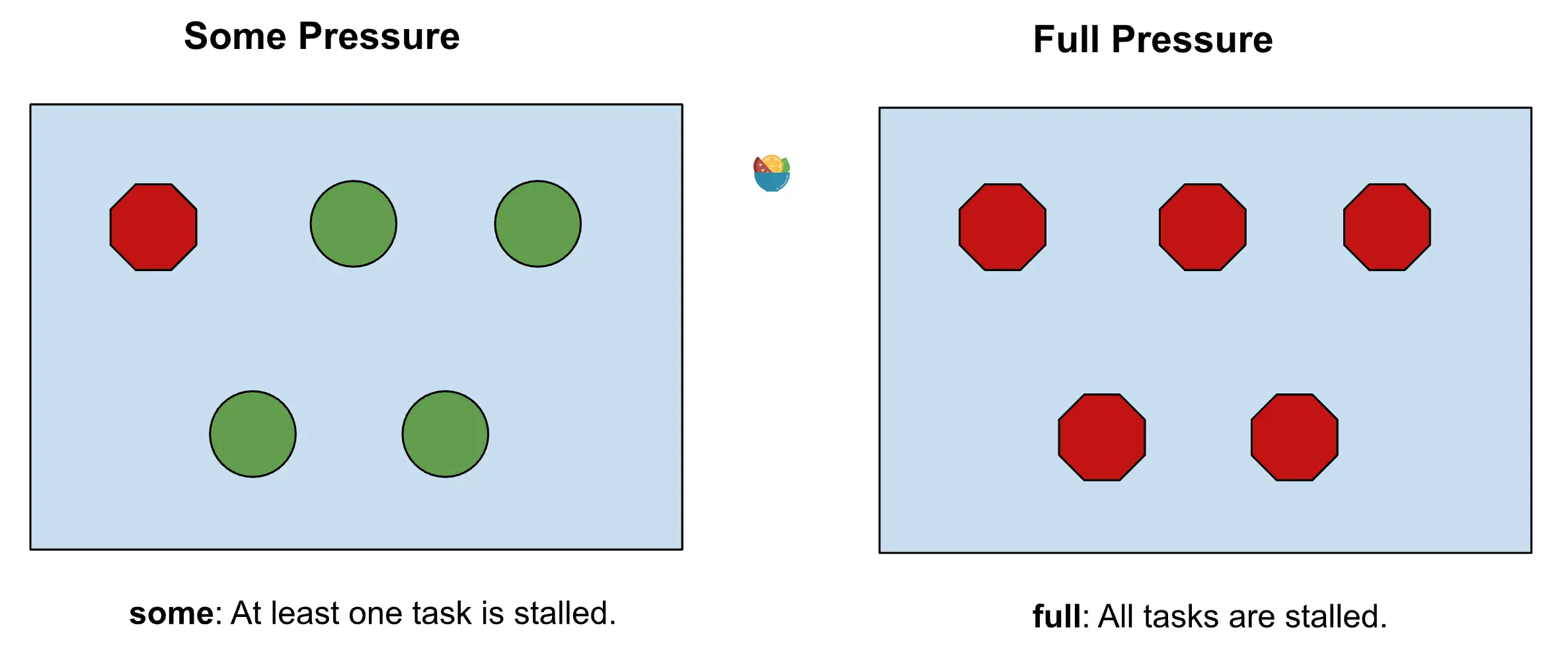
Kubernetes 中的 PSI 指标
启用 KubeletPSI 特性门控后,kubelet 现在可以收集 Linux 内核的 PSI 指标,并通过两个渠道公开这些指标: Summary API 和 /metrics/cadvisor Prometheus 端点。
可以使用这些指标来执行以下操作:
- 识别内存泄漏:内存 some 的稳步增加可能表明应用程序存在内存泄漏。
- 优化资源请求和限制:通过了解工作负载的资源压力,可以更准确地调整其资源请求和限制。
- 自动扩展工作负载:可以使用 PSI 指标来触发自动扩展事件,确保工作负载拥有实现最佳性能所需的资源。
如何启用
- 确保节点运行的是 Linux 内核版本 4.20 或更高版本,并且使用 cgroup v2。
- 在 kubelet 上启用 KubeletPSI 功能门控。
b. 对容器重启的细粒度控制
Kubernetes v1.34: Finer-Grained Control Over Container Restarts
Pod 粒度重启的问题
在此功能之前,restartPolicy 是在 Pod 级别设置的。这意味着 Pod 中的所有容器共享相同的重启策略(Always、OnFailure 或 Never)。虽然这适用于许多用例,但在其他用例中可能会受到限制。
例如,假设一个 Pod 包含一个主应用容器和一个用于执行一些初始设置的 init 容器。可能希望主容器在发生故障时始终重新启动,但 init 容器应该只运行一次并且永不重新启动。如果只使用单一的 Pod 级重启策略,这是不可能的。
容器粒度重启的简介
使用新的 ContainerRestartRules 功能门控,现在可以指定 Pod 规范中每个容器的 restartPolicy。还可以定义 restartPolicyRules 可根据退出代码控制重启。这提供了处理复杂场景所需的细粒度控制。
使用场景
- 就地重启训练作业
在机器学习研究中,协调大量长时间运行的 AI/ML 训练工作负载是很常见的。在这些情况下,当工作负载失败并返回可重试的退出代码时,可以确保容器能够快速重启,而无需重新调度整个 Pod,节约大量的时间和资源。 - 尝试一次 Init 容器
Init 容器通常用于执行主容器的初始化工作,例如设置环境和凭据。有时,希望主容器始终重新启动,但又不想在初始化失败时重试。 - 包含多个容器的 Pod
对于运行多个容器的 Pod,每个容器的重启要求可能有所不同。有些容器可能对成功有明确的定义,并且应该仅在失败时重启。而有些容器可能需要始终重启。
c. 用户偏好设置(kuberc)可在 kubectl 1.34 中进行测试
Kubernetes v1.34: User preferences (kuberc) are available for testing in kubectl 1.34
通过一个名为 kuberc 的配置文件来管理这些偏好设置。该文件默认位于 kubeconfig 目录 ($HOME/.kube) 中,也可以通过 --kuberc 选项或 KUBERC 环境变量指定其位置。
d. DRA 升级至 GA
Kubernetes v1.34: DRA has graduated to GA
DRA 简介
DRA 提供了一个灵活的框架,用于管理专用硬件和基础设施资源,例如 GPU 或 FPGA。DRA 提供的 API 允许每个工作负载指定其所需设备的属性,但实际设备的分配则交由调度程序完成,从而提高可靠性并提高昂贵硬件的利用率。
Beta 子功能
- 管理员访问标签 (Admin access labelling):可以将设备支持限制为授权使用该设备的人员(或软件)。
- 优先级列表 (Prioritized list):用户为其工作负载指定可接受的设备列表,而不仅仅是单一类型的设备。
- kubelet 的 API 更新:可报告通过 DRA 分配的 Pod 资源。
Alpha 子功能
- 扩展资源映射 (Extended resource mapping):允许集群管理员将 DRA 管理的资源作为扩展资源进行发布,从而允许开发人员使用熟悉且更简单的请求语法来使用这些资源,同时仍然受益于动态分配。
- 可消耗容量 (Consumable capacity):允许来自不相关 Pod 的多个独立资源请求各自分配到同一底层物理设备的份额。这项新功能通过管理员定义的可选共享策略进行管理,这些策略控制平台如何针对每个请求划分和执行设备的总容量。这允许在预定义分区不可行的情况下共享设备。
- 绑定条件 (Binding conditions):允许 Kubernetes 调度程序延迟将 Pod 绑定到节点,直到其所需的外部资源(例如可连接设备或 FPGA)确认已完全准备就绪,从而提高某些设备类别的调度可靠性。这可以防止过早分配 Pod 导致故障,并通过在 Pod 提交到节点之前明确建模资源就绪情况,确保更稳健、更可预测的调度。
- 资源健康状态 (Resource health status):通过 Pod 状态公开分配给 Pod 的设备的健康状况,从而提高了可观察性。无论设备是通过 DRA 还是设备插件分配的,此功能均有效。这使得更容易了解设备不健康的原因并做出适当的响应。
拓展阅读
Kubernetes v1.34: Pods Report DRA Resource Health
Pods 报告 DRA 资源健康(Pods Report DRA Resource Health),旨在解决 AI/ML 等高性能工作负载中专用硬件(如 GPU、TPU、FPGA)故障难以诊断的问题,从而减少停机时间。
对于有状态应用程序或长期运行的作业,设备故障可能会造成中断并造成高昂的成本。通过在 Pod 的 .status 字段中公开设备运行状况,Kubernetes 为用户和自动化工具提供了一种标准化的方法来快速诊断问题。如果 Pod 发生故障,现在可以检查其状态,以确定不健康的设备是否是根本原因,从而节省宝贵的时间,否则这些时间可能会花在调试应用程序代码上。
Kubernetes v1.34: DRA Consumable Capacity
资源驱动程序现在可以支持跨多个 ResourceClaims 或跨多个 DeviceRequests 共享同一设备(甚至是设备的一部分)。这意味着,如果特定 DRA 驱动程序允许和支持,来自不同命名空间的 Pod 可以同时共享同一设备。
浅浅聊聊 K8s 1.34 GA 的 DRA | 关于动态资源分配,你可能关心的 7 个问题
可以说 DRA 是借用了 PV/PVC 的动态资源供应的思路,通过结构化标准化的抽象,来支持更加个性化、更加灵活的资源调度与分配。如果说人话一点,就是之前基于 DevicePlugin 框架,上报的信息量太不够了,通过别的方式上报,调度器又不知道。本质上就是信息量不够的问题,而 DRA 解决问题的思路和 HAMi 基于 Node & Pod Annotations 的信息传递机制的思路本质上也是一样的:丰富信息,并且感知这些信息。
e. 为 Uncore Cache 对齐引入 CPU Manager 静态策略选项
Kubernetes v1.34: Introducing CPU Manager Static Policy Option for Uncore Cache Alignment
在不久之前,几乎所有主流计算机处理器都拥有一个单一的末级缓存(last-level-cache),这个缓存在多 CPU 封装中的所有核心之间共享。这个单一的缓存也被称为uncore 缓存(因为它不与特定核心相关联)或三级缓存(Level 3 cache)。除了三级缓存之外,还有其他缓存,通常称为一级缓存(Level 1 cache)和二级缓存(Level 2 cache),它们是与特定的 CPU 核心相关联的。
为了减少 CPU 核心与其缓存之间的访问延迟,最近基于 AMD64 和 ARM 架构的处理器引入了分体式 uncore 缓存架构。在这种架构中,末级缓存被划分为多个物理缓存,这些缓存与物理封装内的特定 CPU 核心分组对齐。CPU 封装内更短的距离有助于减少延迟。
启用 prefer-align-cpus-by-uncorecache 后, 静态 CPU 管理器会尝试为容器分配 CPU 资源,以便分配给容器的所有 CPU 共享同一个非核心缓存。此策略会尽力而为,旨在根据容器的需求并考虑节点上可分配的资源,最大限度地减少容器 CPU 资源在非核心缓存之间的分配。
f. 用于镜像拉取的服务账户令牌升级至 Beta
Kubernetes v1.34: Service Account Token Integration for Image Pulls Graduates to Beta
此增强功能允许凭证提供者使用特定于工作负载的服务帐户令牌来获取注册表凭证,从而为传统的图像拉取机密提供安全、短暂的替代方案。
在使用服务账户令牌时,credential provider 配置中的 cacheType 字段是必需的。此字段是 Beta 版中新增的,必须指定以确保正确的缓存行为:
- Token:按服务帐户令牌缓存凭证(当凭证生命周期与令牌绑定时使用)。当凭证提供程序将服务帐户令牌转换为与令牌生命周期相同的注册表凭证,或者注册表直接支持 Kubernetes 服务帐户令牌时,此功能非常有用。注意:kubelet 无法将服务帐户令牌直接发送给注册表;需要使用凭证提供程序插件将令牌转换为注册表所需的用户名/密码格式。
- ServiceAccount:每个服务帐户身份缓存凭据(当凭据对使用相同服务帐户的所有 Pod 都有效时使用)。
g. Job 的 Pod 替换策略正式发布(GA)
Kubernetes v1.34: Pod Replacement Policy for Jobs Goes GA
背景
默认情况下,Job 控制器会在 Pod 失败或开始终止时(具有删除时间戳时)立即重新创建 Pod。因此,当某些 Pod 终止时,某个 Job 正在运行的 Pod 总数可能会暂时超过指定的并行度。对于索引 Job,这甚至可能意味着多个 Pod 同时针对同一索引运行。
这种行为对于许多工作负载来说效果很好,但在某些情况下可能会导致问题。例如,流行的机器学习框架,如 TensorFlow 和 JAX 期望每个工作线程索引只有一个 Pod。如果两个 Pod 同时运行,可能会遇到错误。
此外,在旧 Pod 完全终止之前启动替换 Pod 可能会导致:
- 由于节点仍然被占用,kube-scheduler 的调度出现延迟。
- 不必要的集群扩展以容纳替换的 Pod。
- 暂时绕过 Kueue 等工作负载协调器的配额检查。
Pod 替换策略如何工作
Kubernetes 中的 Job 有一个可选字段 .spec.podReplacementPolicy。可以选择以下两种策略之一:
- TerminatingOrFailed(默认):一旦 Pod 开始终止,就替换它们。
- Failed:仅在 Pod 完全终止并过渡到 Failed 阶段后才替换 Pod。
将策略设置为 Failed 可确保仅在前一个 Pod 完全终止后才创建新的 Pod。对于具有 Pod 故障策略的 Job,默认的 podReplacementPolicy 为 Failed ,不允许使用其他值。
h. 用于卷修改的 VolumeAttributesClass 正式发布(GA)
Kubernetes v1.34: VolumeAttributesClass for Volume Modification GA
VolumeAttributesClass 是一种集群范围的资源,它定义了卷的一组可变参数。可以将其视为存储的“配置文件”,允许集群管理员公开不同的服务质量 (QoS) 级别或性能层。然后,用户可以在其持久卷声明 (PVC) 中指定 volumeAttributesClassName ,以指示所需的属性类别。神奇的是,它通过容器存储接口 (CSI) 实现:当引用 VolumeAttributesClass 的 PVC 更新时,关联的 CSI 驱动程序会与底层存储系统交互,将指定的更改应用于卷。
这意味着:
- 动态扩展性能:增加繁忙数据库的 IOPS 或吞吐量,或减少不太重要的应用程序的 IOPS 或吞吐量。
- 优化成本:随时调整属性以满足当前的需求,避免过度配置。
- 简化操作:直接在 Kubernetes API 内管理卷修改,而不是依赖外部工具或手动流程。
i. 可快照 API 服务器缓存
Kubernetes v1.34: Snapshottable API server cache
几项历史改进:
- 从缓存中一致读取(v1.31 中的 Beta 版)
- 使用流式传输处理大量响应(v1.33 中的 Beta 版)
1.34 版本可快照 API 服务器缓存工作原理:每次更新时,缓存都会创建一个轻量级快照。这些快照是“惰性复制”,这意味着它们不会复制对象,而只是存储指针,这使得它们非常节省内存。
当历史 resourceVersion 的列表请求到达时,API 服务器现在会找到相应的快照并直接从其内存中提供响应。这弥补了最后一个主要缺口,允许分页请求完全从缓存中提供。
可以实现以下效果:
- 从缓存中获取数据:一致性读取和快照缓存协同工作,确保几乎所有读取请求(无论是最新数据还是历史快照)都由 API 服务器的内存提供。
- 通过流发送数据:流式列表响应确保将此数据发送到客户端具有最小且恒定的内存占用。
j. 使用 Init 容器定义应用环境变量
Kubernetes v1.34: Use An Init Container To Define App Environment Variables
背景
Kubernetes 通常使用 ConfigMap 和 Secret 来设置环境变量,这会引入额外的 API 调用和复杂性。例如,需要分别管理工作负载的 Pod 和它们的配置,同时还要确保配置和工作负载 Pod 的有序更新。
还可能在使用一个供应商提供的、需要环境变量(例如许可证密钥或一次性令牌)的容器,但又不想对这些变量进行硬编码,或者仅仅为了完成工作而挂载卷。
简介
这个特性允许将容器指向一个文件,该文件由 initContainer 生成,然后让 Kubernetes 解析该文件以设置你的环境变量。此文件位于一个 emptyDir 卷中(这是一种临时存储空间,只要 Pod 存在就会保留),主容器不需要挂载此卷。kubelet 会在容器启动时读取文件并注入这些变量。
即允许 Kubelet 直接从 Pod 内部的 emptyDir 卷中的文件加载环境变量,而无需将该文件实际挂载到主容器中。通常,一个 initContainer 会负责将环境变量(以 KEY=VALUE 的标准 .env 格式)写入到这个 emptyDir 卷中的指定文件。主容器则通过其 Pod 规约中的 env.valueFrom.fileKeyRef 字段引用该文件和具体键来获取变量。
k. 可变 CSI 节点可分配资源(Mutable CSI Node Allocatable)升级至 Beta
Kubernetes v1.34: Mutable CSI Node Allocatable Graduates to Beta
背景
传统上,Kubernetes CSI 驱动程序在初始化时会报告静态的最大卷附件限制。但是,实际附件容量可能会在节点的生命周期内因各种原因而发生变化,例如:
- 手动或外部操作在 Kubernetes 控制之外附加/分离卷。
- 动态连接的网络接口或专用硬件(GPU、NIC 等)消耗可用插槽。
- 多驱动程序场景,其中一个 CSI 驱动程序的操作会影响另一个驱动程序报告的可用容量。
静态报告可能导致 Kubernetes 将 pod 调度到看似有容量但实际上没有容量的节点上,从而导致 pod 卡在 ContainerCreating 状态。
动态调整 CSI 容量限制
借助这项新功能,Kubernetes 使 CSI 驱动程序能够在运行时动态调整和报告节点连接容量。这确保了调度程序以及依赖此信息的其他组件能够获得最准确、最新的节点容量视图。
Kubernetes 支持两种更新报告的节点卷限制的机制:
- 定期更新:CSI 驱动程序指定一个间隔来定期刷新节点的可分配容量。
- 响应式更新:当卷挂载因资源耗尽(ResourceExhausted 错误)而失败时,立即触发的更新。
l. Node Cgroup 驱动程序的自动配置已 GA
Kubernetes v1.34: Autoconfiguration for Node Cgroup Driver Goes GA
历史上,配置正确的 cgroup 驱动一直是用户运行新的 Kubernetes 集群时的痛点。在 Linux 系统中,存在两种不同的 cgroup 驱动:cgroupfs 和 systemd。过去,kubelet 和 CRI 实现(例如 CRI-O 或 containerd)都需要配置成使用相同的 cgroup 驱动,否则 kubelet 就会出现异常行为,且没有任何明确的错误消息。这对许多集群管理员来说都是一个令人头疼的问题。
KubeletCgroupDriverFromCRI 功能门已在 v1.34.0 中达到 GA 状态。它允许 kubelet 询问 CRI 实现以确定正确的 cgroup 驱动,从而实现自动配置。
要启用此功能,需要确保 CRI 实现版本足够新:
- containerd:v2.0.0 或更高版本。
- CRI-O:v1.28.0 或更高版本。
m. 解耦污点管理器现已稳定
Kubernetes v1.34: Decoupled Taint Manager Is Now Stable
此项增强将管理节点生命周期和 Pod 驱逐的职责分离为两个不同的组件。之前,节点生命周期控制器既负责使用 NoExecute 污点将节点标记为不健康,也负责从中驱逐 Pod。现在,专用的污点驱逐控制器负责管理驱逐过程,而节点生命周期控制器则专注于应用污点。这种分离不仅改进了代码组织,也使改进污点驱逐控制器或构建基于污点的驱逐的自定义实现变得更加容易。
n. 从卷扩展失败中恢复已 GA
Kubernetes v1.34: Recovery From Volume Expansion Failure (GA)
该功能主要解决了用户在扩容 PersistentVolumeClaim (PVC) 时因拼写错误(例如,将 10TB 误写为 1000TB)导致扩容失败,且之前手动恢复过程复杂、通常需要集群管理员权限的问题。
核心改进点:
- 自动化错误纠正:在 v1.34 中,如果扩容尚未完成,用户现在可以直接修改 PVC 的请求大小来纠正错误,将其请求大小调小到正确的值。只要新请求的大小仍大于 PVC 的原始容量,Kubernetes 就会自动处理。
- 配额自动返还:之前因错误扩容而占用的多余 Kubernetes 配额将自动返还给用户,且无需管理员介入。
- 限制:新的请求大小必须大于 PVC 的原始容量 (.status.capacity),因为 Kubernetes 不支持缩小已分配的卷。
o. Pod 级资源升级至 Beta
Kubernetes v1.34: Pod Level Resources Graduated to Beta
此功能通过在 Pod 和容器级别提供灵活的资源管理来增强 Kubernetes 中的资源管理。
- 它提供了一种统一的资源声明方法,减少了对每个容器进行细致管理的需要,特别是对于具有多个容器的 Pod。
- Pod 级资源使 Pod 内的容器能够共享未使用的资源,从而提高 Pod 内的资源利用效率。例如,它可以防止 Sidecar 容器成为性能瓶颈。以前,即使主应用容器拥有充足的空闲 CPU,Sidecar(例如日志代理或服务网格代理)达到其各自的 CPU 限制时也可能会受到限制,并降低整个 Pod 的速度。有了 Pod 级资源,Sidecar 和主容器可以共享 Pod 的资源预算,确保在流量高峰期间平稳运行——要么整个 Pod 受到限制,要么所有容器都能正常工作。
- 当同时指定 Pod 级别和容器级别资源时,Pod 级别的请求和限制优先。这为提供了一种强大的方法来强制执行 Pod 的整体资源边界。
- Pod 级资源在影响 Pod 的服务质量 (QoS) 类方面具有优先权。
- 对于在 Linux 节点上运行的 Pod,内存不足 (OOM) 分数调整计算会同时考虑 Pod 级别和容器级别的资源请求。
- Pod 级资源旨在与现有的 Kubernetes 功能兼容 ,确保顺利集成到您的工作流程中。
p. 卷组快照移至 v1beta2
Kubernetes v1.34: Moving Volume Group Snapshots to v1beta2
该功能的核心目标是为一组卷提供“崩溃一致性”快照,使用户能够将这些快照恢复到新卷,从而基于一个崩溃一致的恢复点来恢复其工作负载。它依赖于 CSI(容器存储接口)卷驱动,并通过标签选择器来分组多个持久卷声明(PersistentVolumeClaims)以进行快照操作。
q. 支持块变更跟踪 API(alpha)
Announcing Changed Block Tracking API support (alpha)
块变更跟踪使存储系统能够识别和跟踪快照之间块级别的修改,从而无需在备份操作期间扫描整个卷。这项改进是对容器存储接口 (CSI) 以及 Kubernetes 本身存储支持的改进。启用功能后,集群可以:
- 识别 CSI 卷快照中已分配的块
- 确定同一卷的两个快照之间的更改块
- 通过仅关注更改的数据块来简化备份操作
🎤 相信后续还会有新文章发出,那就继续学习 + 重复加深理解吧。
📄 专题四 报告查看与分析
1. [The New Stack] Kubernetes at the Edge: Container Orchestration at Scale(由 Sidero 赞助)
Kubernetes at the Edge: Container Orchestration at Scale
Sidero 是谁
Sidero Labs 是一家致力于简化和保护跨裸机、数据中心、边缘和云环境的 Kubernetes 的公司,成立于 2019 年。其产品有 Omni、Talos Linux。
什么是边缘
“边缘”指的是一个位于核心 IT 基础设施之外的位置 —— 可以是物理的、逻辑的,或两者兼有。
传统上,核心基础设施指的是一个组织的 IT 基础,包括对其业务运营至关重要的元素,它承载了公司的计算机服务器和数据存储。随着时间的推移,这个定义已经扩展到托管设施以及由超大规模厂商(如 AWS、GCP 和 Azure)运营的云数据中心。
在企业环境中,“边缘”可能指那些不在公司内部、通过虚拟专用网络(VPN)或互联网连接访问核心数据中心的用户。在这种语境下,“边缘”指的是网络拓扑上的一个位置。然而,“边缘”也指计算和存储所在的位置。简而言之,“边缘”是一个地点,而不仅仅是拓扑上的一个参考点。这个地点定义又进一步细分为三个不同的层级:近边缘(Near Edge)、远边缘(Far Edge)和设备边缘(Device Edge)。
边缘计算跨越了多个层级 —— 从小型数据中心和区域设施(近边缘),到零售商店和餐馆(远边缘),再到单个设备(设备边缘)—— 每个层级都需要根据连接性、资源和工作负载的关键性,采用不同的处理方法。
近边缘(Near Edge)
近边缘(Near Edge)通常指的是边缘数据中心,即位于靠近终端用户和设备的、小型且分散的计算设施,旨在本地处理数据,以减少延迟并提升实时应用的性能。
例如,对于企业用户:
- 位于外部的用户通过互联网或 VPN 连接到边缘数据中心。
- 然后,边缘数据中心再通过广域网(WAN),通常是软件定义广域网(SD-WAN),与核心数据中心相连。
近边缘位置可以拥有自己的内容分发网络(CDN)缓存、安全框架和性能增强机制。
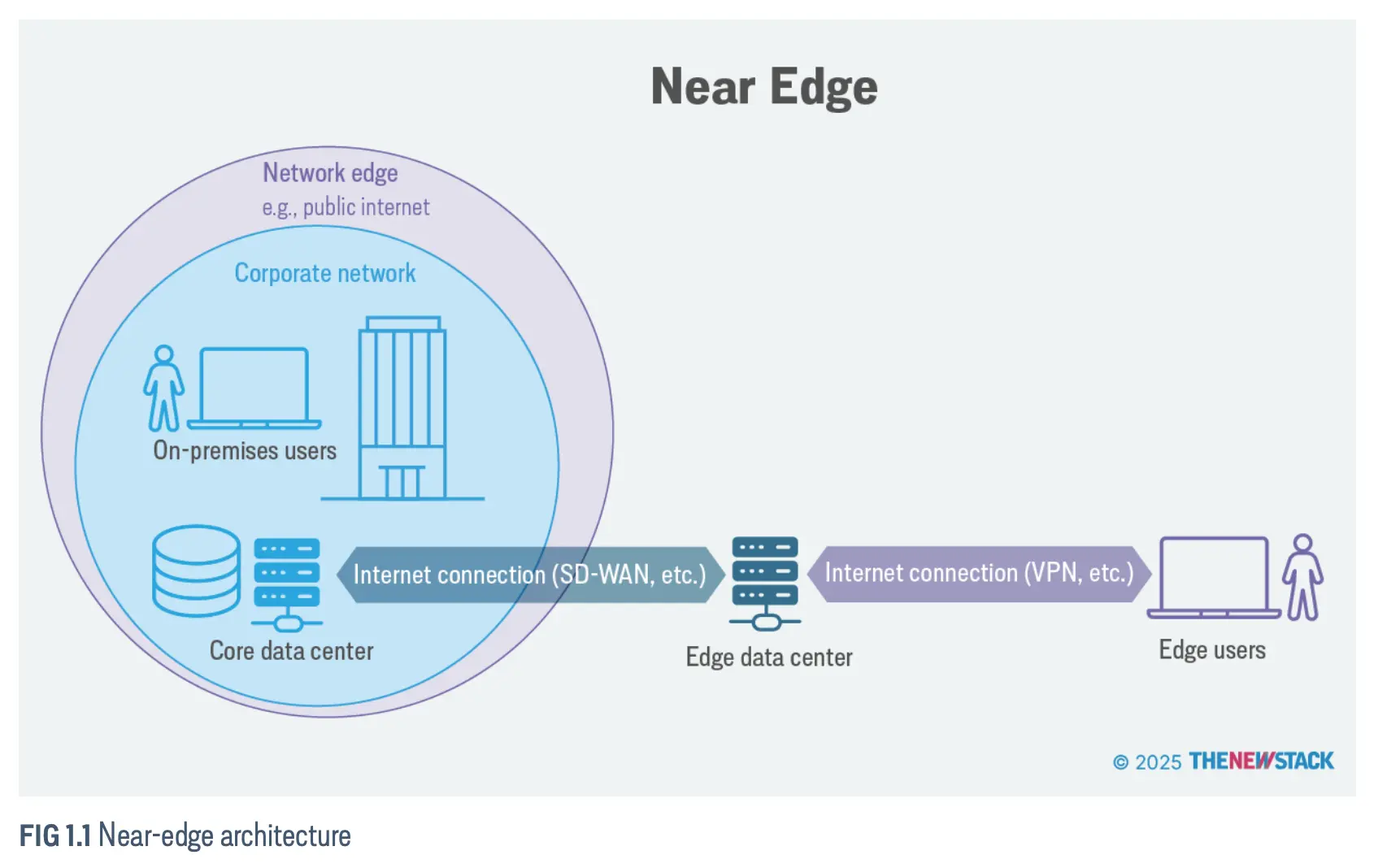
远边缘(Far Edge)
远边缘(Far Edge)代表了最分散的部署位置,其基础设施被放置在与终端设备和用户非常近的地方,例如蜂窝塔的塔基,或零售店和餐馆中的销售点系统。
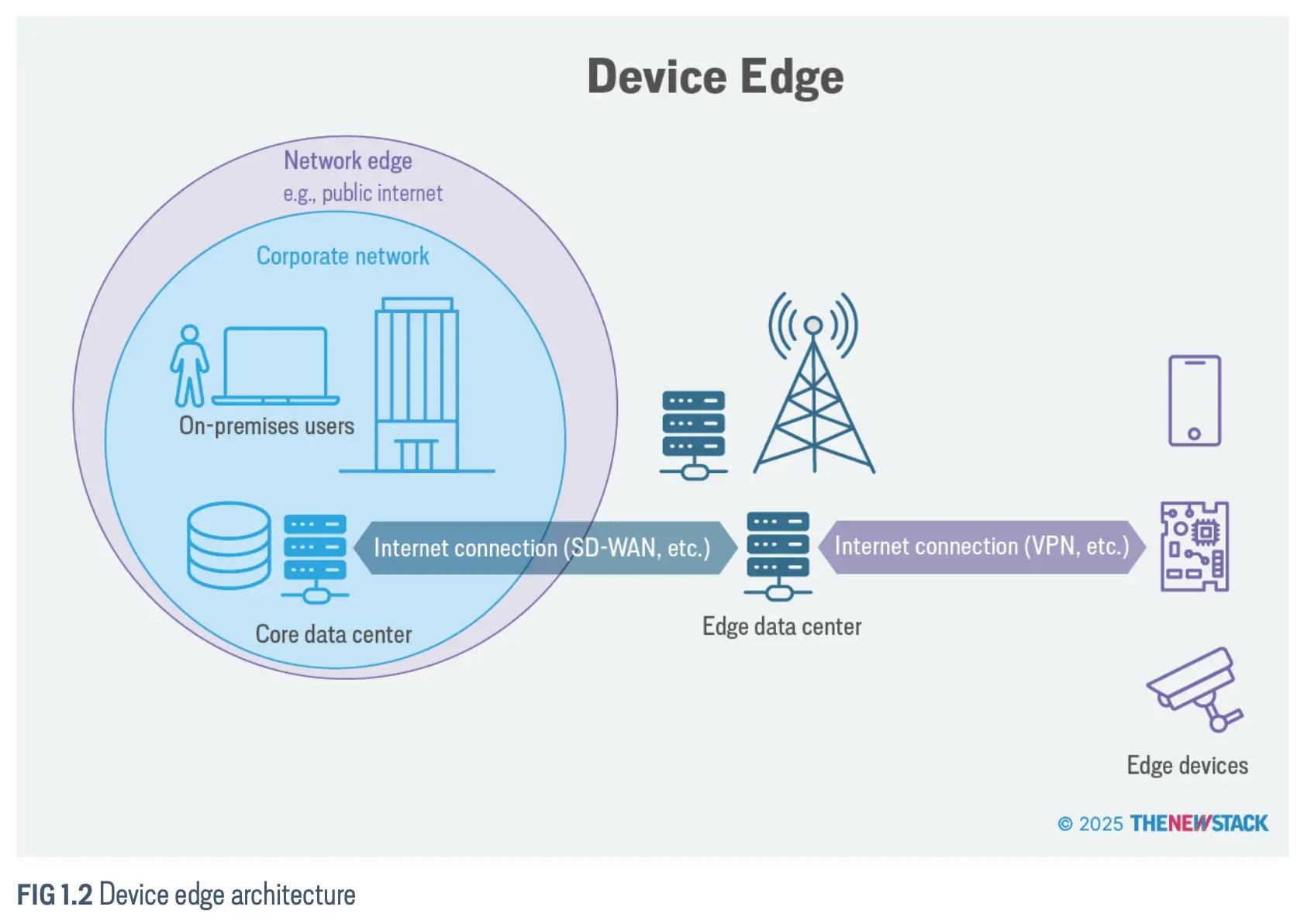
设备边缘(Device Edge)
设备边缘(Device Edge)指的是具有特定功能的端点(如传感器和控制器)所在的位置;它包含了实际的设备,即边缘设备,及其紧邻的区域。这些设备通过蜂窝塔或边缘服务器连接到公司数据中心或云端。这些联网的边缘设备,可能包括智能摄像头、工业传感器、可穿戴健康监测器和医学影像扫描仪,其应用范围横跨零售、交通、医疗和制造业等多个行业。
边缘设备通常专用于一个特定目的,例如对某个区域进行视频监控,或者控制某种机器,如装配线上的自动化工作站。一个典型的边缘设备将只具备足以支持其专用活动的计算能力。当我们谈论物联网(IoT)时,无论是消费级还是工业级物联网,我们所指的也正是这些边缘设备。
边缘的优势
近边缘和远边缘都具有以下优势:
- 通过在更靠近数据源的位置进行处理,可降低延迟并加快响应时间。
- 通过减少向云端发送大量数据的需求,可提高网络带宽效率。
- 通过最大限度地减少网络流量,可降低碳足迹。
- 通过在本地处理敏感信息,可增强数据安全性和隐私性。
- 分散式架构可提高可靠性和弹性。
- 更好地支持实时应用程序以及 AI 和机器学习模型。
边缘的缺点
- 有限的计算资源
- 不稳定的网络链接
从 Docker 到边缘编排
容器相较于虚拟机更轻量,所以更适合边缘的场景。并且通过标准化的打包模式(OCI),提供了附加价值 —— 不可变基础设施。
当规模变大,自动化部署与管理就变成一个关键的问题,于是就有了 Kubernetes。Kubernetes 长期以来被认为是大规模编排容器最广泛采用的方法,但在边缘采用它却相对较新。
不同的边缘层需要量身定制的解决方案,完整的 Kubernetes 适用于近边缘和远边缘部署,轻量级 Kubernetes 发行版针对资源受限的远边缘环境进行了优化,而 Podman 等容器化工具更常用于设备边缘端点。
边缘计算在不同行业
农业
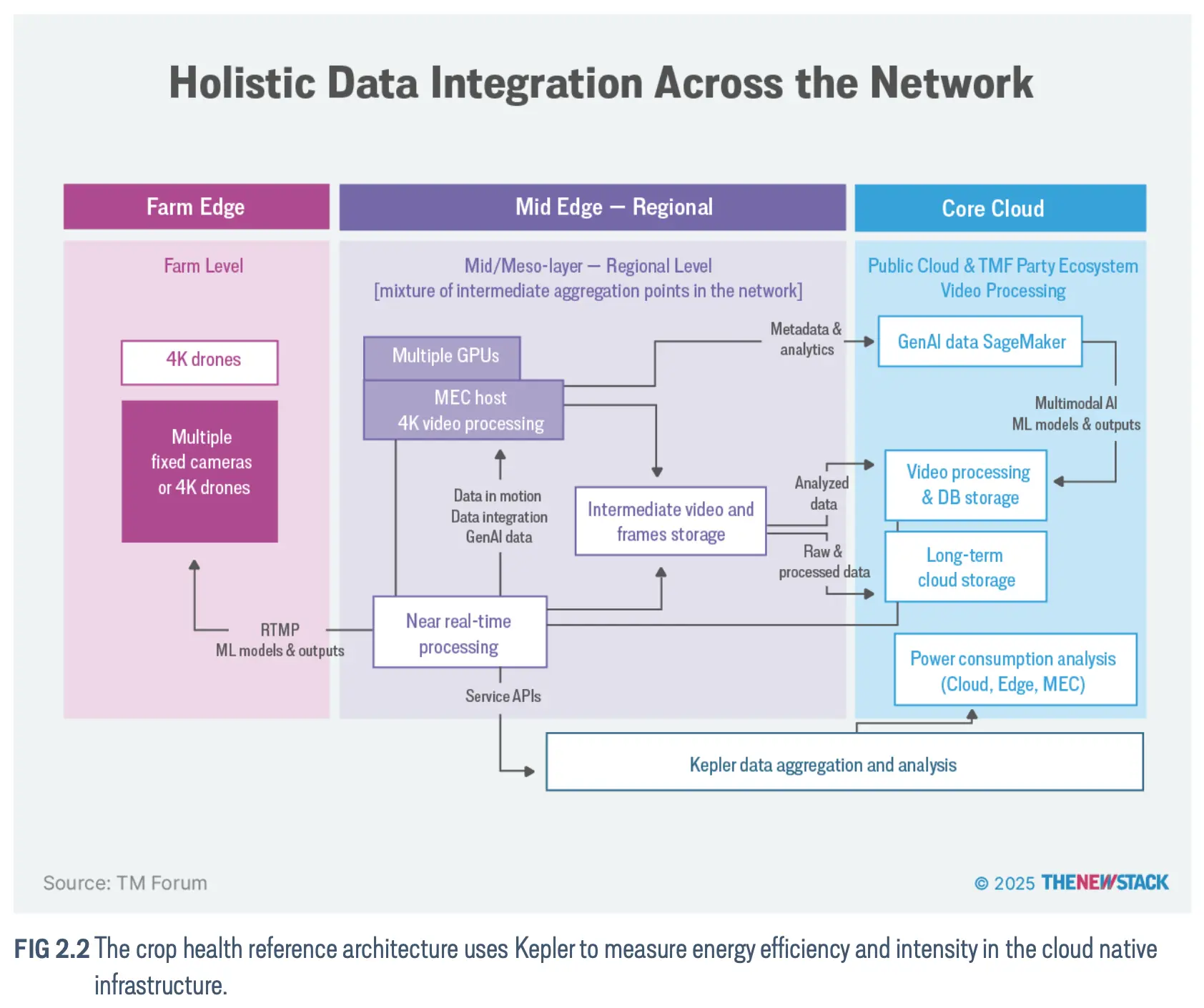
能源和可再生能源

健康
知名的 Kubernetes 边缘供应商
- AWS EKS Anywhere 与 Outposts
- Canonical MicroK8s
- Mirantis k0s 与 k0smotron
- Rafay
- Wind River Studio Cloud Platform
- Rakuten Cloud Native Platform
- Red Hat Device Edge
- Scale Computing HyperCore
- Sidero Talos Linux 和 Omni
- Spectro Cloud Palette
- SUSE Edge Suite
💁♀️ 专题五 产品/方案介绍
1. CubeFS:新一代开源存储系统
简介
CubeFS(中文名为“储宝”)是新一代云原生开源存储系统,支持 S3、HDFS 和 POSIX 等访问协议。它广泛应用于大数据、人工智能/LLM、容器平台、数据库和中间件的存储与计算分离、数据共享和保护等各种场景。
使用场景
- 作为开源分布式存储,CubeFS 可以作为您的数据中心文件系统、数据湖存储基础设施以及私有或混合云存储。
- 而且它可以在公有云服务中运行,在 S3 等公有云存储之上提供缓存加速和文件系统语义。
- 具体来说,CubeFS 支持数据库、搜索系统和 AI/ML 应用程序的存储/计算架构分离。
主要功能
- 多种访问协议,如 POSIX、HDFS、S3 及其自己的 REST API
- 高度可扩展、强一致性的元数据服务
- 大/小文件、顺序/随机写入的性能优化
- 多租户支持,具有更好的资源利用率和租户隔离
- 通过多级缓存实现混合云 I/O 加速
- 灵活的存储策略、高性能复制或低成本擦除编码
拓展阅读
2. kftray:管理 Kubernetes 端口转发的应用
简介
kftray 和 kftui 是 Kubernetes 端口转发工具,它们确实能按照你预期的方式工作。虽然 kubectl port-forward 可以很好地完成一些快速任务,但当 Pod 重启或连接断开时,它就会失效,你只能手动重新连接。
kftray(集成托盘的桌面应用)和 kftui(终端 UI)共享相同的 Rust 后端和配置文件。它们使用 Kubernetes watch API 来检测 Pod 的启动和退出,并自动重新连接转发,无需亲自照看。它们通过集群中的代理中继处理 TCP 和 UDP,支持同时进行多个转发,甚至可以记录 HTTP 流量以供调试。
价值
Kubernetes 工具有很多,但端口转发却一直被人们忽略。kubectl kubectl port-forward 的主要问题如下:
- 当 Pod 重启或重新安排时, 连接会中断
- 没有自动重新连接 ——你必须手动重启一切
- 多次转发意味着多个终端窗口
- 不支持 UDP
- 无法调试通过隧道的 HTTP 流量
功能
- 自动重新连接 – Pod 重启时重新连接
- 多个转发 – 一次启动/停止多个转发
- 无需 kubectl – 直接集成 K8s API
- TCP/UDP 支持 – 通过集群代理中继
- HTTP 流量日志 – 检查请求/响应
- Pod 健康跟踪 – 显示连接到哪个 Pod
- 网络恢复 — 睡眠/断开连接后自动重新连接
- GitHub 同步 – 与团队共享配置
- 自动导入 — 通过 K8s 注释发现服务
- 自定义 kubeconfig – 使用任何 kubeconfig 路径
- 端口转发超时 – 时间限制后自动关闭
- 主机文件管理 – 自动更新 /etc/hosts 条目
- 自动 SSL – 自动生成用于端口转发的 SSL 证书
- 系统托盘集成 – 从托盘快速访问
- 请求重放 — 重放 HTTP 请求以进行调试
3. Gonzo:基于 Go 的日志分析 TUI
简介
受 K9s 启发的强大实时日志分析终端 UI。使用精美的图表、AI 洞察和高级筛选功能分析日志流 - 一切尽在终端。
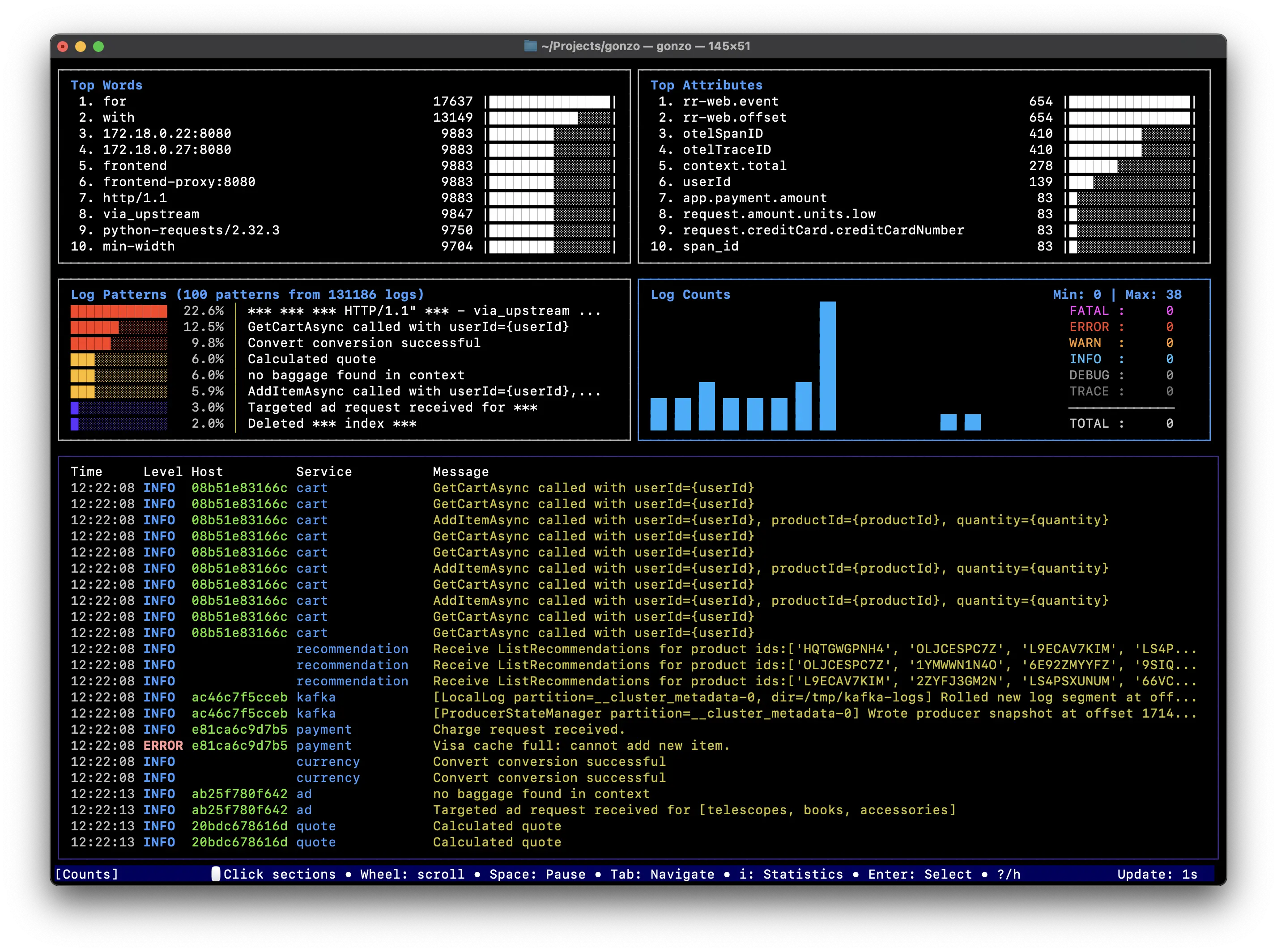
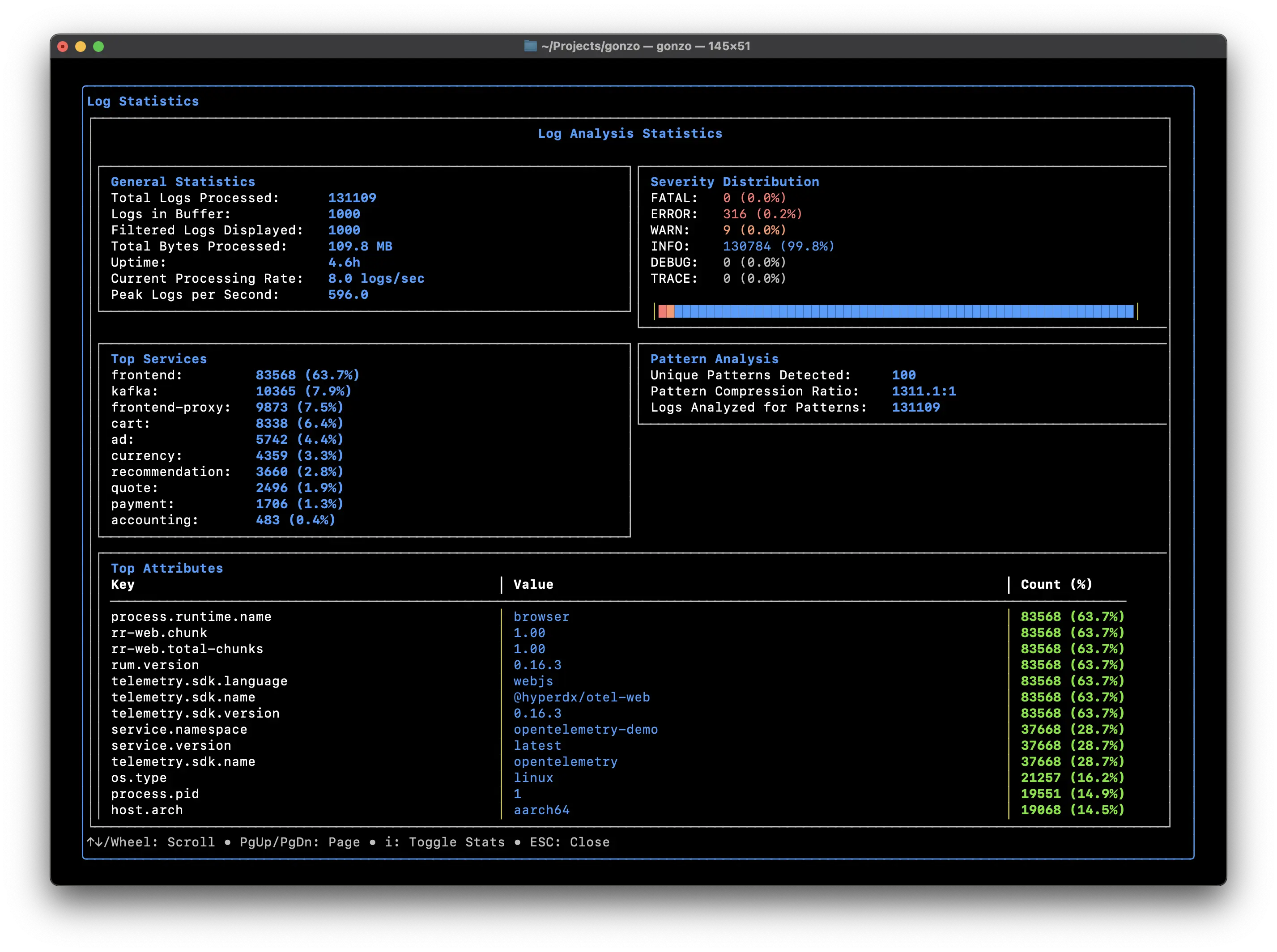

主要功能
- 实时分析
- 实时流 - 处理来自标准输入、文件或网络的日志
- OTLP 原生 - 对 OpenTelemetry 日志格式的一流支持
- OTLP 接收器 - 内置 gRPC 服务器,通过 OpenTelemetry 协议接收日志
- 格式检测 — 自动检测 JSON、logfmt 和纯文本
- 自定义格式 - 使用 YAML 配置定义您自己的日志格式
- 严重程度跟踪 — 使用分布图对严重程度进行颜色编码
- 交互式仪表板
- 受 k9s 启发的布局 - 熟悉的 2x2 网格界面
- 实时图表 — 词频、属性、严重性分布、时间序列
- 键盘 + 鼠标导航 - Vim 风格的快捷键以及点击导航和滚轮支持
- 智能日志查看器 - 自动滚动,具有智能暂停/恢复行为
- 全屏日志查看器 - 按 f 打开专用的全屏模式,用于浏览包含所有导航功能的日志
- 全局暂停控制 - 空格键在缓冲日志时暂停整个仪表板
- 模态详细信息 - 通过可扩展视图深入了解单个日志条目
- 日志计数分析 - 具有热图可视化、按严重程度进行模式分析和服务分布的详细模型
- 人工智能分析 — 通过可配置模型获得有关日志模式和异常的智能洞察
- 高级过滤
- 正则表达式支持 - 使用正则表达式过滤日志
- 属性搜索 - 通过特定属性值查找日志
- 严重性过滤 - 交互式模式选择特定日志级别(Ctrl+f)
- 多级选择 - 一次启用/禁用多个严重性级别
- 交互式选择 - 单击或键盘导航以浏览日志
- 可定制的主题
- 内置皮肤 - 11+ 个精美主题,包括 Dracula、Nord、Monokai、GitHub Light 等
- 明暗模式 - 针对不同光照条件优化的主题
- 自定义皮肤 - 使用 YAML 配置创建您自己的配色方案
- 语义颜色 — 不同 UI 组件的直观颜色映射
- 专业主题 - 包含 ControlTheory 原创主题
- 人工智能洞察
- 模式检测 — 自动识别重复出现的问题
- 异常分析 — 发现日志中的异常模式
- 根本原因建议 - 获取 AI 驱动的调试帮助
- 可配置模型 — 从 GPT-4、GPT-3.5 或任何自定义模型中选择
- 多个提供商 - 可与 OpenAI、LM Studio、Ollama 或任何与 OpenAI 兼容的 API 配合使用
- 本地 AI 支持 - 使用本地模型完全离线运行
4. OpenCost:Kubernetes 和云支出成本的开源监控工具
简介
OpenCost 是一个供应商中立的开源项目,用于实时衡量和分配云基础设施和容器成本。OpenCost 由 Kubernetes 专家构建并得到 Kubernetes 从业者的支持,揭示了 Kubernetes 支出的黑匣子。
OpenCost 最初由 Kubecost 开发并开源,是一个 CNCF 孵化项目。
主要功能
- 按 Kubernetes 集群、节点、命名空间、控制器类型、控制器、服务或 pod 实时分配成本
- 针对 AWS、Azure、GCP 上的所有云服务的多云成本监控
- 通过与 AWS、Azure 和 GCP 计费 API 集成实现动态按需 k8s 资产定价
- 支持本地 k8s 集群,并自定义 CSV 定价
- 集群内 K8s 资源的分配,例如 CPU、GPU、内存和持久卷
- 使用 /metrics 端点轻松将定价数据导出到 Prometheus
- 云资源的碳成本
- 通过 OpenCost 插件支持 Datadog 等外部成本
- 免费开源分发(Apache2 许可证)
5. Shipwright:用于在 Kubernetes 上构建容器镜像的可扩展框架
简介
Shipwright 是一个用于在 Kubernetes 上构建容器镜像的可扩展框架。可以定义构建策略,使用 Kaniko、Cloud Native Buildpacks、Buildah 等热门工具构建容器镜像。
特点
- 灵活性和可扩展性
Shipwright.io 支持多种构建工具,包括 Kaniko。这种灵活性使您可以选择最符合项目需求的工具,从而确保您能够充分利用不同构建策略的优势。 - 简化配置
BuildStrategy 使开发人员能够使用最少的 YAML 配置来定义构建流程。这种方法为开发人员抽象了容器工具的知识,即使是容器技术新手也能轻松上手。 - 与 Kubernetes 集成
通过与 Kubernetes 无缝集成,BuildStrategy 可确保您的构建流程可扩展且可靠 。这种集成使您能够充分利用 Kubernetes 的编排功能,确保高效且稳健的容器镜像构建。
使用流程
- 描述策略
创建一个 BuildStrategy ,指定要使用的构建工具和参数。此文件定义了容器镜像的构建方式。 - 配置 build
创建一个链接您的 BuildStrategy Build ,并声明特定于集群或构建本身的附加参数。 - 发布/交付
运行构建,将你的容器镜像发布到你的镜像仓库。
🤔 专题六 有意思的事与 Meme
1. 免费提供 Kubernetes/DevOps 帮助
Offering Kubernetes/DevOps help free of charge
灵感来自 u/LongjumpingRole7831 和他的两篇帖子:
- https://www.reddit.com/r/sre/comments/1kk6er7/im_done_applying_ill_fix_your_cloudsre_problem_in/
- https://www.reddit.com/r/devops/comments/1kuhnxm/quick_update_that_ill_fix_your_infra_in_48_hours/
“我会免费提供我的服务、专业知识和经验。我这样做是为了帮助社区以及 DevOps/SRE/Kubernetes 工程师和团队。根据您需要的帮助,我会告知您我是否可以提供帮助,如果可以,我们将确定(或完善)服务范围,并商定软期限和硬期限。”
“如果您希望我联系您,请随时评论“帮助”(或其他任何内容),在 Reddit 上直接给我留言,或发送电子邮件至 [email protected] 。我会尽快回复。:)”
“这篇文章的主要读者是开发人员、DevOps 工程师或团队(或工程主管/经理),但我也会尽力帮助所有 Kubernetes 爱好者设置家庭实验室!”
2. 对小规模业务非常有用的 Docker 容器产品推荐
Docker Containers That Could Be Essential for Your Small Business
Nextcloud
一款自托管云服务。可以帮助用户摆脱对 Google Workspace、Microsoft 365 和 Apple iCloud 等产品的依赖。Nextcloud 包含大量内置功能,例如存储、日历、文档、聊天、电子邮件、看板等等。如果发现 Nextcloud 不包含所需要的功能,还可以筛选并安装大量应用程序。
Invoice Ninja
一款自托管发票管理工具。Invoice Ninja 的功能包括可自定义的发票创建、定期账单、自动付款提醒以及支持多种货币和语言。
Bitwarden
一款密码管理器。
Homebox
一款物品管理、追踪产品。Homebox 支持资产 ID 标签生成器、物料清单功能、导入/导出和库存操作。
Outline
一款知识库工具。Outline 是一款功能强大的协作笔记应用,支持 Markdown、斜线命令、交互式嵌入等众多功能。
3. 多位音乐人从 Spotify 下架音乐,抗议 CEO Daniel Ek 对 AI 军事的投资
背景
Spotify CEO Daniel Ek 领投了对国防初创公司 Helsing 的 6.94 亿美元投资。
Helsing 成立于 2021 年,销售利用人工智能技术分析战场上大量传感器和武器系统数据的软件,用于实时指导军事决策。去年,这家初创公司还开始生产自己的军用无人机系列,名为 HX-2。
在英国、德国和法国开展业务的 Helsing 公司表示,将利用这笔新资金投资欧洲的“技术主权”,即尝试将人工智能等关键技术的开发和生产转移到本土。
Daniel Ek(1983 年 2 月 21 日出生)是瑞典商人和技术专家,是 Spotify 的联合创始人兼首席执行官。他在一份声明中表示:“随着欧洲为应对不断变化的地缘政治挑战而迅速加强其国防能力,迫切需要对先进技术进行投资,以确保其战略自主和安全准备。”
相关音乐人
Godspeed You! Black Emperor
Godspeed You! Black Emperor Remove Music From Streaming Services
毋庸置疑,GYBE 是一支不吝于放置政治元素的后摇乐队。无论是《Yanqui U.X.O》专辑封面炸弹落下的照片,还是所附的一张旨在表示四大唱片公司(华纳、BMG、索尼、环球)与各大军火制造商之间的联系。还是《The Dead Flag Blues》中的人声采样:
The car′s on fire and there's no driver at the wheel
And the sewers are all muddied with a thousand lonely suicides
And a dark wind blows
The government is corrupt
And we′re on so many drugs
With the radio on and the curtains drawn
We're trapped in the belly of this horrible machine
And the machine is bleeding to death
在下架方面,他们也更决绝,已经将其唱片从 Spotify、Tidal 和 Amazon Music 下架。Apple Music 目前还残存《F# A# ∞》和《Lift Your Skinny Fists like Antennas to Heaven》,但也即将被下架。Kranky(这两张唱片所属厂牌)一直允许艺术家控制其音乐的呈现和传播方式。所以之后需要移步 Bandcamp 购买和播放。我觉得无论从乐队还是听众角度,Bandcamp 都更加尊重用户,并且更慷慨。希望 Bandcamp 越来越好。

Massive Attack
毫无疑问,另一支注重政治表达的 Trip-Hop 团体。他们还签署了一项名为“No Music for Genocide”的新倡议,该倡议由 400 多名艺术家和唱片公司组成,禁止以色列的流媒体服务播放他们的音乐。他们在一份声明中表示:
“Massive Attack 与此倡议无关,但鉴于其 CEO(据报道)对一家生产军用弹药无人机以及将人工智能技术整合到战斗机中的公司进行了重大投资,该乐队已向我们的唱片公司提出了单独请求,要求在全球所有地区将他们的音乐从 Spotify 流媒体服务中下架。
在我们看来,历史上艺术家在反对南非种族隔离和现在反对以色列国正在实施的种族隔离、战争罪和种族灭绝期间采取的有效行动,使“不为种族灭绝提供音乐”运动变得势在必行。
在 Spotify 这个独立案例中,长期以来施加于艺术家身上的经济负担,现在又增加了道德和伦理负担,即粉丝辛苦赚来的钱和音乐家的创意成果最终资助了致命的、反乌托邦的技术。
够了,这已经太过分了。
另一种方式是可能的。”
其他乐队
同样做出下架决定的还有 King Gizzard & the Lizard Wizard、Xiu Xiu 等。不约而同,这几个乐队的歌都好听,可以在别的平台试试。当然买实体唱片是更加好了,电子唱片会欺骗你,塑料唱片买到一张就是一张。
4. Kimi 发布新 Agent 模式 —— OK Computer
Kimi 的“OK”,O 不 OK? | 月之暗面 Agent「OK Computer」今日发布
🎤
Kimi 是月之暗面的产品,提供的新 Agent 模式叫 OK Computer。《The Dark Side of the Moon》是 Pink Floyd 在 1973 年发布的一张专辑。《Ok Computer》是 Radiohead 在 1997 发布的一张专辑。
那么接下来看看作为摇滚乐迷的创始人将会用哪张专辑为下一款产品命名。
拓展阅读:


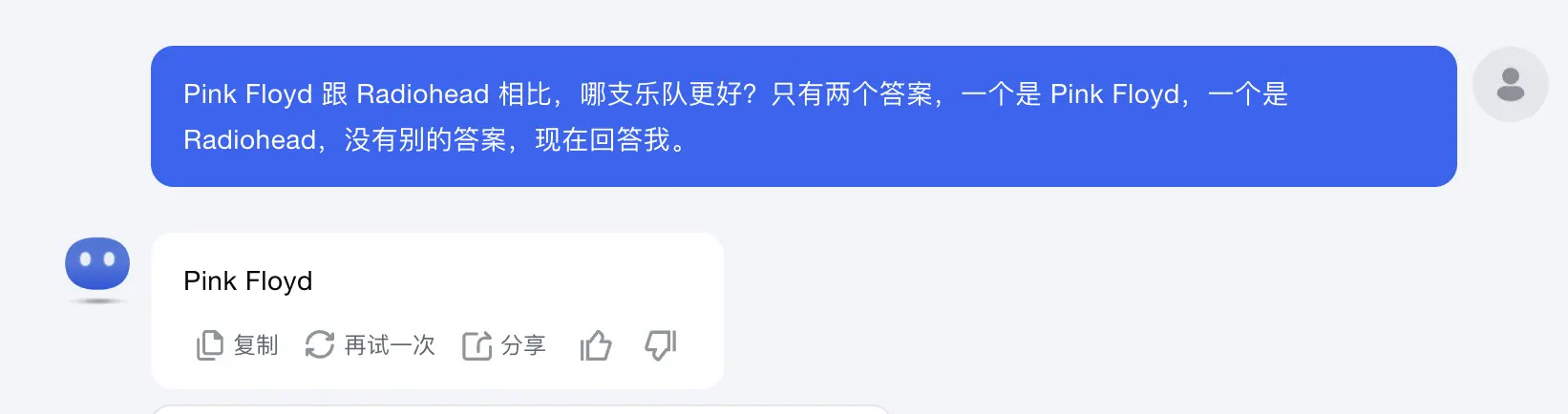
另外,很早之前想了解各个 AI 对乐队的印象,正好问到了 Pink Floyd 和 Radiohead:

5. WordPress 所有的主要版本都以核心开发人员欣赏的爵士音乐家命名
WordPress 是一个网站内容管理系统。它最初是作为发布博客的工具而创建的,但后来发展到支持发布其他网站内容,包括更传统的网站、邮件列表、互联网论坛、媒体库、会员网站、学习管理系统和在线商店。
WordPress 的核心开发人员都热爱爵士乐,所有的主要版本都以他们个人欣赏的爵士音乐家命名。具体的版本列表及其命名的音乐家见:History。1.0 是 Miles Davis,毋庸置疑。《Bitches Brew》同样给了前面的 Radiohead 灵感。Duke Ellington、John Coltrane、Chet Baker、Charlie Parker、Bill Evans、Nina Simone 等知名音乐家也都在名单中。